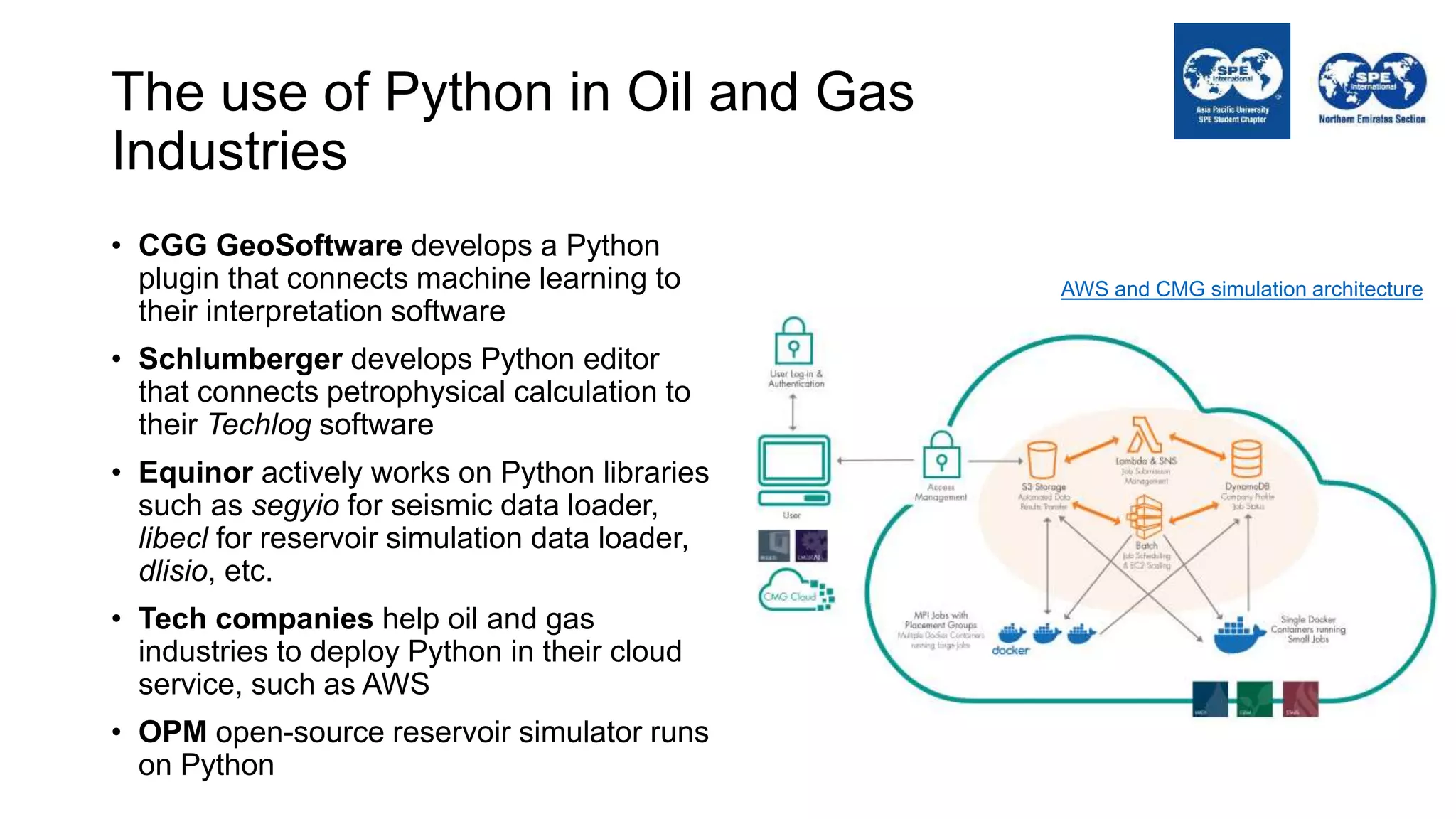
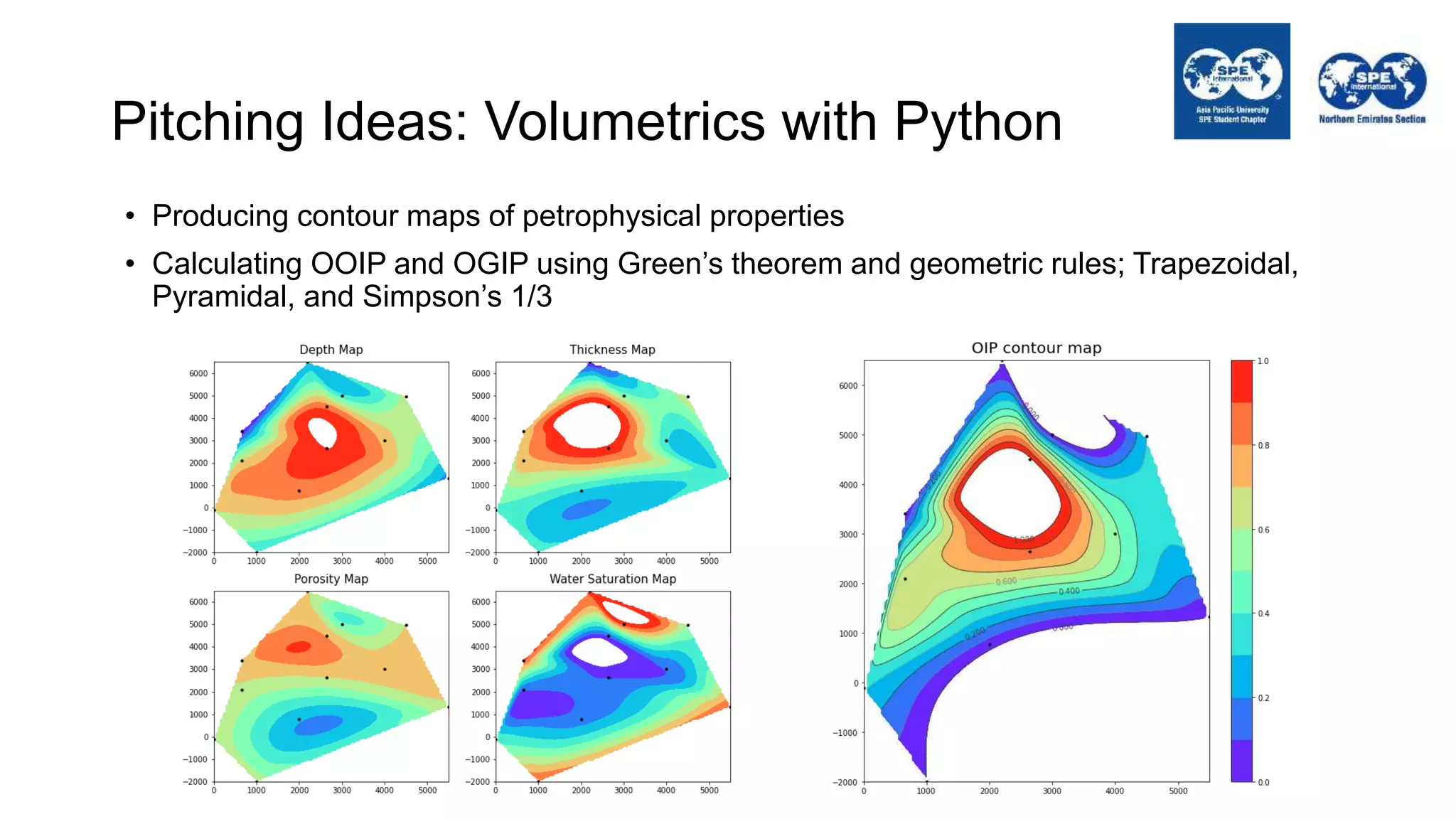
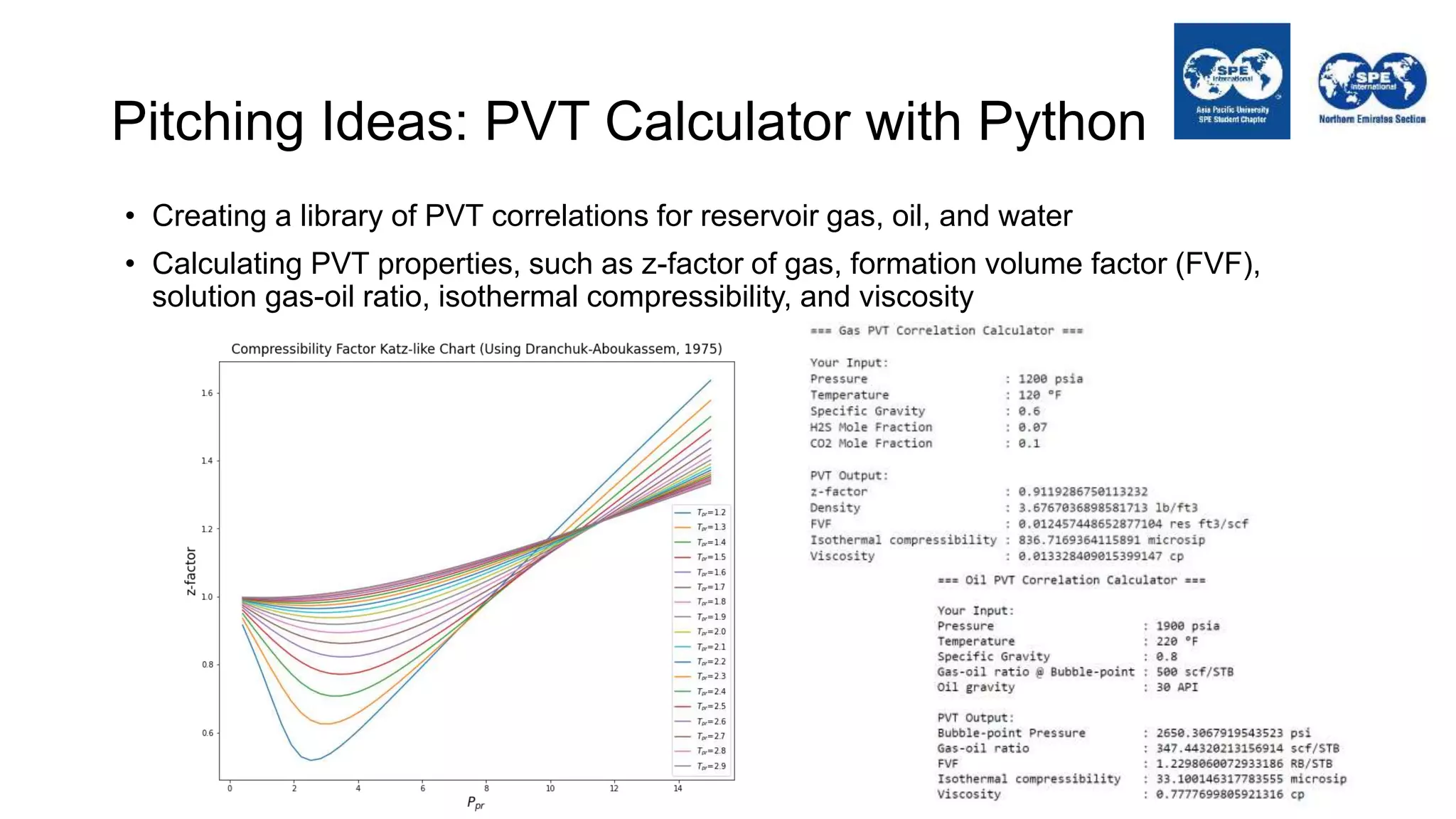
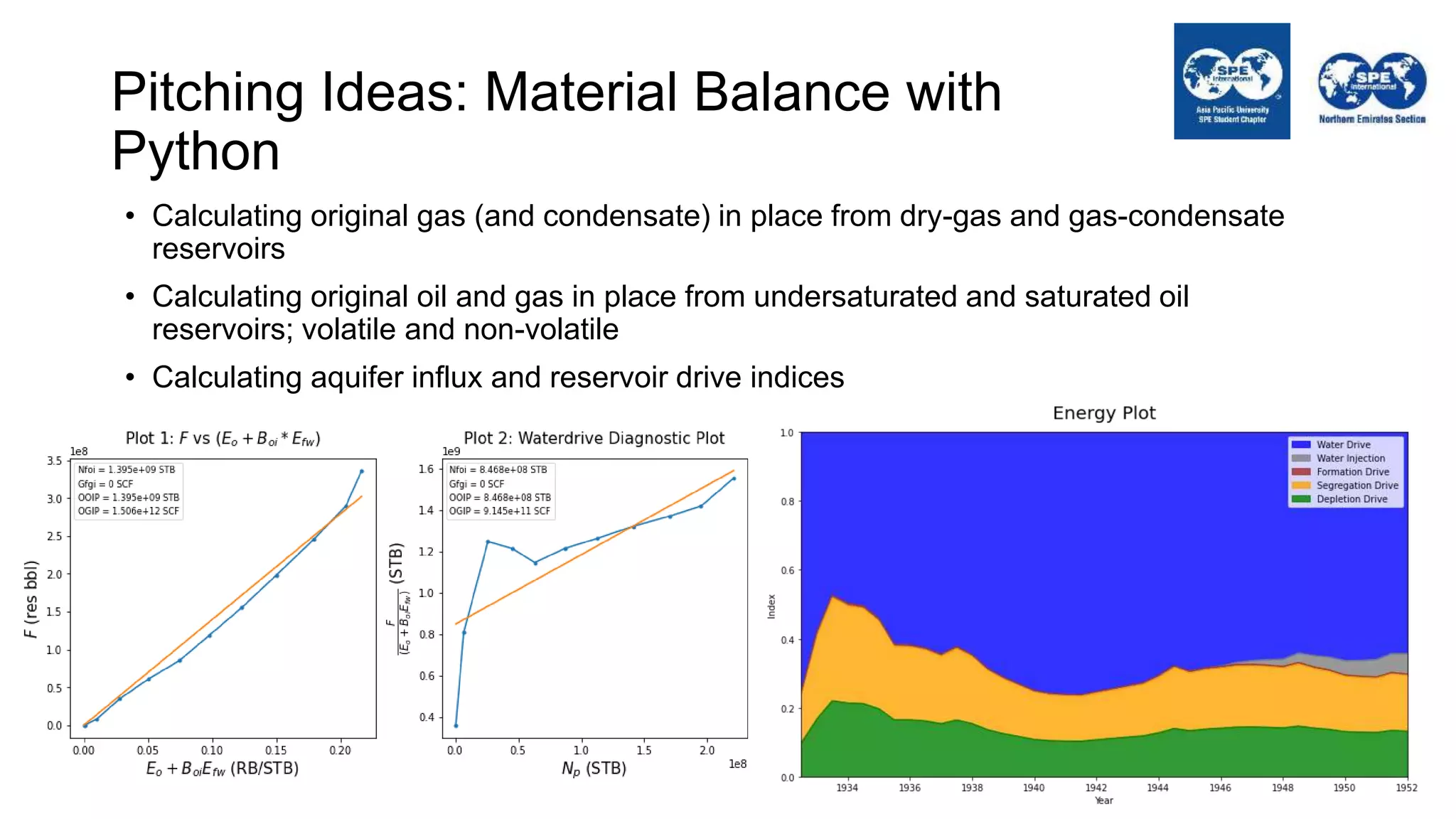
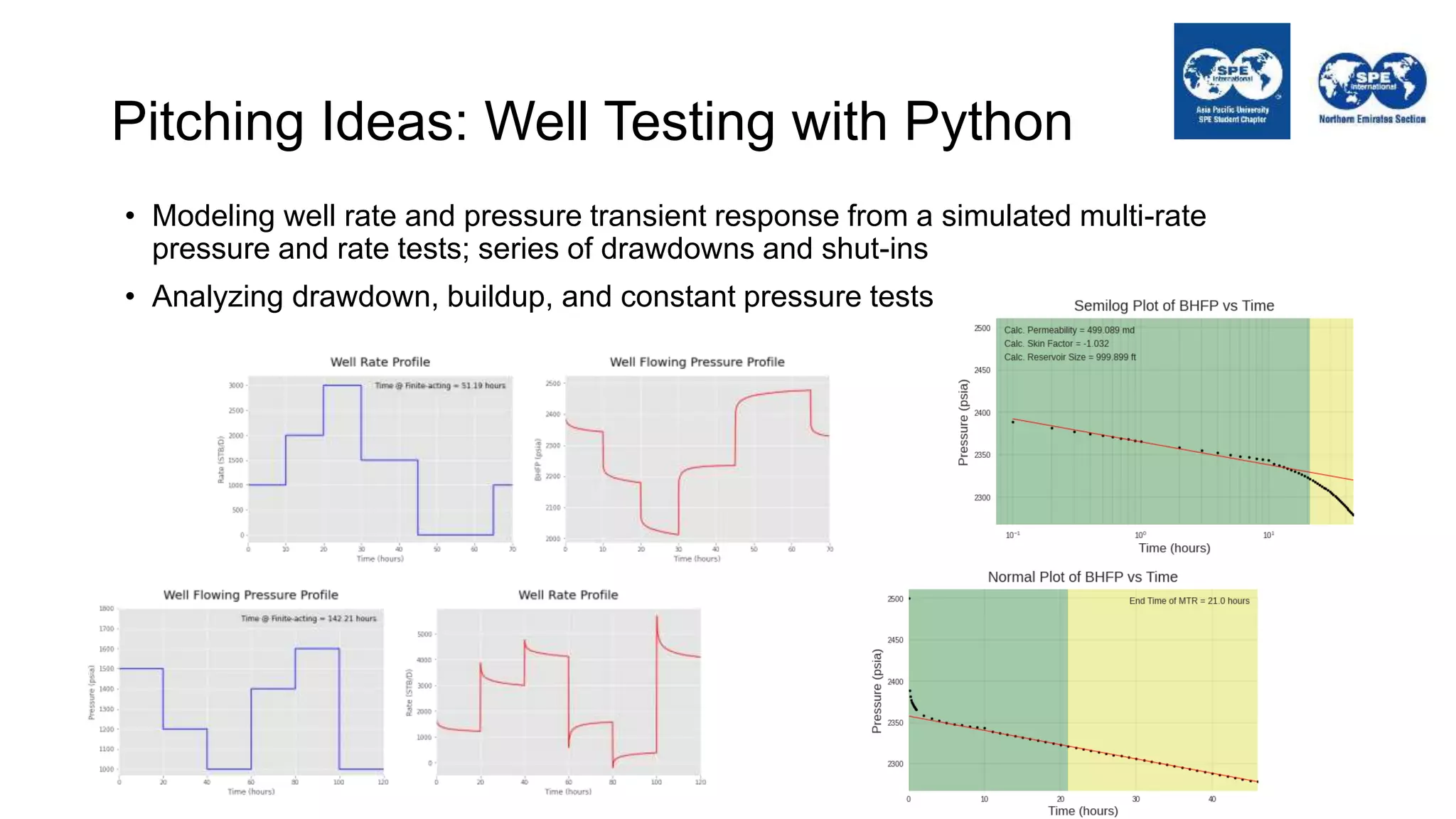
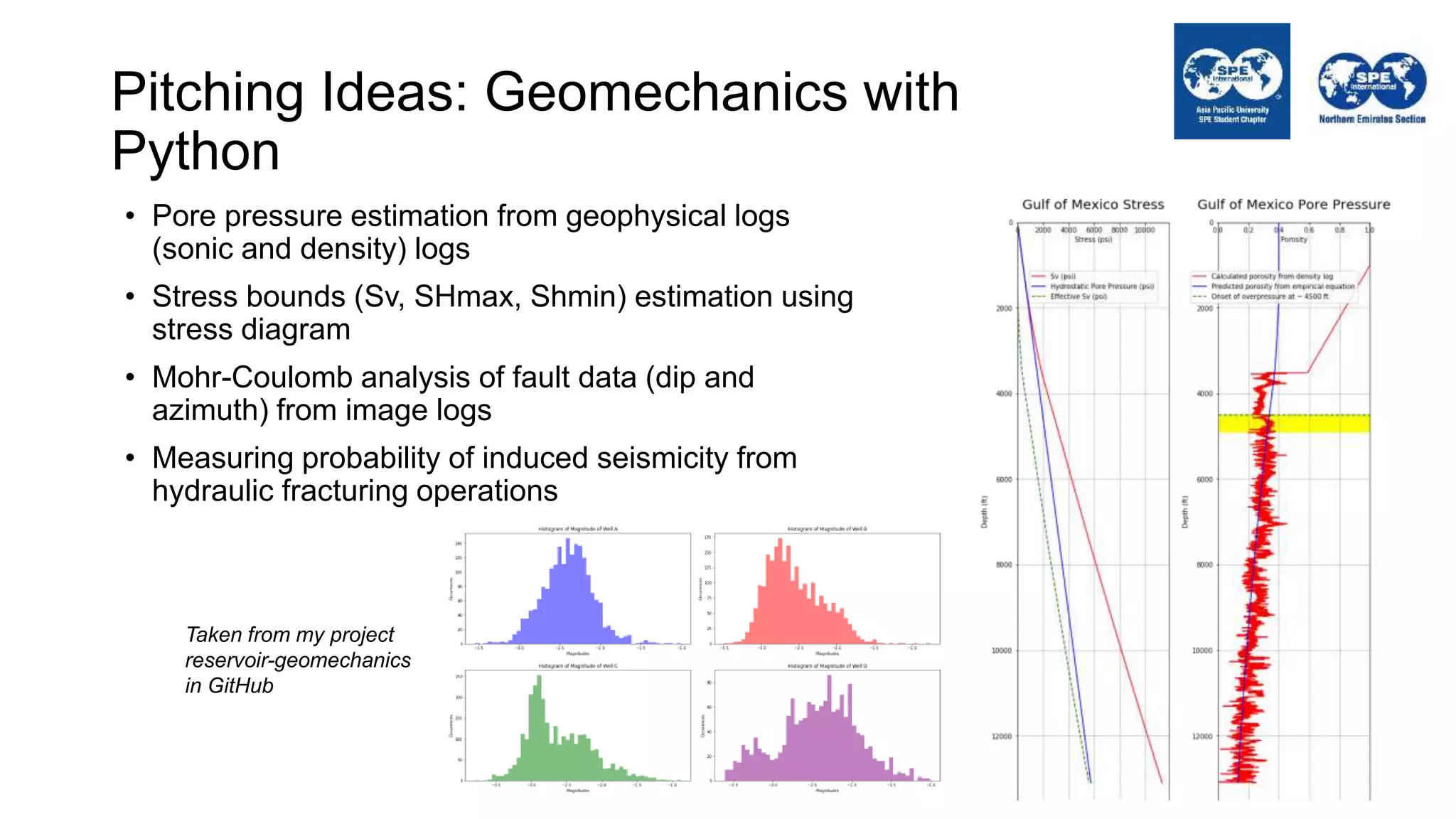
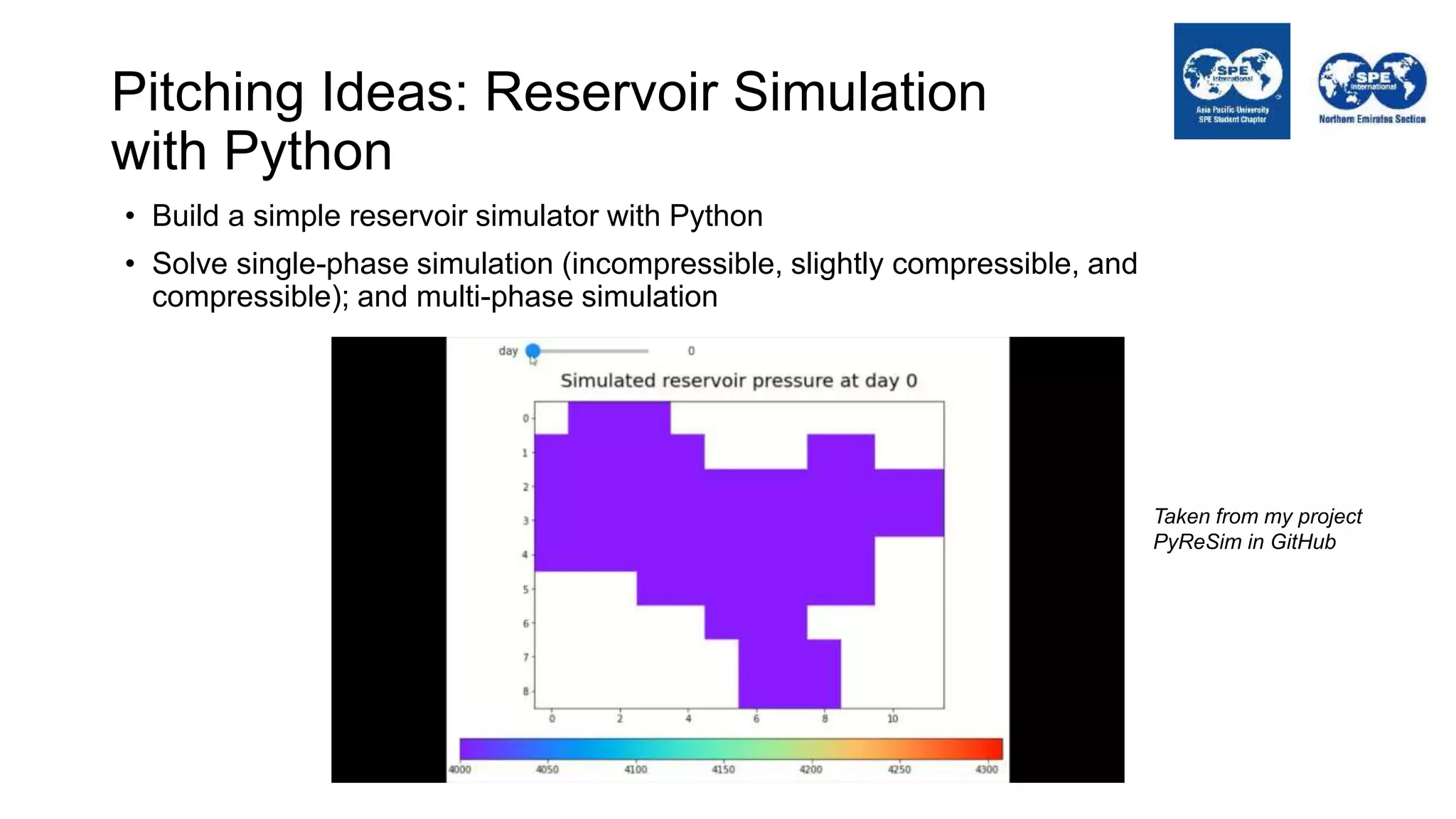
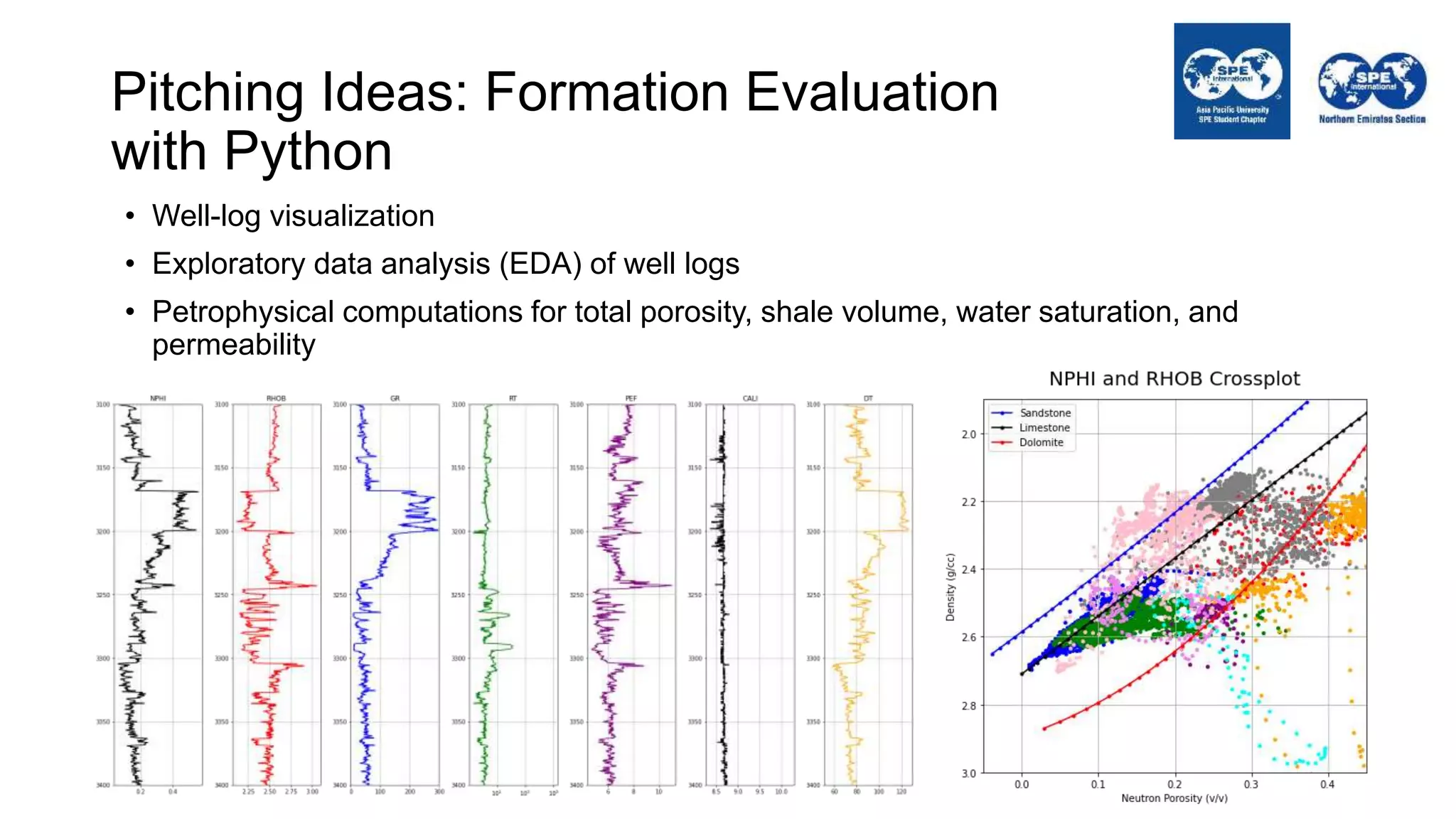
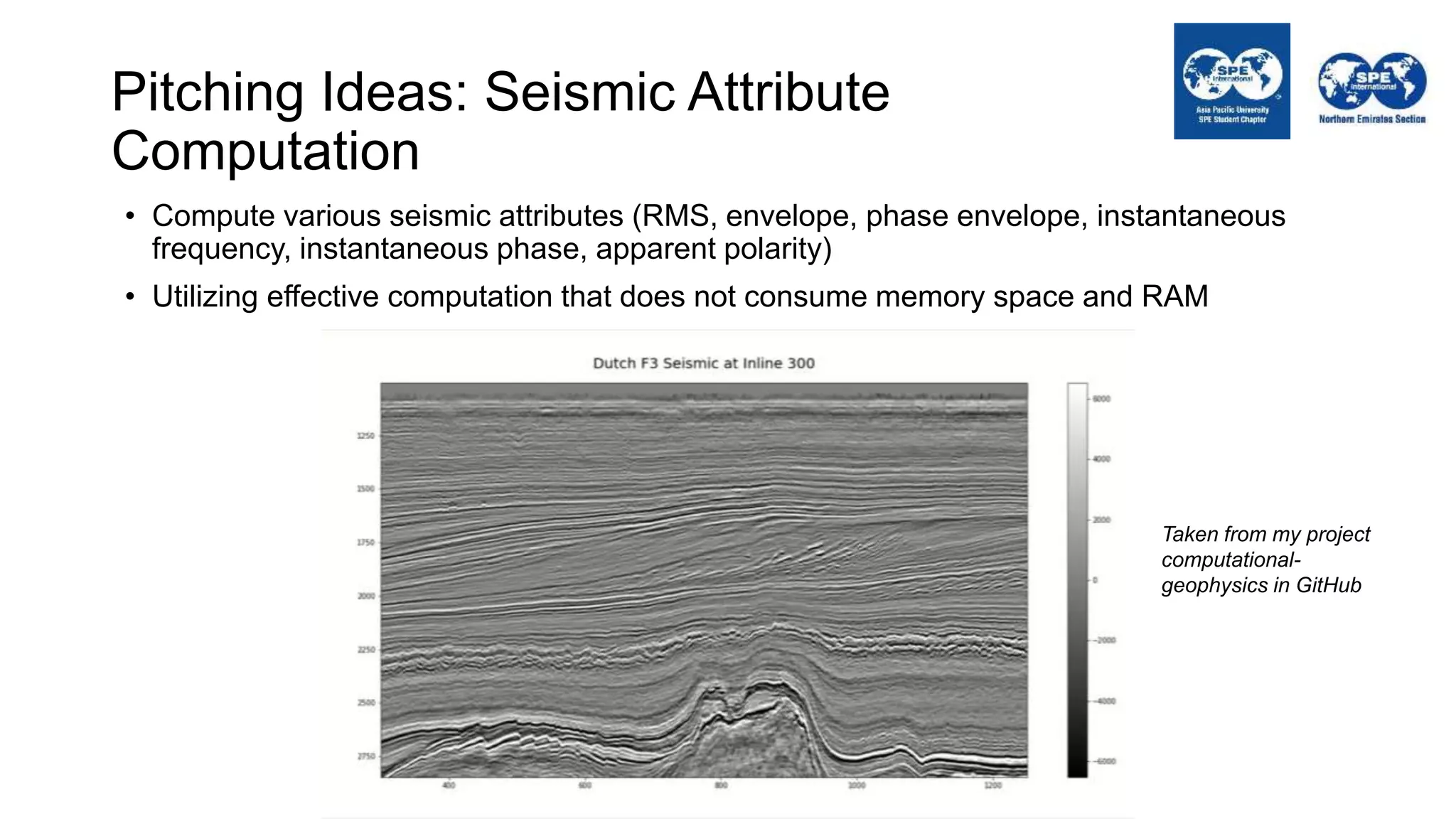
The document outlines the importance of Python programming for students and professionals in the oil and gas sector, emphasizing its benefits as an easy-to-learn, open-source scientific programming language. It details various applications of Python in the industry, including data manipulation, reservoir simulation, and well testing, while also providing practical life hacks for using libraries like NumPy and pandas. Additionally, it offers ideas for projects that can be accomplished using Python, encouraging engineers to leverage programming to enhance their efficiency and effectiveness in solving industry-related problems.