


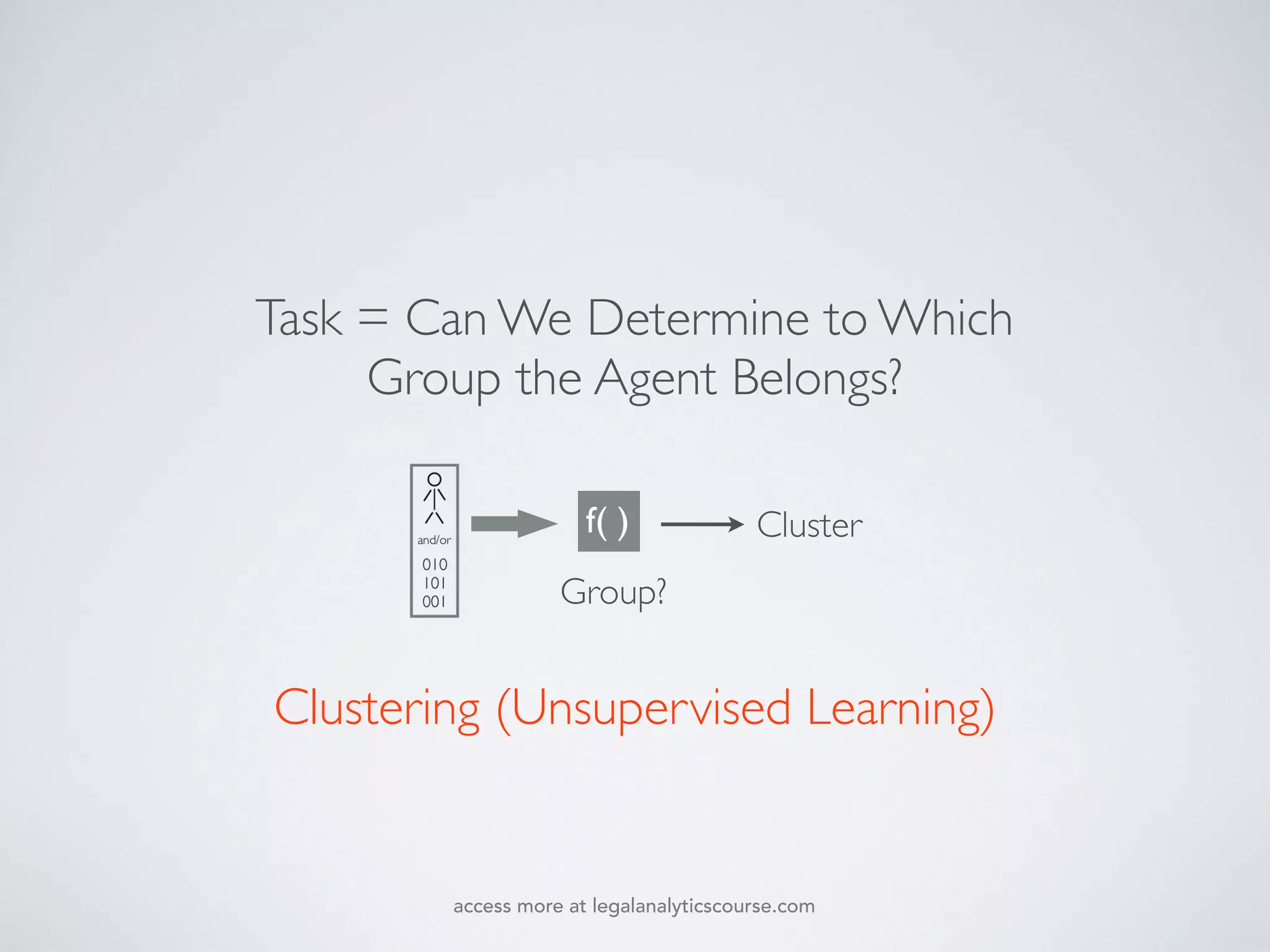
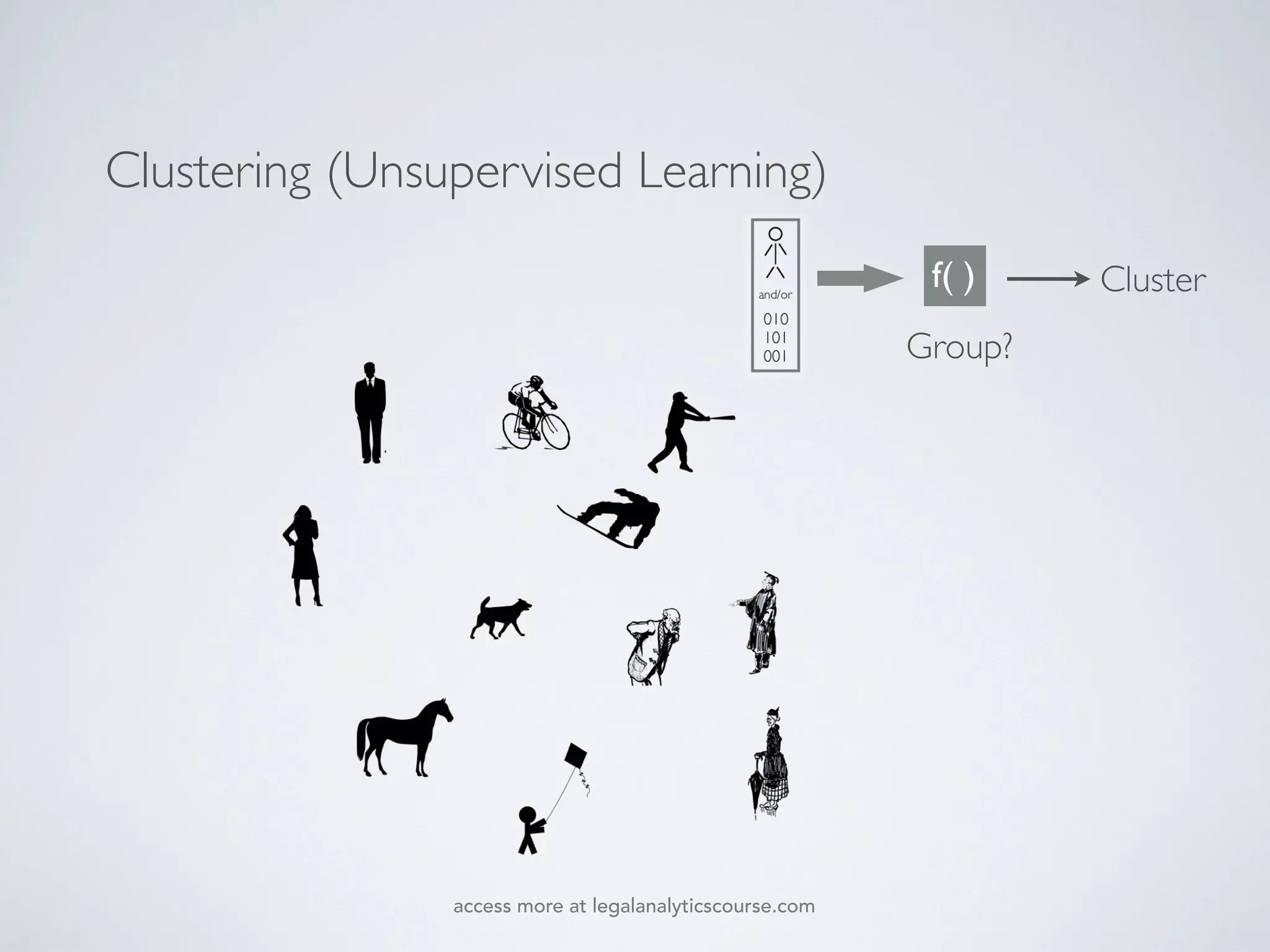
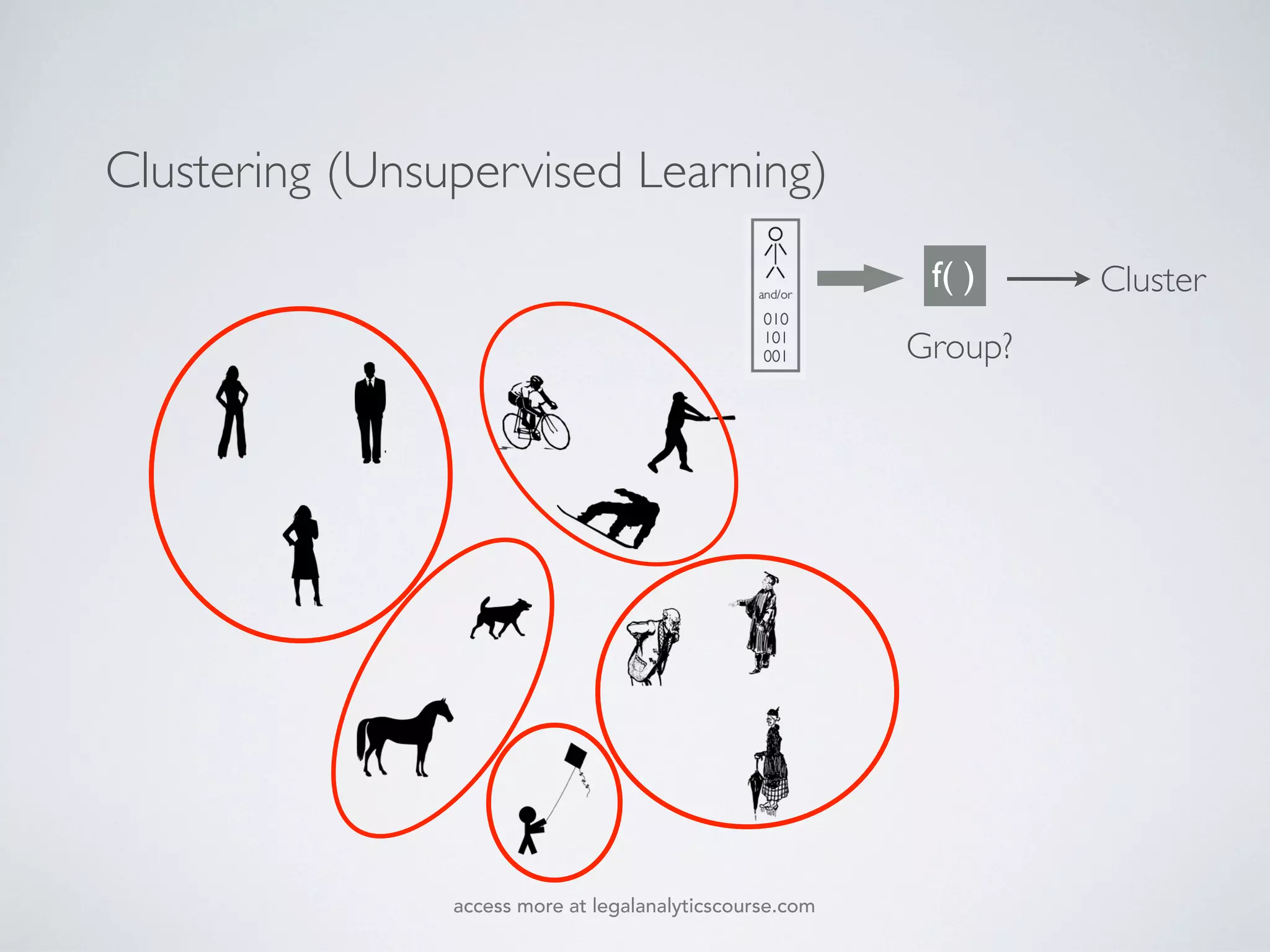














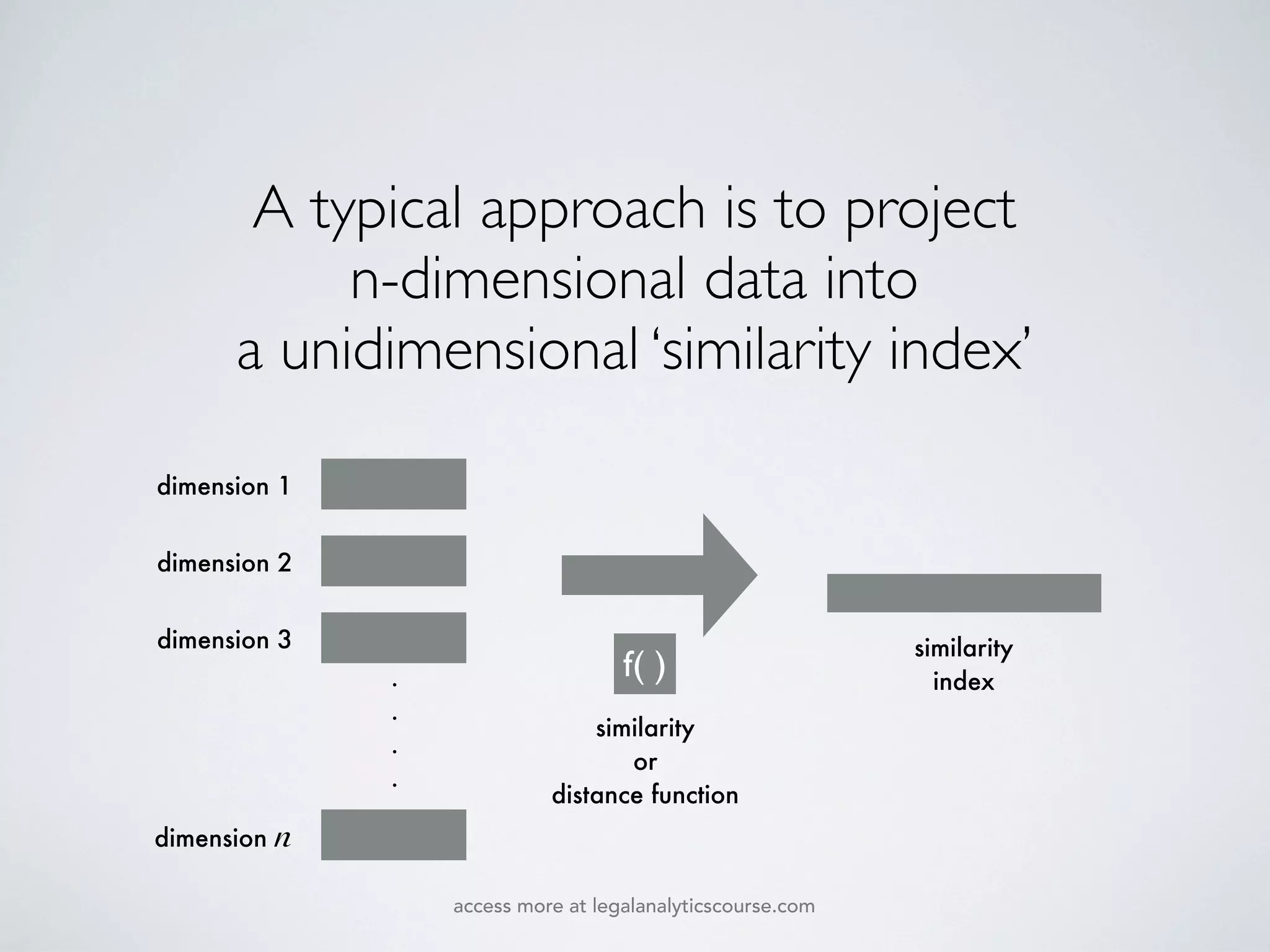













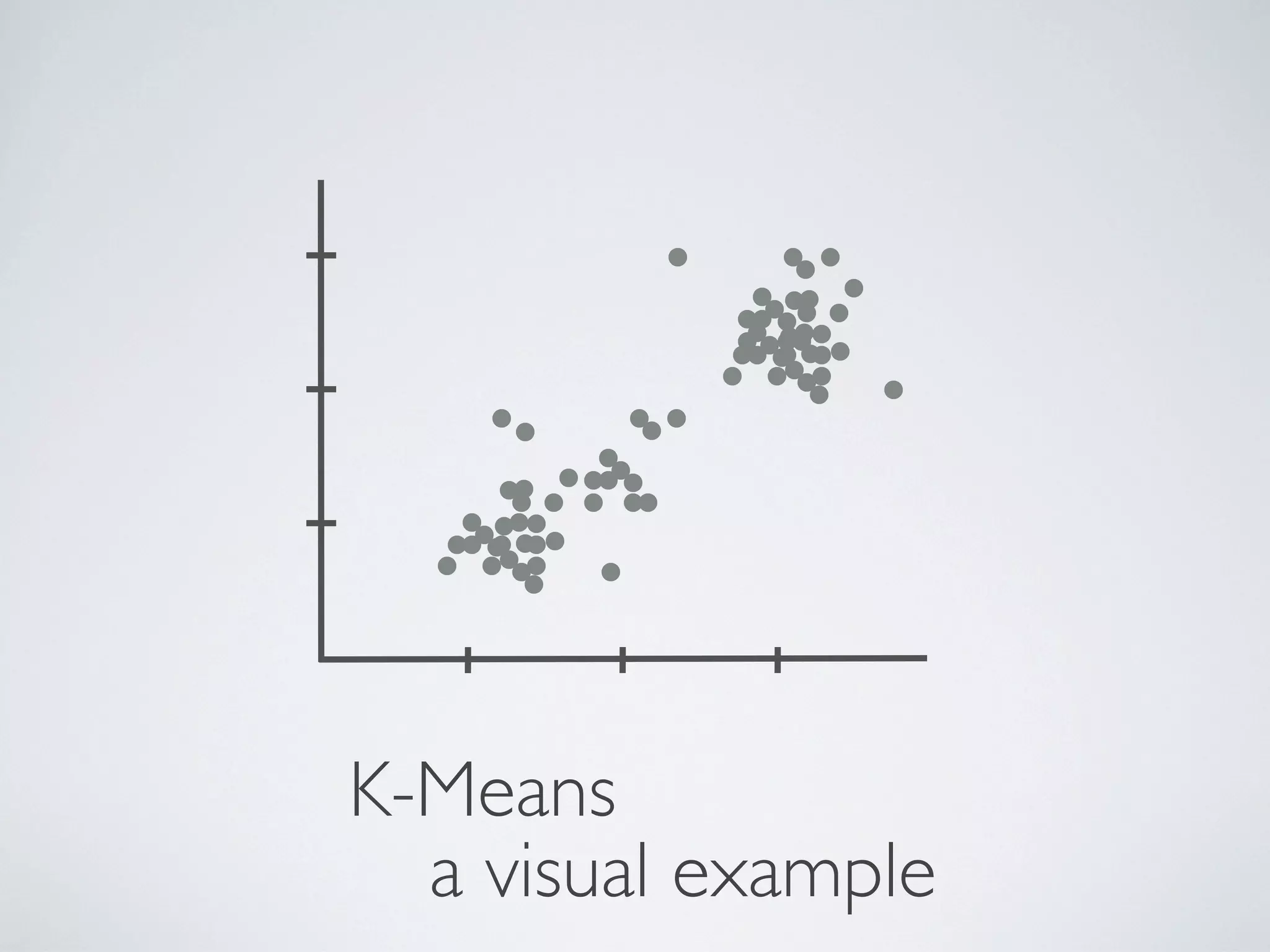
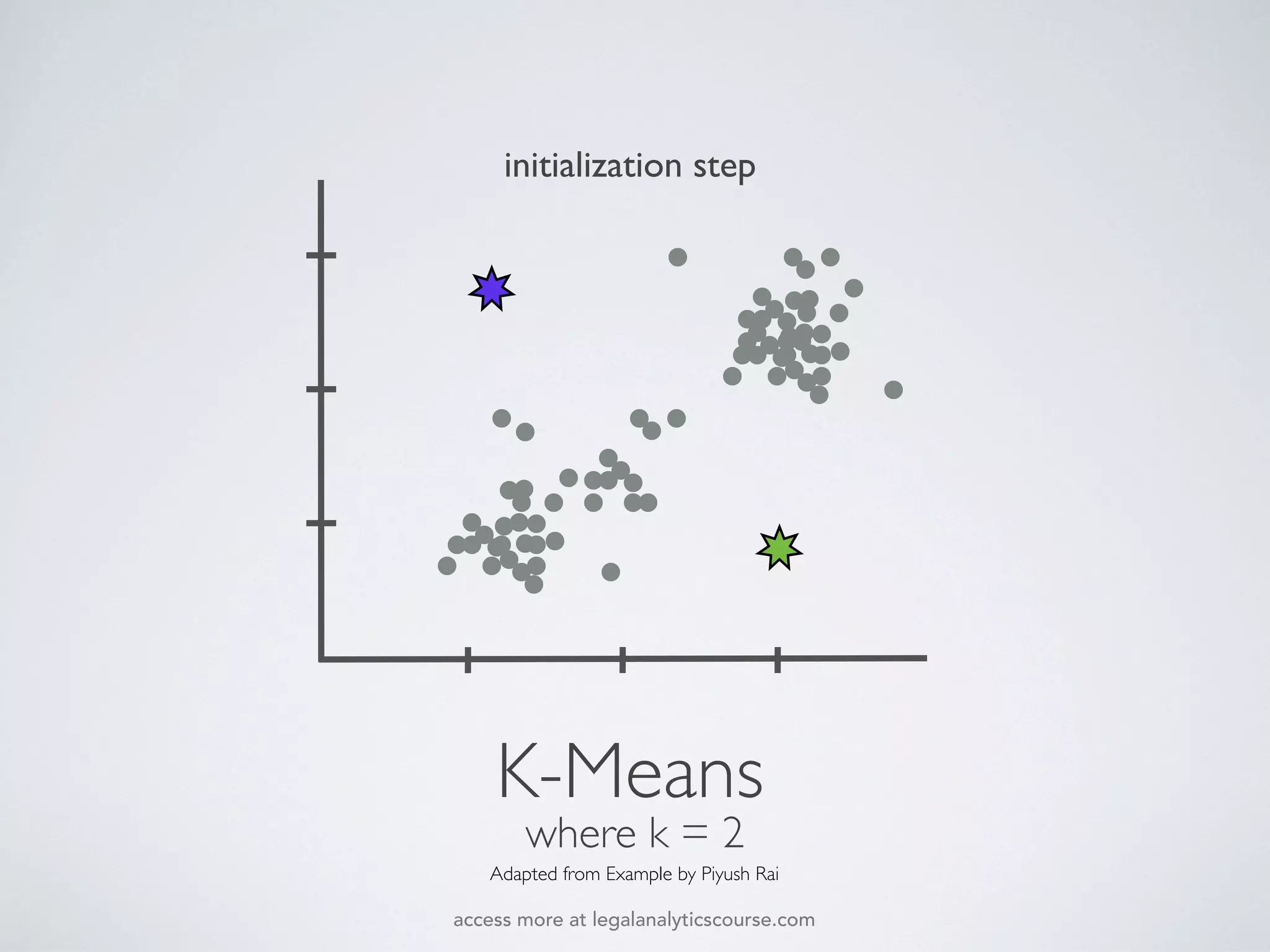
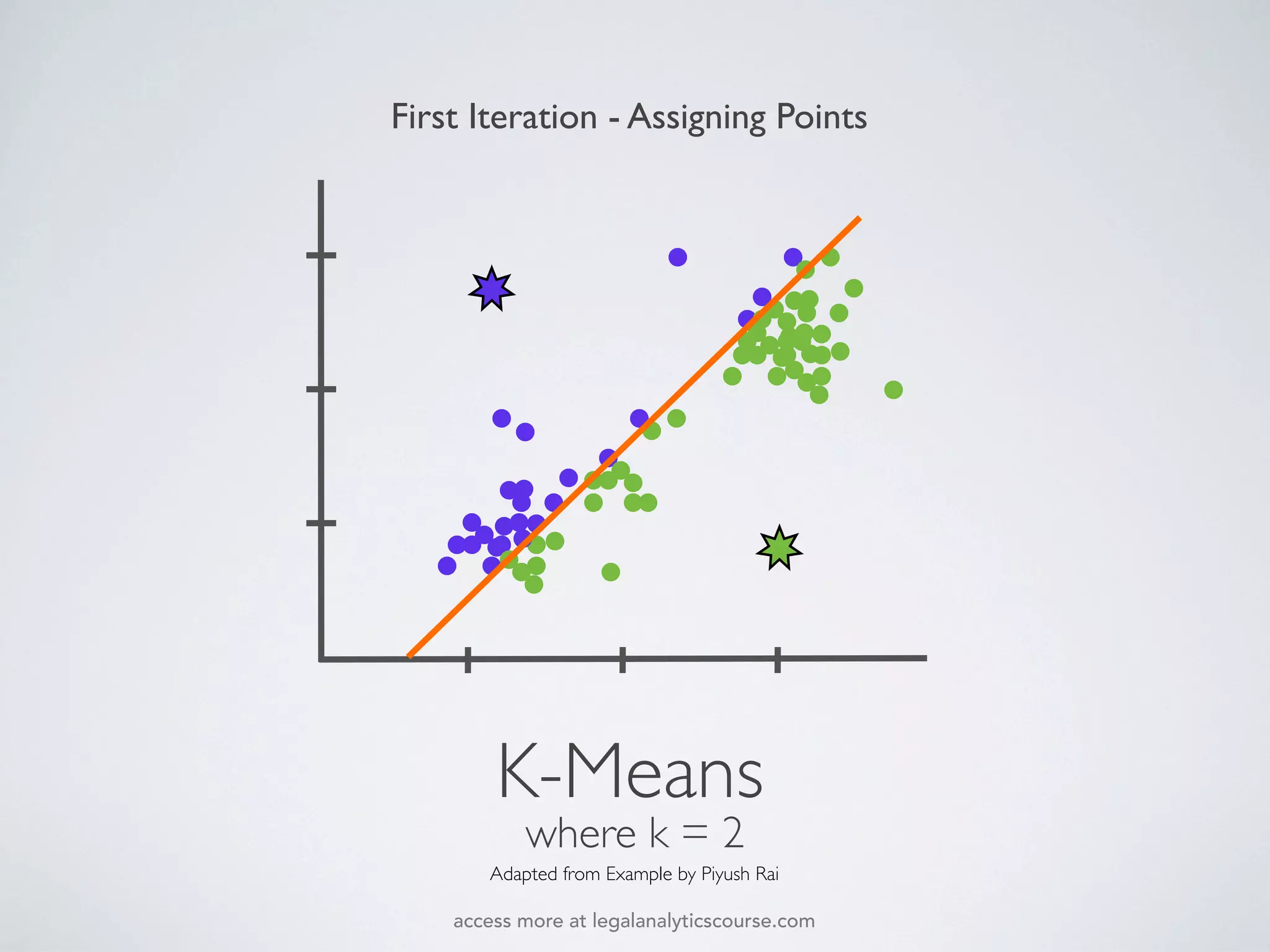
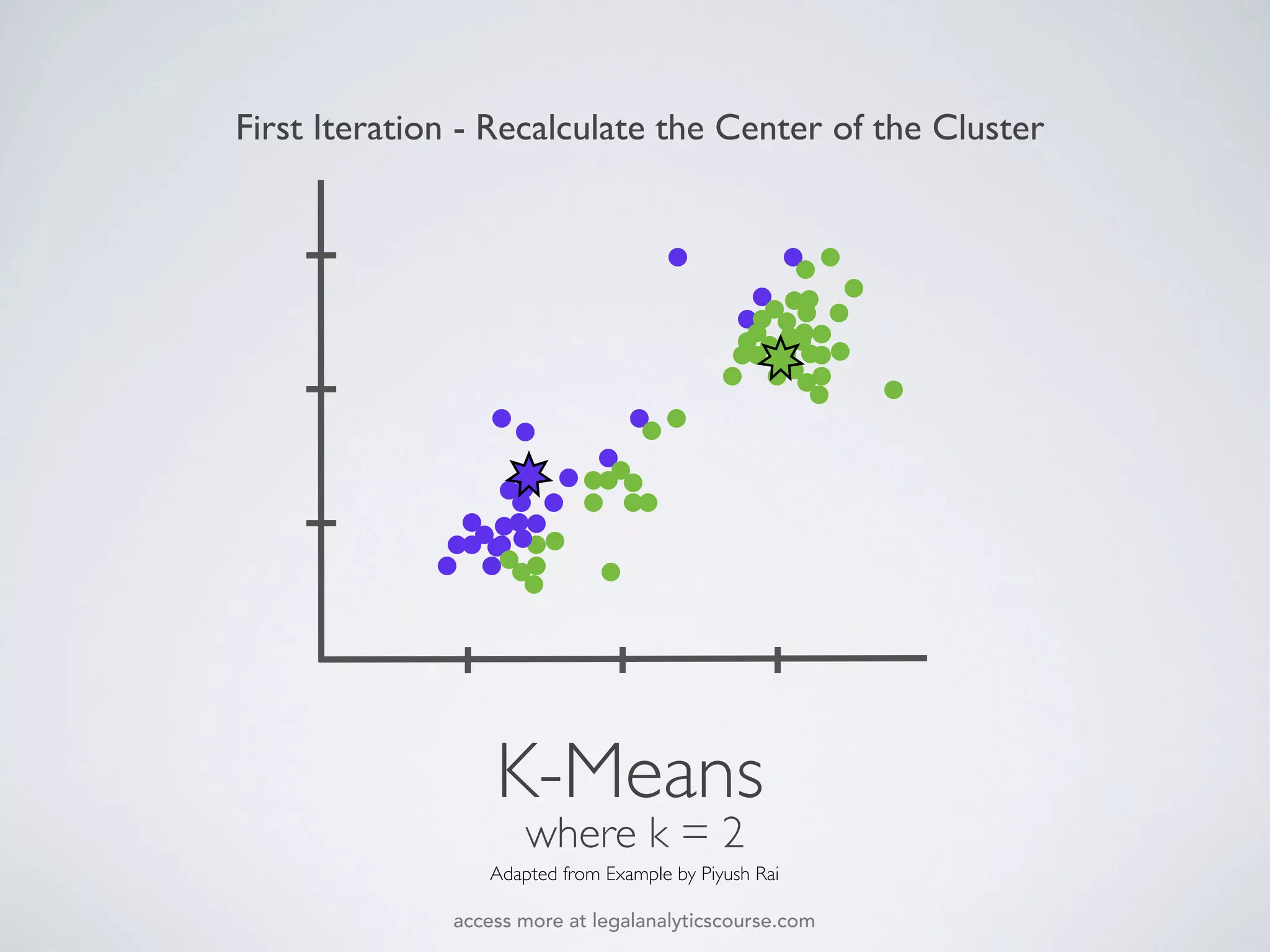
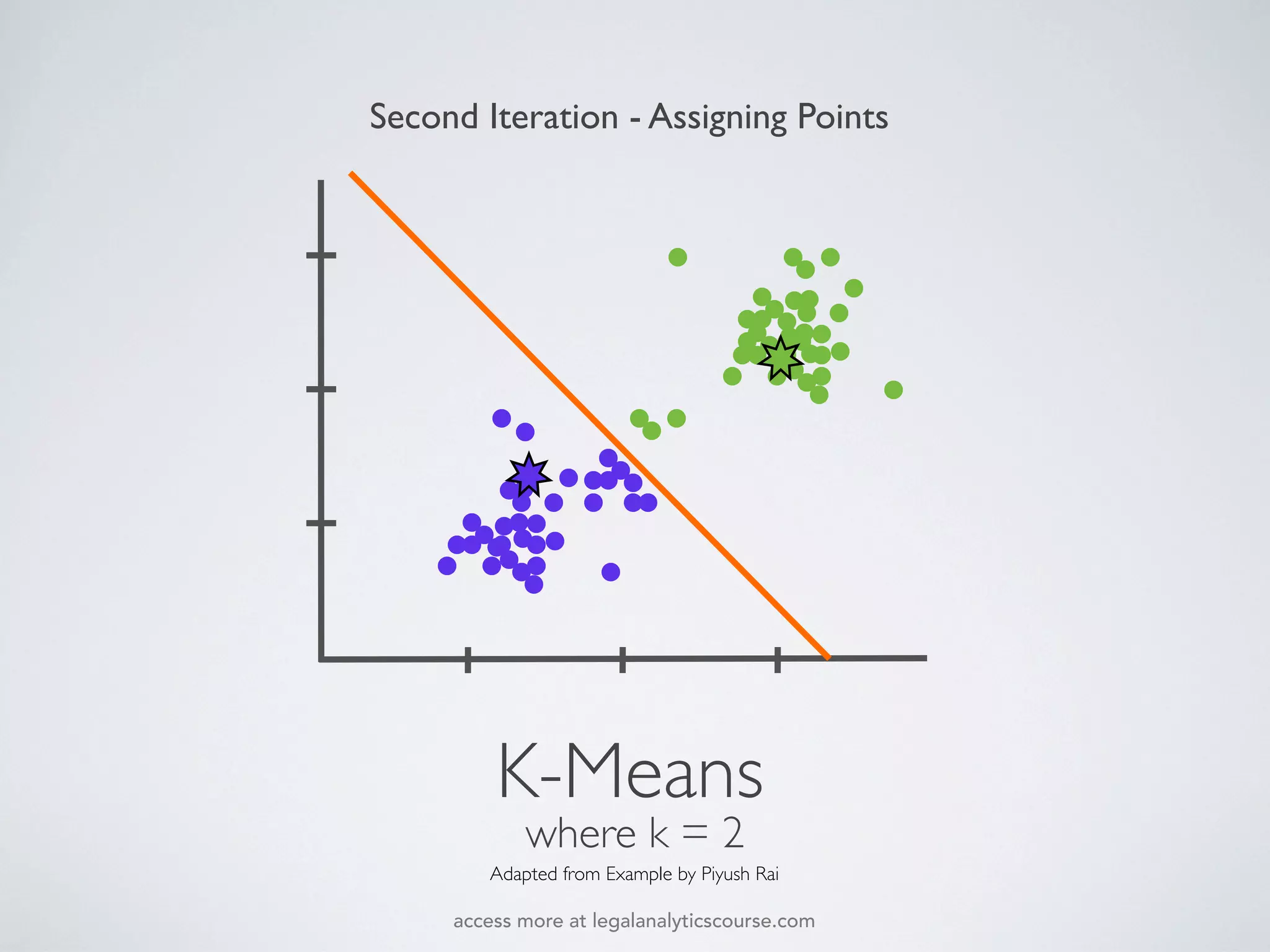
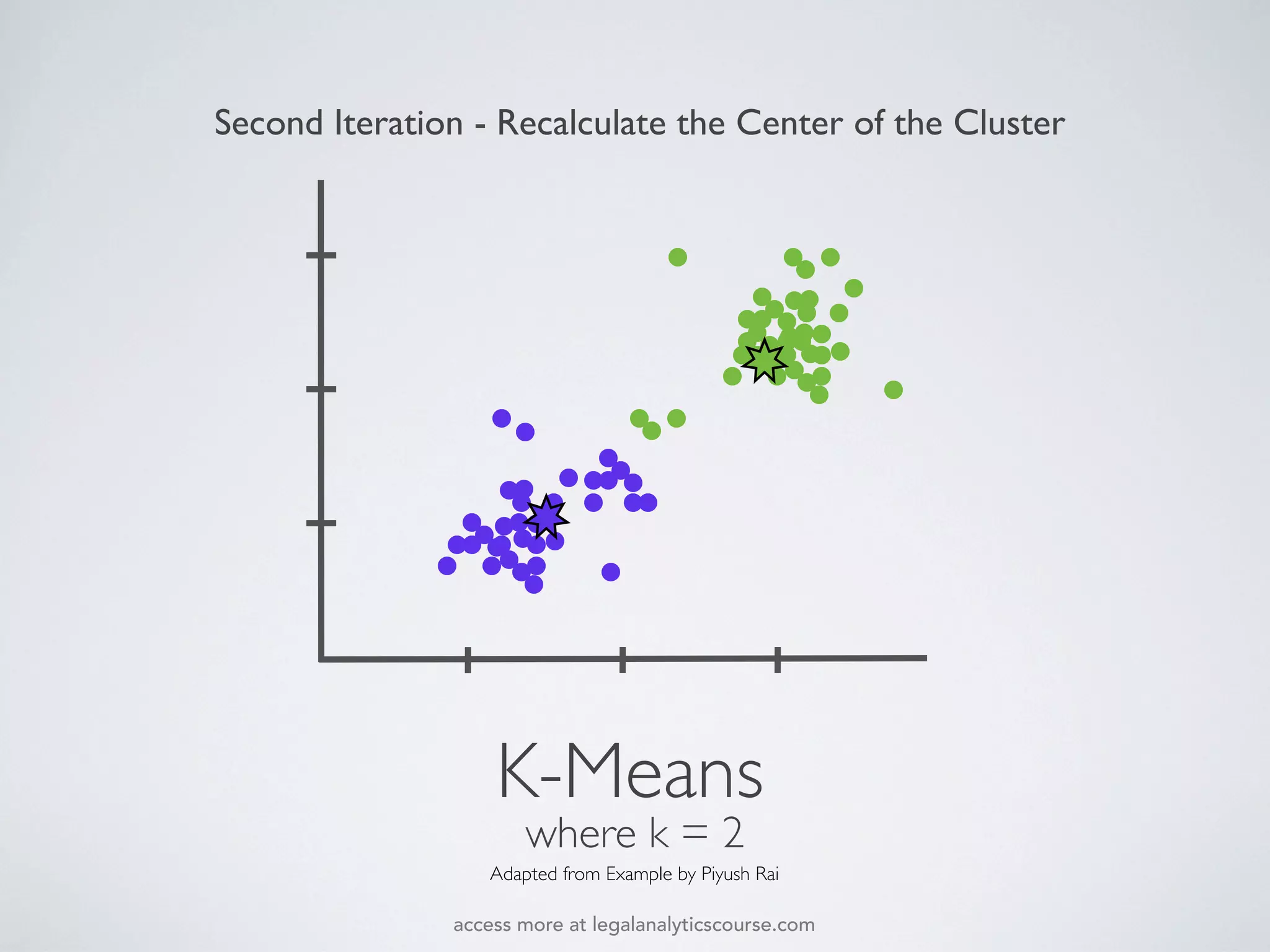
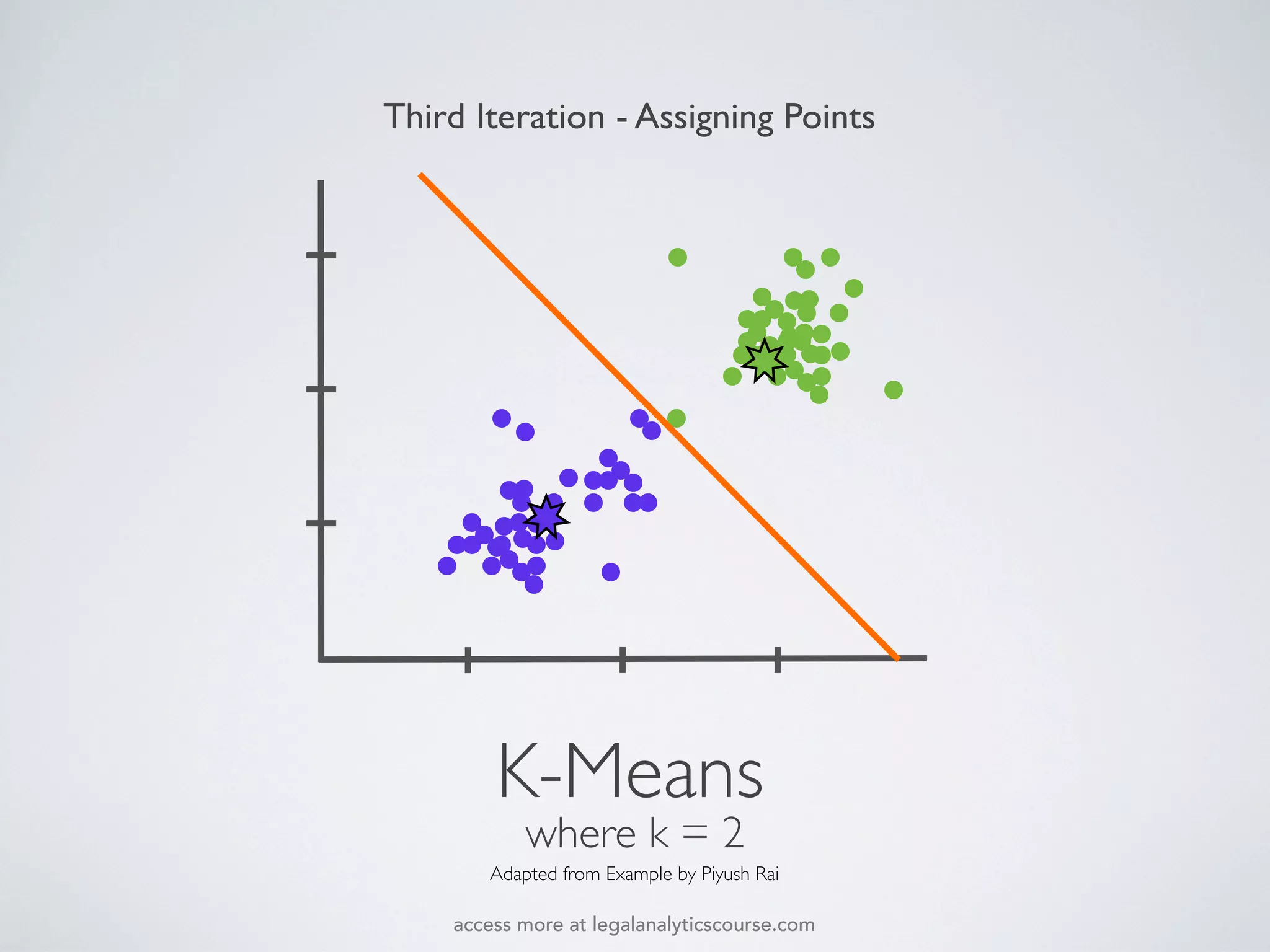
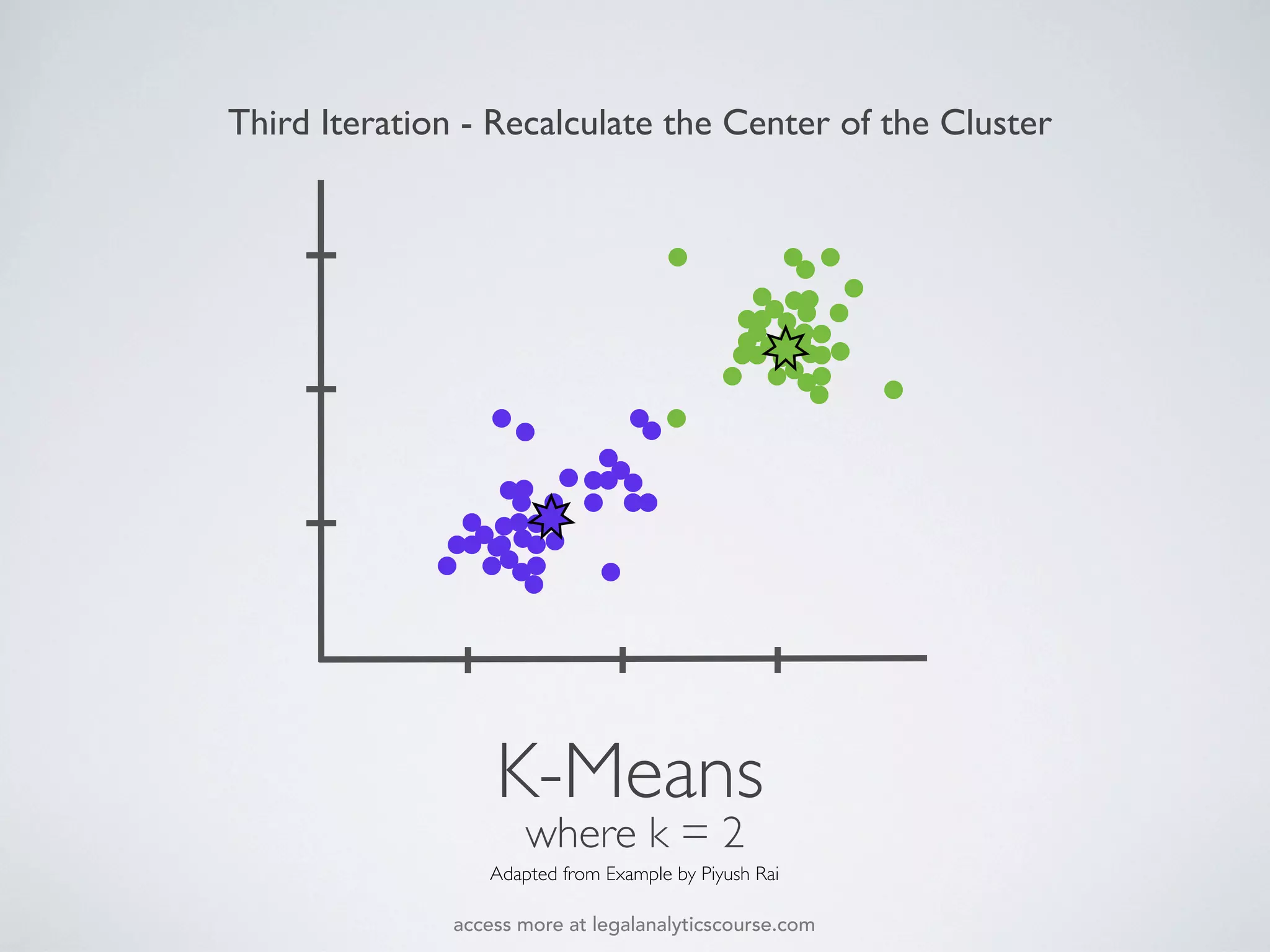




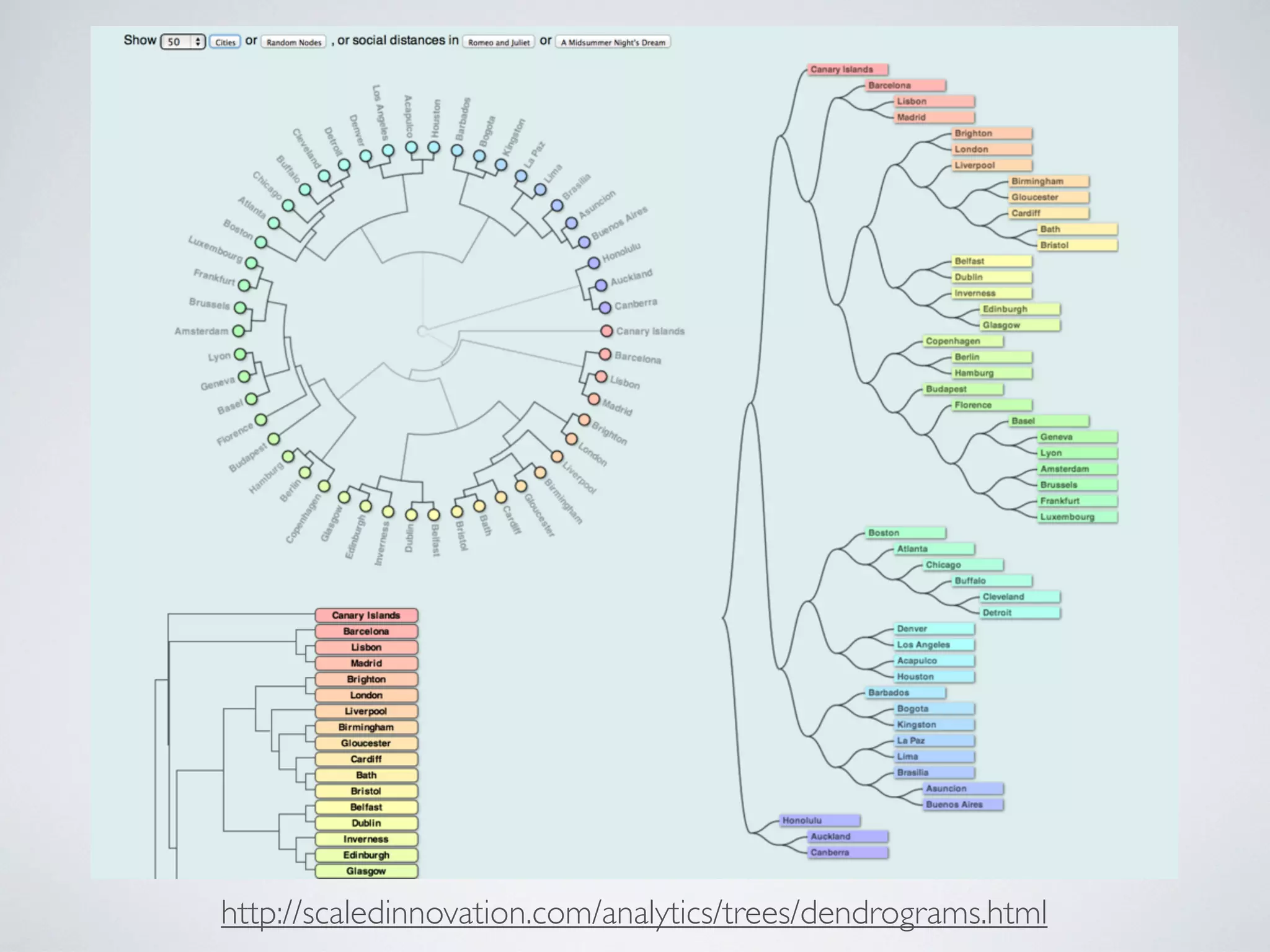

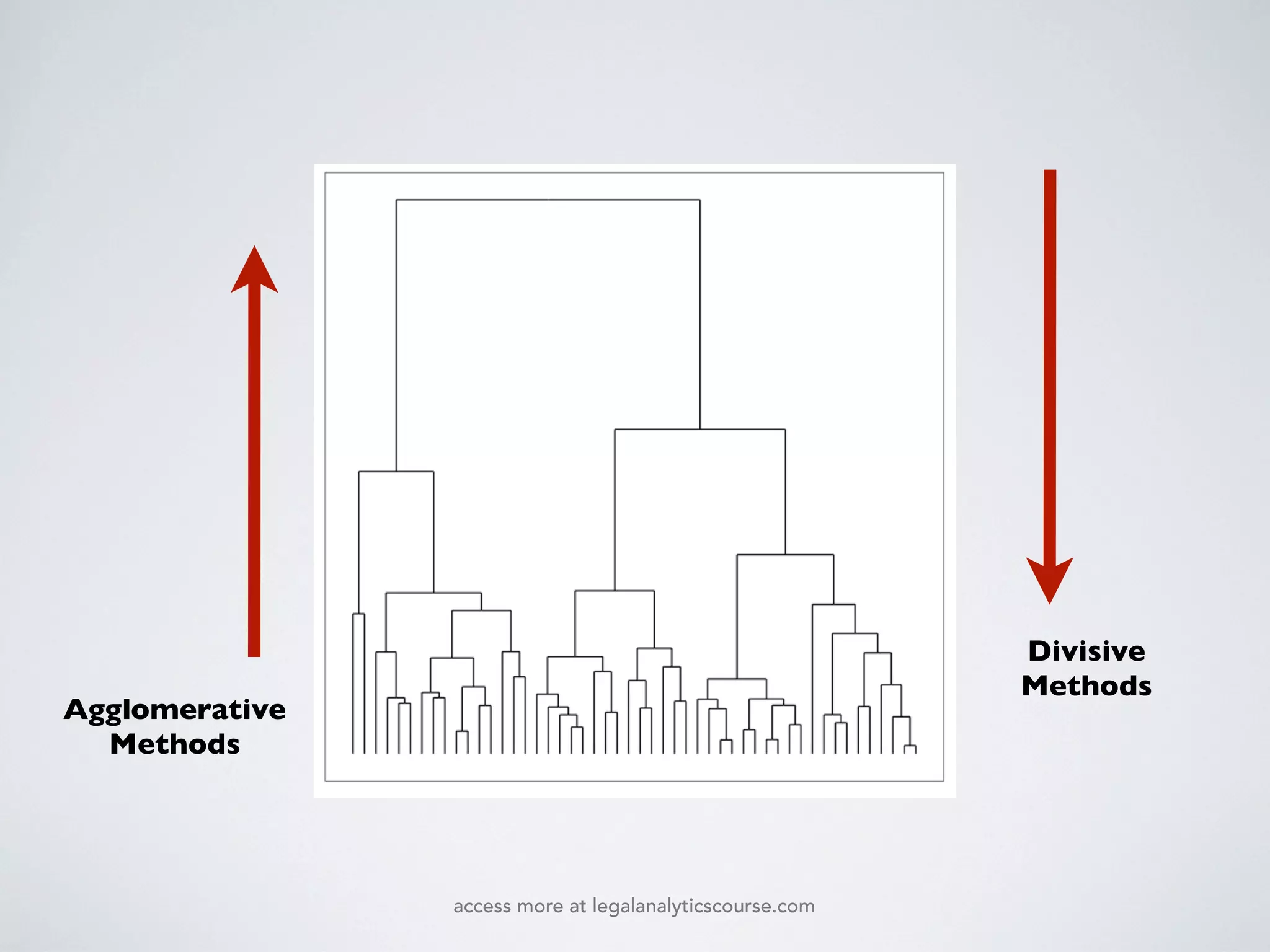
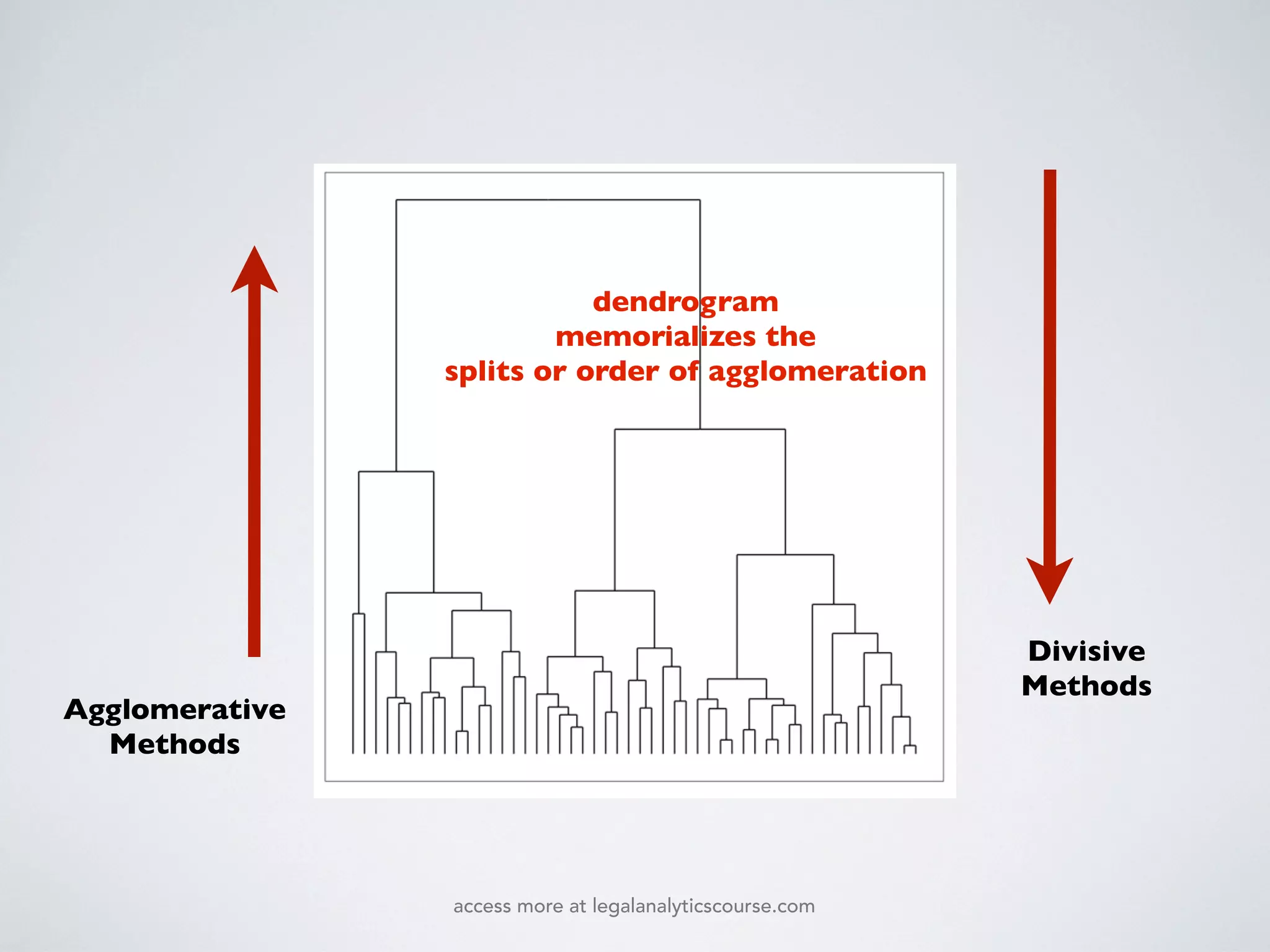




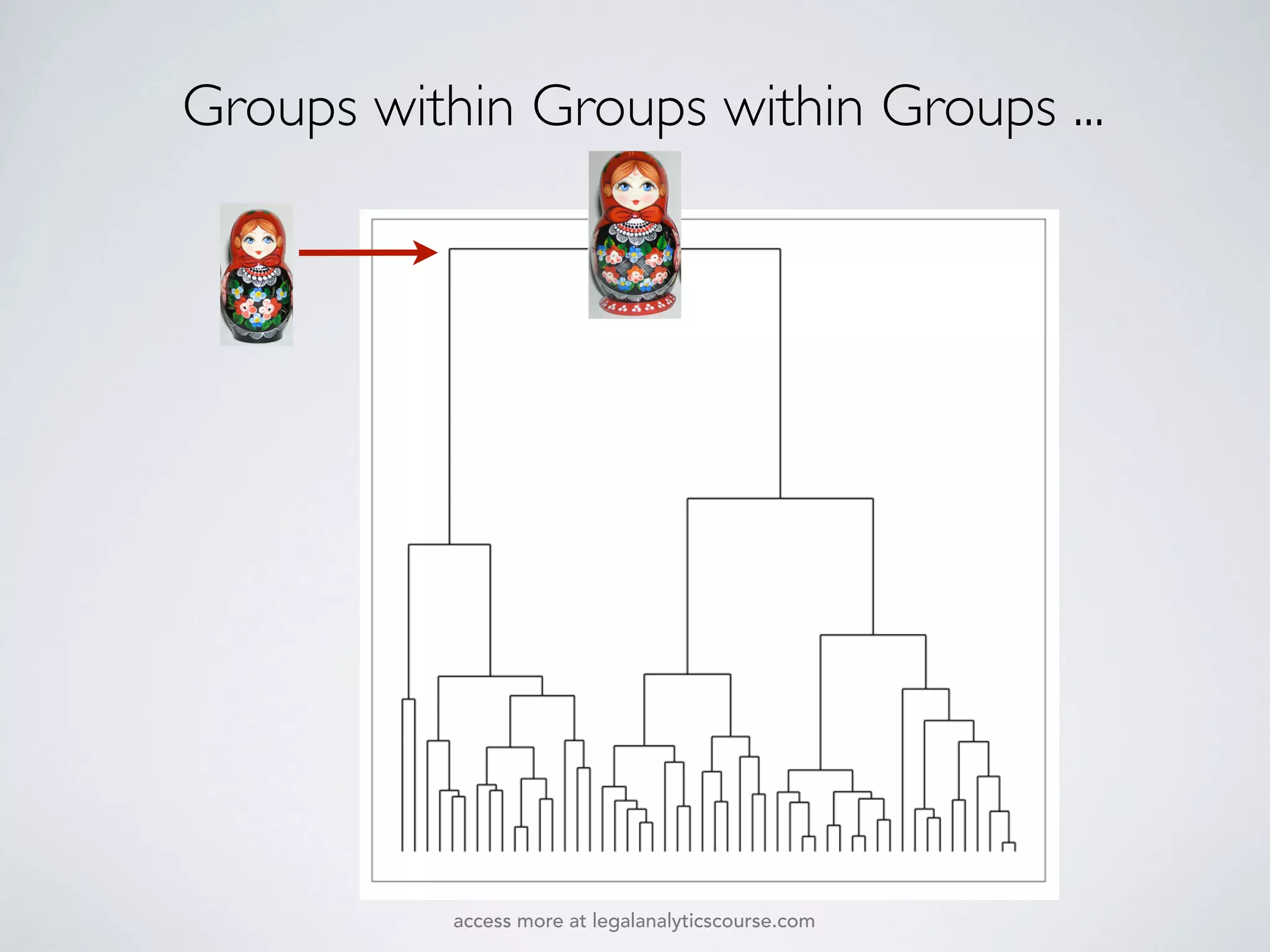
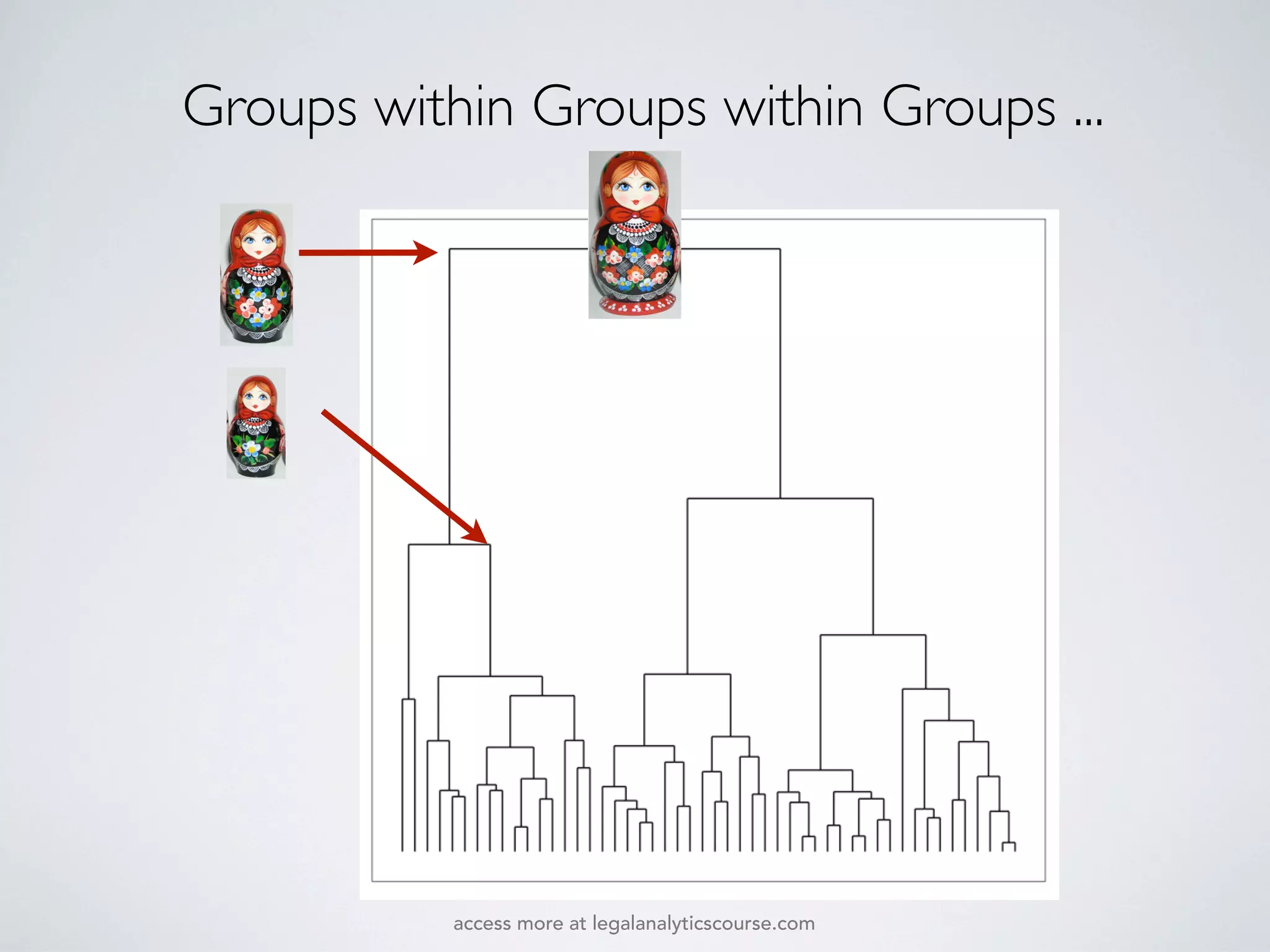
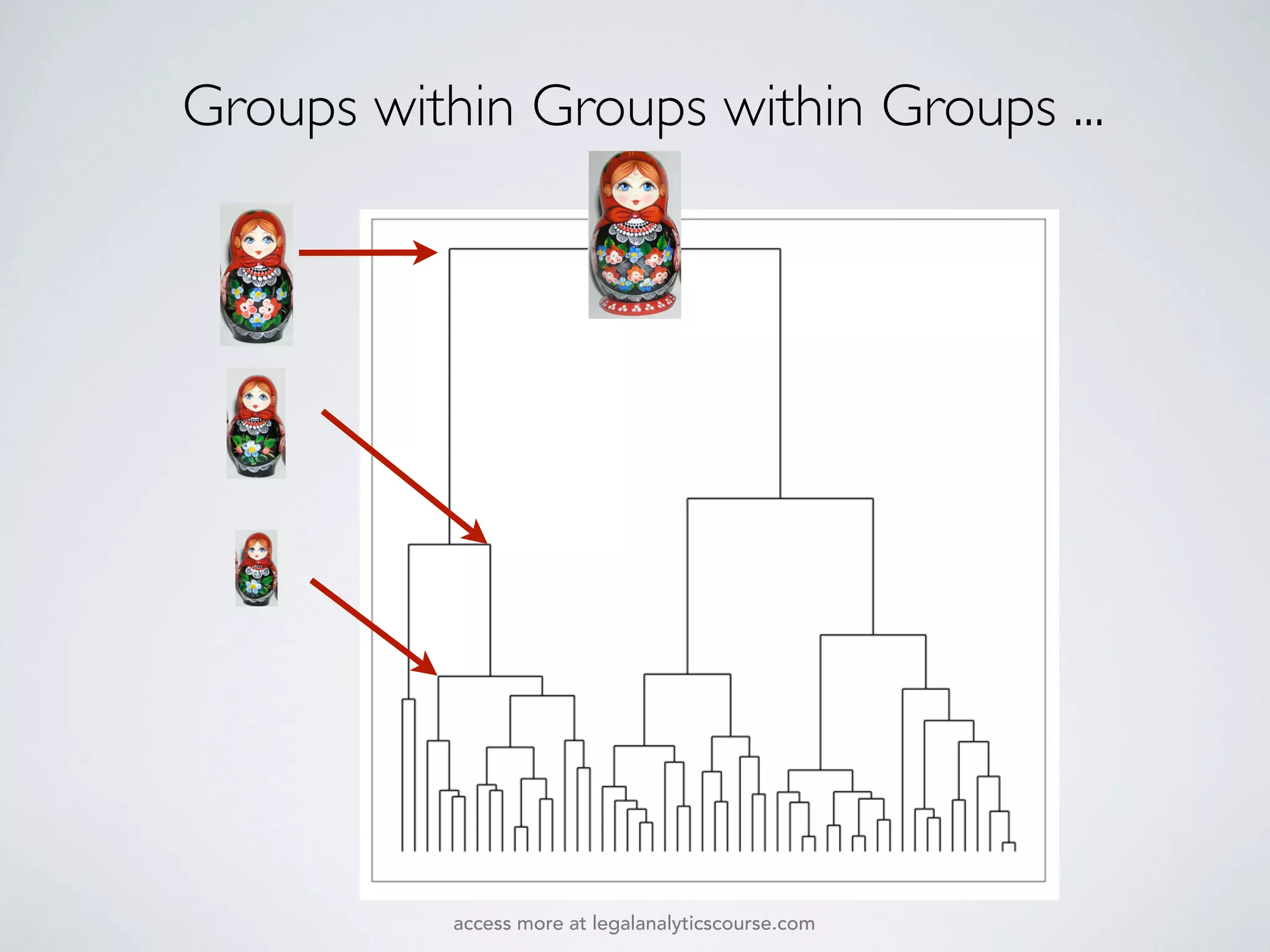
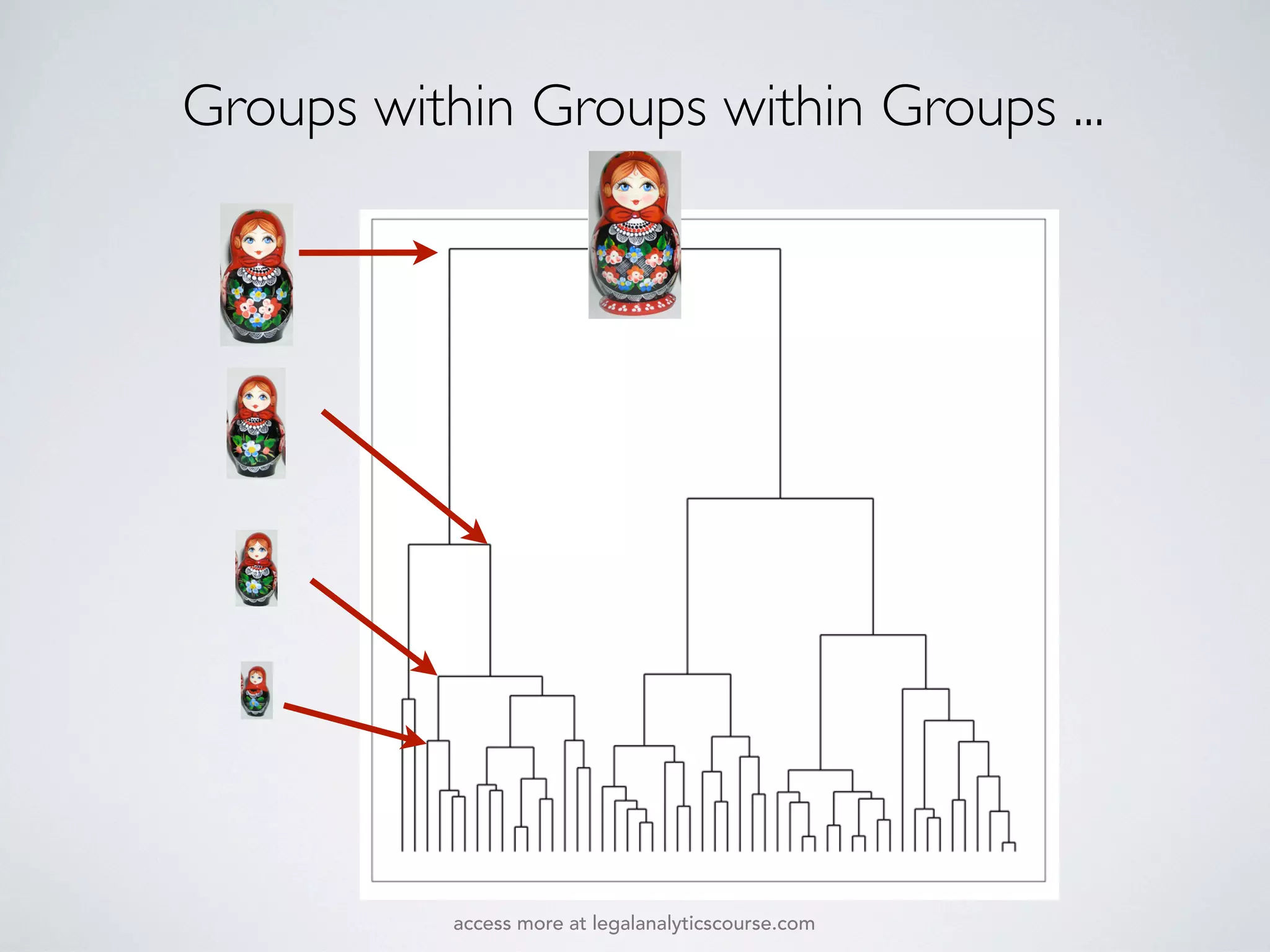
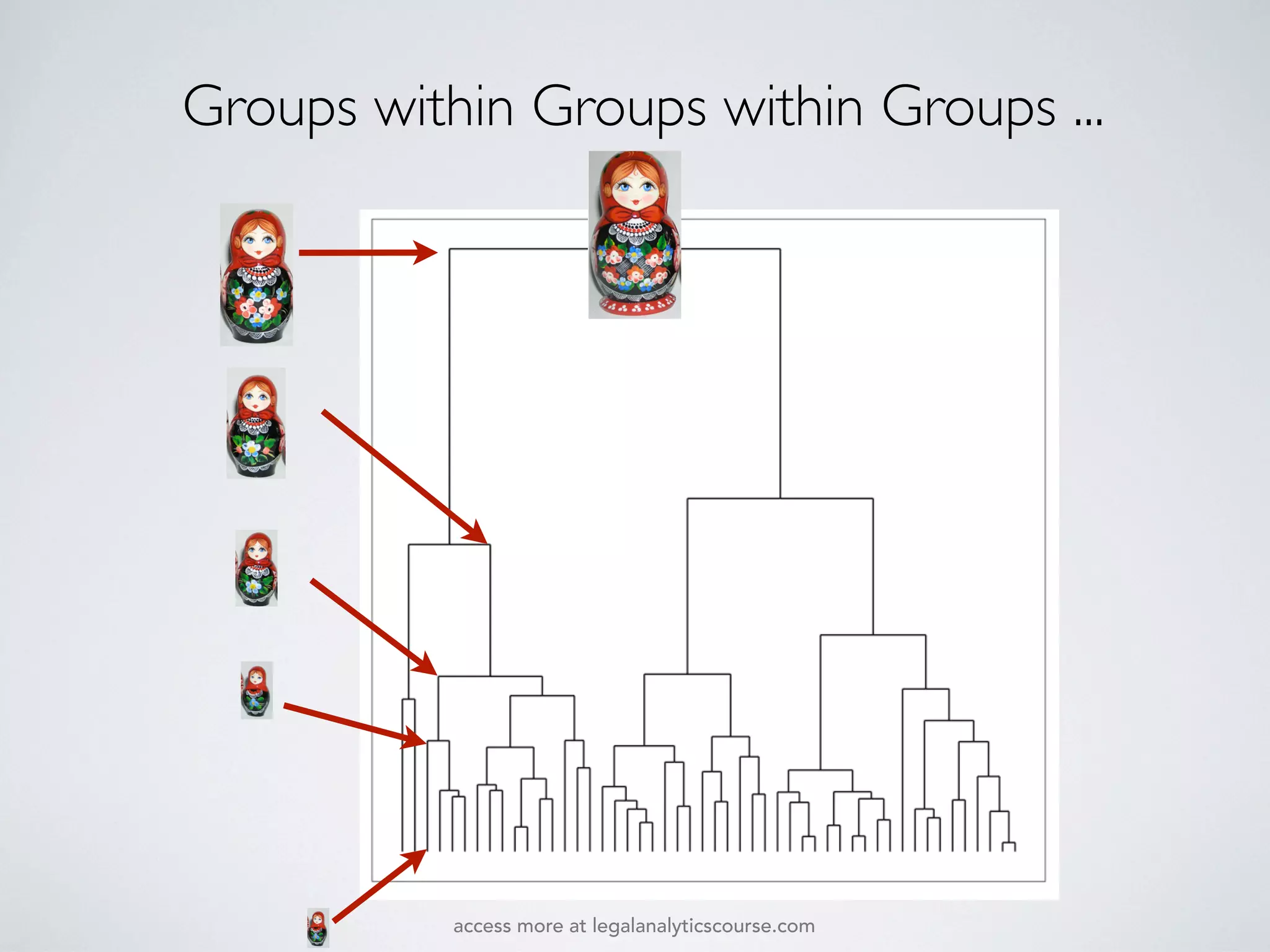




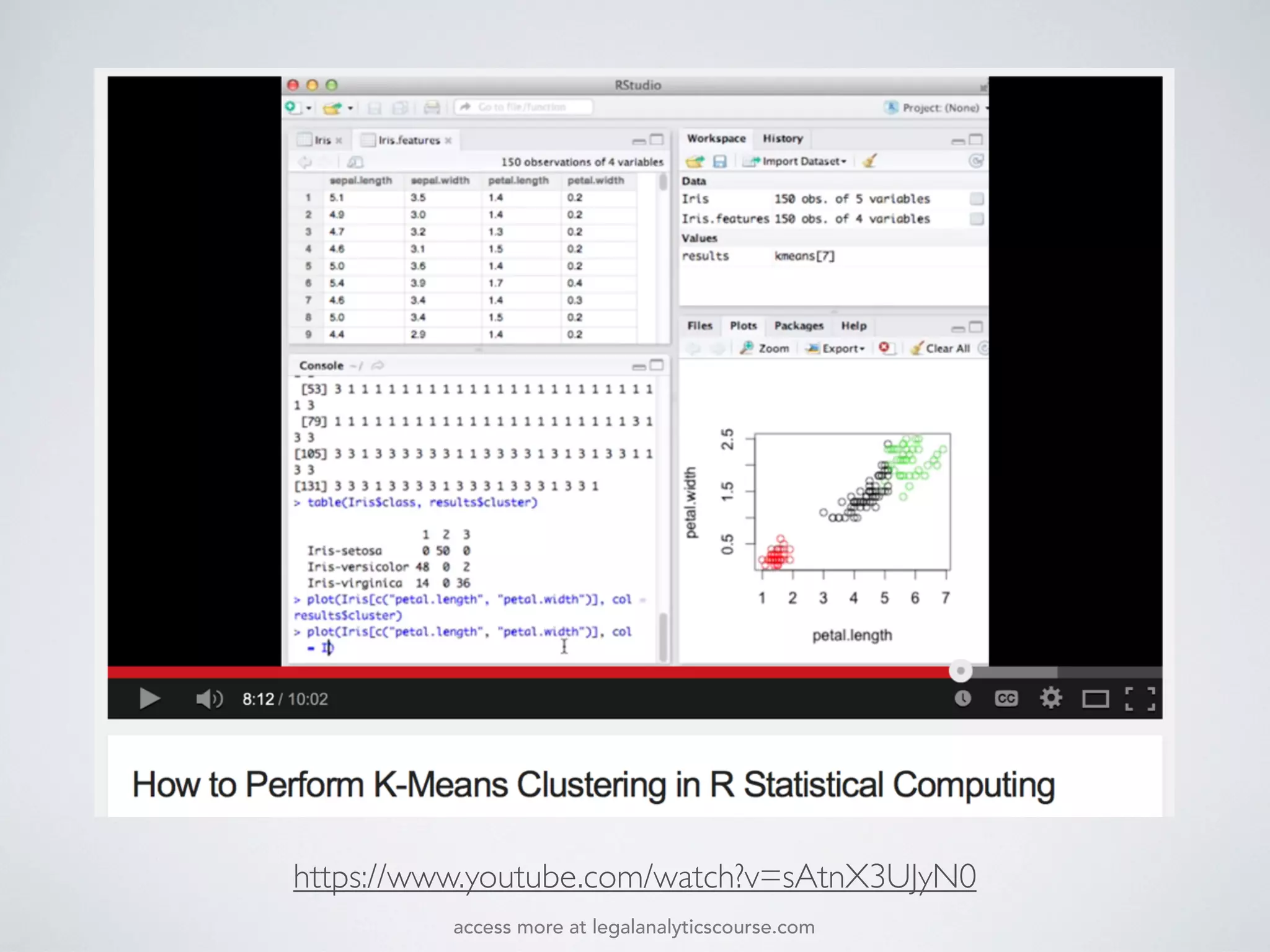
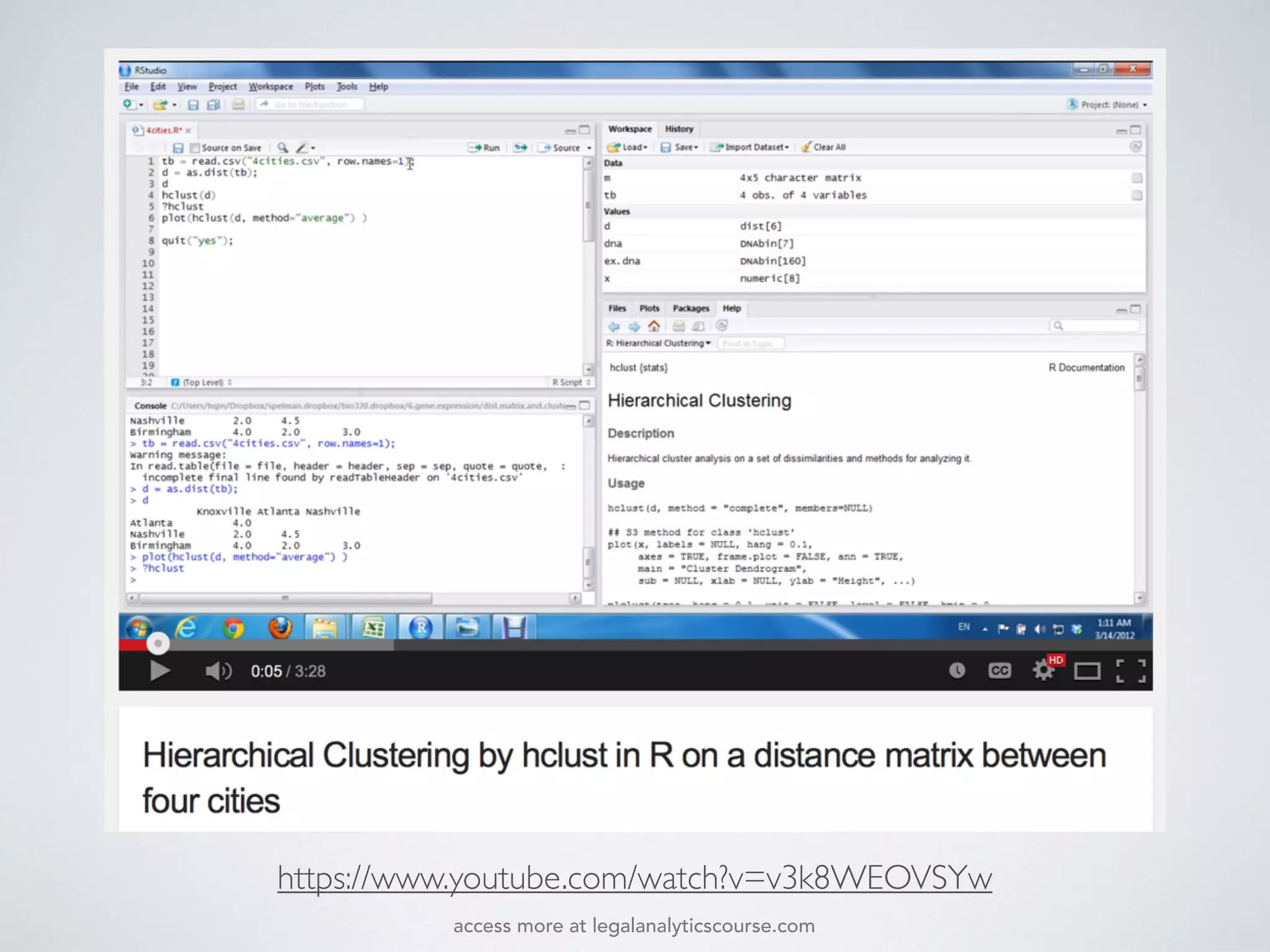






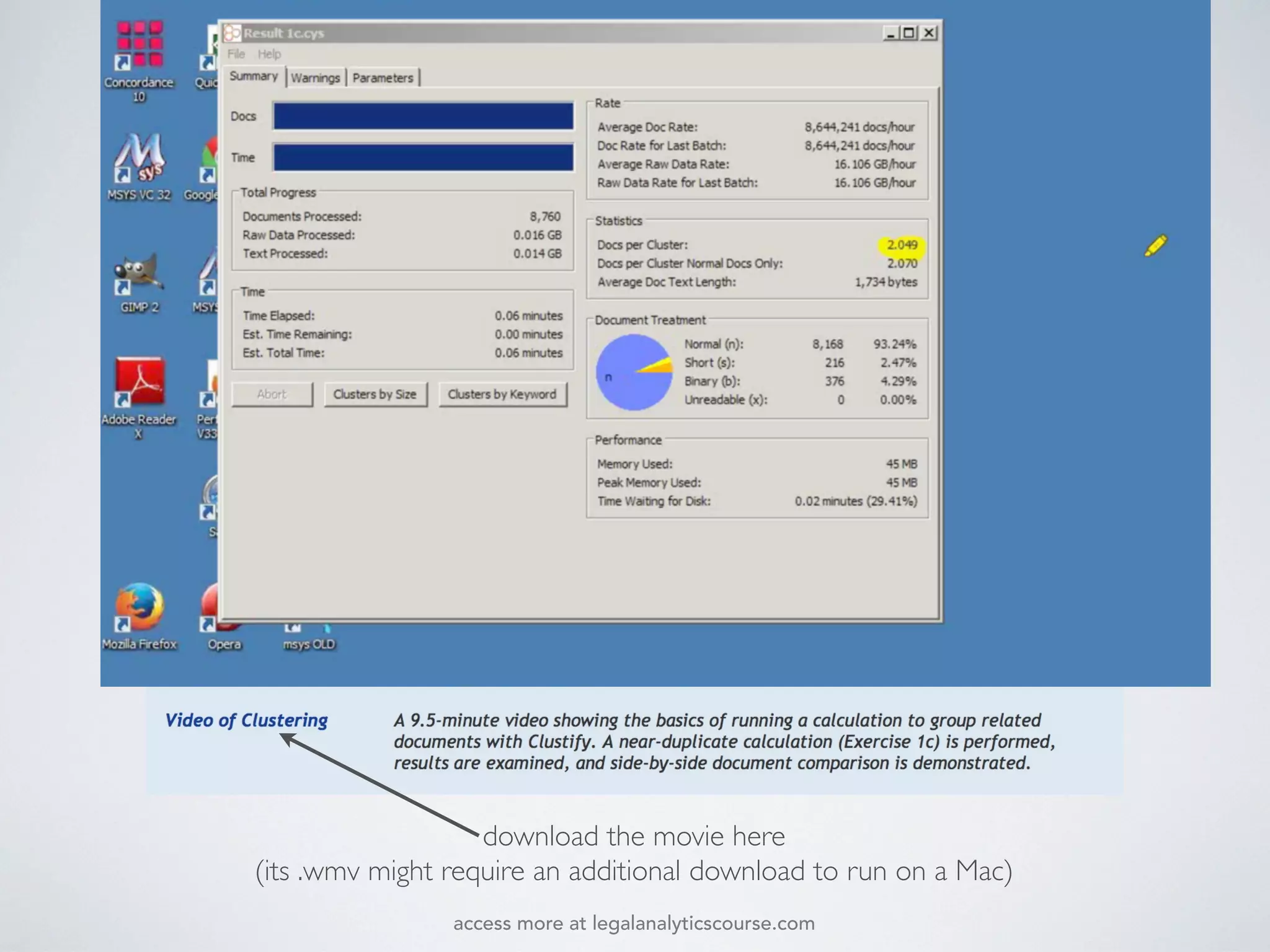





The document discusses k-means and hierarchical clustering, emphasizing their roles as important methods in unsupervised learning for grouping similar objects. It outlines the processes involved in both clustering methods, including the concepts of similarity, distance functions, and the challenges of clustering real n-dimensional data. Additionally, it highlights practical applications in legal analytics and e-discovery, illustrating how clustering can aid in analyzing and retrieving relevant documents.





















































































