ΤΕΧΝΟΛΟΓΙΚΟ ΕΚΠΑΙΔΕΥΤΙΚΟ ΙΔΡΥΜΑΠΑΤΡΩΝ
ΣΧΟΛΗ ΔΙΟΙΚΗΣΗΣ ΚΑΙ ΟΙΚΟΝΟΜΙΑΣ
ΕΠΙΧΕΙΡΗΜΑΤΙΚΟΥ ΣΧΕΔΙΑΣΜΟΥ ΚΑΙ ΠΛΗΡΟΦΟΡΙΑΚΩΝ
ΣΥΣΤΗΜΑΤΩΝ
ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ
ΣΤΑΤΙΣΤΙΚΗ ΜΕ ΤΟ ΠΡΟΓΡΑΜΜΑ R
ΚΑΛΑΝΔΡΑΚΗΣ ΚΩΝΣΤΑΝΤΙΝΟΣ Α.Μ. 2185
ΚΟΥΚΟΣ ΧΡΗΣΤΟΣ Α.Μ. 2254
ΚΛΑΔΗ ΚΟΚΚΙΝΟΥ ΜΑΙΡΗ Α.Μ. 2364
ΕΠΟΠΤΕΥΩΝ ΚΑΘΗΓΗΤΗΣ: ΚΟΥΝΕΤΑΣ ΚΩΝΣΤΑΝΤΙΝΟΣ
ΠΑΤΡΑ 2013
2.
1
Ευχαριστίες
Η ολοκλήρωση αυτήςτης έρευνας υλοποιήθηκε με την υποστήριξη ενός
αριθμού ανθρώπων, που χωρίς αυτούς θα ήταν πολύ δύσκολο να επιτευχθεί.
Πρώτα απ’ όλα, θα θέλαμε να ευχαριστήσουμε τον επιβλέποντα της πτυχιακής
εργασίας ,κ. Κωνσταντίνο Κουνετά, για την πολύτιμη βοήθεια του αλλά και
καθοδήγηση του καθ όλη την διάρκεια της δουλειάς μας. Επίσης , είμαστε
ευγνώμων στουςγονείς μας, που ήταν δίπλα μας και μας υποστήριζαν από την
αρχή των σχολικών μας χρόνων μέχρι και τώρα που φτάνουμε στο τέλος.
ΚΑΛΑΝΔΡΑΚΗΣ ΚΩΝΣΤΑΝΤΙΝΟΣ
ΚΟΥΚΟΣ ΧΡΗΣΤΟΣ
ΚΛΑΔΗ ΚΟΚΚΙΝΟΥ ΜΑΙΡΗ
3.
2
Περιεχόμενα
Περίληψη .......................................................................................................5
ΚΕΦΑΛΑΙΟ 1................................................................................................6
1.1Εισαγωγή στην Στατιστική.........................................................................7
1.2Εισαγωγή για το R.....................................................................................9
1.2.1 Γενικές πληροφορίες για το πρόγραμμα................................................9
1.2.2 Γνωριμία με το περιβάλλον................................................................10
1.2.3 Εισαγωγή Δεδομένων στο Πρόγραμμα...............................................17
1.2.4Αποθήκευση και επανάκτηση δεδομένων ............................................18
1.2.5 Συχνά προβλήματα και αντιμετώπιση τους .........................................18
1.3.1 Τελεστές Εκχώρησης και Σύγκρισης .................................................20
1.3.2 Αριθμητικοί Τελεστές........................................................................20
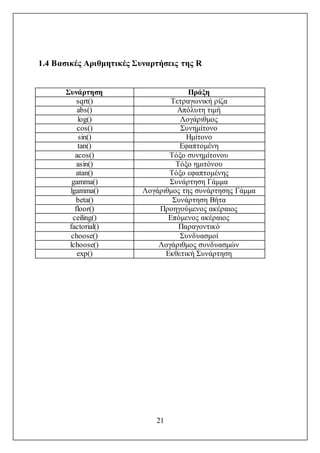
1.4 Βασικές Αριθμητικές Συναρτήσεις της R..................................................21
ΚΕΦΑΛΑΙΟ 2..............................................................................................22
2.1 Εύρεση Μέσου, Διάμεσου και επικρατούσας τιμής...................................23
2.2 Εύρεση τυπικής απόκλισης και διασποράς................................................25
2.3 Εύρεση Τεταρτημόριων...........................................................................26
2.4 Εύρεση συχνοτήτων, σχετικώνσυχνοτήτων ,δημιουργία πίταςκαι
ιστογράμματος..............................................................................................28
2.4.1Εύρεση Συχνοτήτων και Σχετικών Συχνοτήτων ...................................29
2.4.2Δημιουργία Πίτας και Ιστογράμματος .................................................31
2.5 Χρονοσειρά.............................................................................................35
4.
3
2.6 Εύρεση Κλάσεων,δημιουργία ιστογράμματος..........................................37
2.6.1 Εύρεση Κλάσεων, δημιουργία ιστογράμματος ....................................41
2.7 Ελαχίστων Τετραγώνων...........................................................................46
2.8 Άσκηση ελέγχου με γνωστό τον έλεγχο και την τυπική απόκλιση..............53
2.9 Άσκηση ελέγχου με γνωστό μέσο.............................................................55
2.9.1 Εισαγωγή δεδομένων χωρίς διάβασμα από αρχείο...............................55
2.10 Έλεγχος αναλογίας ενός πληθυσμού......................................................56
2.11 Έλεγχος ίσων διασπορών.......................................................................58
2.12 Έλεγχος για το λόγο των διασπορών.....................................................59
2.13 Έλεγχος ίσων διασπορών.......................................................................61
2.14 Έλεγχος Διασποράς...............................................................................62
2.15 Έλεγχος υπόθεσης.................................................................................64
2.16 Έλεγχος υπόθεσης.................................................................................65
2.17 Έλεγχος καλής προσαρμογής .................................................................66
ΚΕΦΑΛΑΙΟ 3..............................................................................................68
3.1 Με λίγα λόγια..........................................................................................69
3.1.2 Πλεονεκτήματα και Μειονεκτήματα του Προγράμματος.....................69
3.1.2.1 Πλεονεκτήματα............................................................................69
1.3.2.2 Μειονεκτήματα............................................................................70
3.1.3 Σύγκριση με άλλα στατιστικά προγράμματα. ......................................71
3.1.4 Προτάσεις. ........................................................................................72
3.2 Συμπεράσματα. .......................................................................................72
Πίνακες ........................................................................................................74
Τιμές των πιθανοτήτων )()()( zZPzZPzΦ της τυποποιημένης
κανονικής κατανομής )1(0,N για 0z . Για 0z ισχύει )(1)( zΦzΦ .......74
α................................................................................................................75
Τιμών aνt ; της νt -κατανομής ώστε atPtP aννaνν )()( ;; ` TT .....................75
ν.............................................................................................................75
5.
4
Tων τιμών 2
aνχ1; της 2
χ κατανομής για τις οποίες
aχXPχXP a-1;νa-1;ν )()( 22
. .................................................................77
Tων τιμών 2
a;νχ της 2
χ κατανομής για τις οποίες aχXPχXP a;νa;ν )()( 22
..................................................................................................................79
Τιμές aννF ;, 21
της F κατανομήςγια τις οποίες
aFXPFXP aννaνν )()( ;,;, 2121
)( 01.0a . ......................................81
Τιμές aννF ;, 21
της F κατανομήςγια τις οποίες
aFXPFXP aννaνν )()( ;,;, 2121
)( 01.0a . ......................................83
Τιμές aννF ;, 21
της F κατανομήςγια τις οποίες
aFXPFXP aννaνν )()( ;,;, 2121
)( 05.0a .......................................85
Τιμές aννF ;, 21
της F κατανομήςγια τις οποίες
aFXPFXP aννaνν )()( ;,;, 2121
)( 05.0a .......................................87
Βιβλιογραφία................................................................................................89
Ελληνική Βιβλιογραφία..............................................................................89
Ξενόγλωσση Βιβλιογραφία.........................................................................89
Χρήσιμες Ιστοσελίδες................................................................................90
6.
5
Περίληψη
Σκοπός αυτήςτης εργασίαςείναι η γνωριμία, η κατανόηση και εξοικείωση με το
πρόγραμμα R σε ότι αφορά θέματα στατιστικής φύσης.
Η έρευνα αυτή θα αναφερθεί ως επί των πλείστων σε βασικούς ορισμούς
της στατιστικής, σε εισαγωγικά θέματα που αφορούν το πρόγραμμα ,αλλά και
στατιστικές μελέτες χρησιμοποιώνταςτο R . Μέσω των ασκήσεων θα δούμε, με
τον πιο απλό τρόπο την επίλυση προβλημάτων χρησιμοποιώντας εντολές και
στην συνέχεια υα εξετάσουμε τα αποτελέσματα τα οποία προέκυψαν.
Τέλος, ακόμα ένας σκοπός αυτήςτης εργασίας είναι η εξαγωγή χρήσιμων
συμπερασμάτων σχετικά με τις στατιστικές μελέτες μέσω του προγράμματος R,
η κριτική του προγράμματος αυτού κάθε αυτού. Η σύγκριση του με αλλά
στατιστικά προγράμματα , αλλά και η διαμόρφωση προτάσεων σχετικά με το
πρόγραμμα.
7
1.1 Εισαγωγή στηνΣτατιστική
Για να καταλάβουμεκαλύτερα τις στατιστικέςμελέτες πάνω στο πρόγραμμα
R θα πρέπει να εξηγήσουμε κάποια βασικά χαρακτηριστικά της Στατιστικής
επιστήμης, όπως είναι οι βασικοί ορισμοί αλλά και τα είδη τους.
Αρχικά, για την διεξαγωγή συμπερασμάτων, εξετάζουμε τα δεδομένα ενός
Πληθυσμού. Ο πληθυσμός είναι ένα σύνολο από στοιχεία, τα οποία και
ερευνούμε. Όπως γίνεται αντιληπτό , ο πληθυσμός μπορεί να είναι αρκετά
μεγάλος και η εξαγωγή συμπερασμάτων να γίνει εξαιρετικά χρονοβόρα αλλά
και αρκετά ζημιογόνα για μια επιχείρηση. Γι’ αυτό τον λόγο, από το σύνολο του
πληθυσμού διαλέγουμε ένα δείγμα, το οποίο είναι ένα υποσύνολο του
πληθυσμού, με σκοπό να γίνει η ανάλυση των μεταβλητών με μεγαλύτερη
ταχύτητα. . Οι μεταβλητές αυτές χωρίζονται σε δυο κατηγορίες : στις ποσοτικές
και στις ποιοτικές μεταβλητές.
Οι ποιοτικές μεταβλητές είναι στοιχεία ενός δείγματος τα οποία δεν
δέχονται αριθμητική μέτρηση. Τέτοιες μεταβλητές μπορεί να απαντάνε σε
ερωτήματα όπως φύλου( Άνδρα, Γυναίκα), οικογενειακής κατάστασης (
Έγγαμος, Άγαμος, Διαζευγμένος), επαγγελματικής κατάστασης κ.τ.λ.
Οι ποσοτικέςμεταβλητέςείναι αυτές πο δέχονται αριθμητική μέτρηση. Με
την σειρά τους χωρίζονται σε άλλες δύο υποκατηγορίες : στις συνεχείς και στις
ασυνεχείς. Συνεχείς ονομάζουμε εκείνες οι οποίες μπορούννα πάρουν τις τιμές
ενός διαστήματος πραγματικών αριθμών, και απαντούν σε ερωτήματα όπως
ύψος , μισθός, κιλά και άλλα. Αντίθετα, ασυνεχείς ονομάζουμε εκείνες οι οποίες
μπορούν να πάρουν ακέραιες μεταβλητές και απαντούν σε ερωτήματα όπως
αριθμό σπιτιών, αριθμό παιδιών και αλλά.
Μια άλλη μελέτη αυτών των δεδομένων μας δίνει αρκετά χρήσιμα στοιχεία
όπως είναι τα μέτρα θέσης και τα μέτρα διασποράς. Μερικά από τα κυριότερα
μέτρα θέσης, όπως η μέση τιμή ή η διάμεσος των μεταβλητών μας ,μας δίνουν
χρήσιμες πληροφορίες για το φάσμα του δείγματος μας. Από την άλλη , το
εύρος, η διακύμανση , η τυπική απόκλιση και ο συντελεστής μεταβολής μας
δίνουνακόμα περισσότερα στοιχεία σχετικά με την κατανομή των μεταβλητών
μας γύρω από την κεντρική τιμή του δείγματος μας. Τα μέτρα θέσης αλλά και
διασποράς περιγράφουν λίγο πολύ τη περιγραφική στατιστική και είναι μια
απλή μέθοδος ελέγχου των μεταβλητών , αλλά ταυτόχρονα αρκετά
9.
8
χρήσιμη για τηνεξαγωγή συμπερασμάτων
Στην σύγχρονη στατιστική, παρ’ όλα αυτά , για την απόρροια
συμπερασμάτων μπορεί να γίνει με τον έλεγχο υποθέσεων και την εύρεση
διαστημάτων εμπιστοσύνης. Ο έλεγχος υποθέσεων ανήκουν στην επαγωγική
στατιστική ή Στατιστική συμπερασματολογίας και όπως αντιλαμβανόμαστε και
από την ονομασία της σκοπόςτης είναι να καταλήξουμε σε συμπεράσματα μέσα
από την απόρριψη ή την αποδοχή υποθέσεων βάση των στοιχείων- μεταβλητών
που μελετάμε, όπως επίσης και η πιθανότητα εύρεσης σωστών αποτελεσμάτων
μέσα σε ένα συγκεκριμένο πλαίσιο.
10.
9
1.2Εισαγωγή για τοR
1.2.1 Γενικές πληροφορίες για το πρόγραμμα
Tο R είναι μια πλατφόρμα την οποία την χρησιμοποιούν για την επεξεργασία
υπολογισμών, γραφημάτων και την εφαρμογή στατιστικών τεχνικών. Οι
δυνατότητες του είναι τεράστιες μίας και ο χρήστης έχει την δυνατότητα να
χρησιμοποιεί έτοιμα προγράμματα τα οποία είναι ενσωματωμένα μέσα σε
πακέτα ή μπορεί να προγραμματίσει και ο ίδιος για την επίλυση πολύπλοκων
προβλημάτων. Η γλώσσα πάνω στην οποία ο χρήστης μπορεί να
προγραμματίσει είναι μια διάλεκτος της S. Αν και το R με την S δεν είναι
απόλυτα συμβατά μεταξύ τους, μπορεί και τρέχει στο R χωρίς καμία αλλαγή.
Στην S οι εντολές αφού διαβαστούν εκτελούνται αμέσως κάτι το οποίο δεν
συμβαίνει στη γλώσσα Fortran. Ένα χαρακτηριστικότων διερμηνέων γλωσσών
,όπως είναι η S,είναι ότι επιτρέπουν την σταδιακή ανάπτυξη. Πιο αναλυτικά, ο
χρήστης δημιουργεί μια συνάρτηση ,την εκτελεί και μετά έχει την δυνατότητα
να δημιουργήσει μια καινούρια η οποία χρησιμοποίει και την πρώτη. Τέλος,ένα
από τα πλεονεκτήματα του R είναι ότι μπορεί να αποκτηθεί δωρεάν ,μέσα από
τις ιστοσελίδες http:/www.r-project.org και http:/www.cran.r-project.org .
11.
10
1.2.2 Γνωριμία μετο περιβάλλον
Τα τελευταία περίπου δέκα χρόνια το R έχει γίνει ένα από τα πιο σημαντικά
στατιστικά εργαλεία. Υπολογίζεται μάλιστα ότι πάνω από τρία εκατομμύρια
χρηστές το χρησιμοποιούν τόσο στην ακαδημαϊκή κοινότητα όσο και στον
επαγγελματικό τομέα. Το περιβάλλοντου είναι απλό. Ανοίγονταςτο πρόγραμμα
εμφανίζεται η βασική οθόνη στην οποία βρίσκεται το παράθυρο των εντολών
και η γραμμή εργαλείων.
Πατώντας το κουμπί “file” να μπορούμε να κάνουμε μια σειρά από βασικές
ενέργειες. Αρχικά, μπορούμε να εισάγουμε κώδικα και γενικότερα εντολές από
προηγούμενεςαναλύσεις και εφαρμογές μας. Αυτό επιτυχαίνεται με το source R
code. Μια πολύ σημαντική επιλογή που μας δίνει το πρόγραμμα είναι το “new
script”. Εδώ μπορούμε να γράψουμε τις εντολές που θέλουμε να εκτελέσουμε.
12.
11
Μαυρίζονταςαυτές πουθέλουμε νατρέξουμε και πατώντας με δεξί κλικ πάνω
στον συντάκτη επιλεγούμε το run line ή selection.Μπορούμε να ανοίξουμε έναν
παλιό συντάκτη με το “openscript” και να δούμε τα αρχεία R που μπορούμε να
χρησιμοποιήσουμε του φακέλου που βρισκόμαστε με το “display
file(s)”.Μπορούμε να φορτώσουμε και να αποθηκεύσουμε χώρο εργασίας
(load/save workspace) όπως και να φορτώσουμε ή να αποθηκεύσουμε εντολές
που έχουμε χρησιμοποιήσει στο παρελθόν(load/save history).Με την επιλογή
“change dir” μπορούμε να αλλάξουμε τον φάκελο εργασίας μας. Tέλος,
μπορούμε να εκτυπώσουμε (print) να αποθηκεύσουμε ν δουλειά μας σε μορφή
txt (save to file) και να τερματίσουμε το πρόγραμμα (exit)
13.
12
Στο menu Editμας παρέχετε η δυνατότητα της αντιγραφής(copy),επικόλλησης
(paste), της επιλογής όλων όσων έχουμε πληκτρολογήσει(select all) πχ εντολές,
όπως επίσης και το να καθαρίσομε το παράθυροτων εντολών. Τέλος, μπορούμε
κάνοντας κλικ πάνω στο “data editor” και “GUI preferences” να ανοίξουμε
έναν συντάκτη δεδομένων για τα δεδομένα που είναι υπό τη μορφή πλαισίου
δεδομένων και να τα επεξεργαστούμε και να αλλάξουμε το πώς φαίνεται το
περιβάλλον στο όποιο δουλεύουμε αντίστοιχα.
14.
13
Στο “View” μπορούμενα την εμφανίσουμε ή όχι το την μπάρα τα βασικά
εργαλεία δουλειάς(toolbar) από το περιβάλλον εργασίας όπως επίσης και τις
πληροφορίες για την έκδοση του προγράμματος πουχρησιμοποιείτε (statusbar).
Πατώντας το κουμπί “misc”μπορούμε να σταματήσουμε το τρέχον πρόγραμμα
(stop current computations) ή όλα τα προγράμματα που εκτελούνται(stop all
computations).Επίσης, έχουμε την δυνατότητα να σταματήσουμε την εκτύπωση
των αποτελεσμάτων στην οθόνη(buffered output), να δούμε όλα τα αντικείμενα
και τις αναλύσεις που έχουμε κάνει (list objects) και να τα διαγράψουμε
(remove all objects). Τέλος , να δούμε τις βιβλιοθήκες(libraries) και τα πλαίσια
(data frames) που υπάρχουν στο περιβάλλον εργασίας μας.
15.
14
Από το μενούpackages ο χρήστης μπορεί να φορτώσει βιβλιοθήκες που ειδή
υπάρχουν(load packages), να κατεβάσει και να εγκαταστήσει βιβλιοθήκες από
πρότυπα CRAN(install package(s)),να εγκαταστήσει από zip αρχεία μέσα από
τον σκληρό του δίσκο (install package(s) from local zip files) και να τις
ενημερώσει με πιο πρόσφατες εκδοχές τους. Τέλος ο χρήστης μπορεί να
επιλέξει από πιο μέρος του κόσμου θα κατεβάσει μέσω των προτύπων CRAN
τις βιβλιοθήκες(set CRAN mirror) και να επιλέξει ,περά από το CRAN, από
ποιόν διανομέα θέλει να τις κατεβάσει(set repositories).
16.
15
Με το μενούwindows μπορεί κάποιος να μετακινηθεί μεταξύ των παραθύρων
των οποίων χρησιμοποίει εκείνη την στιγμή. Επίσης μπορεί να τα τοποθετήσει
όπως επιθυμεί είτε κάθετα(Tile Vertically ) είτε οριζόντια( Tile Horizontally).
17.
16
Από το μενούHelp ο χρήστης μπορεί να βοηθήσει για όλες τις ιδιότητες του
πακέτου. Πιο αναλυτικά:
Στο Console υπάρχουν πληροφορίες για την βασική οθόνη του
προγράμματος R.
Στα FAQ on R,FAQ on R for Windows υπάρχουν απαντήσεις σε
ερωτήσεις που γίνονται συχνά για την R.
Στο Manuals (in PDF) έχουμε το βασικό εγχειρίδιο χρήσης της R σε
PDf.
Στο R functions(text) έχουμε πληροφορίες για τις ήδη υπάρχουσες
εντολές της R.
Με το Html help μεταφερόμαστε σε έναν διαδικτυακό τόπο όπου μας
παρέχει πληροφορίες για το πρόγραμμα μας.
Από το Search help μπορούμε να ψάξουμε όποιο αρχείο επιθυμούμε να
βρούμε .
Στο Search.r-project.org μπορούμε να αναζητήσουμε όποιον σύνδεσμο
στο διαδίκτυο θέλουμε.
Από το Apropos μπορούμε να αναζητήσουμε εντολές που είναι ήδη
φορτωμένες στην R.
Από το R project home page μεταφερόμαστε στην ιστοσελίδα της R.
Από το CRAN home page μεταφερόμαστε στην ιστοσελίδα της CRAN.
About μας παρέχει πληροφορίες για τα δικαιώματα και την τρέχον
έκδοση του πακέτου μας.
18.
17
1.2.3 Εισαγωγή Δεδομένωνστο Πρόγραμμα
Το R όντας ένα πρόγραμμα με πολλές δυνατότητες σου παρέχει την δυνατότητα
να του φορτώσεις δεδομένα από πολλούς διαφορετικούς τύπους αρχείων. Με
την χρήση διαφορετικών βασικών εντολών μπορούμε να εισάγουμε δεδομένα
από τους εξής τύπους αρχείων: Excel,Minitab,SPSS,Table,CSV, Stata, systat .
Πιο αναλυτικά, αρκετά συχνά τα δεδομένα μας είναι σε μορφή Excel. Για να
τα εισάγου στο R χρησιμοποιούμε την εντολή data<-read.xls(“data.xls”), όπου
με το “data<-” εισάγουμε την τιμή μας στο αντικείμενο data. Επίσης πολύ
σημαντικό είναι το ότι άμα δεν το αρχείο μας δεν βρίσκεται στον ίδιο φάκελο
με το πρόγραμμα μας τότε μέσα στην παρένθεση θα πρέπει να γράψουμε το
μονοπάτι της ακριβής τοποθεσίας του αρχείου μας .Για παράδειγμα αν τα
19.
18
δεδομένα μας είναιστο σκληρό δίσκο C στον φάκελο παράδειγμα τότε η εντολή
που θα πρέπει να γράψουμε θα είναι η εξής
data<-read.xls ("C:παράδειγμαdata.xlsx").
Εάν τα δεδομένα μας είναι σε μορφή Minitab ο τρόπος διαβάσματος του
αρχείου θα είναι ο ίδιος με μια μικρή διαφορά. Θα γράψουμε data<-
read.mtp(“data.mtp”) και σε περίπτωση πουτο αρχείο μας είναι σε διαφορετικό
φάκελο θα πράξουμε με τον ίδιο τρόπο .Χρησιμοποιώντας το προηγούμενο
παράδειγμα θα έχω : data<-read.mtp("C:παράδειγμαdata.mtp")
Με τον ίδιο τρόπο περνάμε τα δεδομένα στο πρόγραμμα μας με την μόνη
διαφορά τα τελειώματα τα όποια θα αντιστοιχούν στον τύπο του αρχείου που
είναι αποθηκευμένα. Αν είναι αποθηκευμένα σε αρχείο SPSS τότε θα έχω
data<- read.spss(“data.spss”),αν είναι σε αρχείο table ή csv ή Stata ή systat
θα έχω data<-read.table(“data.txt”) ,data<- read.csv(“data.csv”), data<-
read.dta(“data.dta”) και data<- read.systat(“data.dta”)αντίστοιχα.
Τέλος, στην συγκεκριμένη εργασία θα σας δείξουμε πώς εισάγουμε τα
δεδομένα μας χωρίς να τα διαβάσουμε από κάποιο άλλο αρχείο(
1.2.4Αποθήκευση και επανάκτηση δεδομένων
Μια άλλη δυνατότητα που μας προσφέρει το R είναι η αποθήκευση των
αντικειμένων. Για την αποθήκευση τους χρησιμοποιούμε την εντολή
save(data, file=”data.Rdata”, ascii=TRUE)
όπου το data είναι το όνομα του αρχείου μας και οπου το data.Rdata είναι το
όνομα του φάκελου που θα αποθηκευτεί.H παράμετρος “ascii=TRUE” είναι
προαιρετική στην περίπτωση που θέλουμε να χρησιμοποιήσουμε το
αποθηκευμένο αντικείμενο και σε αλλά στατιστικά πακέτα.
1.2.5 Συχνά προβλήματα και αντιμετώπιση τους
Τα προβλήματα τα οποία μπορεί να αντιμετωπίσει κάποιος στο πρόγραμμα R
δεν είναι πολλά. Οι λύσεις αυτών των προβλημάτων βρίσκονται σχετικά
20.
19
εύκολα, κάτι πουκάνει το πρόγραμμα ακόμα πιο αξιόπιστο και λειτουργικό.
Τα πιο συνήθη λάθη-προβληματα που μπορεί να αντιμετωπίσει κάποιος
είναι αυτά της ορθογραφίας. Το πρόγραμμαR είναι ευαίσθητο σε κεφαλαία και
μικρά γράμματα και όπως γίνεται αντιληπτό καμία εντολή δεν θα
πραγματοποιηθεί αν δεν έχει διατυπωθεί με τον σωστό τρόπο. Ακόμα πιθανό
είναι να έχει δοθεί στο πρόγραμμα κάποια εντολή αλλά με κάποιο λάθος
γράμμα η συμβολισμό. Στις δύο αυτές περιπτώσεις το πρόγραμμα βγάζει ένα
μήνυμα λάθους (error) βοηθώντας έτσι τον χρήστη να καταλάβει ποίο
ακριβώς είναι το πρόβλημα.
Παρ’ όλα αυτά, τα λάθη λογικής είναι αυτά τα οπoία δυσκολεύουν
περισσότεροαπό αυτά της ορθογραφίας . Συχνά στο πρόγραμμα γίνεται χρήση
εντολών οι οποίες μπορεί να είναι σωστές αλλά να μας δίνουν διαφορετικό
αποτέλεσμα από αυτό που θέλουμε ή από αυτό που περιμέναμε να δούμε. Τα
λάθη λογικής είναι συχνό φαινόμενο στις γλώσσες προγραμματισμού και το R
δεν αποτελεί εξαίρεση. Ο χρήστης θα πρέπει να είναι ιδιαίτερα προσεκτικός
ώστε να έχει το επιθυμητό αποτέλεσμα.
Τέλος, υπάρχουνκαι τα ανθρώπιναλάθη όπως η λάθος καταχώριση αρχείων
,η ονομασία εvός αρχείου με το ίδιο όνομα με ενός άλλου ή η χρησιμοποίηση
λάθος βιβλιοθήκης(package).
21.
20
1.3Τελεστές
1.3.1 Τελεστές Εκχώρησηςκαι Σύγκρισης
Με τους Τελεστές εκχώρησης όπως μας προϊδεάζει και η λέξη έχουμε την
δυνατότητα να δώσουμε τιμές σε αντικείμενα και μεταβλητές .Οι Τελεστές
σύγκρισης μας βοηθούν στο να συγκρίνουμε δυοτιμές. Αυτοί οι Τελεστές είναι
οι πιο κάτω.
Τελεστής Ιδιότητα
<- Το αριστερό μέρος της σχέσης μας παίρνει την τιμή
-> Το δεξί μέρος της σχέσης μας παίρνει την τιμή
< Μεγαλύτερο
> Μικρότερο
<= Μικρότερο ή ίσο
>= Μεγαλύτερο ή ίσο
!= Όχι ίσο
== Ίσο
1.3.2 Αριθμητικοί Τελεστές
Με αυτούς τους Τελεστές μπορούμε να εκτελέσουμε τις βασικές αριθμητικές
πράξεις- λειτουργιές , δηλαδή, πρόσθεση ,αφαίρεση, πολλαπλασιασμός όπως
και να υψώσουμε έναν αριθμό σε δύναμη .Πιο αναλυτικά:
Σύμβολα Πράξη
+ Πρόσθεση
- Αφαίρεση
* Πολλαπλασιασμός
/ Διαίρεση
^ Ύψωση σε δύναμη
%/% Ακέραια Διαίρεση
%% Υπόλοιπο Διαίρεσης
23
2.1 Εύρεση Μέσου,Διάμεσου και επικρατούσας τιμής
Στο συγκεκριμένο παράδειγμα θα ασχοληθούμε με την εύρεση Μέσου
,Διάμεσου και επικρατούσας τιμής ταχυτήτων διερχόμενων αυτοκίνητων.
Όπως αναφέραμε και στο πρώτο κεφάλαιο με την εντολή read.csv εισάγουμε τα
δεδομένα μας. Με το “kef4<-“ εισάγουμε την τιμή μας στο αντικείμενο
kef4,κάτι το οποίο θα μας φανεί πολύ χρήσιμο στην συνέχεια για την αποφυγή
λαθών. Τα αρχεία CSV χωρίζονται μεταξύ τους με κόμμα και οι περισσότερες
ασκήσεις έχουν και τίτλους. Για παράδειγμα όπως θα δούμε σε αυτήν την
άσκηση έχουμε τον τίτλο Speeds.Γι αυτό τον λόγο θα πρέπει στην εισαγωγή
των δεδομένων μας να το επισημάνουμε με κάποιους παραμέτρους . Πιο
αναλυτικά, για τον λόγο που τα δεδομένα μας χωρίζονται με κόμμα θα πρέπει
να βάλουμε την παράμετρο <<sep=”,”>>.Το “sep” βγαίνει από την αγγλική
λέξη separated που σημαίνει χωρίζονται το οποίο το βάζουμε να ισούται με το
κόμμα. Με την παράμετρο <<header=T>>,όπου “T” βγαίνει από την αγγλική
λέξη TRUE που σημαίνει αλήθεια και “header” σημαίνει Τίτλος, ορίζουμε ότι
στα δεδομένα μας υπάρχει τίτλος για να είναι σε θέση να τον διαβάσει. Επίσης
,θα πρέπει να δηλώσουμε την ακριβή τοποθεσία του αρχείου που θέλουμε να
εισάγουμε.
Τέλος, με την εντολή str και στην περίπτωση αυτής της άσκησης str(kef4)
βλέπουμε τα δεδομένα που έχουμε εισάγει.
Για να βρούμε τον μέσο χρησιμοποιούμε την εντολή “mean” που βγαίνει από
την αγγλική λέξη mean και σημαίνει “μέσος”. Στην συνέχεια, ανοίγουμε
παρένθεση και βάζουμε το όνομα του αντικειμένου που του εισάγαμε την τιμή
κατά το διάβασμα”kef4”. Μετέπειτα χρησιμοποιούμε το σύμβολο “$”και μετά
εισάγουμε το όνομα της μεταβλητής που μας ενδιαφέρει. Στην περίπτωση της
25.
24
άσκησης μας “Speeds”.Τοαποτέλεσμα που εμφανίζεται στην οθόνη
[1]3290833 είναι ο μέσος των 120 παρατηρήσεων της άσκησης μας.
Για να βρούμε την διάμεσο χρησιμοποιούμε την εντολή “median” που βγαίνει
από την αγγλική λέξη median και σημαίνει “διάμεσος”. Στην συνέχεια,
ανοίγουμε παρένθεση και βάζουμε το όνομα του αντικειμένου που του
εισάγαμε την τιμή κατά το διάβασμα”kef4”. Μετέπειτα χρησιμοποιούμε το
σύμβολο “$”και μετά εισάγουμε το όνομα της μεταβλητής που μας ενδιαφέρει.
Στην περίπτωση της άσκησης μας “Speeds”.Το αποτέλεσμα που εμφανίζεται
στην οθόνη [1]32 είναι η διάμεσος των 120 παρατηρήσεων της άσκησης μας.
Για την επικρατούσα τιμή χρησιμοποιώ την εντολή <<table>> ,αφού πρώτα
την εισάγουμε ένα νέο αντικείμενο που θα έχει ένα όνομα που θα τα έχουμε
ορίσει εμείς, στην περίπτωση μας “ep.timh”. Μετά ανοίγουμε παρένθεση και
γράφουμε την εντολή <<as.vector>> και μέσα σε μια καινούρια παρένθεση το
πρώτο αντικείμενο που είχαμε δηλώσει κατά το διάβασμα “kef4”.Tέλος
κλείνουμε τις παρενθέσεις και πατάμε “enter”.Τέλος ,γράφουμε το όνομα του
νέου μας αντικειμένου και μας εμφανίζει το από κάτω πίνακα.
26.
25
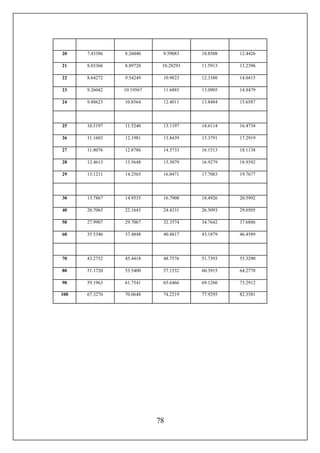
Στον πίνακα παρατηρούμεότι έχουμε δυο σειρές. Στην πάνω σειρά,
εμφανίζονται οι ταχύτητες των διερχομένων αυτοκίνητων που έχουμε στα
δεδομένα μας. Στην δεύτερη,βλέπουμε κάποιους αριθμούς ,στο συγκεκριμένο
παράδειγμα οι τιμές τους κυμαίνονται από1 ως και 8. Αυτές οι τιμές μας
σηματοδοτούνπόσες φορέςη κάθε ταχύτητα έχει εμφανιστεί. Για παράδειγμα η
ταχύτητα εξήντα 60 έχει εμφανιστεί μόνο μια (1) φορά, ενώ η εξήντα οκτώ(68)
έχει εμφανιστεί δυο(2).Ηταχύτητα εκείνη που έχει εμφανιστεί τις περισσότερες
φορές ,είναι και η επικρατούσα τιμή. Μιλώντας με τις τιμές της άσκησης,
έχουμε δύο επικρατούσεςτιμές, την ενενήντα οκτώ(98)και την εκατόν δυο(102)
οι οποίες παρουσιάστηκαν οκτώ φορές η κάθε μια.
2.2 Εύρεση τυπικής απόκλισης και διασποράς
Στο συγκεκριμένο παράδειγμα θα ασχοληθούμε με την εύρεση της τυπικής
απόκλισης και της διασποράς του αριθμού των αφίξεων των πελατών στα
ταμεία του καταστήματος .
Αρχικά, καταχωρούμετα δεδομένα μας όπως γνωρίζουμε και χρησιμοποιούμε
την εντολή <<str>>για να δούμε τα δεδομένα μας.
Για να βρούμε την τυπική απόκλιση χρησιμοποιούμε την εντολή “ sd “που
βγαίνει από τις αγγλικές λέξεις standart deviation και σημαίνει “τυπική
απόκλιση”. Στην συνέχεια, ανοίγουμε παρένθεση και βάζουμε το όνομα του
αντικειμένου που του εισάγαμε την τιμή κατά το διάβασμα”kef4”. Μετά
χρησιμοποιούμε το σύμβολο “$”και στην συνέχεια εισάγουμε το όνομα της
μεταβλητής που μας ενδιαφέρει. Στην περίπτωση της άσκησης μας
“Arrivals”.Το αποτέλεσμα που εμφανίζεται στην οθόνη [1]1500639 είναι η
τυπική απόκλιση των 150 παρατηρήσεων της άσκησης μας.
27.
26
Για να βρούμετην διασπορά χρησιμοποιούμε την εντολή “var”που βγαίνει από
την αγγλική λέξη variance και σημαίνει “διασπορά”. Στην συνέχεια, ανοίγουμε
παρένθεση και βάζουμε το όνομα του αντικειμένου που του εισάγαμε την τιμή
κατά το διάβασμα”kef4”. Μετά χρησιμοποιούμε το σύμβολο “$”και στην
συνέχεια εισάγουμε το όνομα της μεταβλητής που μας ενδιαφέρει. Στην
περίπτωση της άσκησης μας “Arrivals”.Το αποτέλεσμα που εμφανίζεται στην
οθόνη [1]2251918 είναι η διασπορά των150 παρατηρήσεωντης άσκησης μας.
2.3 Εύρεση Τεταρτημόριων
Στο επόμενο παράδειγμα εξετάζουμε τουςχρόνους δέσμευσης των τραπεζιών
,μιας καφετέριας, διακοσίων ομάδων πελατών σε ένα εστιατόριο
Αρχικά, καταχωρούμετα δεδομένα μας όπως γνωρίζουμε και χρησιμοποιούμε
την εντολή <<str>> για να τα δούμε.
28.
27
Για να βρούμετα τεταρτημόρια χρησιμοποιούμε την εντολή “quantile” που
βγαίνει από την αγγλική λέξη quartile και σημαίνει “τεταρτημόριο”. Στην
συνέχεια, ανοίγουμε παρένθεση και βάζουμε το όνομα του αντικειμένου που
του εισάγαμε την τιμή κατά το διάβασμα”kef4”. Μετά χρησιμοποιούμε το
σύμβολο “$”και στην συνέχεια εισάγουμε το όνομα της μεταβλητής που μας
ενδιαφέρει. Στην περίπτωση της άσκησης μας “Times”.Το αποτέλεσμα που
εμφανίζεται στην οθόνη μας είναι ο χρόνος δέσμευσης των τραπέζιων της
καφετέριας ,με βάση τα τεταρτημόρια, των 200 πελατών μας.
Αναλύοντας το αποτέλεσμα της εντολής quantile(kef4$Times)βλέπουμε ότι
εμφανιστήκαν το πρώτο ,το δεύτερο, το τρίτο και τέταρτο τεταρτημόριο.
Βλέπουμε πως το πρώτο έχει ελάχιστη τιμή το 21(0% )και μέγιστη 26(25%). Εν
συνεχεία ,το δεύτεροτεταρτημόριο έχει ελάχιστη τιμή το 26(25%),δηλαδή την
μεγίστη του προηγούμενου και μεγίστη το 28.5(50%). Οι τιμές του τρίτου
κυμαίνονται από το 28,5(50%) μέχρι και το 32(75%). Τέλος, το τέταρτο
τεταρτημόριο έχει τιμές από το 32(75%) μέχρι και το 55(100%). Αυτό που
παρατηρούμε είναι ότι το 50% των πελατών δεσμεύει ένα τραπέζι από 32 έως
και 55 λεπτά. Επίσης, μια άλλη παρατήρηση που μπορούμε να κάνουμεείναι ότι
μεταξύ του τρίτου και τέταρτου η διαφορά είναι πολύ μεγάλη σε αντίθεση με
την διαφορά των άλλων δυο τεταρτημορίων.
29.
28
2.4 Εύρεση συχνοτήτων,σχετικών συχνοτήτων ,δημιουργία πίτας
και ιστογράμματος
Στο συγκεκριμένο παράδειγμα θα ασχοληθούμε με την εύρεση συχνοτήτων,
σχετικών συχνοτήτων αλλά και με την δημιουργία ιστογράμματος και
δημιουργία πίτας.
Αρχικά, περνάμε τα δεδομένα μας. Επειδή, το αρχείο μας είναι csv ,όπως είχαμε
πει και στο προηγούμενο κεφάλαιο θα γράψουμε read.csv και το μονοπάτι που
βρίσκεται το αρχείο μας μέσα στην παρένθεση. Στην συνέχεια, με την εντολή str
βλέπουμε τα δεδομένατα οποία εισάγαμε με την προηγούμενο διάβασμα μας.
Η δυνατότητα αλλαγής ονομάτων είναι σημαντική γιατί μας δίνει την
δυνατότητα καλύτερης κατανόησης της άσκησης ,αποφυγήςσημαντικών λαθών
και είναι και οπτικά πιο όμορφη. Για να μπορέσουμε να αλλάξουμε το όνομα
που θα φαίνεται στα διαγράμματα μας θα πρέπει ,πρώτα, να δηλώσουμε την
στήλη στην οποία θέλουμε να αλλάξουμε τα ονόματα των δεδομένων της ως
χαρακτήρα. Αυτό το κάνουμε με την εντολή x$Brand<-as.character(x$Brand).
Εν συνεχεία, με την εντολή x$Brand[x$Brand == “1”] <-“bud light” το
πρόγραμμα αυτόματα ψάχνει στην στήλη Brand και όποιος χαρακτήρας είναι
ίσος με το ένα τον άσσο του δίνει το όνομα bud light(για το συγκεκριμένο
παράδειγμα). Με τον ίδιο τρόπο, αλλάζοντας όμωςκάθε φορά το όνομα που θα
πρέπει να βρει το πρόγραμμα και το νέο που θα πάρει την θέση του μπορούμε
να αλλάξουμε τα ονόματα (όπως βλέπουμε και ποιο κάτω).
30.
29
2.4.1Εύρεση Συχνοτήτων καιΣχετικών Συχνοτήτων
Η εντολή attach() είναι μια πολύ απλή εντολή αλλά στην ουσία πάρα πολύ
χρήσιμη. Με αυτήν μπορούμε να “μπούμε”μέσα στον αρχείο x και να κάνουμε
όποια ενέργεια θέλουμε χωρίς να χρειαστεί να το ξαναγράψουμε (θα την δούμε
πιο αναλυτικά και στο παράδειγμα 2.6)
Με το table() το R μας βγάζει τον πίνακα των συχνοτήτων. Με την αλλαγή που
κάναμε πριν στα ονόματα ο πίνακας εμφανίζεται όπως τον βλέπουμε από κάτω,
βοηθώνταςμας έτσι να καταλάβουμε ακριβώςσε ποιο τύπο μπύρας ανήκουν οι
τιμές.
Παρατηρούμεότι οι περισσότεροι τελειόφοιτοι προτιμούντην μπύρα bud light,
δεύτερηκαι τρίτη επιλογή του είναι η coors light και miller light αντίστοιχα ενώ
στο τέλος βρίσκεται η Michelob light.
31.
30
Για να εμφανίσουμετον πίνακα των σχετικών συχνοτήτωνπληκτρολογούμε την
εντολή prop.table(s.suxnothtwn). Πριν από αυτό όμως θα πρέπει για δική μας
διευκόλυνση να δώσουμε σε ένα όνομα της δικής μας επιλογής( στο
συγκεκριμένο παράδειγμα s.suxnothtwn) την τιμή από τη δημιουργία του
πίνακα συχνοτήτων, δηλαδή, table(Brand).
Στην περίπτωση που θέλουμε τον πίνακα σχετικών συχνοτήτων μας
πολλαπλασιασμένο επί τοις %,δεν μένει παρά να γράψουμε την ίδια εντολή με
την προηγούμενη αλλά πολλαπλασιασμένη με το 100. Δηλαδή,
prop.table(s.suxnothtwn)*100
32.
31
2.4.2Δημιουργία Πίτας καιΙστογράμματος
Για να δημιουργήσουμε μια Πίτα η εντολή που θα χρειαστεί κάποιος είναι η
pie(). Μέσα στην παρένθεση αρχικά μπαίνει το όνομα για τις τιμές του οποίου
θέλουμε να δημιουργήσουμε την πίτα(στο παράδειγμα μας piechart, μιας και το
έχουμε ορίσει με αυτό το όνομα δύο εντολές πιο πάνω). Μετά δηλώνουμε τα
ονόματα που θα έχει μέσα η πίτα μας . Εδώ , έχουμε ορίσει με το όνομα lbls τις
τιμές και τα ονόματα που θα έχει στην προηγούμενη εντολή . Τέλος, είναι η
περιγραφή για την πίτα που φτιάχνουμε.Η εντολή για τη δημιουργία μια τέτοιας
πίτας, όπως το βλέπουμε και παρακάτω, είναι pie(piechart, labels=lbls, main=
“Pie chart of Speciesn(with sample sizes)”).
33.
32
Το κυκλικό διάγραμμαή πίτα, απεικονίζει ποσοστά. Όπως μπορούμε να δούμε
περίπου το ένα τρίτο των τελειοφοίτων προτιμούν την μπύρα Bud Light με
ποσοστό 31.6%. Ενώ ακολουθούν με ποσοστό 21.8% και 20.7% οι μπύρες
Coors και Miller αντίστοιχα.
34.
33
Στην περίπτωση πουκάποιος θέλει να δημιουργήσει ένα κυκλικό διάγραμμα
αλλά σε τρισδιάστατη μορφή θα πρέπει για αρχή να κατεβάσει και να
εγκαταστήσει την βιβλιοθήκη (package) με την ονομασία plotrix, έτσι ώστε να
μπορέσει το πρόγραμμα να εμφανίσει το διάγραμμα με την μορφή που το
θέλουμε. Αν δεν φορτωθεί η συγκεκριμένη βιβλιοθήκη ,το R, θα βγάλει μήνυμα
λάθους. Η εντολή που θα χρειαστούμε για το τρισδιάστατο κυκλικό διάγραμμα
είναι pie3D(). Μέσα στην παρένθεση όπωςκαι πριν τοποθετούμε το όνομα για
του οποίου τις τιμές θέλουμε να δημιουργήσουμε τη πίτα, τα ονόματα που θα
έχει το διάγραμμα. Η μόνη διαφορά είναι ότι του ορίζουμε το ύψος που
θέλουμε να έχει το διάγραμμα μας από το explode(στο συγκεκριμένο
παράδειγμα explode=0.1)
35.
34
Για να δημιουργήσουμεένα ραβδόγραμμα δεν μένει παρά να γράψουμε την
εντολή barplot(), όπου μέσα στην παρένθεση μπαίνει το όνομα για του οποίου
τις τιμές θέλουμε να φτιάξουμε το συγκεκριμένο παράδειγμα.
Το ραβδόγραμμααναπαριστά τουςαπόλυτουςαριθμούς.Όπως παρατηρούμε οι
περισσότεροι τελειόφοιτοι προτιμούν την μπύρα Bud και ακολουθούνοι μπύρες
Coors και Miller, ενώ τελευταία επιλογή τους θα ήταν η μπύρα Michelob.
Στην περίπτωση που κάποιοςθέλει να δημιουργήσει ένα ραβδόγραμμα αλλά με
τους ράβδους να είναι οριζόντια, τότε, το μόνο που πρέπει να κάνει είναι να
γράψει την ίδια εντολή με πριν, με την μόνη διαφορά ότι θα πρέπει να του
ορίσουμε ότι το θέλουμε να είναι σε οριζόντια μορφή. Αυτό το καταφέρνουμε
με το horiz= T. Το horiz βγαίνει από την αγγλική λέξη horizontally και σημαίνει
οριζόντια και το βάζουμε να ισούται με T δηλαδή True(αλήθεια).
36.
35
2.5 Χρονοσειρά
Στο αυτότο παράδειγμα θα μετατρέψουμε μια αριθμητική συνάρτηση σε
αντικείμενο χρονοσειράς και θα δημιουργήσουμε ένα ραβδόγραμμα που θα
παρουσιάζει τις τιμές της βενζίνης.
Αρχικά, καταχωρούμετα δεδομένα μας όπως γνωρίζουμε και χρησιμοποιούμε
την εντολή <<str>>για να δούμε τα δεδομένα μας.
Με την εντολή ts() θα μετατρέψουμε την αριθμητική συνάρτηση σε ένα
αντικείμενο χρονοσειράς. Η μορφή της είναι ts(start=,end=, frequency=) όπου
το start και το end είναι η πρώτη και η τελευταία παρατήρηση και frequency
37.
36
είναι ο αριθμόςτων παρατηρήσεων ανά μονάδα χρόνου( 1=ετησία, 4= τρίμηνη,
12= μηνιαία, κλπ.)
Για να δημιουργήσει κανείςένα γραμμικό διάγραμμα μπορεί να το κάνει με την
εντολή plot.ts(). Μέσα στην παρένθεση μπαίνει το όνομα που έχουμε θέσει
εμείς για τα δεδομέναμας και το όνομα για τις τιμές που θέλουμε να φτιάξουμε
το συγκεκριμένο διάγραμμα.
38.
37
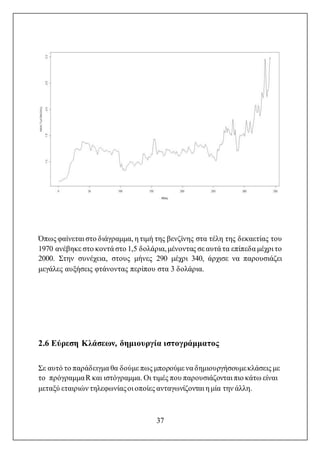
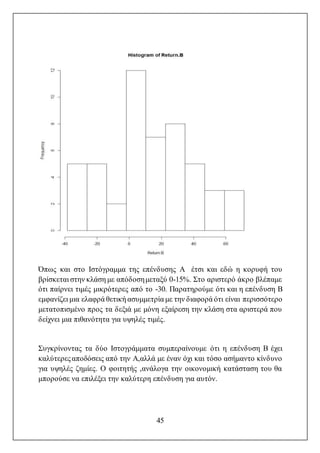
Όπως φαίνεται στοδιάγραμμα, η τιμή της βενζίνης στα τέλη της δεκαετίας του
1970 ανέβηκε στο κοντά στο 1,5 δολάρια,μένοντας σε αυτά τα επίπεδα μέχρι το
2000. Στην συνέχεια, στους μήνες 290 μέχρι 340, άρχισε να παρουσιάζει
μεγάλες αυξήσεις φτάνοντας περίπου στα 3 δολάρια.
2.6 Εύρεση Κλάσεων, δημιουργία ιστογράμματος
Σε αυτό το παράδειγμα θα δούμε πως μπορούμε να δημιουργήσουμεκλάσεις με
το πρόγραμμαR και ιστόγραμμα. Οι τιμές που παρουσιάζονται πιο κάτω είναι
μεταξύ εταιριών τηλεφωνίαςοι οποίες ανταγωνίζονται η μία την άλλη.
39.
38
Αρχικά, καταχωρούμετα δεδομέναμας όπως γνωρίζουμε και χρησιμοποιούμε
την εντολή <<str>>για να δούμε τα δεδομένα μας.
Με την εντολή “Gefort=cut()”χωρίζουμε το δείγμα μας σε κλάσεις. Σε αυτό το
παράδειγμα όπουοι παρατηρήσεις μας είναι 200 και με το τύπο που δείξαμε πιο
πάνω στην παράγραφο ,χωρίζουμε το δείγμα μας σε 8 κλάσεις ,γράφοντας
“Geffort=cut(kef2$Bills, 8)”. Στην συνέχεια, με την βοήθεια της εντολής
“table()” εμφανίζουμε τον πινάκα όπου τα στοιχεία μας πλέον είναι χωρισμένα
σε ομάδες.Επίσης , σε αυτόν τον πίνακα βλέπουμε πόσες παρατηρήσεις έχει η
κάθε ομάδα.
Με την εντολή “attach()” που στα Ελληνικά σημαίνει συνάπτω καταφέρνουμε
να μπούμε μέσα στα δεδομένα του “kef2”.Για παράδειγμα, στην προηγούμενη
εντολή είχαμε γράψει “Geffort=cut(kef2$Bills, 8)”.Μπορούσαμε να
πληκτρολογήσουμε πριν από αυτόν τον τύπο το “attach(kef2)”,όποτε τώρα η
εντολή μας θα γραφόταν έτσι:
attach(kef2)
Geffort=cut(Bills, 8)
40.
39
Με αυτόν τοντρόπο γλυτώνουμε να γραφούμε το “kef2” ή όποιο άλλο όνομα
έχουμε δώσει εμείς στο αντικείμενο μας και μας γλυτώνει πολλές φορές από
απρόσεκτα λάθη. Πιο κάτω θα την δούμε την εντολή αυτή στην πράξη.
Για να δημιουργήσουμε ένα Ιστόγραμμα πρέπει να χρησιμοποιήσουμε την
εντολή “hist(Bills,breaks=bins)”.To “hist” ,βγαίνει από το histogram, δηλαδή,
ιστόγραμμα ,με το “Bills” του ορίζουμε για πια μεταβλητή μας θέλουμε να
κάνουμε το διάγραμμα αυτό και τέλος με το “break=bins” του θέτουμε τα όρια
ώστε να αλλάξει μπάρα στο διάγραμμα. Αυτό το επιτυγχάνουμε με την εντολή
“bins=seq(min(Bills),max(Bills)+15,15).To “bins” είναι όνομα που του ορίσαμε
εμείς, το “seq” βγαίνει από την αγγλική λέξη “Sequence” που σημαίνει
“ακολουθία” και μέσα σε αυτό θέτουμε το ελάχιστο(min),το μέγιστο(max) και
την διαφορά που έχουν μεταξύ τους οι κλάσεις.
41.
40
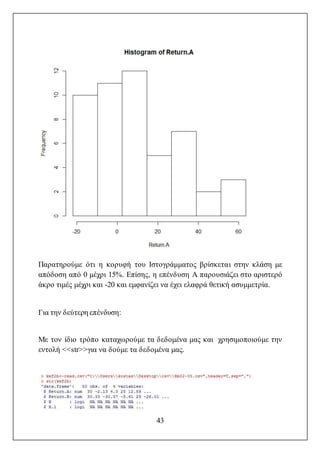
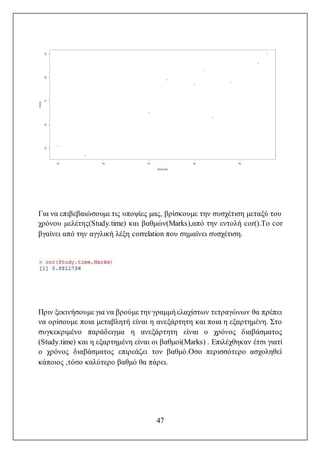
Το ιστόγραμμα μαςδίνει μια καθαρή εικόνα της κατανομής των λογαριασμών.
Οι μισοί περίπου από τους μηνιαίους λογαριασμούς αφορούν τα μικρά ποσά,
δηλαδή από 0 ως 30,λίγοι βρίσκονται στις ενδιάμεσες τιμές, από 30 μέχρι και 75
και ένα αρκετά σημαντικόμέρος των λογαριασμών είναι στο ανώτεροδιάστημα
των τιμών, από 75 μέχρι το 120.
Η εταιρία θα πρέπει να μάθει περισσότερα για τους πελάτες οι οποίοι κάνουν
μεγάλους λογαριασμούς. Οι συγκεκριμένοι πελάτες μπορούν να αποτελέσουν
στόχο για προσφορές από ανταγωνιστές με πιο ελκυστικές τιμές. Με αυτές τις
πληροφορίες θα μπορέσει η εταιρεία να τους συγκρατήσει( τους πελάτες της)
αλλά και με τις κατάλληλες προσφορές να προσελκύσει και πελάτες από τους
ανταγωνιστές της.
42.
41
2.6.1 Εύρεση Κλάσεων,δημιουργία ιστογράμματος
Εδώ θα δούμε ένα ακόμα παράδειγμα για το πώς μπορούμενα δημιουργήσουμε
κλάσεις. ¨Ένας φοιτητήςδιαθέτει κάποια χρήματα και μπορεί να τα διαθέσει σε
μία από τις δύο επενδύσεις που έχει στην επιλογή του. Με την βοήθεια του
ιστογράμματος θα συγκρίνει τις δύο επιλογές του και θα επιλέξει την καλύτερη
γι’ αυτών επένδυση.
Για την πρώτη επένδυση:
Αρχικά, καταχωρούμετα δεδομένα μας όπως γνωρίζουμε και χρησιμοποιούμε
την εντολή <<str>>για να δούμε τα δεδομένα μας.
Με την εντολή “Gefort=cut()”χωρίζουμε το δείγμα μας σε κλάσεις. Σε αυτό το
παράδειγμα όπουοι παρατηρήσεις μας είναι 50 και με το τύπο που δείξαμε πιο
πάνω στην παράγραφο ,χωρίζουμε το δείγμα μας σε 7 κλάσεις ,γράφοντας
“Geffort=cut(kef2b$Return.A, 7)”. Στην συνέχεια, με την βοήθεια της εντολής
“table()” εμφανίζουμε τον πινάκα όπου τα στοιχεία μας πλέον είναι χωρισμένα
σε ομάδες.Επίσης , σε αυτόν τον πίνακα βλέπουμε πόσες παρατηρήσεις έχει η
κάθε ομάδα.
43.
42
Για να δημιουργήσουμεένα Ιστόγραμμα πρέπει να χρησιμοποιήσουμε την
εντολή “hist(Return.A,breaks=bins)”.To “hist” ,βγαίνει από το histogram,
δηλαδή, ιστόγραμμα,με το “Bills” του ορίζουμε για πια μεταβλητή μας θέλουμε
να κάνουμε το διάγραμμα αυτό και τέλος με το “break=bins” του θέτουμε τα
όρια ώστε να αλλάξει μπάρα στο διάγραμμα. Αυτό το επιτυγχάνουμε με την
εντολή “bins=seq(min(Return.A),max(Return.A)+12.2,12.2).To “bins” είναι
όνομα που του ορίσαμε εμείς, το “seq” βγαίνει από την αγγλική λέξη
“Sequence” που σημαίνει “ακολουθία” και μέσα σε αυτό θέτουμε το
ελάχιστο(min),το μέγιστο(max) και την διαφορά που έχουν μεταξύ τους οι
κλάσεις.
44.
43
Παρατηρούμε ότι ηκορυφή του Ιστογράμματος βρίσκεται στην κλάση με
απόδοση από 0 μέχρι 15%. Επίσης, η επένδυση A παρουσιάζει στο αριστερό
άκρο τιμές μέχρι και -20 και εμφανίζει να έχει ελαφρά θετική ασυμμετρία.
Για την δεύτερη επένδυση:
Με τον ίδιο τρόπο καταχωρούμε τα δεδομένα μας και χρησιμοποιούμε την
εντολή <<str>>για να δούμε τα δεδομένα μας.
45.
44
Με την εντολή“Gefort=cut()”χωρίζουμε το δείγμα μας σε κλάσεις. Σε αυτό το
παράδειγμα όπουοι παρατηρήσεις μας είναι 50 και με το τύπο που δείξαμε πιο
πάνω στην παράγραφο ,χωρίζουμε το δείγμα μας σε 7 κλάσεις ,γράφοντας
“Geffort=cut(kef2b$Return.B, 7)”. Στην συνέχεια, με την βοήθεια της εντολής
“table()” εμφανίζουμε τον πινάκα όπου τα στοιχεία μας πλέον είναι χωρισμένα
σε ομάδες.Επίσης , σε αυτόν τον πίνακα βλέπουμε πόσες παρατηρήσεις έχει η
κάθε ομάδα.
Για να δημιουργήσουμε ένα Ιστόγραμμα πρέπει να χρησιμοποιήσουμε την
εντολή “hist(Return.B,breaks=bins)”.To “hist” ,βγαίνει από το histogram,
δηλαδή, ιστόγραμμα,με το “Bills” του ορίζουμε για πια μεταβλητή μας θέλουμε
να κάνουμε το διάγραμμα αυτό και τέλος με το “break=bins” του θέτουμε τα
όρια ώστε να αλλάξει μπάρα στο διάγραμμα. Αυτό το επιτυγχάνουμε με την
εντολή “bins=seq(min(Return.B),max(Return.B)+12.2,12.2).To “bins” είναι
όνομα που του ορίσαμε εμείς, το “seq” βγαίνει από την αγγλική λέξη
“Sequence” που σημαίνει “ακολουθία” και μέσα σε αυτό θέτουμε το
ελάχιστο(min),το μέγιστο(max) και την διαφορά που έχουν μεταξύ τους οι
κλάσεις.
46.
45
Όπως και στοΙστόγραμμα της επένδυσης A έτσι και εδώ η κορυφή του
βρίσκεται στην κλάση με απόδοσημεταξύ 0-15%. Στο αριστερό άκρο βλέπαμε
ότι παίρνει τιμές μικρότερες από το -30. Παρατηρούμε ότι και η επένδυση B
εμφανίζει μια ελαφρά θετική ασυμμετρία με την διαφορά ότι είναι περισσότερο
μετατοπισμένο προς τα δεξιά με μόνη εξαίρεση την κλάση στα αριστερά που
δείχνει μια πιθανότητα για υψηλές τιμές.
Συγκρίνοντας τα δύο Ιστογράμματα συμπεραίνουμε ότι η επένδυση B έχει
καλύτερεςαποδόσεις από την A,αλλά με έναν όχι και τόσο ασήμαντο κίνδυνο
για υψηλές ζημίες. Ο φοιτητής ,ανάλογα την οικονομική κατάσταση του θα
μπορούσε να επιλέξει την καλύτερη επένδυση για αυτόν.
47.
46
2.7 Ελαχίστων Τετραγώνων
Οιτιμές που παρουσιάζονται στο επόμενοπαράδειγμα είναι μια προσπάθεια
ενός φοιτητή να κατανοήσει την σχέση ανάμεσα στον βαθμό εξέτασης και τον
χρόνο μελέτης ,δέκα συμφοιτητώντου σε ένα συγκεκριμένομάθημα.
Αρχικά, καταχωρούμετα δεδομένα μας όπως γνωρίζουμε και χρησιμοποιούμε
την εντολή <<str>>για να δούμε τα δεδομένα μας.
Με summary() (όπως είδαμε και στο κεφάλαιο 2.4) μας δίνει γρήγορα και
εύκολα βασικές αλλά χρήσιμες πληροφορίεςγια την άσκηση μας ,όπως διάμεσο
,μέσο και άλλα.
Με την εντολή plot() δημιουργούμε ένα διάγραμμα με το οποίο ελέγχουμε αν η
σχέση μας είναι γραμμική.
48.
47
Για να επιβεβαιώσουμετις υποψίες μας, βρίσκουμε την συσχέτιση μεταξύ του
χρόνου μελέτης(Study.time) και βαθμών(Marks),από την εντολή cor().Το cor
βγαίνει από την αγγλική λέξη correlation που σημαίνει συσχέτιση.
Πριν ξεκινήσουμε για να βρούμε την γραμμή ελαχίστων τετραγώνων θα πρέπει
να ορίσουμε ποια μεταβλητή είναι η ανεξάρτητη και ποια η εξαρτημένη. Στο
συγκεκριμένο παράδειγμα η ανεξάρτητη είναι ο χρόνος διαβάσματος
(Study.time) και η εξαρτημένη είναι οι βαθμοί(Marks) . Επιλέχθηκαν έτσι γιατί
ο χρόνος διαβάσματος επιρεάζει τον βαθμό.Οσο περισσότερο ασχοληθεί
κάποιος ,τόσο καλύτερο βαθμό θα πάρει.
49.
48
Η εντολή γιατην εκτέλεση των ελαχίστων τετραγώνων είναι η lm. Η
περισπωμένη μας δείχνει την στην ουσία ότι οι βαθμοι (Marks) εξαρτόνται
(~)από τον χρόνο διαβάσματος (Study.time).
Αφού τρέξουμε την εντολή lm και γράφοντας το όνομα στο οποίο περάσαμε
τις τιμές, το πρόγραμμα ,θα μας εμφανίσει ελάχιστες πληροφορίες .
Αν θελήσουμε να μάθουμε τι άλλο είναι αποθηκευμένο στην μεταβλητή, με την
εντολή attributes().
Με την εντολή fit$c παίρνουμε τις τιμές των α και β στην ευθεία
παλινδρόμησηςψ=α+βχ. Συγκεκριμένα βλέπουμε, ότι για το α η τιμη είναι ίση
με 5,921746 και για το β είναι ίση με 1,704864.
50.
49
Για να βρούμετις τιμές των εκτιμημένων σφαλμάτων ή υπολοίπων(residuals)
χρησιμοποιούμε την κάτω εντολή.Δημιουργούμεένα καινούριο αντικείμενο το
res, το οποίο πληκτρολογώντας το στην συνέχεια μας δίνει τις τιμές που
θέλουμε. Εν συνεχεία, με την εντολή plot() δημιουργούμε ένα διάγραμμα για το
χρόνο διαβάσματοςκαι τα υπόλοιπα,όπουείναι και οι τιμές που μπαίνουν μέσα
στην παρένθεση.
51.
50
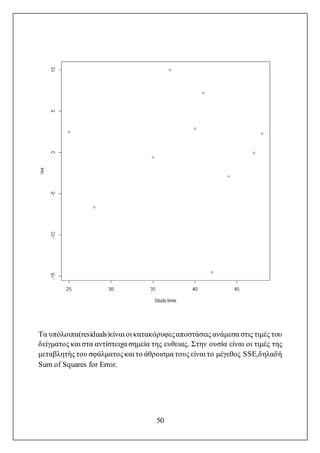
Τα υπόλοιπα(residuals)είναι οικατακόρυφεςαποστάσεις ανάμεσα στις τιμές του
δείγματος και στα αντίστειχα σημεία της ευθειας. Στην ουσία είναι οι τιμές της
μεταβλητής του σφάλματος και το άθροισμα τους είναι το μέγεθος SSE,δηλαδή
Sum of Squares for Error.
52.
51
Με την προηγούμενηεντολη είδαμε πώς να βρήσκουμε τα υπόλοιπα,όμως
υπάρχει και ένας πολύ πιο εύκολος τρόπος. Μπορούμε απλά να γράψουμε την
εντολή residuals(). Η τιμή “fit” που βάζυμε μέσα στην παρένθεση , είναι το
αντικείμενο που έχουμε δημιουργήσει εμείς για την εκτέλεση των ελαχίστων
τετραγώνων.Αυτος ο τρόπος είναι πολύ πιο απλός από τον προηγούμενο και
είναι χρήσιμος προς την αποφυγή λαθών.
Για να δημιουργήσουμε το διάγραμμα με το χρόνο διαβάσματος (Study.time)και
των βαθμών(Marks), όπως γνωρίζουμε και από τα προγουμενά παραδείγματα,
χρησιμοποιούμε την εντολή plot(Study.time,Marks).Μετέπειτα για να
εμφανίσουμε την γραμμή πάνω στο διάγραμμα πληκτρολογούμε το abline(fit).
53.
52
Ο συντελεστής διεύθυνσηςβ=1,704864είναι η κλίση της ευθείας, δηλαδή , για
κάθε μονάδα που κινούμαστε προς τα δεξιά στον οριζόντιο άξονα, η ευθεία
ανεβαίνει κατά 1,704864 μονάδες στον κάθετο άξονα. Με απλά λόγια η κλίση
της ευθείας μας δείχνει την αύξηση της Y ανά μονάδα της X.
Ο συντελεστής α=5,921746 αντιπροσωπεύει το σημείο τομής της ευθείας με
τον άξονα Y.
54.
53
2.8 Άσκηση ελέγχουμε γνωστό τον έλεγχο και την τυπική
απόκλιση
Στο επόμενο παράδειγμα θα εξετάσουμε έναν έλεγχο υπόθεσης, όταν ο μέσος
και η τυπική απόκλιση είναι γνωστά στοιχεία . Σκοπός μας είναι, γνωρίζοντας
αυτά τα δύο στοιχεία, να εξετάσουμε αν υπάρχει διαφορά στο μέσο λογαριασμό
μια εταιρείας έναντι του ανταγωνιστή της.
Αρχικά εισάγουμε τη τοποθεσία των δεδομένων μας και στη συνέχεια, αν
θέλουμε για λόγους ευκολίας το μετονομάζουμε.
Σε αυτή την άσκηση θα χρειαστούμε ένα από τα packages και για την ακρίβεια
την TeachingDemos. Αφού κάνουμε load και install την συγκεκριμένη
βιβλιοθήκη τρέχουμετην εντολή z.test(). Μέσα στις παρενθέσεις εισάγουμε το
μέρος απ’ όπου θέλουμε να πάρει μεταβλητές για τον έλεγχο η
55.
54
εντολή(x$Bills),την υποθετική τυπικήαπόκλιση(sd=3.87), τον υποθετικό μέσο
(m=17.09) και στην συνέχεια πατάμε ENTER.
Στην οθόνη του χρήστη εμφανίζεται το όνομα του ελέγχου, οι τιμές z,n (που
είναι το μέγεθος του δείγματος μας), η τυπική απόκλιση, η τιμή SE mean και η
τιμή p. Ακόμα ,βλέπουμε την εναλλακτική υπόθεση, το διάσημα εμπιστοσύνης
και τον πραγματικό μέσο του δείγματος μας.
Η μηδενική υπόθεση σε αυτή τη περίπτωση απορρίπτεται αν ο μέσος είναι είτε
μικρότερος είτε μεγαλύτερος από τον υπάρχοντα,με την περιοχή απόρριψης να
είναι z< -z a/2 ή z>z a/2. Με το a=0.05 έχουμε z< -1,96 ή z>1,96( πίνακας
τιμών z).
Ο έλεγχος z είναι 1.1884 και επειδή δεν είναι ούτε μικρότεροούτε μεγαλύτερο
του -1,96 δεν απορρίπτεται η μηδενική υπόθεση. Με τη τιμή της p να είναι στο
0.2347 μπορούμε να πούμε πως δεν υπάρχουναρκετά στατιστικά στοιχεία ώστε
να συμπεράνουμεότι ο μέσος λογαριασμός των ανταγωνιστών διαφέρει από
αυτόν της εταιρείας που εξετάζουμε.
56.
55
2.9 Άσκηση ελέγχουμε γνωστό μέσο.
2.9.1 Εισαγωγή δεδομένων χωρίς διάβασμα από αρχείο
Το όνομα που θα δώσουμε θα είναι Libres και στην συνέχεια με την Στο
επόμενο παράδειγμα θα καταχωρήσουμε τα δεδομένα δίνοντας τους ένα όνομα
εντολή c() καταχωρούμε τα στοιχεία μας. Στην συνέχεια, πατώντας το ENTER
η μεταβλητή μας έχει δημιουργηθεί με το όνομα Libres και είναι έτοιμη προς
επεξεργασία.
…….
Εδώ θα εξετάσουμε δείγματα βάρουςεφημερίδωνσε λίβρες που απορρίφθηκαν
από 148 νοικοκυριά. Η υπόθεση που θέλουμε να εξετάσουμε είναι αν η μέση
εβδομαδιαία απόρριψη εφημερίδων είναι μεγαλύτερη από 2 λίβρες, έτσι ώστε
να ανοίξει ένα νέο κέντρο ανακυκλώσεων.
Χρησιμοποιώντας την εντολή t.test()παίρνουμε την απάντηση μας βάζοντας
μέσα στις παρενθέσεις τα χαρακτηριστικά κάτω από τα οποία θα γίνει ο
έλεγχος. Πρώτα μέσα στην παρένθεση βάζουμε το όνομα της μεταβλητής
(Libres). Εν συνεχεία ,μετα το κόμμα, βάζουμε το μέσο που θέλουμε να
εξετάσουμε(mu=2). Μετέπειτα εισάγουμε αν θέλουμε να είναι μεγαλύτερος
αυτός ο μέσος ή μικρότερος(alternative= “greater”) και τη στάθμη
σημαντικότηταςτης υπόθεσης(conf.=0.99). Να σημειωθεί, ότι αυτές οι εντολές
είναι απαραίτητες καθώς χωρίς αυτές, η εντολή t.test() από μόνη της θα μας
έδινε διαφορετικά αποτελέσματα.
Αρχικά, βλέπουμε το όνομα του test(one sample t-test). Στη συνέχεια τη βάση
δεδομέων που χρησιμοποιήσαμε(data:libres). Έπειτα, βλέπουμε την τιμή του
57.
56
ελέγχου t(t=2.1526), τουςβαθμούς ελευθερίας (df=147) και την τιμή
p(p=0.01644).
2.10 Έλεγχος αναλογίας ενός πληθυσμού
Στο επόμενο παράδειγμα θα εξετάσουμε την αναλογία ενός πληθυσμού, με
σκοπό να συμπεράνουμε τη νίκη ενός υποψηφίουέναντι του αντιπάλου του. Τα
δεδομένα μας είναι ονομαστικά και συμβολίζονται με «1» για το πρώτο
υποψήφιο και με «2» για τον δεύτερο.Σκοπός μας είναι να δούμε αν ο
υποψήφιος έχει κερδίσει τις εκλογές στη συγκεκριμένη περιοχή.
Αρχικά φορτώνουμε τα δεδομένα μας στο πρόγραμμα και στη συνέχεια δίνουμε
μια ονομασία (askhsh).
Έπειτα και με την βοήθεια της εντολής subset, ονομάζουμε με το όνομα y όλους
τους ψήφους της x όπου έχουν τον αριθμό «2». Αυτό γίνεται έτσι ώστε στην
συνέχεια με την εντολή str(y) να δούμε πόσοι από το σύνολο των ψηφοφόρων
έχουν ψηφίσει το δεύτερουποψήφιο. Το σύνολο των ψηφοφόρων το βλέπουμε
με την εντολή str(x).
58.
57
Έχοντας τον αριθμούςπου χρειαζόμαστε εισάγουμε την εντολή
prop.test(407,765,p=0.5,alternative= “greater”,correct=F). Ο αριθμός των
ψηφοφόρων στο σύνολοείναι 765 και αυτοί που ψήφισαν το δεύτερο είναι 407.
Η εναλλακτική υπόθεση που εξετάζουμε είναι ότι η αναλογία του δεύτερου
υποψηφίου πρέπει να είναι μεγαλύτερη του 0.5. Τέλος, με την εντολή correct=F
δηλώνουμε ότι δε θέλουμε να γίνει διόρθωση συνέχειας.
Το αποτέλεσμα της εντολής prop.test μας δίνει το x^2όπου η ρίζα του είναι ο
έλεγχος z. Τον έλεγχο z τον βρίσκουμε δίνοντας την εντολή sqrt() και στην
παρένθεση τον αριθμό X-squared(3.1386). Στη συνέχεια βλέπουμε τους
βαθμούς ελευθερίας , την τιμή p, την εναλλακτική υπόθεση ,το διάστημα
εμπιστοσύνης καθώς και την αναλογία των ψηφοφόρων του δεύτερου
υποψήφιου προς το σύνολο των υποψηφίων(0,5320261)
Με τη στάθμη σημαντικότητας στο 5% διαπιστώνουμε ο συγκεκριμένος
υποψήφιος έχει κερδίσει στην συγκεκριμένη περιοχή.
59.
58
2.11 Έλεγχος ίσωνδιασπορών
Στα επόμενα τρία παραδείγματα θα ελέγξουμε τις διασπορές των δειγμάτων μας
, κάνοντας τον έλεγχο ίσων διασπορών. Σκοπός μας είναι να επιλέξουμε το
κατάλληλο έλεγχο βάση των αποτελεσμάτων του ελέγχου διασπορών.
Στο συγκεκριμένο παράδειγμα εξετάζουμεαν είναι καλύτερογια μια επιχείρηση
να αναλαμβάνεται από το παιδί του διευθυντή ή από ξένο διευθυντή. Οι τιμές
του δείγματος μας είναι της μορφής ποσοστιαίας μεταβολής.
Αρχικά, περνάμε το δείγμα μας στο πρόγραμμα και το ονομάζουμε.
Έπειτα η εντολή attach() μας επιτρέπει να μην χρησιμοποιήσουμετο όνομα του
δείγματος αλλά μόνο των μεταβλητών. Πρώτος έλεγχος που πρέπει να
πραγματοποιήσουμε είναι ο var.test(Offspring,Outsider). Στην οθόνη του
χρήστη εμφανίζονται τα αποτελέσματα του ελέγχου και βλέπουμε την τιμή F,
την τιμή p, τους βαθμούςελευθερίαςκαι των δύο μεταβλητών,την εναλλακτική
υπόθεση και το διάστημα εμπιστοσύνης. Από τον έλεγχο των λόγων των
διασπορών βλέπουμε πως η τιμή F=0.4714 είναι εντός της περιοχής
απόρριψης(πίνακας τιμών F ). Ακόμα, από τη τιμή της p=0.008095
καταλαβαίνουμε ότι πρέπει να απορρίψουμε τη μηδενική υπόθεση και να
χρησιμοποιήσουμε τον έλεγχο των άνισων διασπορών.
60.
59
Για τον έλεγχοάνισων διαπορών δίνουμε την εντολή t.test(Offspring, Outsider,
mu=0), με τον όρο mu=0 να δηλώνει ότι στην εναλλακτική υπόθεση η διαφορά
των μέσων δεν είναι ίση του μηδενός.
Στην οθόνη μας, εμφανίζεται η τιμή του ελέγχου t,η τιμή της p, οι βαθμοί
ελευθερίας , ο όρος της εναλλακτικής υπόθεσης , το διάστημα εμπιστοσύνης
καθώς και οι μέσοι των δύο μεταβλητών.
Από τα αποτελέσματα συμπεραίνουμε ότι πρέπει να απορριφθεί η μηδενική
υπόθεση και να δεχθούμε ότι υπάρχει διαφορά στη μέση απόδοση μιας
επιχείρησης όταν την αναλαμβάνει ένα από τα παιδία του ιδρυτή από όταν
αναλαμβάνει ένας ξένος. Αυτό το καταλαβαίνουμε από τον έλεγχο t=-3.2196 με
την περιοχή απόρριψης 1.982(πίνακας τιμών students t) και τη τιμή p να είναι
ίση με 0.001685. Τέλος, συμπεραίνουμε ότι η μέση απόδοση μια επιχείρησης
είναι από 0.5136909% έως 2.1581458% υψηλότερη όταν αναλαμβάνει ξένος
διευθυντής έναντι κάποιου παιδιού του ιδρυτή.
2.12 Έλεγχος για το λόγο των διασπορών
Στο επόμενο παράδειγμα θα πραγματοποιήσουμε έναν έλεγχο για το λόγο των
διασπορών δύο μηχανών εμφιάλωσης.
61.
60
Αρχικά περνάμε ταδεδομένα μας στο πρόγραμμα και στη συνέχεια για τη δική
μας ευκολία, ονομάζουμε τα αρχεία.
Με την εντολή attach() και μέσα στη παρένθεση το όνομα που δώσαμε στο
δείγμα μας, όπως γνωρίζουμε από προηγούμενα παραδείγματα, δεν χρειάζεται
να ξαναχρησιμοποιήσουμε το όνομα το οποίο δώσαμε. Επισημαίνεται ότι αυτό
γίνεται για τη δική μας ευκολία και δεν αποτελεί ένα υποχρεωτικό βήμα.
Στη συνέχεια γίνεται χρησιμοποίηση της εντολής var.test(). Ο έλεγχος var
γίνεται για τις διακυμάνσεις και είναι συντομογραφία της λέξης variance όπου
είναι η αγγική μετάφραση της λέξης. Ακολούθως, εισάγουμε τις δύο μεταβλητές
μας (Machive.1, Machive.2) όπως και τον έλεγχο της εναλλακτικής υπόθεσης
(alternative= “greater”).
Στην οθόνη του χρήστη εμφανίζεται η τιμή f όπως και η τιμή p.Ακόμα
εμφανίζεται το διάστημα εμπιστοσύνης όπως και η εναλλακτική υπόθεση. Από
τη τιμή της F συμπεραίνουμε ότι δε μπορούμε να απορρίψουμε τη μηδενική
υπόθεση καθώς η περιοχή απόρριψης μας είναι 1.98 (πίνακας F) και ο έλεγχος
62.
61
μας είναι F=1.3988.Με τα δεδομένα αυτά δεν στηρίζεται η υπόθεση ότι η
διασπορά του δεύτερου πληθυσμού είναι μικρότερη από αυτή του πρώτου.
2.13 Έλεγχος ίσων διασπορών
Σε αυτό το παράδειγμα εξετάζουμε αν τα αμοιβαία κεφάλαια που προτείνουν οι
χρηματιστές έχουν μεγαλύτερη απόδοση από αυτά που είναι άμεσα διαθέσιμα
στους επενδυτές.
Αρχικά εισάγουμε και ονομάζουμε το δείγμα το οποίο εξετάζουμε.
Στη συνέχεια πραγματοποιούμε το έλεγχο διασπορών με την εντολή var.test().
Η τιμή του ελέχου F είναι ίση με 0.865, με την τιμή της p να είναι ίση με
0.57(πίνακας τιμών F) και επειδή ο έλεγχος μας δεν βρίσκεται στη περιοχή
απόρριψης, δε μπορούμε να απορρίψουμε τη μηδενική υπόθεση και έτσι θα
χρησιμοποιήσουμε το τύπο των ίσων διασπορών.
63.
62
Στο πρόγραμμα Rο έλεγχος t με ίσες διασπορές δηλώνεται με την εντολή
var.equal=T. Έτσι, με αυτό το τρόπο δίνουμε την εντολή ελέγχου
t.test(x$Direct,x$Broker,alternative= “greater”,var.equal=T) και στην οθόνη μας
εμφανίζεται ο έλεγχος t, η τιμή p, η εναλλακτική υπόθεση ,το διάστημα
εμπιστοσύνης και οι μέσοι δύο μεταβλητών.
2.14 Έλεγχος Διασποράς
Σκοπός μας είναι να δείξουμε ότι η διασπορά των ποσοτήτων είναι μικρότερη
από ένα κυβικό εκατοστό, για ένα μηχάνημα εμφιάλωσης, σε συσκευασίες ενός
λίτρου. Σε αυτό το παράδειγμα θα χρειαστεί να ελέγξουμε τη διασπορά του
δείγματος μας.
Πρώτο βήμα μας θα είναι η εισαγωγή των δεδομένων στο πρόγραμμα και στη
συνέχεια η μετονομασία του δείγματος μας.
64.
63
Στη συνέχεια θαεγκαταστήσουμε το package “TeachingDemos” με σκοπό να
χρησιμοποιήσουμε το έλεγχο sigma.test(). Μέσα στις παρενθέσεις θα μπούνε οι
παράμετροι μας, οι οποίοι είναι το όνομα της μεταβλητής μας (Fills), η τιμή της
διασποράς που εξετάζουμε (sigma=1) ,καθώς και ο όρος της εναλλακτικής
υπόθεσης( alternative= “less”).
Ο χρήστης στη συνέχεια δέχεται τα αποτελέσματα στην οθόνη όπου είναι το
όνομα του ελέγχου(One Sample Chi-Squared test for variance) η βάση
δεδομένων πουχρησιμοποιήθηκες (data:Fills), η τιμή του x^2( x-squared=15.2),
οι βαθμοί ελευθερίας(df=24)και η τιμή p(p-value=0.08523). Ακόμα φαίνονται η
εναλλακτική υπόθεση, το διάστημα εμπιστοσύνης καθώς και η διασπορά της
μεταβλητής μας (var of Fills 0.6333333). Από τον έλεγχο μας και με τη περιοχή
απόρριψης να είναι στο 13.85, βλέπουμε πως δεν μπορούμε να απορρίψουμε
την μηδενική υπόθεση. Με τη τιμή του ελέγχου p να είναι ίση με 0.08523
μπορούμε να πούμε πως δεν υπάρχουν αρκετά στατιστικά στοιχεία που να μας
κάνουν να συμπεραίνουμε πως ο ισχυρισμός είναι αληθής.
Αυτό βέβαια δε σημαίνει ότι η διασπορά είναι ίση ή μεγαλύτερη του ένα,
παρά μόνο μας δίνει το δικαίωμα να στηρίξουμε πως είναι μικρότερη του.
65.
64
2.15 Έλεγχος υπόθεσης
Στηνεπόμενη άσκηση θα εξετάσουμε τα λάθη που κάνουν δύο σαρωτές και
ύστερα θα τους συγκρίνουμε με σκοπό να δούμε ποιος από τους δύο είναι
καλύτερος.
Όπως και στα προηγούμενα παραδείγματα, φορτώνουμε τα δεδομένα μας και
στη συνέχεια τα ονομάζουμε.
Εν συνεχεία εισάγουμε την εντολή t.test() δηλώνοντας αυτή τη φορά ως
εναλλακτική υπόθεση ο μέσος (mu=0) να είναι μικρότερος του
μηδενός(alternative= “less”) και η σύγκριση των δεδομένων να γίνει κατά
ζεύγη(paired=T ή paired=TRUE).
Στην οθόνη του χρήστη εμφανίζεται το όνομα του test(paired t-test), τα
δεδομένα που χρησιμοποιήθηκαν(Brand.A και Brand.B), η τιμή του ελέγχου t,
η τιμή p, οι βαθμοί ελευθερίας, καθώς και η εναλλακτική υπόθεση και το
66.
65
διάστημα εμπιστοσύνης.Η τιμήτου ελέγχου είναι t=-3.2248 και η p είναι ίση με
0.007278. Με αυτά τα στοιχεία συμπεραίνουμε ότι ο σαρωτής A είναι
καλύτερος από τον B.
2.16 Έλεγχος υπόθεσης
Στο επόμενο έλεγχο υπόθεσης εξετάζουμε ποίοι κάτοχοι MBA δέχονται
καλύτερες προσφορές στην αγορά εργασίας, συγκρίνοντας αυτούς με
οικονομικές σπουδές με εκείνους από σπουδές μάρκετινγκ.
Αρχικά, φορτώνουμε στο πρόγραμμα τα δεδομένα μας και ύστερα τους δίνουμε
ένα όνομα.
Στη συνέχεια πληκτρολογούμε την εντολή var.test() με σκοπό να ελέγξουμε τις
διασπορές των μεταβλητών μας.
Ο έλεγχος μας έδειξε ότι μπορούμε να χρησιμοποιήσουμε το τύπο των ίσων
διασπορών, επομένως, η επόμενη εντολή που θα χρησιμοποιήσουμε θα είναι η
t.test() με εναλλακτική υπόθεση,η διαφοράτων μέσων να είναι μεγαλύτερη του
μηδενός( alternative= “greater”).
67.
66
Η περιοχή απόρριψηςείναι ίση με 1,676(πίνακας τιμών student t) και ο έλεγχος
μας είναι ίσος με t=1.0422. Επιπρόσθετα, η τιμή pείναι ίση με 0.1513 και έτσι,
με τα δεδομένα αυτά, δεν μπορούμε να στηρίξουμε την υπόθεση ότι οι
προσφορές που δέχονται οι κάτοχοι MBA με οικονομικές σπουδές είναι
υψηλότερες από εκείνες των κατόχων MBA με σπουδές στο τομέα του
Marketing.
2.17 Έλεγχος καλής προσαρμογής
Ως τελευταίο παράδειγμα θα δείξουμε έναν έλεγχο καλής προσαρμογής. Αυτό
που θέλουμε να δείξουμε είναι αν η επιλογή MBA σχετίζεται με την
κατεύθυνση των προπτυχιακών σπουδών.
Περνώντας τα δεδομένα μας και μετονομάζοντας τα ,μπορούμε έπειτα με την
εντολή data.frame() να δούμε τα δεδομένα μας τα οποία είναι ομαδοποιημένα.
68.
67
Στην συνέχεια πληκτρολογούμετην εντολή chisq:test() και στις παρενθέσεις
εισάγουμε τις δύο μεταβλητές(Degree,MBA.Major). Σημαντικό βήμα είναι να
έχει χρησιμοποιηθεί εντολή attach() και μέσα στη παρένθεση το όνομα του
δείγματος μας. Ειδάλλως μπορούμε να γράψουμε την εντολή με το όνομα του
δείγματος και στη συνεχεία το σύμβολο του δολαρίου με τις εκάστοτε
μεταβλητές.
Στην οθόνη του χρήστη εμφανίζεται το όνομα του ελέγχου που “τρέξαμε”
(Pearson’s Chi-squared test), οι μεταβλητές που τέθηκαν προς εξέταση(Degree
and MBA.Major) και τα αποτελέσματα του έλεγχου. Βλέπουμε πως η τιμή του
x^2(x-squared) είναι ίση με 14.7019 με τη περιοχή απόρριψης μας να είναι ίση
με 12.5916( πίνακας τιμών x^2). Τέλος, η τιμή p είναι ίση με 0.02271. Με τον
έλεγχο να βρίσκεται μέσα στη περιοχή απόρριψης μπορούμε να συμπεράνουμε
ότι υπάρχει σχέση μεταξύ προπτυχιακής κατεύθυνσης σπουδών και
κατεύθυνσης MBA.
69
3.1 Με λίγαλόγια.
3.1.1 Τι είδαμε.
Σε αυτήν την έρευνα είδαμε διεξοδικά τις δυνατότητεςτου προγράμματος R,όσο
αναφορά τις στατιστικές μελέτες και την έκβαση χρήσιμων συμπερασμάτων.
Αναφερθήκαμε στην στατιστική επιστήμη, βλέποντας βασικούς ορισμούς της
όπως επίσης και τα είδη της, αναλύοντας τους κυριότερους τομείς της
περιγραφικής αλλά και της επαγωγικής στατιστικής. Στην συνέχεια είχαμε μια
πρώτη γνωριμία με το πρόγραμμα R βλέποντας το περιβάλλον του
προγράμματος, τουςτελεστές του αλλά και τον τρόπο αποθήκευσης, ανάκτησης
και εισαγωγής δεδομένων. Με την βοήθεια ασκήσεων καταφέραμε να δείξουμε
όλες τις βασικές λειτουργίεςτου R ξεκινώντας από την εισαγωγή αρχείων και
δεδομένων στο πρόγραμμα και στην συνέχεια, με τις κατάλληλες εντολές να
εξάγουμε τα αποτελέσματα που μας ενδιαφέρουν. Από την περιγραφική
στατιστική, με τα μέτρα θέσης και διασποράς, έως και την επαγωγική, με τους
ελέγχους υποθέσεων και τα διαστήματα εμπιστοσύνης, καταφέραμε να
πραγματοποιήσουμε τον κύριο και αρχικό σκοπό αυτής της έρευνας που δεν
ήταν άλλος από το να γνωρίσουμε το πρόγραμμα R ,να το κατανοήσουμε και
στην συνέχεια να το αξιολογήσουμε.
3.1.2 Πλεονεκτήματα και Μειονεκτήματα του Προγράμματος.
3.1.2.1 Πλεονεκτήματα
Ένα από τα μεγαλύτερα θετικά στοιχεία του προγράμματος είναι τα σχετικά
λίγα προβλήματα που μπορεί να συναντήσει ο χρήστης καθώς και η εύκολη
επίλυση τους. Με την ανοιχτή κοινότητα R να είναι πάντοτε πρόθυμη να
βοηθήσει ,είτε αρχάριους, είτε προχωρημένους χρηστές ,η εκμάθηση και η
κατανόηση του R γίνεται με σχετική άνεση. Ακόμα με το ίδιο το πρόγραμμα να
δίνει λύσεις , όπου αυτό γίνεται δυνατό ,ο χρήστης μαθαίνει να βρίσκει και να
επιλύει προβλήματα παντόςφύσης. Ένα ακόμη σημαντικό πλεονέκτημα είναι το
λειτουργεί με βιβλιοθήκες(packages) . Με την χρήση βιβλιοθηκών ο χρήστης
μπορεί να χρησιμοποιήσει πληθώρα παραδειγμάτωνπρος επίλυση όπως επίσης
και εντολές οι οποίες πιθανόν να τον βοηθήσουν στην λύση των ασκήσεων.
Συνεχίζοντας θα πρέπει να τονίσουμε, ότι ακόμα και αν δεν υπάρχει κάποια
βιβλιοθήκη έτσι ώστε να βοηθήσει το χρήστη, ο ίδιος μπορεί να τη
δημιουργήσει. Το R πέρα από ένα πολυεργαλείο , είναι και μια γλώσσα
71.
70
προγραμματισμού η οποίαμας δίνει την δυνατότητα να κατασκευάσουμε την
εντολή που χρειαζόμαστε. Ως ένα από τα μεγαλύτερα πλεονεκτήματα θα
μπορούσαμε ακόμα να αναφέρουμε την λυτή αλλά άκρως κατανοητή
παρουσίαση δεδομένων στο περιβάλλον του προγράμματος. Το R εμφανίζει
στο χρήστη το απαιτούμενοαποτέλεσμα με όλες τις πληροφορίεςπου μπορεί να
ζητήσει ο χρήστης χωρίς να χρειάζεται να ανατρέξει αλλού ή να δώσει
παραπάνω εντολές από τις απαιτούμενες. Επιπρόσθετα, το R, δίνει ένα ευρύ
φάσμα γραφημάτων, στα οποία γίνεται αντιληπτή και η πιο μικρή λεπτομέρεια
και υπάρχει η δυνατότητα να τα προσαρμόσει ο χρήστης στις δικές του ανάγκες
και απαιτήσεις. Τέλος, ίσως και το σημαντικότερο πλεονέκτημα, είναι ότι δεν
χρειάζεται κάποιο αντίτιμο για την χρησιμοποίηση του. Όντας ένα δωρεάν
πρόγραμμα το οποίο μπορεί να χρησιμοποιηθεί από οποιονδήποτε ,το R αποκτά
ένα μεγάλο συγκριτικό πλεονέκτημα έναντι των υπολοίπων προγραμμάτων
στατιστικής, μαθηματικώνή προγραμματισμού. Ακόμα το ευρέοςεργασιών που
μπορεί να καλύψει είναι αναπόφευκταένα θετικό στοιχείο για το συγκεκριμένο
πρόγραμμα. Με τη στατιστικών είναι ένα μόνο κομμάτι από την πληθώρα
εργασιών, το R ,μπορεί να χρησιμοποιηθεί με μεγάλη ευχέρεια στη μαθηματική
επιστήμη, όπως ακόμα και στο προγραμματισμό και στην δημιουργία βάσεων
δεδομένων.
1.3.2.2 Μειονεκτήματα
Πέρα από τα θετικά στοιχεία παρατηρούμε και μια σειρά από κάποια
μειονεκτήματα, τα οποία δεν ξεπερνούν σε αριθμό τα πλεονεκτήματα του.
Αρχικά, όντας ένα πρόγραμμα το οποίοδεν διδάσκεται σε αρκετά εκπαιδευτικά
ιδρύματα, αντιμετωπίζει ένα μεγάλο πρόβλημα αναγνωσιμότητας. Επιπρόσθετα,
μπορεί να προκαλέσει άσχημη πρώτη εντύπωση στους νέους χρήστες. Με το
περιβάλλον του προγράμματος να μην θυμίζει σε τίποτα προγράμματα όπως
είναι το SPPS ή Excel, η εικόνα που δέχεται ο χρήστης μπορεί να θεωρηθεί
ασυνήθιστη και να δημιουργήσει κακή εντύπωση. Ο χρόνος απομνημόνευσης
και της σωστής χρήσης του μεγάλου πλήθους εντολών του μπορεί να θεωρηθεί
ως κάτι το αρνητικό. Ο χρήσης θα πρέπει να μάθει και να κατανόηση των
μεγάλο όγκο εντολών ώστε να έχει τα επιθυμητά αποτελέσματα. Όπως γίνεται
αντιληπτό θα πρέπει να κάνει αρκετά λάθη και να περάσει αρκετές ώρες πάνω
στο πρόγραμμα μέχρι να φθάσει στο σημείο να εφαρμόζει σωστά τις εντολές.
Τέλος, οι ελάχιστες πληροφορίες που υπάρχουν στην Ελληνική γλώσσα,
72.
71
καθιστούν το Rως ένα μέσο σχεδόν απρόσιτο για όσους δεν μιλούν κάποια
ξένη γλώσσα. Αποτέλεσμα αυτού είναι η αργή διάδοση του προγράμματος στη
χώρα μας
3.1.3 Σύγκριση με άλλα στατιστικά προγράμματα.
Σε σύγκριση με τα υπόλοιπαστατιστικά προγράμματα ,το R,έχει κάνει τεράστια
πρόοδο από την μέρα δημιουργίαςτου μέχρι και σήμερα. Η δωρεάν διανομή του
σε σύγκριση με πολλά άλλα στατιστικά πακέτα του δίνει ένα δυναμικό
πλεονέκτημα. Επίσης σε σύγκριση με τα στατιστικά προγράμματα SPSS ,
STATA έχει μεγάλη ποικιλία γραφημάτων αλλά σου παρέχει μεγάλη ευκολία
στην δημιουργία τους, στην διαχείριση τους και στην μετατροπή τους. Σχετικά
με το προγραμματισμό ,το R φαίνεται να προτιμάται σε σχέση με το STATA
καθώς είναι πολύ πιο εύκολο να το προγραμματίσεις. Στα περισσότερα
προβλήματα στατιστικής ακόμα και αν τα περισσότερα πακέτα μας δίνουν τα
στοιχεία και τις εξισώσεις που χρειαζόμαστε,πολλές φορές ο προγραμματισμός
είναι απαραίτητος και έτσι το R έχει συγκριτικό πλεονέκτημα.
Συγκριτικά με το SPSS, το συγκεκριμένο πρόγραμμα, με το πλεονέκτημα
του προγραμματισμού επιτρέπει στο χρήστη να κάνει πιο εξειδικευμένες
μελέτες, που είναι πιθανό να μην υπάρχουν,να είναι δύσκολοστο χειρισμό ή να
απαιτεί περισσότερο χρόνο και περισσότερα βήματα στην ίδια μελέτη στο
SPSS. Επίσης, σε διαφορές ιστοσελίδες με κύριο θέμα την στατιστική, το R
δείχνει να έχει μεγάλη απήχηση, με τους νέους ηλικιακά κατά κύριο λόγο να το
υποστηρίζουν σε σχέση με κάποια άλλα στατιστικά πακέτα, ισχυριζόμενοι
μάλιστα ότι το πρόγραμμα R είναι για εξειδικευμένες στατιστικές μελέτες σε
αντίθεση με το SAS,SPSS ή to STATA. Η αλήθεια βέβαια είναι ότι ακόμα και
σήμερα τα πακέτα αυτά(SPSS,SAS) θεωρούνται κορυφαία στατιστικά πακέτα
αλλά με το πέρασμα του χρόνου η απήχηση τους να μειώνεται. Στον αντίποδα
το STATAκαι το R αυξάνουντην δυναμική τουςκαι επακόλουθου αυτού είναι
η συνεχής αύξηση των χρηστών αυτών των προγραμμάτων. Συμβολικό αυτής
της απήχησης ,για το R, είναι η δημοσίευση από ,μια από τις μεγαλύτερης
εφημερίδας των Ηνωμένων Πολιτειών της Αμερικής , την New York Times το
2009 το οποίο δηλώνει πως το πακέτο αυτό κερδίζει την εμπιστοσύνη των
στατιστικών αναλυτών ανά τον κόσμο καθώς επίσης και ότι μπορεί στο μέλλον
να αποτελέσει μεγάλο ανταγωνιστή των μέχρι τότε μεγάλων στατιστικών
73.
72
προγραμμάτων.
Τέλος, μια έρευνα,του Bob Munchen, μας δείχνει την ανοδική αυτή πορεία
και προβλέπει πως μέχρι το 2015 θα έχει έρθει η αρχή του τέλους για τα δύο
πρωτοπόρα στατιστικά πακέτα.
3.1.4 Προτάσεις.
Ως μια πρώτη πρόταση,ύστερα από την εξαγωγή των συμπερασμάτων μας, θα
μπορούσαμενα πούμε την αναγκαιότητα εκμάθησης του προγράμματος σε όλα
τα εκπαιδευτικά ιδρύματα της χώρας. Το R, με την μεγάλη γκάμα δυνατοτήτων,
είτε στη στατιστική, είτε στα μαθηματικά, είτε στο προγραμματισμό θα ήταν
τέλειο εργαλείο δουλειάς για τους φοιτητές γιατί θα τους βοηθούσε να
καταλάβουν πολύ πιο εύκολα , πιο εξειδικευμένα προγράμματα ή ακόμα και
άλλες γλώσσες προγραμματισμού. Συγκεκριμένα, για τις σχολές με κύριο
αντικείμενο τη στατιστική, την οικονομία, τα μαθηματικά και τους
ηλεκτρονικούςυπολογιστές, θα πρέπει να θεωρείται απαραίτητο. Το R είναι ένα
πρόγραμμα με μηδενικό κόστος για την εκπαίδευση.Επιπρόσθετα, η δημιουργία
και η ανάπτυξη μιας Ελληνικής διαδικτυακής κοινότητας του προγράμματος
μπορεί να θεωρηθεί αναγκαία. Με αυτό τον τρόποοι Έλληνες χρήστες θα έχουν
μεγαλύτερη υποστήριξη και βοήθεια. Τέλος, θα ήταν ένας τρόπος προώθησης
του R στην Ελληνική αγορά, με τους πιθανούς χρήστες να βρίσκουν άμεσα
λύση στα προβλήματατουςξεπερνώντας έτσι το εμπόδιο μιας ξένης γλώσσας.
3.2 Συμπεράσματα.
Αυτό που μπορεί να συμπεράνει κανείς είναι ότι το πρόγραμμα έχει αρκετά
πλεονεκτήματα έναντι άλλων στατιστικών πακέτων, αλλά και προβλήματα, που
με τον καιρό όμως αντιμετωπίζονται. Το πρόγραμμαR , δείχνει να έχει σύμμαχο
τον χρόνο καθώς κερδίζει με τον καιρό την εμπιστοσύνη χιλιάδωνχρηστών ανά
τον κόσμο, με αποτέλεσμα να γίνεται ένα από τα πιο διαδεδομένα και αξιόπιστα
προγράμματα, όχι μόνο για στατιστικούς, αλλά και για άλλους σκοπούς.
74.
73
Βλέπουμε, ακόμα πωςοι δυνάμειςτου προγράμματοςξεπερνούνσε μεγάλο
βαθμό εκείνες των ανταγωνιστικών προγραμμάτων. Παρ’ όλα αυτά
παρατηρούμε και αδυναμίες, όπως είναι η αργή διάδοση του και πιο
συγκεκριμένα στην χώρα μας. Ακόμα και σε αυτήν την περίπτωση όμως τα
προβλήματα φαίνονται να είναι πολύ λίγα σε σχέση με την δυναμική του, την
αξιοπιστία του και γενικότερα, τα θετικά στοιχεία που παρουσιάζει το εν λόγο
πρόγραμμα. Κάτι που μας κάνει να πιστεύουμε ότι πολύ σύντομα θα είναι ίσως
το πιο επιτυχημένο, αλλά και εξεζητημένο στατιστικό πρόγραμμα.






















![24
άσκησης μας “Speeds”.Το αποτέλεσμα που εμφανίζεται στην οθόνη
[1]3290833 είναι ο μέσος των 120 παρατηρήσεων της άσκησης μας.
Για να βρούμε την διάμεσο χρησιμοποιούμε την εντολή “median” που βγαίνει
από την αγγλική λέξη median και σημαίνει “διάμεσος”. Στην συνέχεια,
ανοίγουμε παρένθεση και βάζουμε το όνομα του αντικειμένου που του
εισάγαμε την τιμή κατά το διάβασμα”kef4”. Μετέπειτα χρησιμοποιούμε το
σύμβολο “$”και μετά εισάγουμε το όνομα της μεταβλητής που μας ενδιαφέρει.
Στην περίπτωση της άσκησης μας “Speeds”.Το αποτέλεσμα που εμφανίζεται
στην οθόνη [1]32 είναι η διάμεσος των 120 παρατηρήσεων της άσκησης μας.
Για την επικρατούσα τιμή χρησιμοποιώ την εντολή <<table>> ,αφού πρώτα
την εισάγουμε ένα νέο αντικείμενο που θα έχει ένα όνομα που θα τα έχουμε
ορίσει εμείς, στην περίπτωση μας “ep.timh”. Μετά ανοίγουμε παρένθεση και
γράφουμε την εντολή <<as.vector>> και μέσα σε μια καινούρια παρένθεση το
πρώτο αντικείμενο που είχαμε δηλώσει κατά το διάβασμα “kef4”.Tέλος
κλείνουμε τις παρενθέσεις και πατάμε “enter”.Τέλος ,γράφουμε το όνομα του
νέου μας αντικειμένου και μας εμφανίζει το από κάτω πίνακα.](https://image.slidesharecdn.com/11d4cedd-a338-41a8-9113-406800aff19a-160215111857/85/R-statistics-25-320.jpg)
![25
Στον πίνακα παρατηρούμε ότι έχουμε δυο σειρές. Στην πάνω σειρά,
εμφανίζονται οι ταχύτητες των διερχομένων αυτοκίνητων που έχουμε στα
δεδομένα μας. Στην δεύτερη,βλέπουμε κάποιους αριθμούς ,στο συγκεκριμένο
παράδειγμα οι τιμές τους κυμαίνονται από1 ως και 8. Αυτές οι τιμές μας
σηματοδοτούνπόσες φορέςη κάθε ταχύτητα έχει εμφανιστεί. Για παράδειγμα η
ταχύτητα εξήντα 60 έχει εμφανιστεί μόνο μια (1) φορά, ενώ η εξήντα οκτώ(68)
έχει εμφανιστεί δυο(2).Ηταχύτητα εκείνη που έχει εμφανιστεί τις περισσότερες
φορές ,είναι και η επικρατούσα τιμή. Μιλώντας με τις τιμές της άσκησης,
έχουμε δύο επικρατούσεςτιμές, την ενενήντα οκτώ(98)και την εκατόν δυο(102)
οι οποίες παρουσιάστηκαν οκτώ φορές η κάθε μια.
2.2 Εύρεση τυπικής απόκλισης και διασποράς
Στο συγκεκριμένο παράδειγμα θα ασχοληθούμε με την εύρεση της τυπικής
απόκλισης και της διασποράς του αριθμού των αφίξεων των πελατών στα
ταμεία του καταστήματος .
Αρχικά, καταχωρούμετα δεδομένα μας όπως γνωρίζουμε και χρησιμοποιούμε
την εντολή <<str>>για να δούμε τα δεδομένα μας.
Για να βρούμε την τυπική απόκλιση χρησιμοποιούμε την εντολή “ sd “που
βγαίνει από τις αγγλικές λέξεις standart deviation και σημαίνει “τυπική
απόκλιση”. Στην συνέχεια, ανοίγουμε παρένθεση και βάζουμε το όνομα του
αντικειμένου που του εισάγαμε την τιμή κατά το διάβασμα”kef4”. Μετά
χρησιμοποιούμε το σύμβολο “$”και στην συνέχεια εισάγουμε το όνομα της
μεταβλητής που μας ενδιαφέρει. Στην περίπτωση της άσκησης μας
“Arrivals”.Το αποτέλεσμα που εμφανίζεται στην οθόνη [1]1500639 είναι η
τυπική απόκλιση των 150 παρατηρήσεων της άσκησης μας.](https://image.slidesharecdn.com/11d4cedd-a338-41a8-9113-406800aff19a-160215111857/85/R-statistics-26-320.jpg)
![26
Για να βρούμε την διασπορά χρησιμοποιούμε την εντολή “var”που βγαίνει από
την αγγλική λέξη variance και σημαίνει “διασπορά”. Στην συνέχεια, ανοίγουμε
παρένθεση και βάζουμε το όνομα του αντικειμένου που του εισάγαμε την τιμή
κατά το διάβασμα”kef4”. Μετά χρησιμοποιούμε το σύμβολο “$”και στην
συνέχεια εισάγουμε το όνομα της μεταβλητής που μας ενδιαφέρει. Στην
περίπτωση της άσκησης μας “Arrivals”.Το αποτέλεσμα που εμφανίζεται στην
οθόνη [1]2251918 είναι η διασπορά των150 παρατηρήσεωντης άσκησης μας.
2.3 Εύρεση Τεταρτημόριων
Στο επόμενο παράδειγμα εξετάζουμε τουςχρόνους δέσμευσης των τραπεζιών
,μιας καφετέριας, διακοσίων ομάδων πελατών σε ένα εστιατόριο
Αρχικά, καταχωρούμετα δεδομένα μας όπως γνωρίζουμε και χρησιμοποιούμε
την εντολή <<str>> για να τα δούμε.](https://image.slidesharecdn.com/11d4cedd-a338-41a8-9113-406800aff19a-160215111857/85/R-statistics-27-320.jpg)

![28
2.4 Εύρεση συχνοτήτων, σχετικών συχνοτήτων ,δημιουργία πίτας
και ιστογράμματος
Στο συγκεκριμένο παράδειγμα θα ασχοληθούμε με την εύρεση συχνοτήτων,
σχετικών συχνοτήτων αλλά και με την δημιουργία ιστογράμματος και
δημιουργία πίτας.
Αρχικά, περνάμε τα δεδομένα μας. Επειδή, το αρχείο μας είναι csv ,όπως είχαμε
πει και στο προηγούμενο κεφάλαιο θα γράψουμε read.csv και το μονοπάτι που
βρίσκεται το αρχείο μας μέσα στην παρένθεση. Στην συνέχεια, με την εντολή str
βλέπουμε τα δεδομένατα οποία εισάγαμε με την προηγούμενο διάβασμα μας.
Η δυνατότητα αλλαγής ονομάτων είναι σημαντική γιατί μας δίνει την
δυνατότητα καλύτερης κατανόησης της άσκησης ,αποφυγήςσημαντικών λαθών
και είναι και οπτικά πιο όμορφη. Για να μπορέσουμε να αλλάξουμε το όνομα
που θα φαίνεται στα διαγράμματα μας θα πρέπει ,πρώτα, να δηλώσουμε την
στήλη στην οποία θέλουμε να αλλάξουμε τα ονόματα των δεδομένων της ως
χαρακτήρα. Αυτό το κάνουμε με την εντολή x$Brand<-as.character(x$Brand).
Εν συνεχεία, με την εντολή x$Brand[x$Brand == “1”] <-“bud light” το
πρόγραμμα αυτόματα ψάχνει στην στήλη Brand και όποιος χαρακτήρας είναι
ίσος με το ένα τον άσσο του δίνει το όνομα bud light(για το συγκεκριμένο
παράδειγμα). Με τον ίδιο τρόπο, αλλάζοντας όμωςκάθε φορά το όνομα που θα
πρέπει να βρει το πρόγραμμα και το νέο που θα πάρει την θέση του μπορούμε
να αλλάξουμε τα ονόματα (όπως βλέπουμε και ποιο κάτω).](https://image.slidesharecdn.com/11d4cedd-a338-41a8-9113-406800aff19a-160215111857/85/R-statistics-29-320.jpg)




















































































![Ise iv-computer organization [10 cs46]-notes new](https://cdn.slidesharecdn.com/ss_thumbnails/ise-iv-computerorganization10cs46-notesnew-140624013827-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

































