Downloaded 41 times


![Data Structures - Redis’ Building Blocks
Lists
[ A → B → C → D → E ]
Hashes
{ A: “foo”, B: “bar”, C: “baz” }
Bitmaps
0011010101100111001010
Strings
"I'm a Plain Text String!”
Bit field
{23334}{112345569}{766538}
Key
Streams
{id1=time1.seq1(A:“xyz”, B:“cdf”),
d2=time2.seq2(D:“abc”, )}
Hyperloglog
00110101 11001110
Sorted Sets
{ A: 0.1, B: 0.3, C: 100 }
Sets
{ A , B , C , D , E }
Geospatial Indexes
{ A: (51.5, 0.12), B: (32.1, 34.7) }](https://image.slidesharecdn.com/redisstreamsmeetup-191115211755/85/Redis-Streams-3-320.jpg)
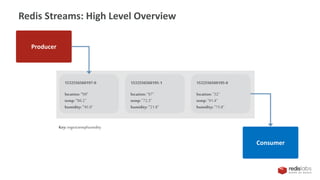
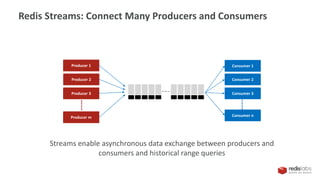







This document provides an overview of Redis Streams, which allow for asynchronous data exchange between producers and consumers in Redis. Redis Streams enable producers to add JSON-formatted messages to a stream, while consumers can read from streams using queries. Streams support connecting multiple producers and consumers, and allow consumers to retrieve messages within a specified time range or read the latest messages.


































![[Spark meetup] Spark Streaming Overview](https://cdn.slidesharecdn.com/ss_thumbnails/sparkmeetupstratiostreaming-150121022614-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)




















































