




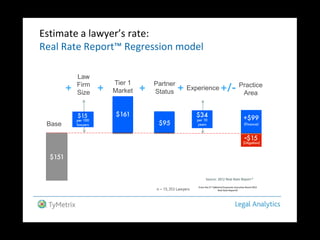
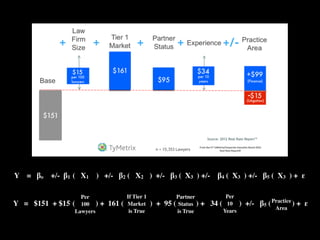


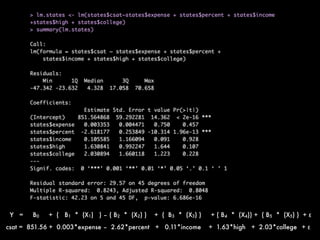
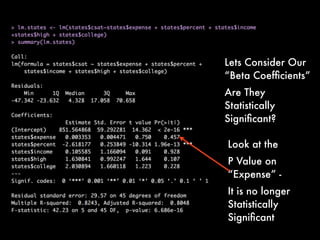
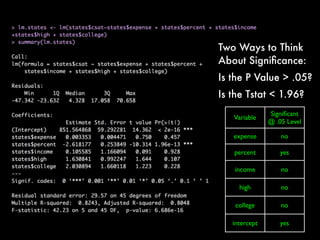







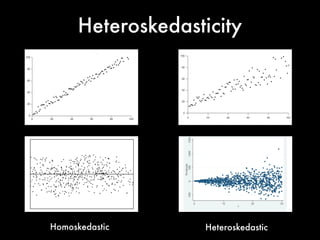

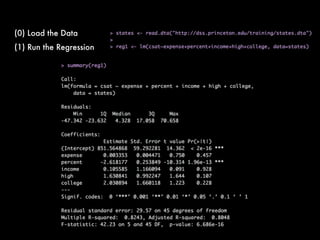
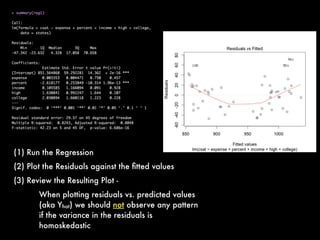
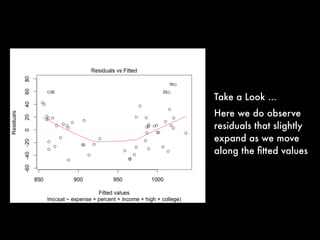




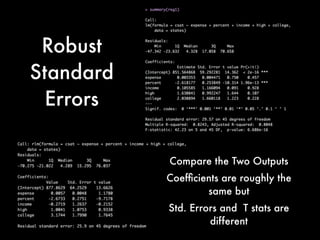


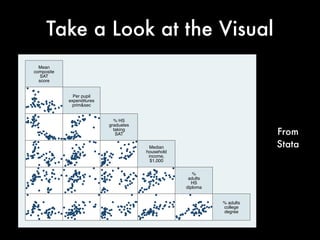
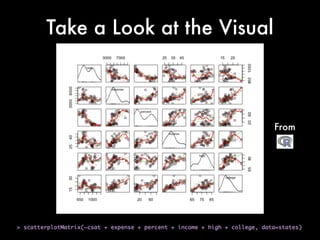

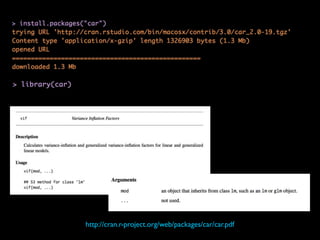



This document discusses multiple regression analysis and some key assumptions and issues that can arise. It provides an example of using multiple regression to estimate SAT scores based on various state-level factors like expenditures, income levels, education levels etc. It discusses how to detect issues like heteroskedasticity and multicollinearity that can violate the assumptions of regression analysis. It demonstrates how to use robust standard errors to account for heteroskedasticity and examines variance inflation factors to check for multicollinearity issues.























































































