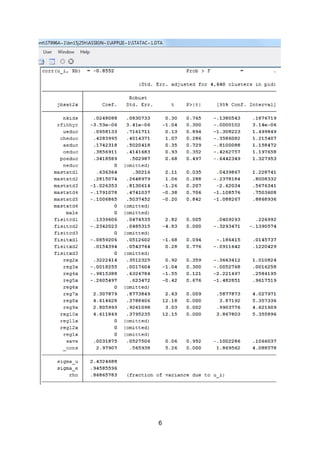
This document summarizes the results of an analysis of factors influencing individuals' job satisfaction using panel data from the British Household Panel Survey. A fixed effects model was preferred to a random effects model based on a Hausman test. The analysis found that being married, having an improved financial situation compared to the previous year, and living outside of London were associated with higher levels of job satisfaction, while a worse financial situation was associated with lower satisfaction. Regional differences in satisfaction were also observed.





![5
Reference List
McManus, P.A. 2011. Introduction to Regression Models for Panel Data Analysis. [Online].
[Accessed 14th May 2016]. Available from:
http://www.indiana.edu/~wim/docs/10_7_2011_slides.pdf.
Appendices
Appendix 1:
Appendix 2:
Appendix 3: (on next page for easier viewing)](https://image.slidesharecdn.com/e98c7161-8bce-48ab-8ccb-772d25247e4f-160722150855/85/200994363-5-320.jpg)