Downloaded 140 times










![Let’s look at some
[anonymous] case studies
where people did it right by
asking MongoDB for help](https://image.slidesharecdn.com/k2zr5vctiyqtnhxwbjhw-signature-1fff2c55bcb3dde9a35194ae2b283f3e1bcf0b42460983f225b77971d17f867d-poli-140707152107-phpapp01/85/Hardware-Provisioning-for-MongoDB-10-320.jpg)












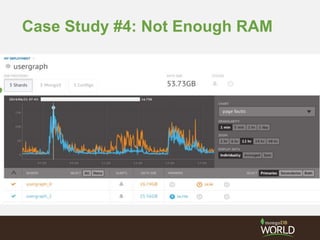





1) Two case studies are presented of companies provisioning MongoDB clusters correctly and incorrectly. A Spanish bank stored 6 months of logs (18TB total) in MongoDB and sized their cluster to handle a 4TB working set. An online retailer moved their product catalog to MongoDB and deployed a single replica set large enough to hold all 240GB of data to meet their performance needs. 2) A software company deployed a replica set incorrectly by overspending on physical servers and underprovisioning EC2 instances, causing the EC2 instances to be a bottleneck. Another company did not provision enough RAM for their workload. 3) Key lessons are to understand performance needs up front, get help from MongoDB, conduct proof of concepts to











































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)






























