![a six part primer
artificial intelligence in law (and beyond)
daniel martin katz
blog | ComputationalLegalStudies.com
corp | LexPredict.com
page | DanielMartinKatz.com
edu | chicago kent college of law
lab | TheLawLab.com
[ a.i. + law ]](https://image.slidesharecdn.com/ailawjuly26-160728000254/75/Artificial-Intelligence-and-Law-A-Primer-1-2048.jpg)
































































































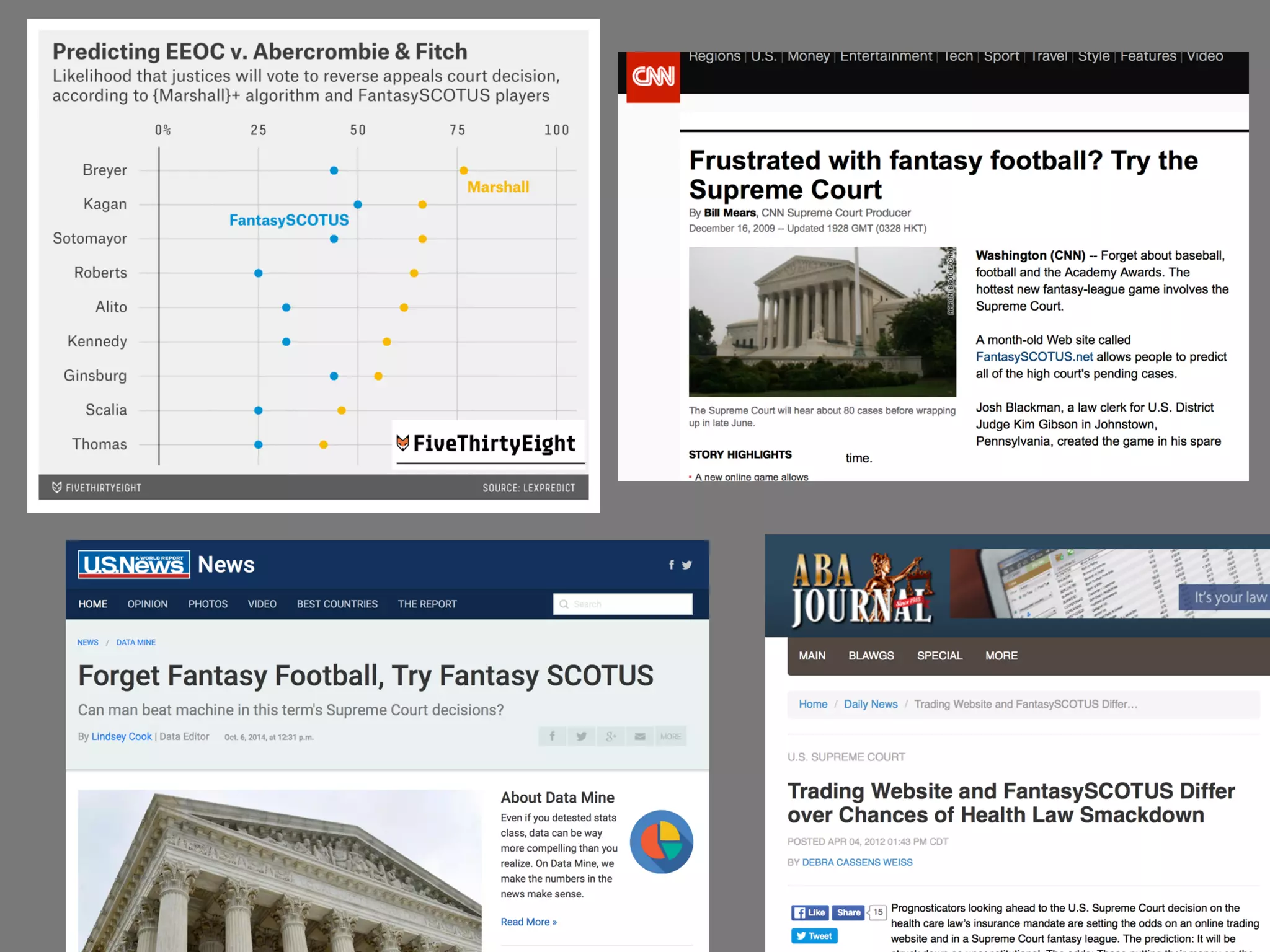


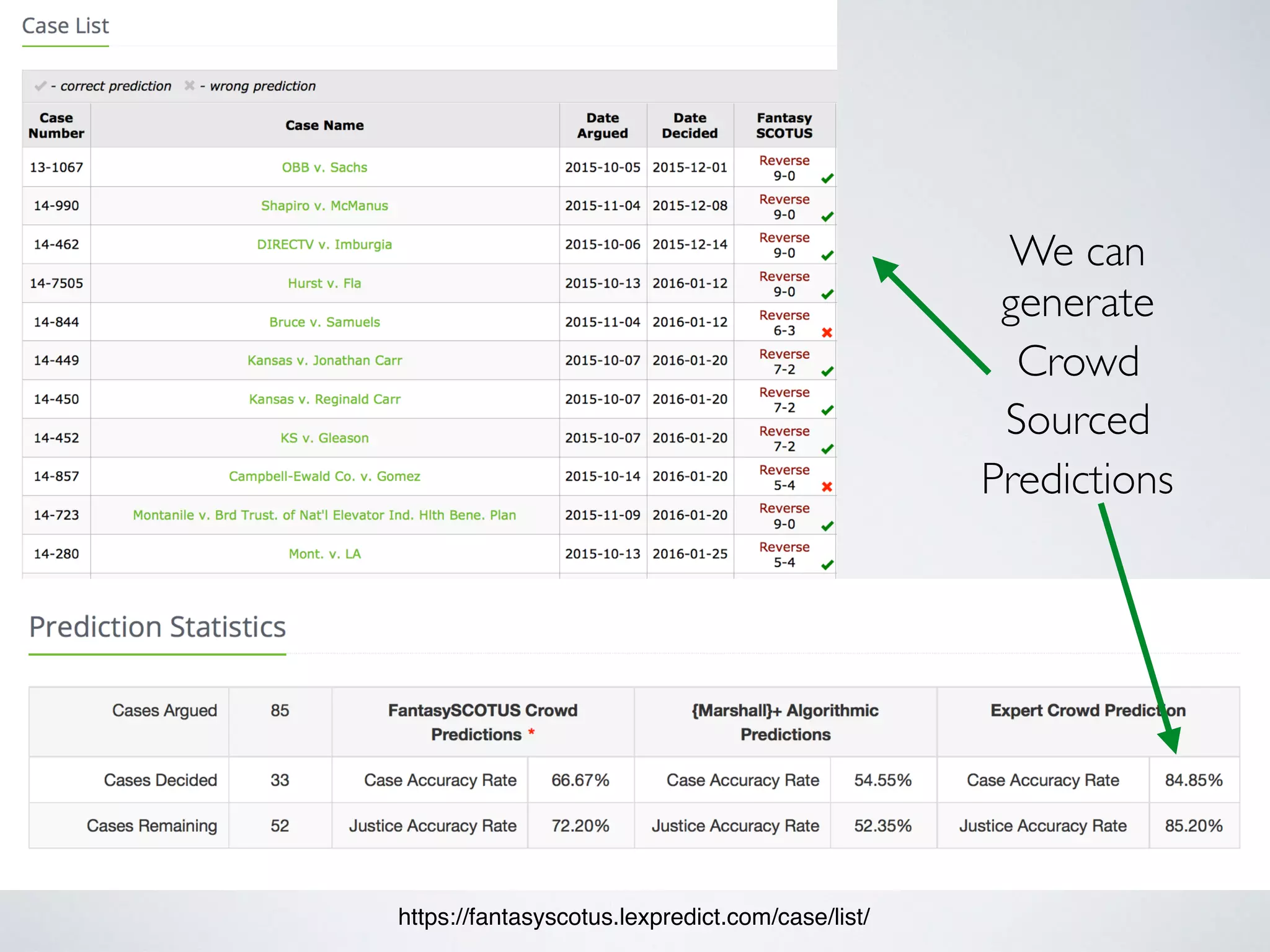



























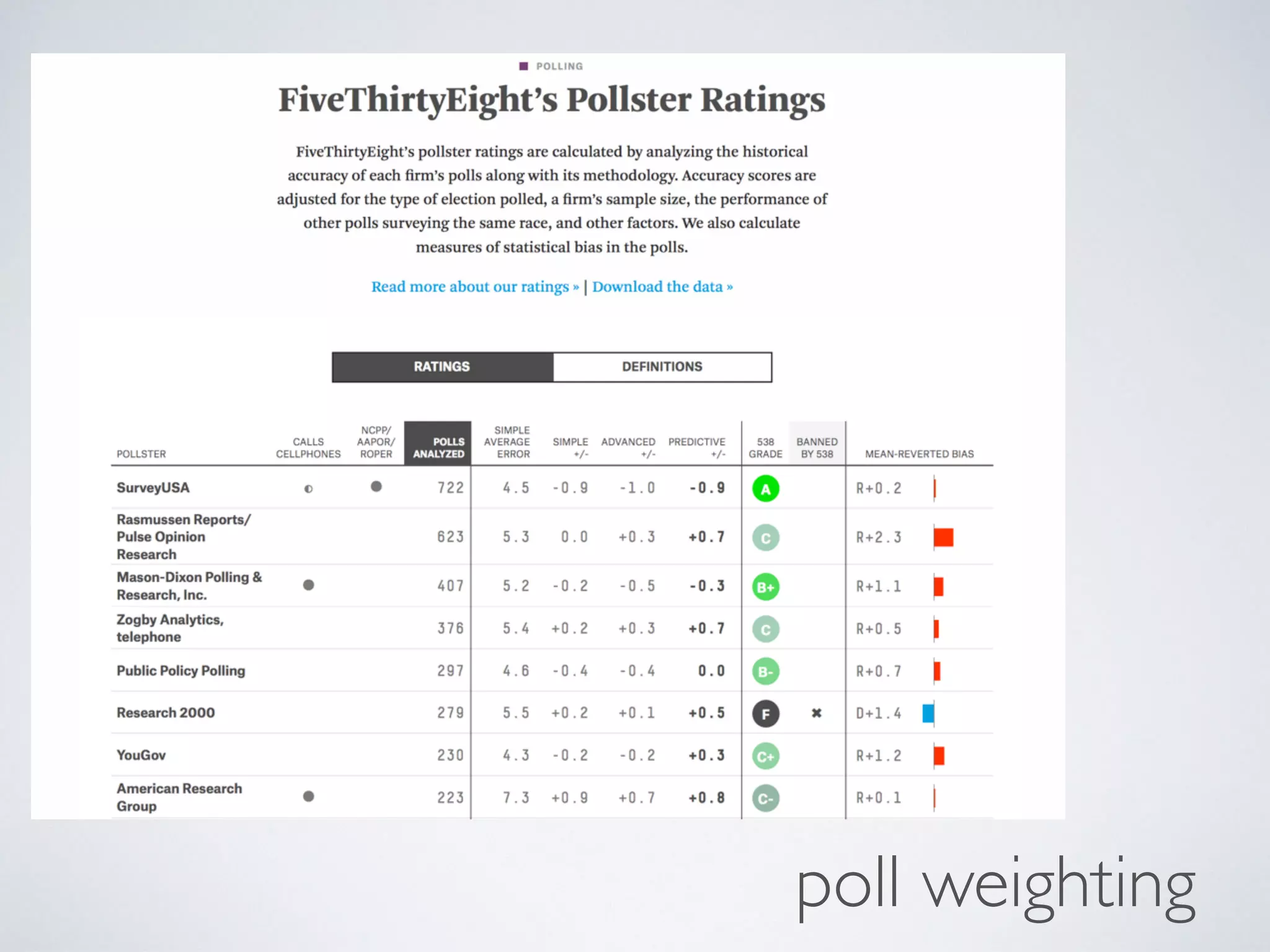


























































































































































This document discusses the application of artificial intelligence (AI) in the legal field, highlighting the debate between rules-based and data-driven AI approaches. It elaborates on the potential of various AI technologies, such as expert systems and predictive analytics, to improve access to legal services and decision-making processes. The author expresses skepticism toward rules-based AI for broader applications while emphasizing the importance of data-driven methods, ultimately advocating for a blend of expert input, crowdsourcing, and algorithms to enhance predictive accuracy in legal contexts.





































































































