Downloaded 66 times









![Document Data Model
Relational MongoDB
{
first_name: 'Paul',
surname: 'Miller',
city: 'London',
location: [45.123,47.232],
cars: [
{ model: 'Bentley',
year: 1973,
value: 100000, … },
{ model: 'Rolls Royce',
year: 1965,
value: 330000, … }
]
}](https://image.slidesharecdn.com/productiondeployment-150408133554-conversion-gate01/85/Production-deployment-10-320.jpg)
![Documents are Rich Data Structures
{
first_name: 'Paul',
surname: 'Miller',
cell: '+447557505611'
city: 'London',
location: [45.123,47.232],
Profession: [banking, finance, trader],
cars: [
{ model: 'Bentley',
year: 1973,
value: 100000, … },
{ model: 'Rolls Royce',
year: 1965,
value: 330000, … }
]
}
Fields can contain an array of sub-
documents
Fields
Typed field values
Fields can contain
arrays](https://image.slidesharecdn.com/productiondeployment-150408133554-conversion-gate01/85/Production-deployment-11-320.jpg)

![Do More With Your Data
MongoDB
{
first_name: 'Paul',
surname: 'Miller',
city: 'London',
location: [45.123,47.232],
cars: [
{ model: 'Bentley',
year: 1973,
value: 100000, … },
{ model: 'Rolls Royce',
year: 1965,
value: 330000, … }
}
}
Rich Queries
Find Paul's cars
Find everybody in London with a car
built between 1970 and 1980
Geospatial
Find all of the car owners within 5km
of Trafalgar Sq.
Text Search
Find all the cars described as having
leather seats
Aggregation
Calculate the average value of Paul's
car collection
Map Reduce
What is the ownership pattern of
colors by geography over time?
(is purple trending up in China?)](https://image.slidesharecdn.com/productiondeployment-150408133554-conversion-gate01/85/Production-deployment-13-320.jpg)





















![DMZDMZ
2.1 Data Centers
App Server
Application
Driver
mongos
DC1
Primary
[Anywhere]
Arbiter
DC2
Secondary](https://image.slidesharecdn.com/productiondeployment-150408133554-conversion-gate01/85/Production-deployment-35-320.jpg)
![DMZDMZ
2.1 Data Centers
App Server
Application
Driver
mongos
DC1
Primary
[Anywhere]
Arbiter
DC2
Primary
✗](https://image.slidesharecdn.com/productiondeployment-150408133554-conversion-gate01/85/Production-deployment-36-320.jpg)

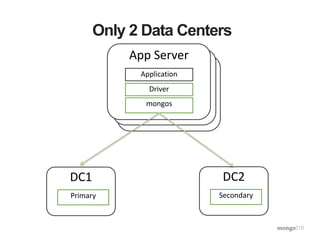
![DMZDMZ
Only 2 Data Centers
App Server
Application
Driver
mongos
DC1
Primary
[Nowhere]
Nothing
DC2
Secondary](https://image.slidesharecdn.com/productiondeployment-150408133554-conversion-gate01/85/Production-deployment-38-320.jpg)













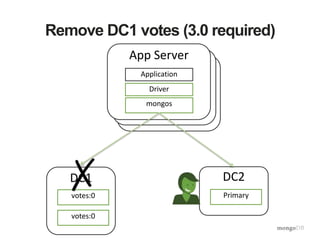









![Install and Configure two DCs
brew install mongodb
git clone https://github.com/rueckstiess/mtools.git
[[ -d ~/data/replset ]] && rm -rf ~/data/replset
mlaunch init --nodes 3 --replicaset
mongo localhost:27017 #DC1
//rs.init()
rs.status()
//rs.add("cbiow.local:27018") //DC1
//rs.status()
//rs.add("cbiow.local:27019") //simulating DC2
//rs.status()
//rs.status()](https://image.slidesharecdn.com/productiondeployment-150408133554-conversion-gate01/85/Production-deployment-63-320.jpg)
![Reconfigure and Fail Over in DC1
db.mycoll.insert({a:1},{writeConcern: {w: "majority", wtimeout: 5000}})
db.mycoll.find()
r = rs.config()
r.members[2].priority = 0.5
rs.reconfig(r)
pkill -f 27017
mongo localhost:27018
rs.status()
db.mycoll.insert({a:2},{writeConcern: {w: "majority", wtimeout: 5000}})
db.mycoll.find()
db.mycoll.count()](https://image.slidesharecdn.com/productiondeployment-150408133554-conversion-gate01/85/Production-deployment-64-320.jpg)
![DC1 Down and Recover in DC2
pkill –f 27018
mongo localhost:27018
rs.status()
db.mycoll.insert({a:3},{writeConcern: {w: "majority", wtimeout: 5000}})
r = rs.config()
r.members[0].votes = 0
r.members[1].votes = 0
rs.reconfig(r, { force: true })
rs.status()
db.mycoll.insert({a:4},{writeConcern: {w: "majority", wtimeout: 5000}})
db.mycoll.find()](https://image.slidesharecdn.com/productiondeployment-150408133554-conversion-gate01/85/Production-deployment-65-320.jpg)
![DC1 Recovery and Restore
mlaunch start 27017
mongo localhost:27017
rs.status()
db.mycoll.insert({a:5},{writeConcern: {w: "majority", wtimeout: 5000}})
db.mycoll.find()
mlaunch start 27018
mongo localhost:27017
rs.status()
r = rs.config()
r.members[0].votes = 1
r.members[1].votes = 1
rs.reconfig(r)](https://image.slidesharecdn.com/productiondeployment-150408133554-conversion-gate01/85/Production-deployment-66-320.jpg)



The document provides an overview of MongoDB 3.0, covering its introduction, data model, production considerations, deployment architectures, and operational practices. It highlights MongoDB's capabilities for scalability, durability, and availability through replica sets and sharding, alongside various use cases across industries. Additionally, it discusses MongoDB Ops Manager for managing operations efficiently with tools for backup, monitoring, and recovery.






































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































