Download as PDF, PPTX







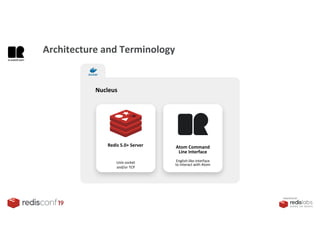
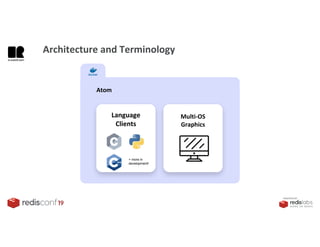

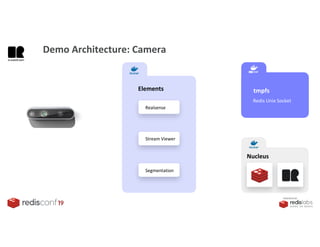




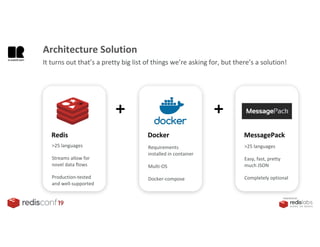


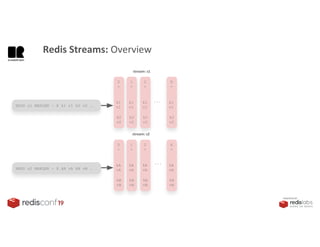
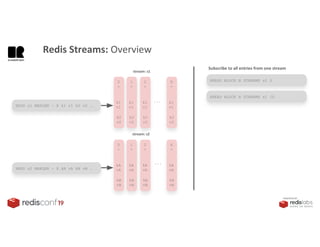
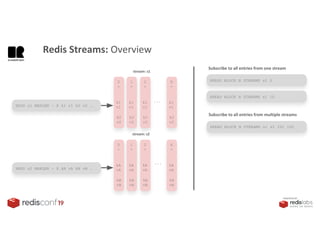
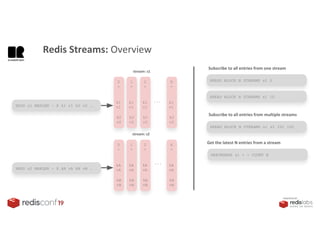
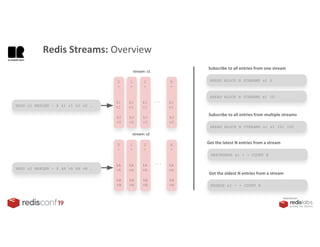
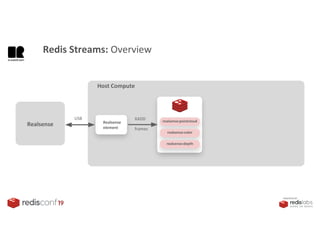
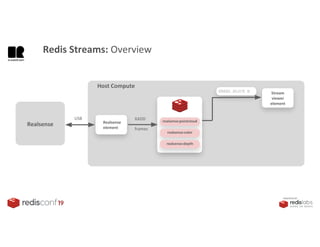
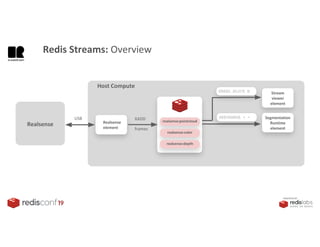
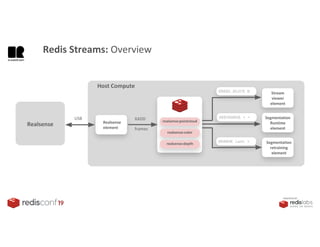

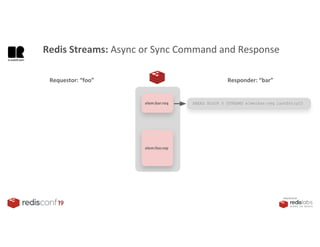
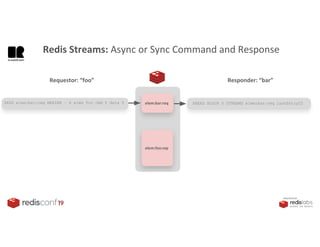
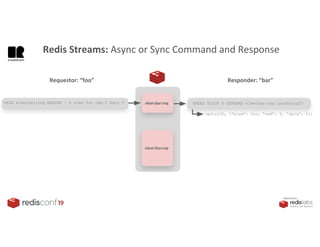
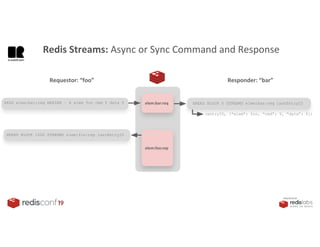
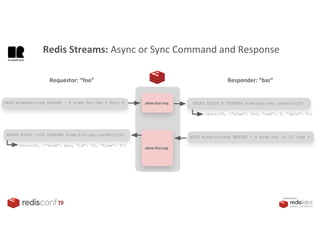
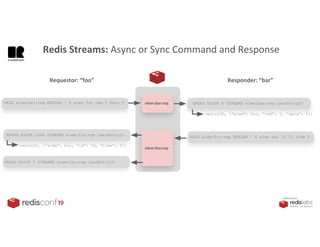
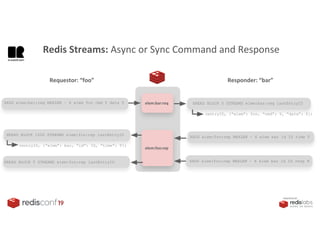
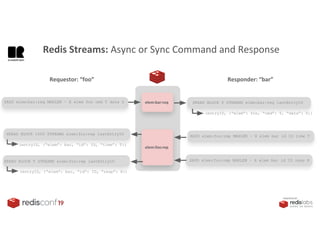
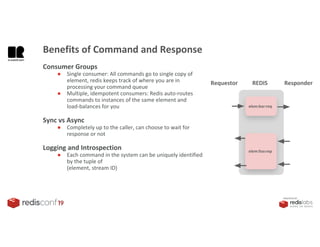
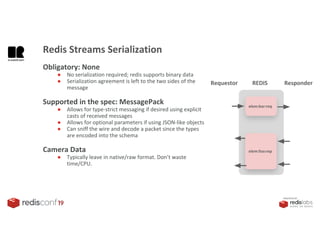

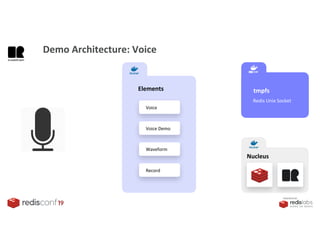







1. The document describes an SDK called Atom that uses Redis Streams to enable communication between microservices. 2. Atom allows developers to break applications into reusable microservices that can interact through publishing to and subscribing from Redis Streams. 3. Redis Streams provides an efficient way to handle pub/sub messaging between microservices as well as asynchronous request/response capabilities through its ability to add and query entries in streams.























































































