Download as PDF, PPTX

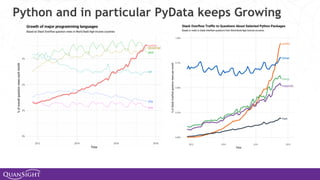

![1998 20182001
2015
2009 20122005
…
2001
2006
A brief history of [my] time [with Python]
1991
2003
2014
2008
2010 2016
2009](https://image.slidesharecdn.com/pyconee-191025141730/85/PyCon-Estonia-2019-4-320.jpg)








![Modular Extensibility
Modules Packages
>>> import numpy
>>> numpy.__file__
{path-prefix}numpy/__init__.py
>>> numpy.__path__
{path-prefix}numpy
>>> numpy.linalg.__file__
{path-prefix}numpy/linalg/__init__.py
>>> import math
>>> math.__file__
{path}math{platform}.so
>>> import os
>>> os.__file__
{path}os.py
.pydor
# my_module.py
a = 3
b = 4
def cross(x,y):
Return a*x + b*y
>>> import my_module
>>> my_module.__file__
{path}my_module.py
>>> ks = my_module.__dict__.keys()
>>> [y for y in ks
if not y.startswith('__')]
['a', 'b', 'cross']
subpackages = []
for name in dir(numpy):
obj = getattr(numpy, name)
if hasattr(obj, '__file__') and
obj.__file__.endswith('__init__.py')
subpackages.append(obj.__name__)
>>> print subpackages
[‘numpy.matrixlib','numpy.compat','numpy.core',
'numpy.fft','numpy.lib','numpy.linalg','numpy.ma',
'numpy.matrixlib','numpy.polynomial','numpy.random',
'numpy.testing']](https://image.slidesharecdn.com/pyconee-191025141730/85/PyCon-Estonia-2019-14-320.jpg)
![New types New functions
class Node:
def __init__(self, item, parent=None):
self.item = item
self.children = []
if parent is not None:
parent.children.append(self)
from math import sqrt
def kurtosis(data):
N = len(data)
mean = sum(data)/N
std = sqrt(sum((x-mean)**2 for x in data)/N)
zi = ((x-mean)/std for x in data)
return sum(z**4 for z in zi)/N - 3
>>> g = Node(“Root”)
>>> type(g)
__main__.Node
>>> type(g).__mro__
(__main__.Node, object)
>>> type(Node).__mro__
(type, object)
>>> type(3)
int
>>> type(3).__mro__
(int, object)
>> type(int).__mro__
(type, object)
>>> type(kurtosis)
function
>>> type(sqrt)
builtin_function_or_method
>>> type(sum)
builtin_function_or_method
>>> import numpy; type(numpy.add)
numpy.ufunc
New Types and Functions](https://image.slidesharecdn.com/pyconee-191025141730/85/PyCon-Estonia-2019-15-320.jpg)























![Universal Functions (Ufuncs)
Ufuncs are a core concept in NumPy for array-oriented
computing.
◦ A function with scalar inputs is broadcast across the elements of
the input arrays:
• np.add([1,2,3], 3) == [4, 5, 6]
• np.add([1,2,3], [10, 20, 30]) == [11, 22, 33]
◦ Parallelism is present, by construction. Numba will generate
loops and can automatically multi-thread if requested.
◦ Before Numba, creating fast ufuncs required writing C. No
longer!](https://image.slidesharecdn.com/pyconee-191025141730/85/PyCon-Estonia-2019-41-320.jpg)




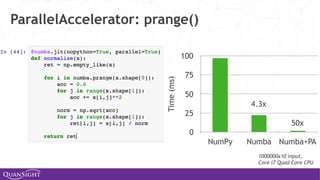



















The document discusses the evolution and growth of Python, particularly in the context of data science and machine learning, highlighting key projects like SciPy and Pandas. It emphasizes Python's modularity, interoperability, and extension capabilities through various tools and libraries like Numba and Cython. Future directions focus on improving Python's extensibility across different runtimes and enhancing the ecosystem through community collaboration and financial support for open-source initiatives.














































































