Download as PDF, PPTX
























































.
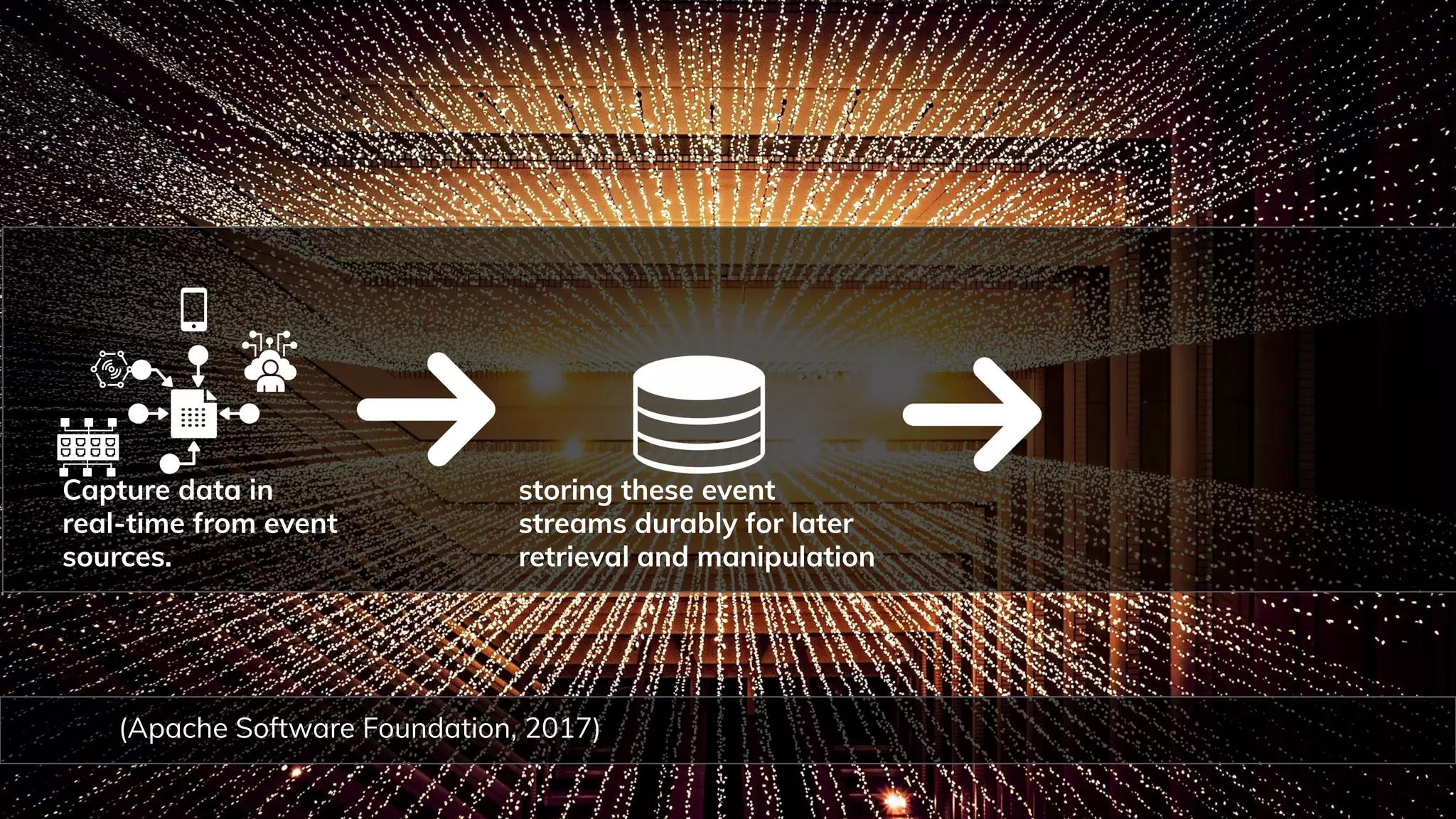
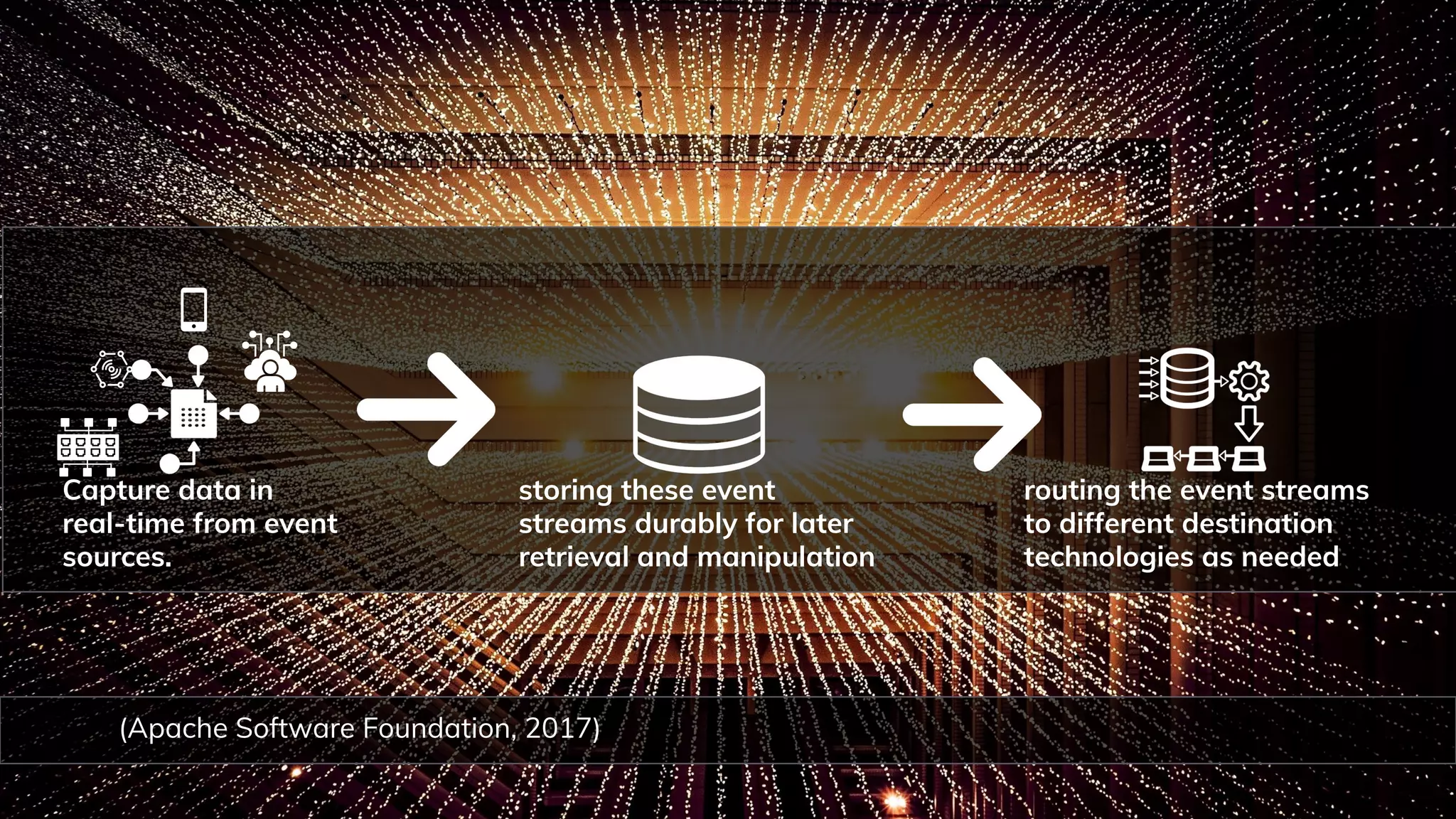
Apache Software Foundation. (2017). INTRODUCTION Everything you need to know about Kafka in 10 minutes. Apache Kafka.
[https://kafka.apache.org/intro](https://kafka.apache.org/intro).
Brewer, E. (2001). Lessons from giant-scale services IEEE Internet Computing 5(4), 46-55.
[https://dx.doi.org/10.1109/4236.939450](https://dx.doi.org/10.1109/4236.939450)
Brewer, E. (2012). CAP Twelve Years Later: How the “Rules” Have Changed Computer 45(2), 23-29.
[https://dx.doi.org/10.1109/mc.2012.37](https://dx.doi.org/10.1109/mc.2012.37)
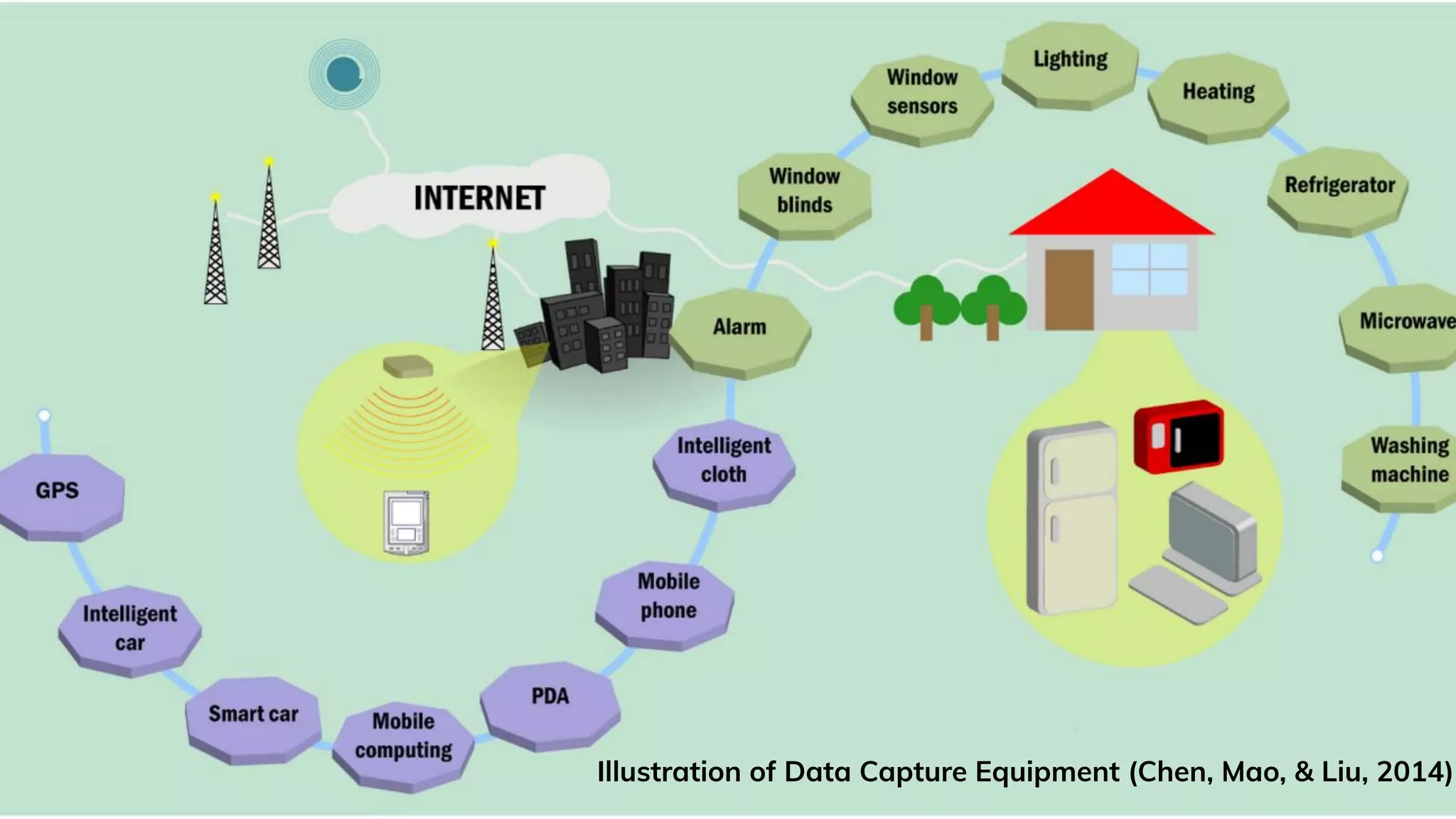
Chen, M., Mao, S., & Liu, Y. (2014). Big data: A survey. Mobile networks and applications, 19(2), 171-209.
Dean, J., Ghemawat, S., Mehta, B. (2008). MapReduce: simplified data processing on large clusters Communications of the ACM 51(1), 107-113.
https://dx.doi.org/10.1145/1327452.1327492
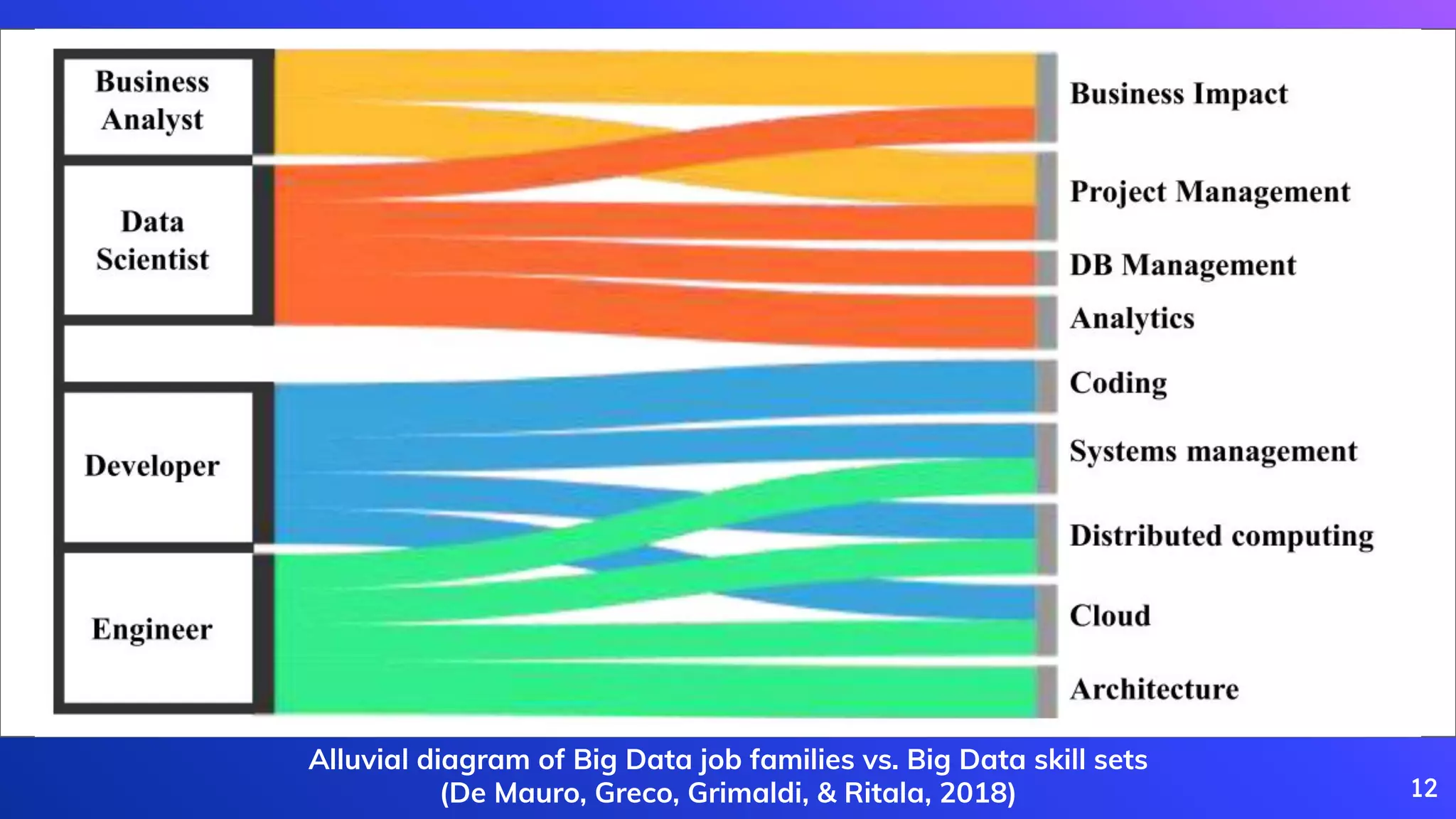
De Mauro, A., Greco, M., Grimaldi, M., & Ritala, P. (2018). Human resources for Big Data professions: A systematic classification of job roles and required skill sets.
Information Processing & Management, 54(5), 807-817.
Devopedia. 2020. "CAP Theorem." Version 4, April 30. Accessed 2020-09-14. https://devopedia.org/cap-theorem
Dixon, J. (2010, October 14). Pentaho, Hadoop, and Data Lakes. James Dixon’s Blog.
[https://jamesdixon.wordpress.com/2010/10/14/pentaho-hadoop-and-data-lakes/](https://jamesdixon.wordpress.com/2010/10/14/pentaho-hadoop-and-data-lakes/).
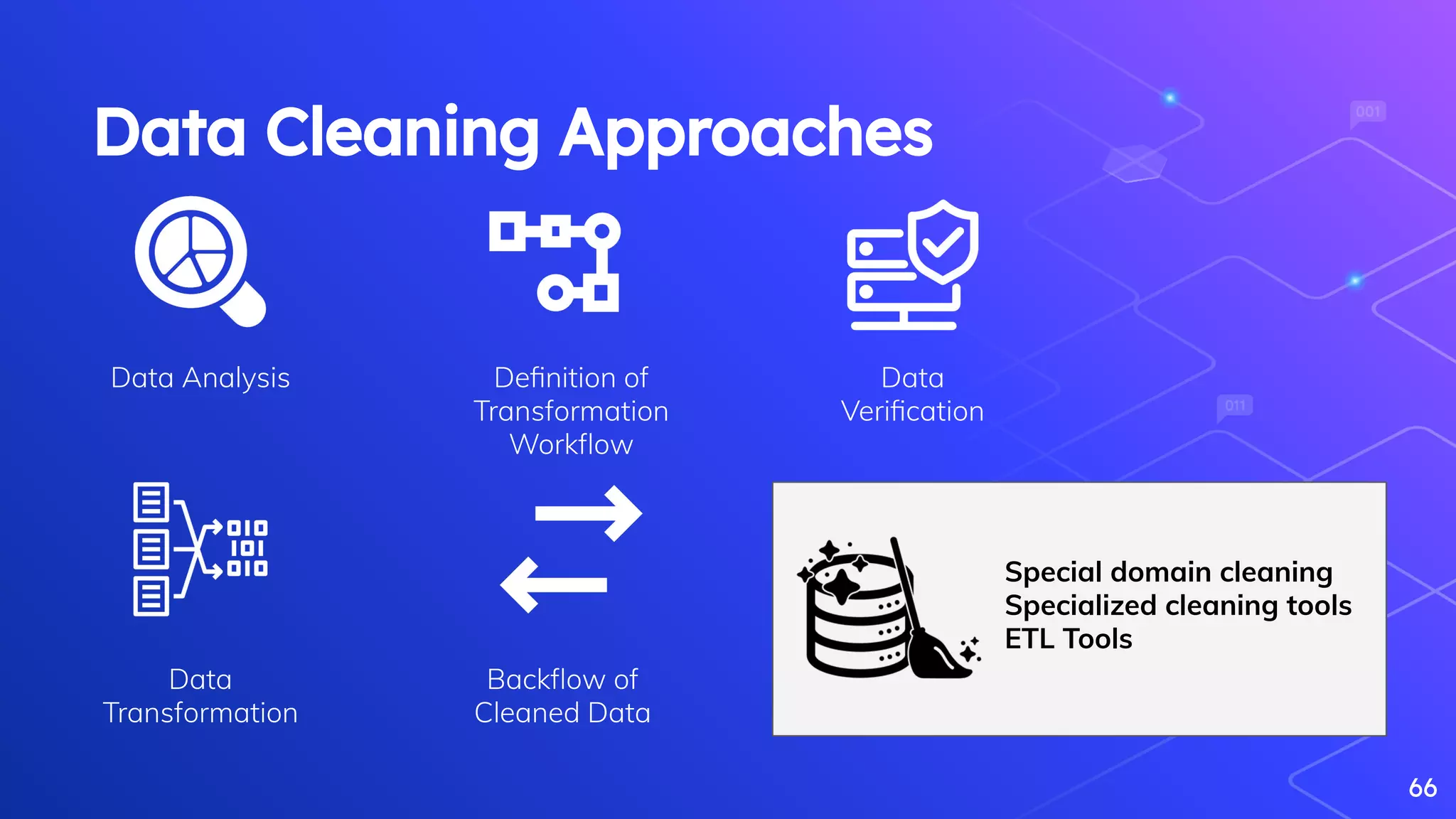
Feng, Z., Hui-Feng, X., Dong-Sheng, X., Yong-Heng, Z., & Fei, Y. (2013). Big data cleaning algorithms in cloud computing. International Journal of Online Engineering, 9(3),
77–81. [https://doi.org/10.3991/ijoe.v9i3.2765](https://doi.org/10.3991/ijoe.v9i3.2765)
Gray, J., & Shenoy, P. (2000). Rules of thumb in data engineering. Proceedings - International Conference on Data Engineering, 3–10.
[https://doi.org/10.1109/icde.2000.839382](https://doi.org/10.1109/icde.2000.839382)
97](https://image.slidesharecdn.com/theroleofdataengineeringindatascienceandanalyticspractice-200915114740/75/The-role-of-data-engineering-in-data-science-and-analytics-practice-96-2048.jpg)

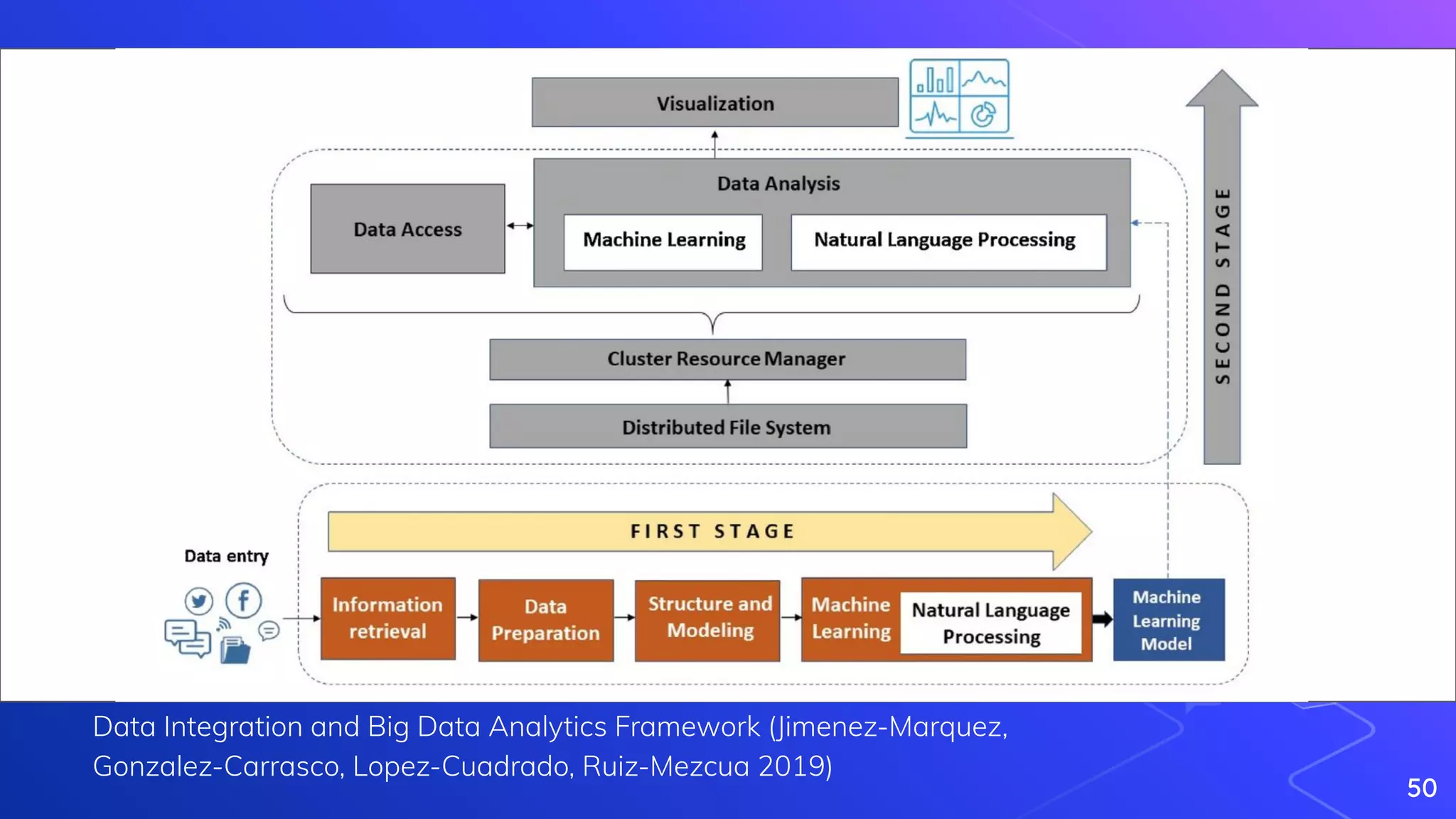
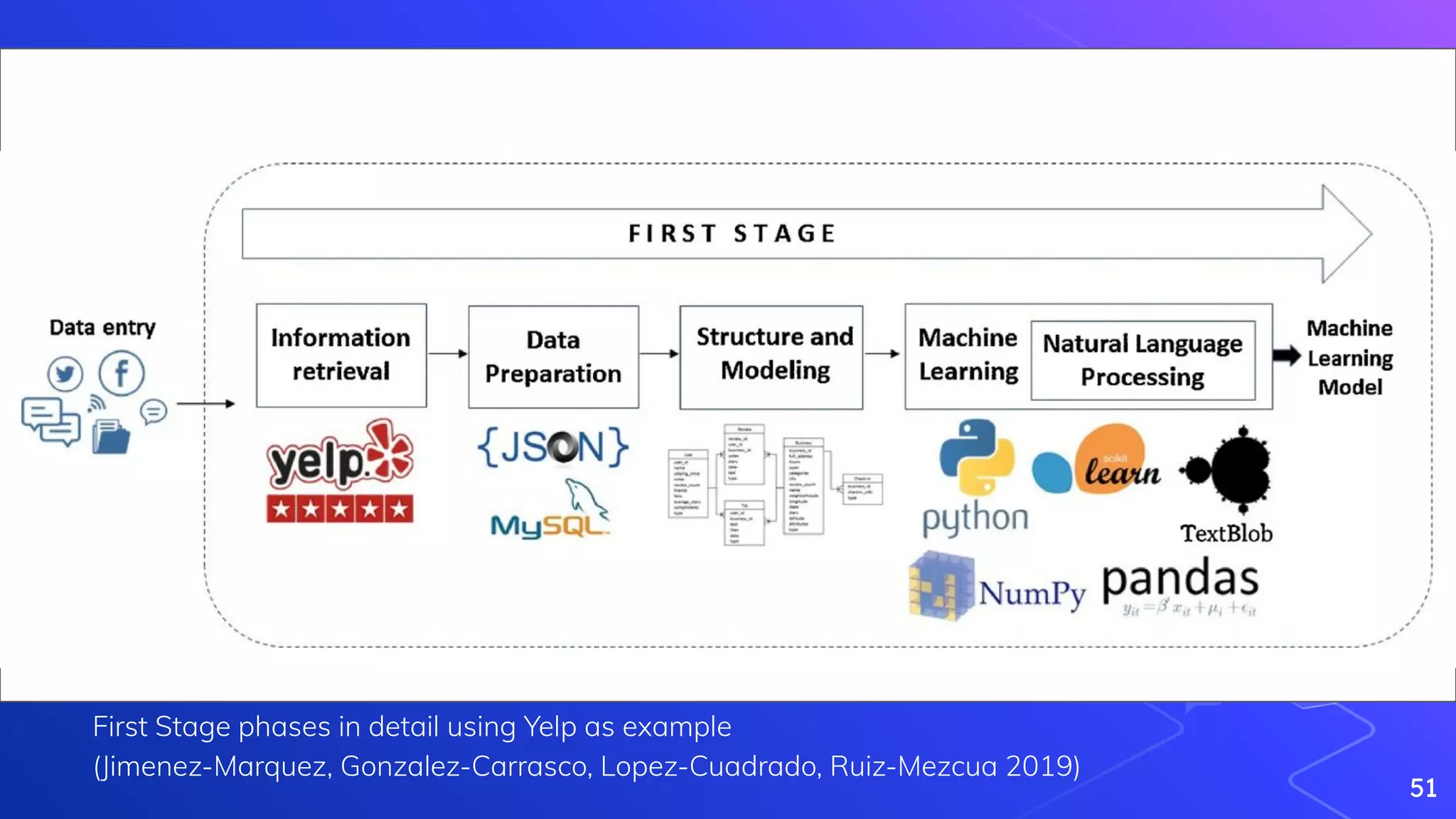
Jimenez-Marquez, J., Gonzalez-Carrasco, I., Lopez-Cuadrado, J., Ruiz-Mezcua, B. (2019). Towards a big data framework for analyzing social media content International
Journal of Information Management 44(), 1-12. [https://dx.doi.org/10.1016/j.ijinfomgt.2018.09.003](https://dx.doi.org/10.1016/j.ijinfomgt.2018.09.003)
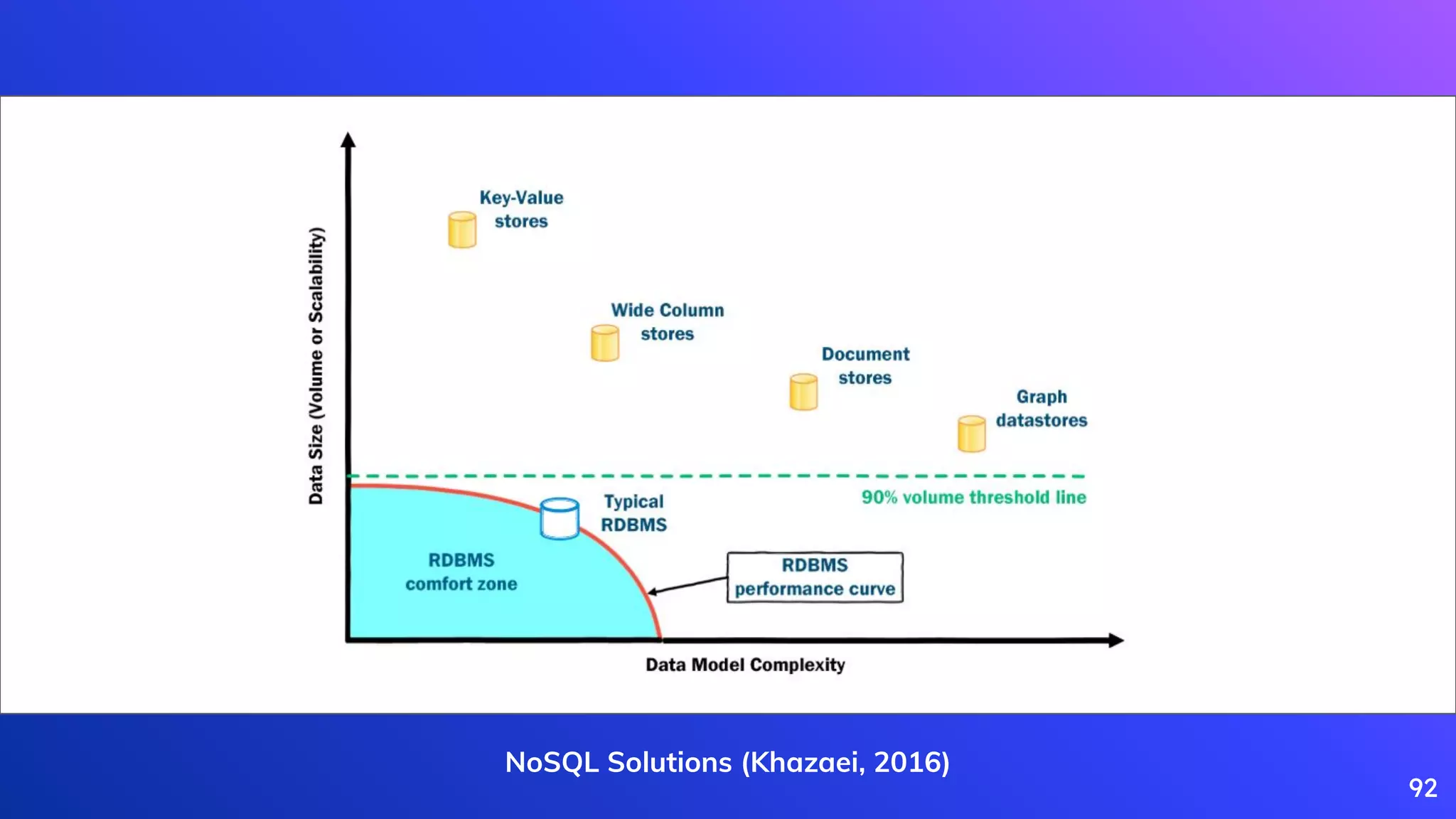
Khazaei, H. (2016). How do I choose the right NoSQL solution? Big Data, X(0), 1–33.
Laskowski, N. (2016). Data lake governance: A big data do or die. URL:
[http://searchcio](http://searchcio/).techtarget.com/feature/Data-lake-governance-A-big-data-do-or-die (access date 28/05/2016)
Marz, N., & Warren, J. (2015). Big Data: Principles and best practices of scalable real-time data systems. New York; Manning Publications Co.
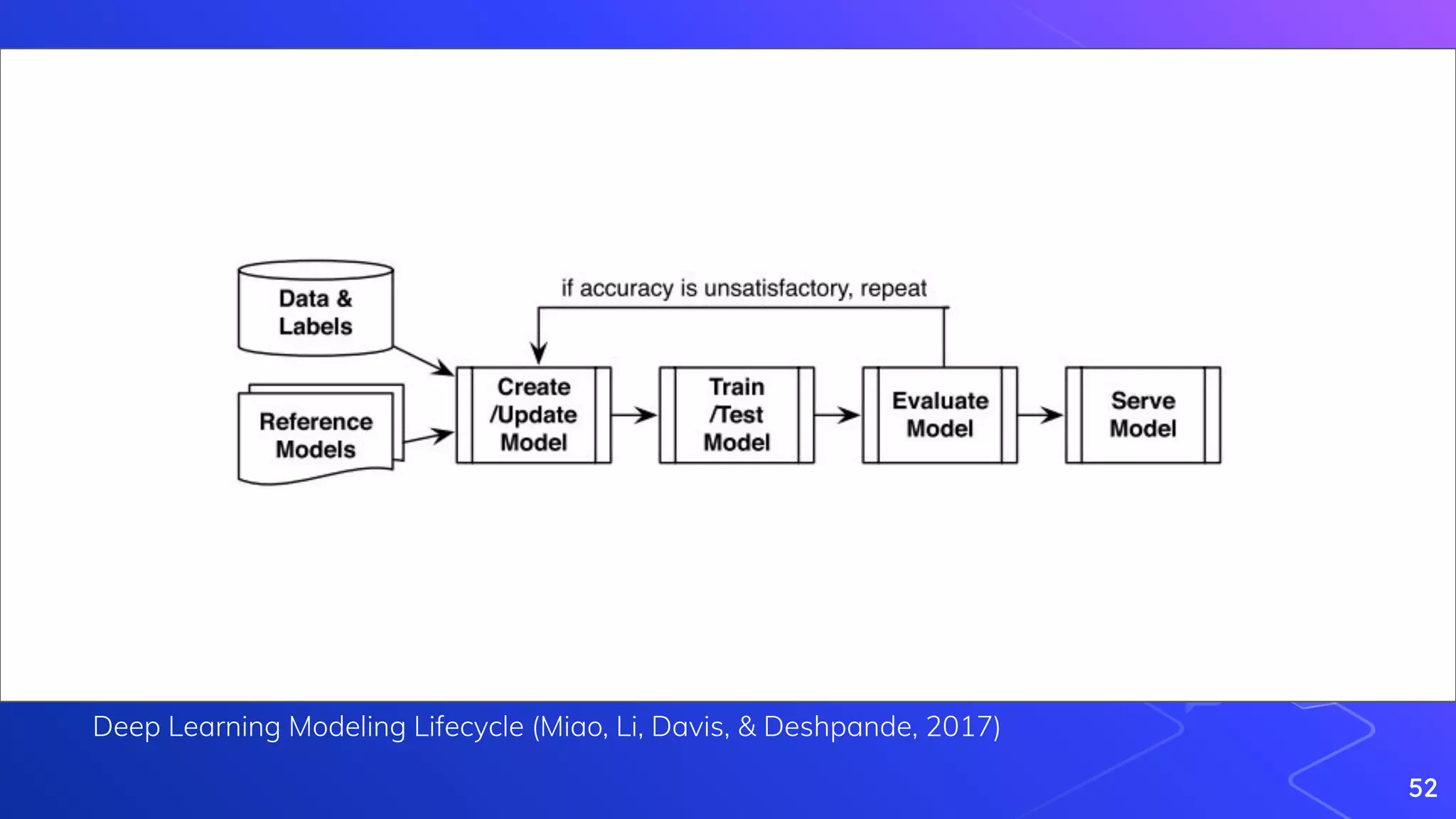
Miao, H., Li, A., Davis, L. S., & Deshpande, A. (2017, April). Towards unified data and lifecycle management for deep learning. In 2017 IEEE 33rd International Conference on
Data Engineering (ICDE) (pp. 571-582). IEEE.
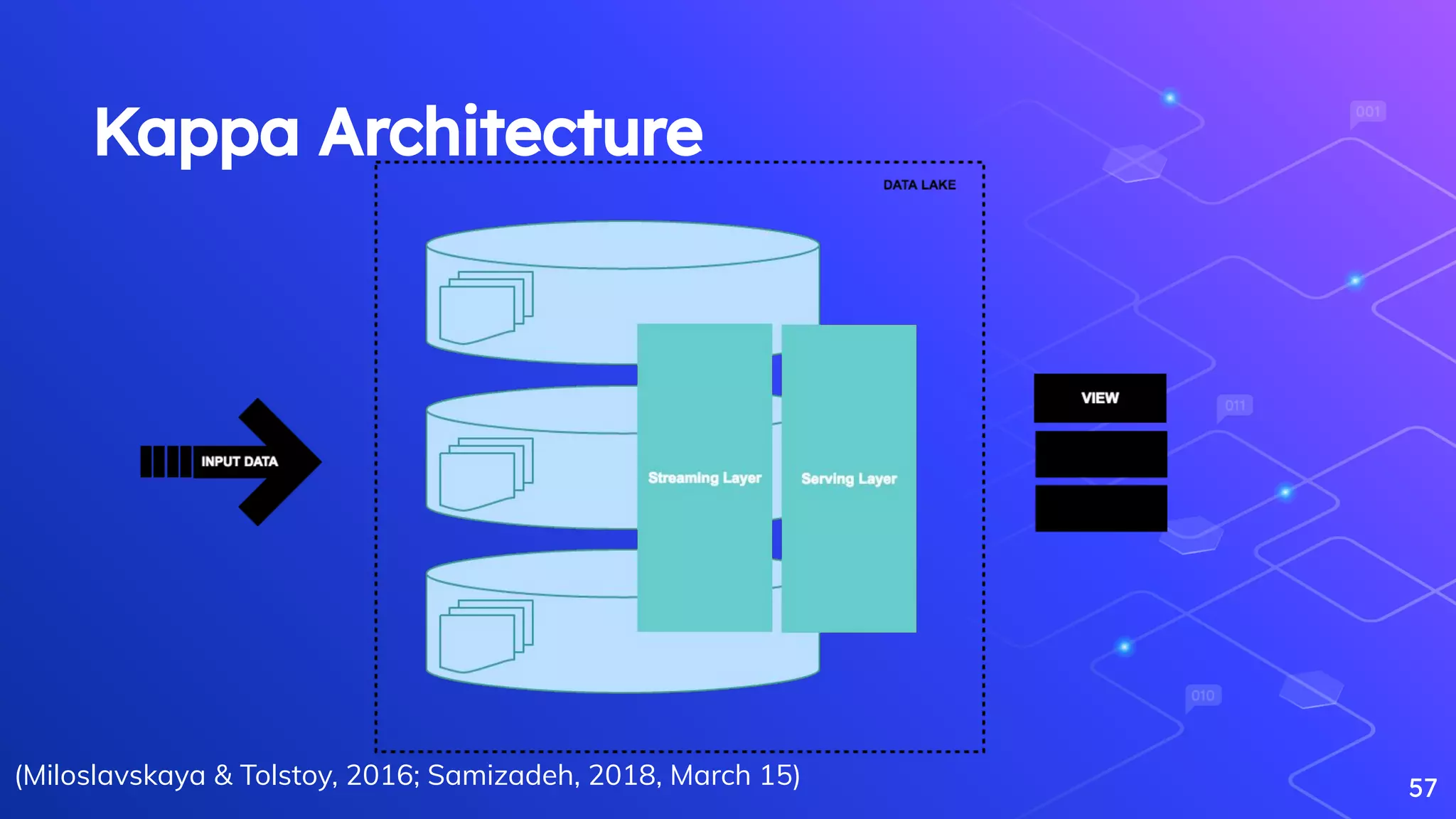
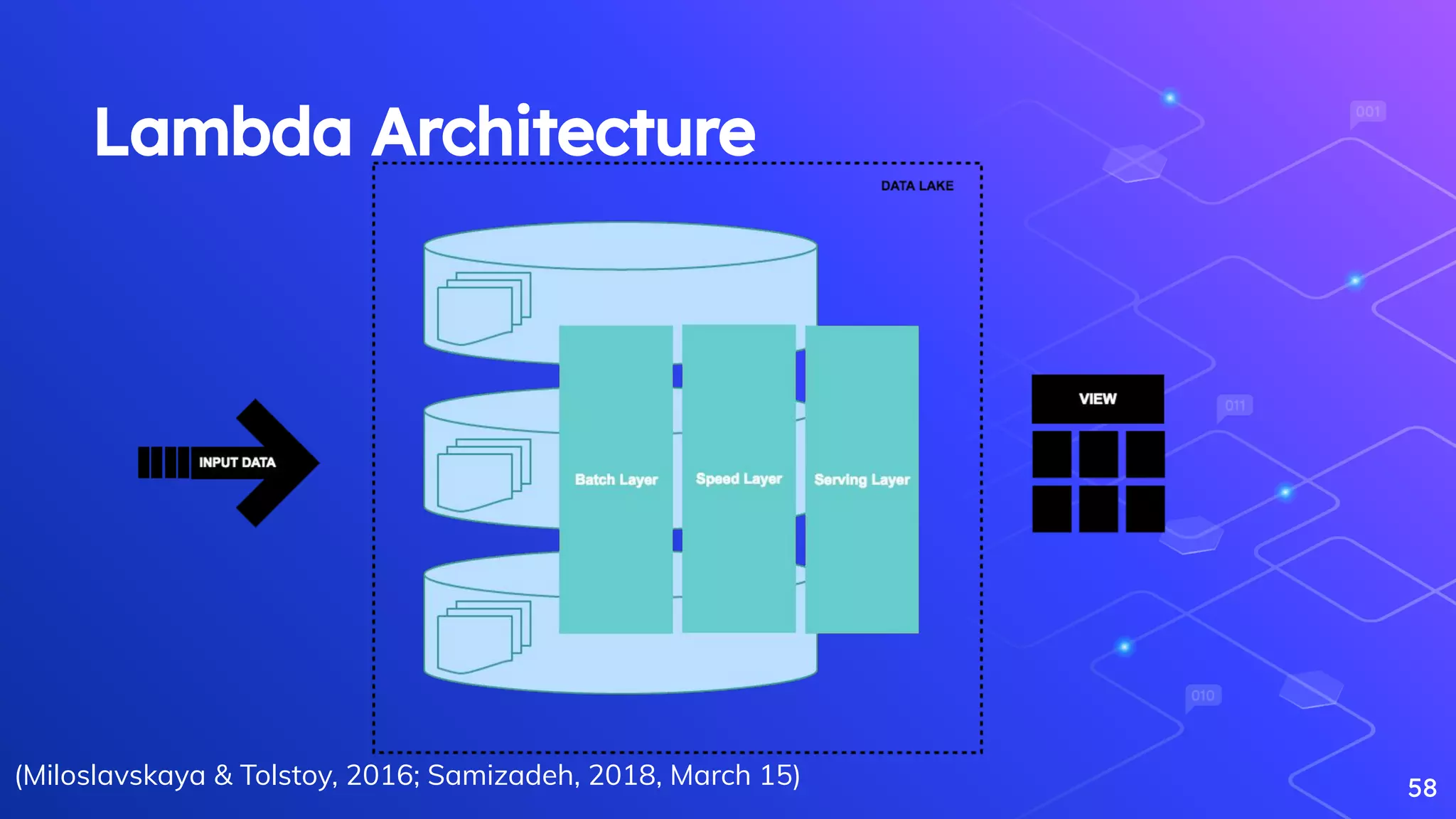
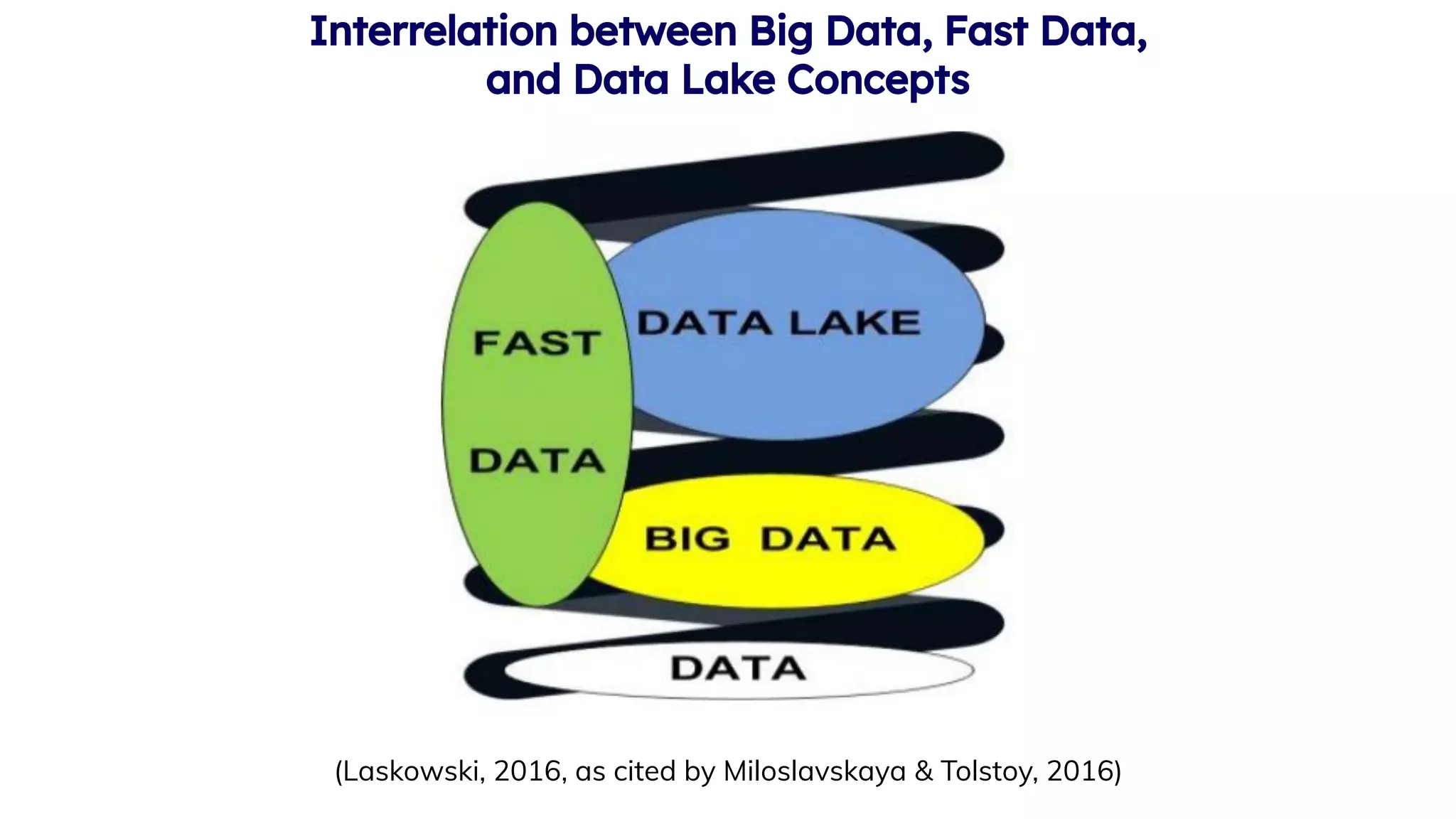
Miloslavskaya, N., & Tolstoy, A. (2016). Big Data, Fast Data and Data Lake Concepts. Procedia Computer Science, 88, 300–305.
[https://doi.org/10.1016/j.procs.2016.07.439](https://doi.org/10.1016/j.procs.2016.07.439)
Najafabadi, M. M., Villanustre, F., Khoshgoftaar, T. M., Seliya, N., Wald, R., & Muharemagic, E. (2015). Deep learning applications and challenges in big data analytics. Journal
of Big Data, 2(1), 1.
Rahm, E., & Do, H. H. (2000). Data cleaning: Problems and current approaches. IEEE Data Eng. Bull., 23(4), 3-13.
Samizadeh, I. (2018, March 15). A brief introduction to two data processing architectures - Lambda and Kappa for Big Data.
[https://towardsdatascience.com/a-brief-introduction-to-two-data-processing-architectures-lambda-and-kappa-for-big-data-4f35c28005bb](https://towardsdatasci
ence.com/a-brief-introduction-to-two-data-processing-architectures-lambda-and-kappa-for-big-data-4f35c28005bb).
98](https://image.slidesharecdn.com/theroleofdataengineeringindatascienceandanalyticspractice-200915114740/75/The-role-of-data-engineering-in-data-science-and-analytics-practice-97-2048.jpg)

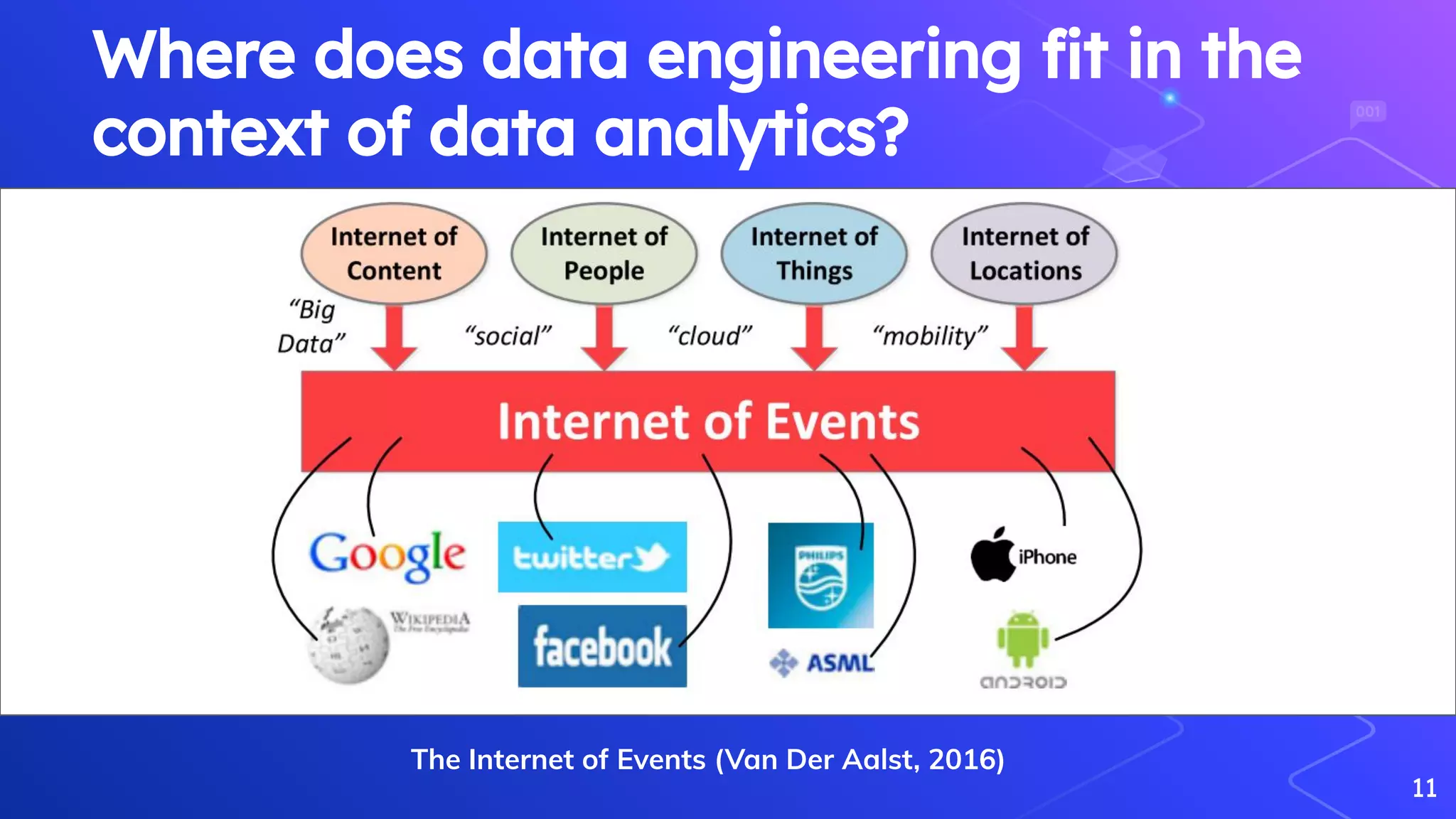
Van Der Aalst, W. (2016). Data science in action. In Process mining (pp. 3-23). Springer, Berlin, Heidelberg.
Vogels, W. (2009). Eventually consistent Communications of the ACM 52(1), 40-44.
[https://dx.doi.org/10.1145/1435417.1435432](https://dx.doi.org/10.1145/1435417.1435432)
Wang, R. Y., Kon, H. B., & Madnick, S. E. (1993). Data quality requirements analysis and modeling. Proceedings - International Conference on Data Engineering, 670–677.
[https://doi.org/10.1109/icde.1993.344012](https://doi.org/10.1109/icde.1993.344012)
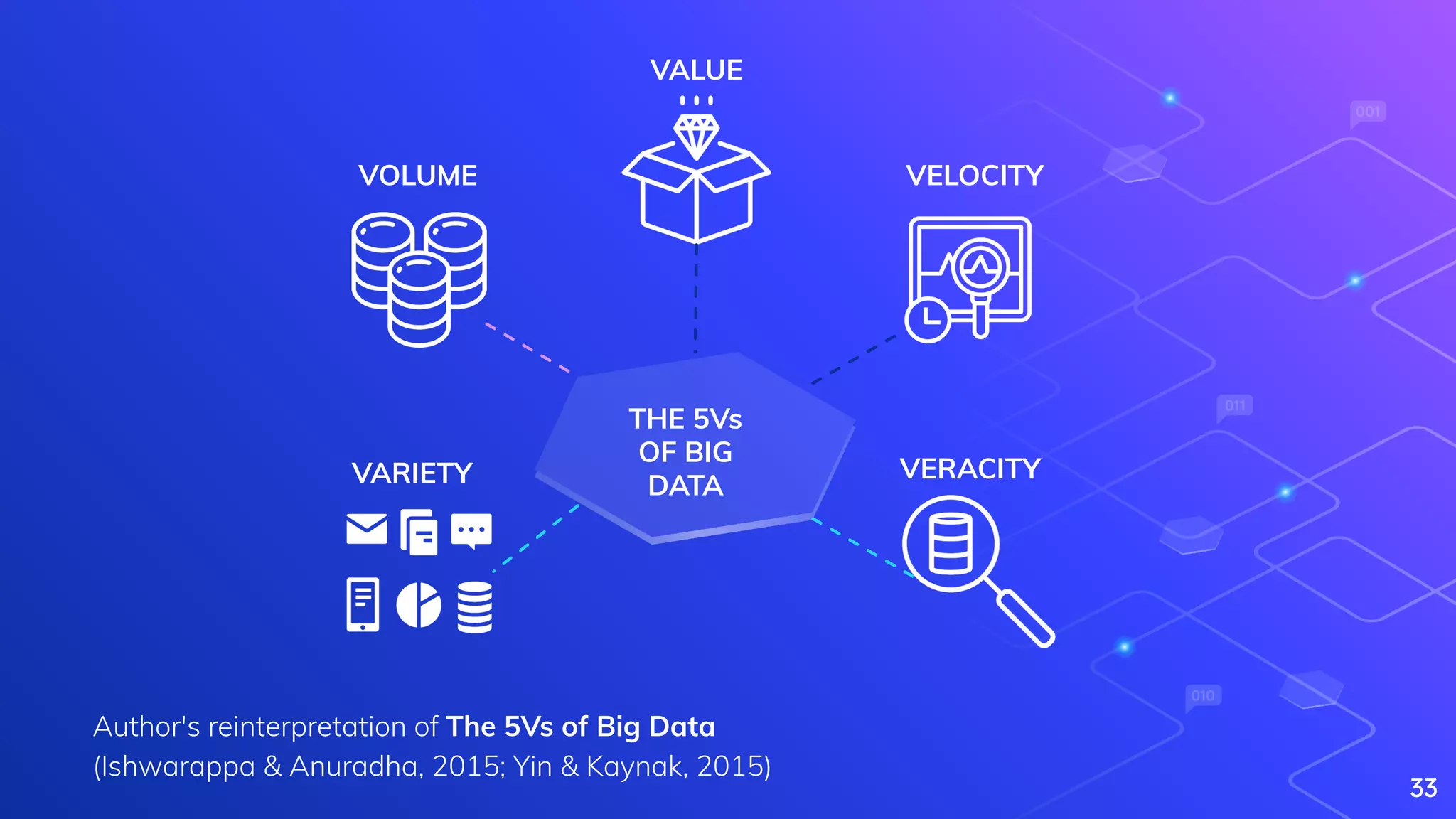
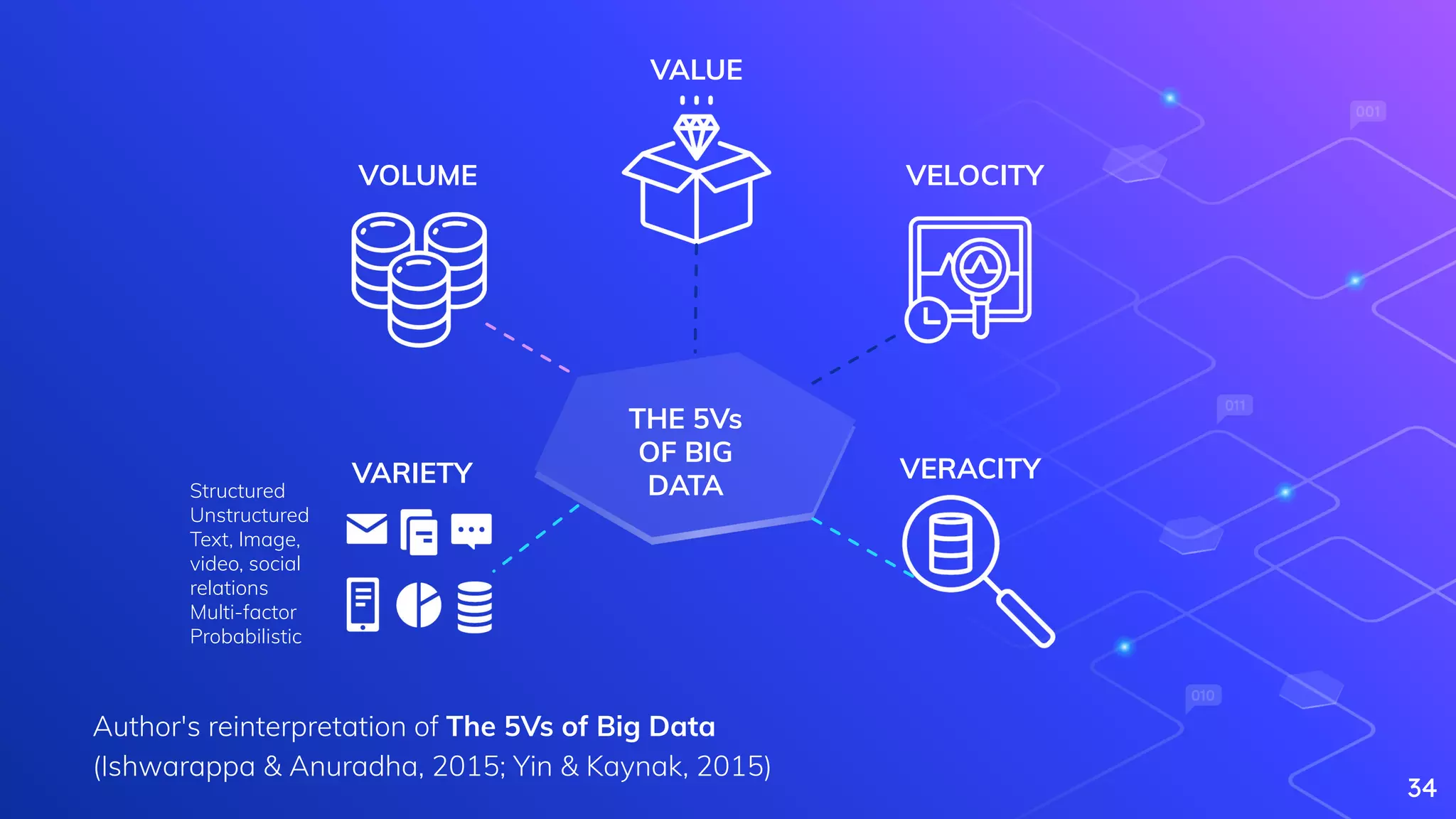
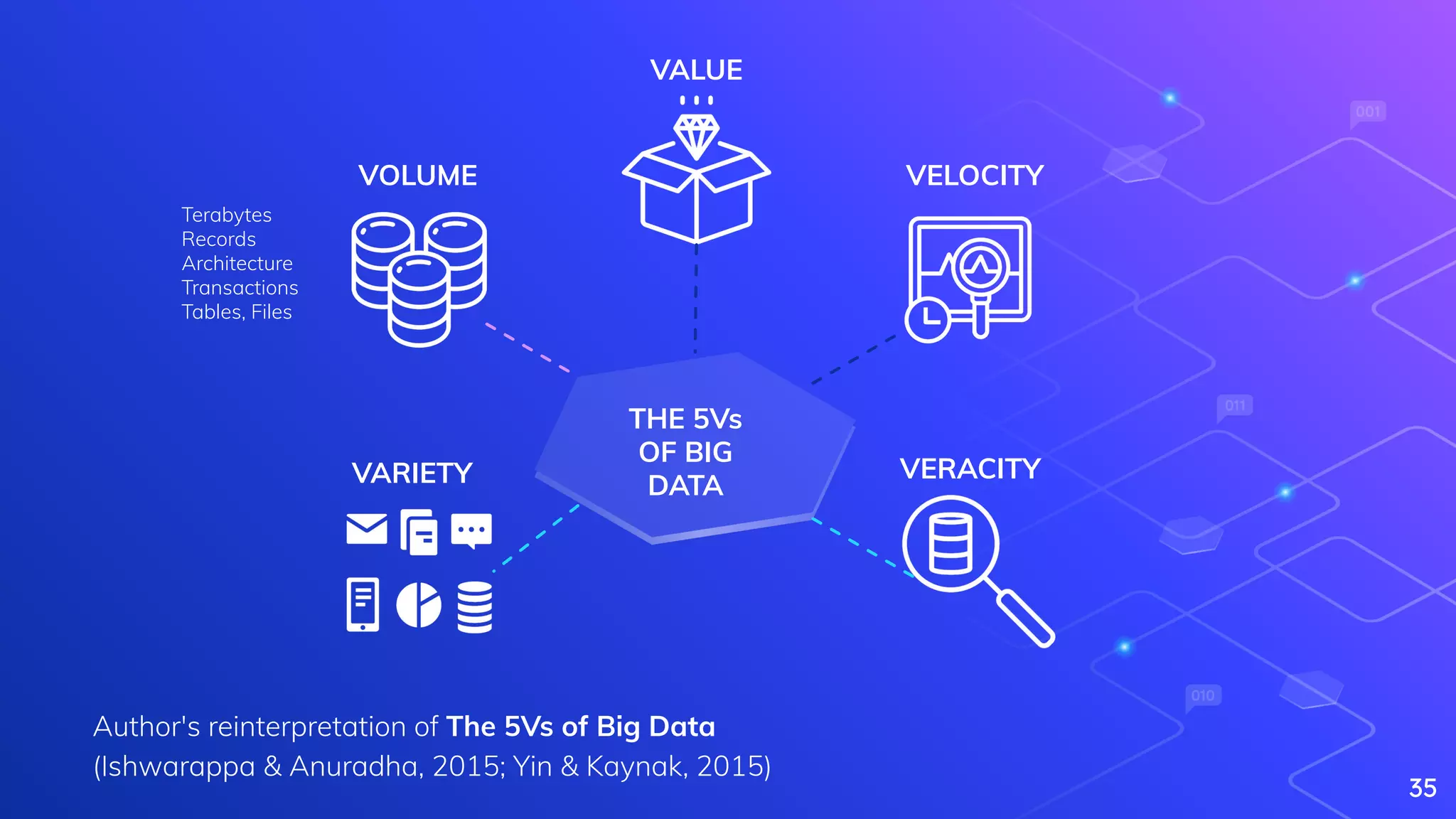
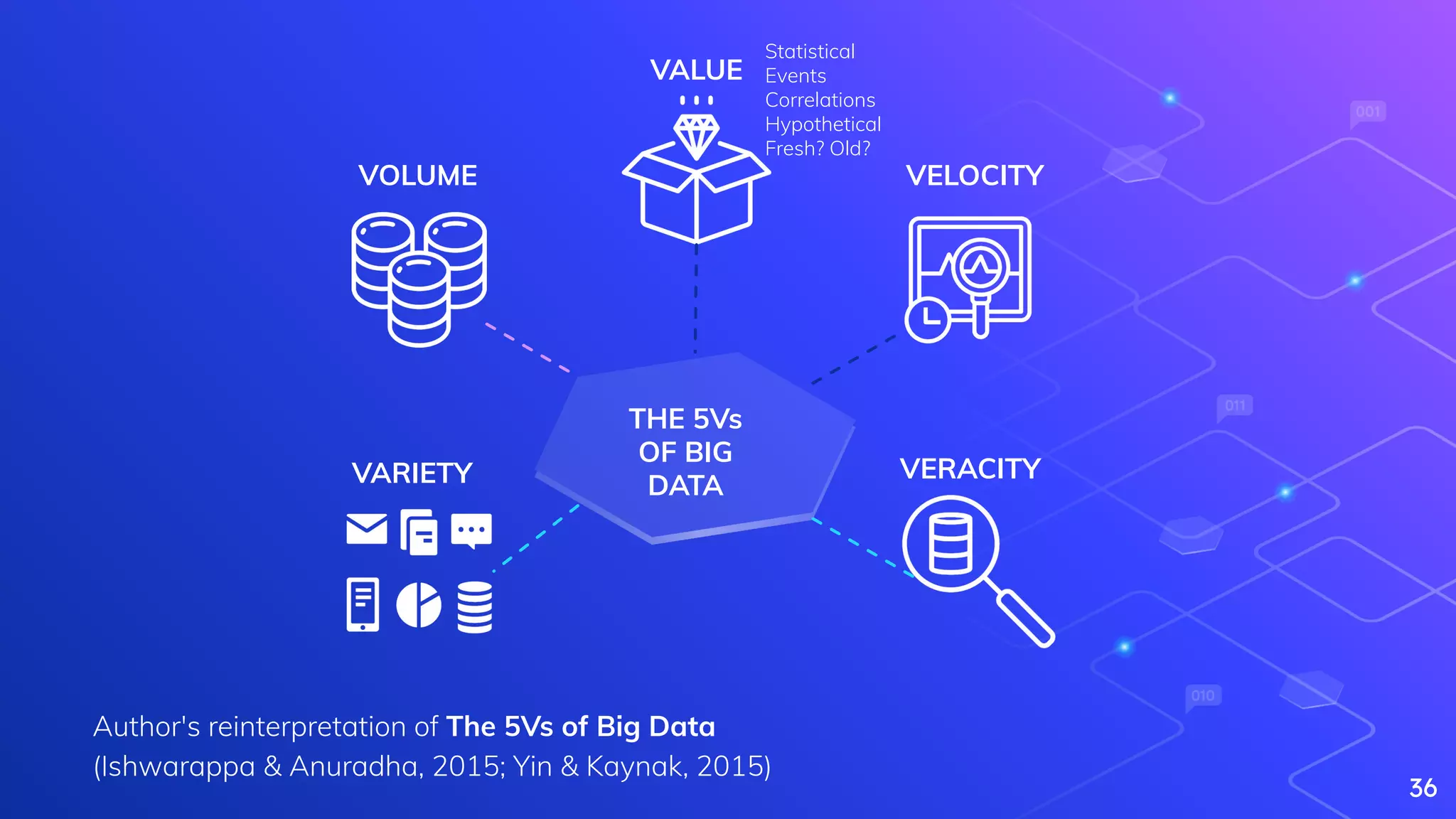
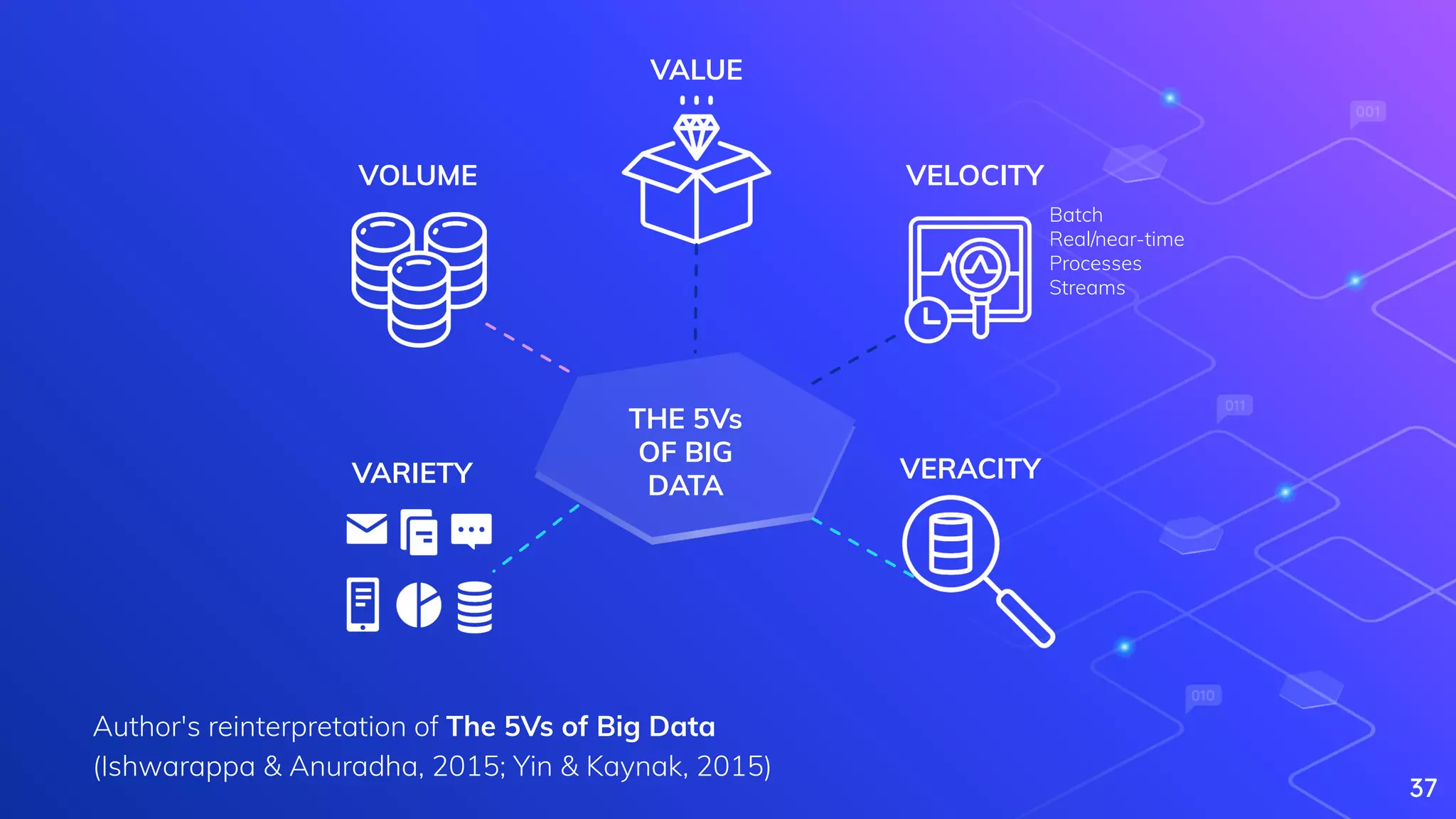
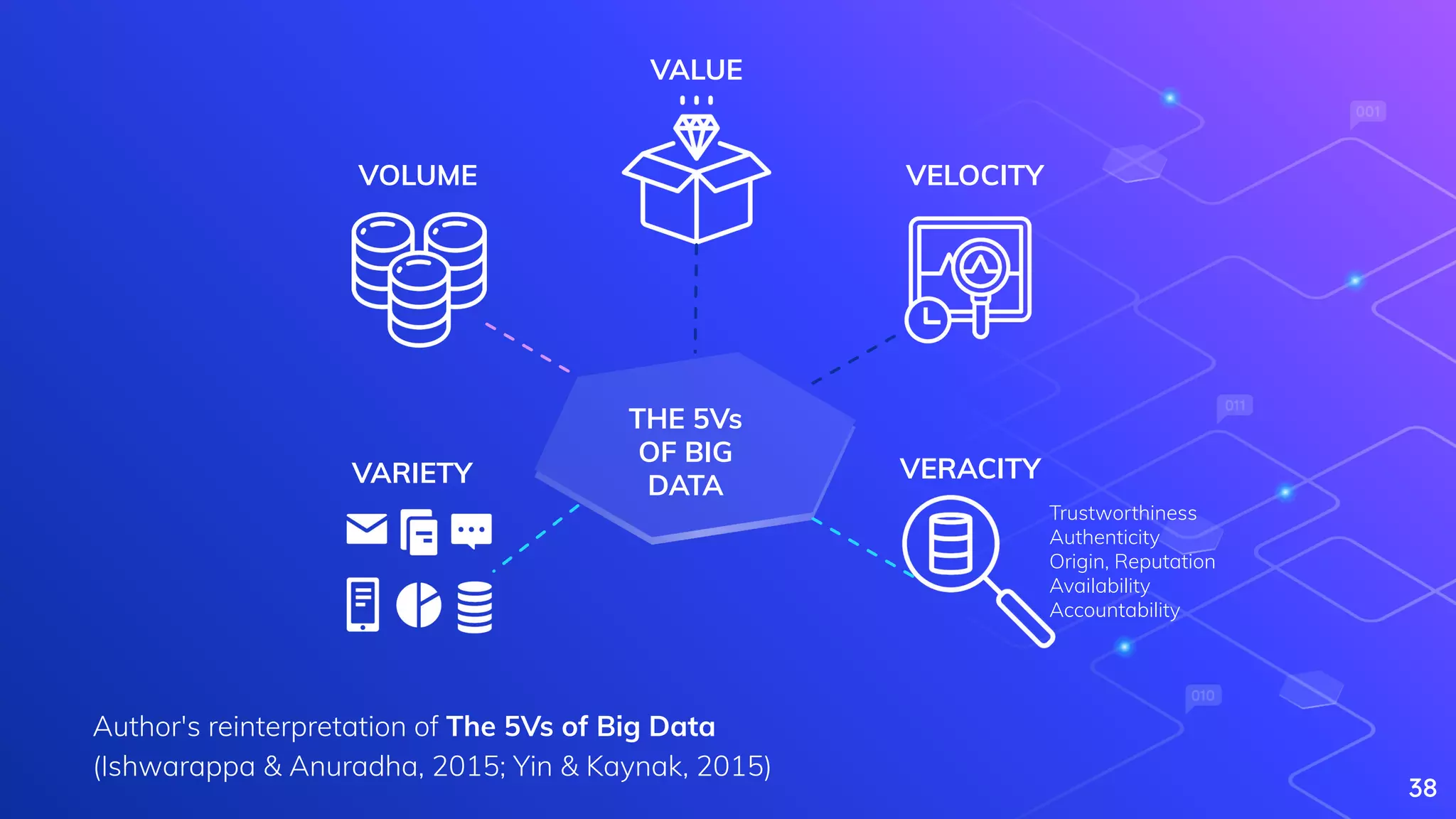
Yin, S., & Kaynak, O. (2015). Big data for modern industry: challenges and trends [point of view]. Proceedings of the IEEE, 103(2), 143-146.
99](https://image.slidesharecdn.com/theroleofdataengineeringindatascienceandanalyticspractice-200915114740/75/The-role-of-data-engineering-in-data-science-and-analytics-practice-98-2048.jpg)

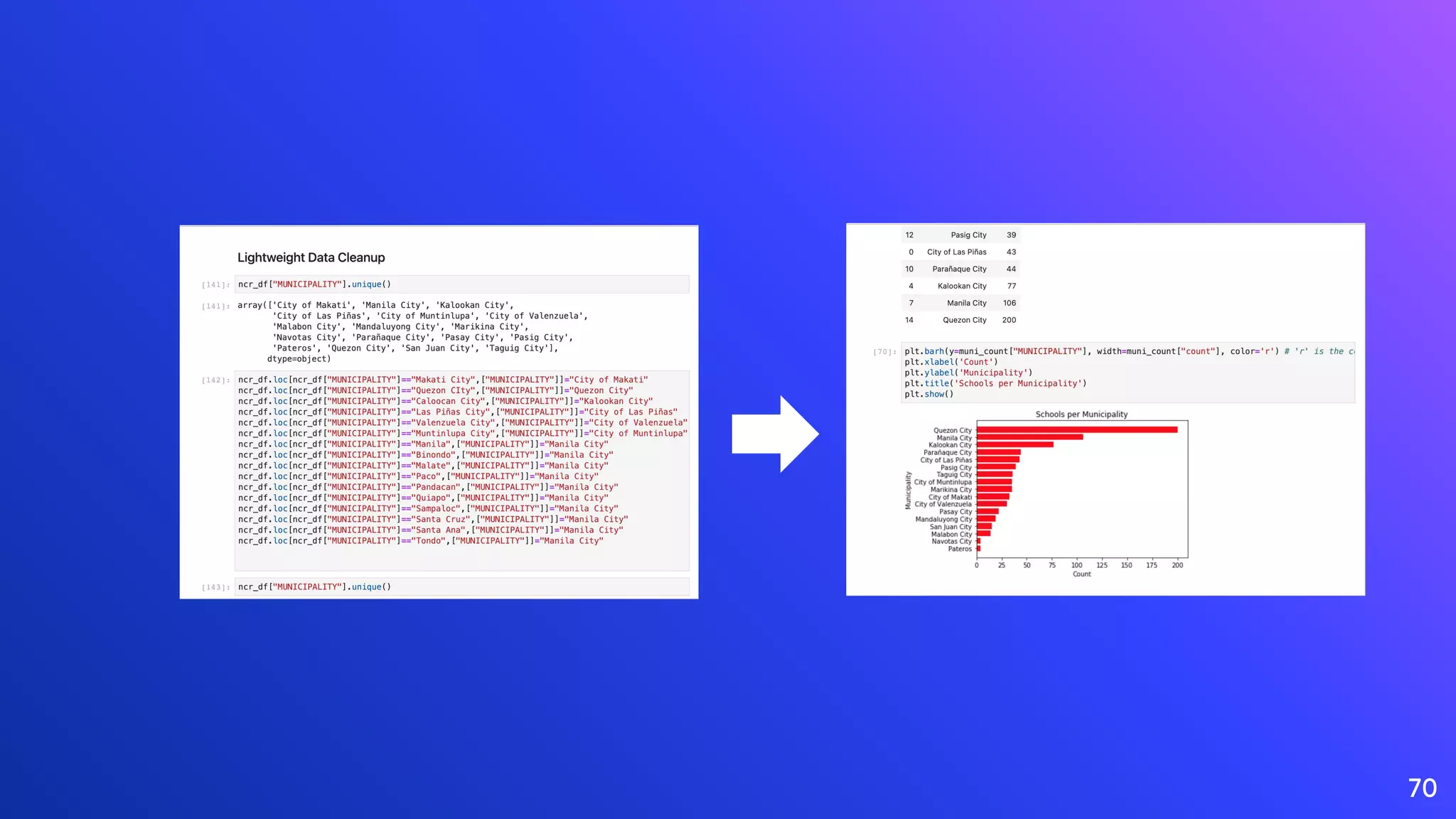
The document discusses the role of data engineering in the context of data science and analytics, highlighting the multidisciplinary nature of data engineering teams and the significance of creating data pipelines. It outlines essential skills, processes, and big data concepts, including the importance of data cleaning, event streaming, and the distinctions between big data and fast data. The document emphasizes continuous learning and collaboration within the field of data engineering.
















































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)




