Downloaded 98 times











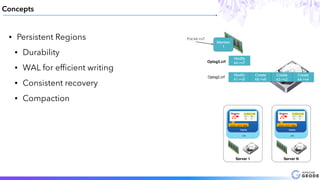
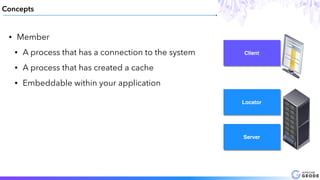
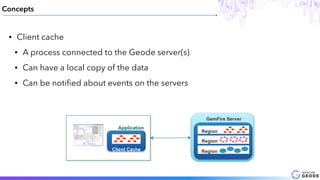
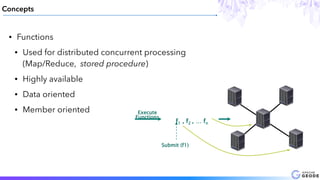
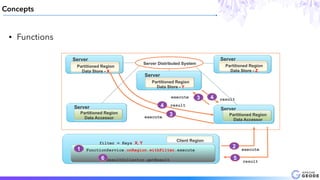
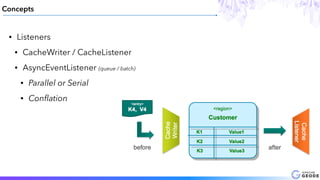

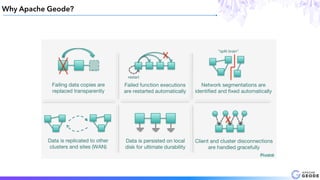





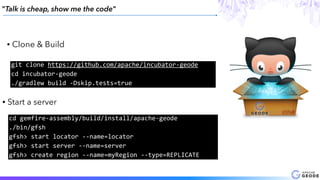




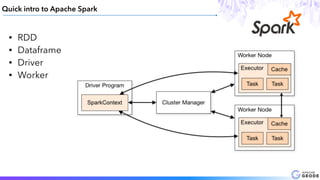
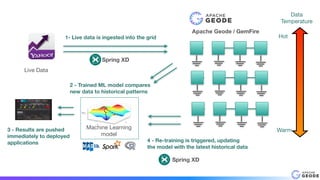
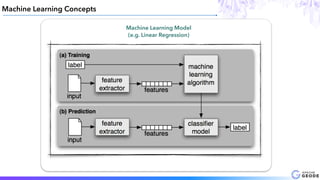






This document provides an introduction to Apache Geode (incubating), including: - A brief history of Geode and why it was developed - An overview of key Geode concepts such as regions, caching, and functions - Examples of interesting large-scale use cases from companies like Indian Railways - A demonstration of using Geode with Apache Spark and Spring XD for a stock prediction application - Information on how to get involved with the Geode open source project community























































































