The document summarizes common patterns for processing large datasets using MapReduce. It describes how MapReduce works by applying map and reduce functions to key-value pairs in parallel. Common patterns discussed include filtering, parsing, counting, merging, binning, distributed tasks, grouping, finding unique values, secondary sorting, and joining datasets. Real-world applications are described as chaining many MapReduce jobs together to process large amounts of data.




![Keys and Values
• Map translates input to keys
and values to new keys and
values [K1,V1] Map [K2,V2]*
• System Groups each unique [K2,V2] Group [K2,{V2,V2,....}]
key with all its values
[K2,{V2,V2,....}] Reduce [K3,V3]*
• Reduce translates the values
of each unique key to new
keys and values * = zero or more
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-5-320.jpg)
![Word Count
Mapper
[0, "when in the course of
human events"] Map ["when",1] ["in",1] ["the",1] [...,1]
["when",1]
["when",1]
["when",1]
["when",1] Group ["when",{1,1,1,1,1}]
["when",1]
Reducer
["when",{1,1,1,1,1}] Reduce ["when",5]
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-6-320.jpg)

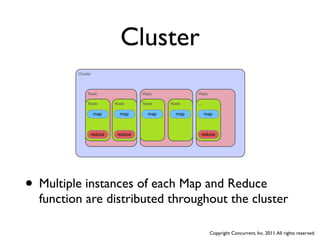
![Another View
[K1,V1] Map [K2,V2]
Combine Group [K2,{V2,...}] Reduce [K3,V3]
Mapper
Task same code
Mapper Reducer
Shuffle
Task Task
Mapper Reducer
Shuffle
Task Task
Mapper Reducer
Shuffle Task
Task
Mapper
Task
Mappers must
complete before
Reducers can
begin
split1 split2 split3 split4 ... part-00000 part-00001 part-000N
file directory
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-9-320.jpg)
![Complex job
assemblies
• Real applications are many MapReduce jobs chained together
• Linked by intermediate (usually temporary) files
• Executed in order, by hand, from the ‘client’ application
Count Job Sort Job
[ k, [v] ] [ k, [v] ]
Map Reduce Map Reduce
[ k, v ] [ k, v ] [ k, v ] [ k, v ]
File File File
[ k, v ] = key and value pair
[ k, [v] ] = key and associated values collection
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-10-320.jpg)
![Real World Apps
[37/75] map+reduce
[54/75] map+reduce
[41/75] map+reduce [43/75] map+reduce [42/75] map+reduce [45/75] map+reduce [44/75] map+reduce [39/75] map+reduce [36/75] map+reduce [46/75] map+reduce [40/75] map+reduce [50/75] map+reduce [38/75] map+reduce [49/75] map+reduce [51/75] map+reduce [47/75] map+reduce [52/75] map+reduce [53/75] map+reduce [48/75] map+reduce
[23/75] map+reduce [25/75] map+reduce [24/75] map+reduce [27/75] map+reduce [26/75] map+reduce [21/75] map+reduce [19/75] map+reduce [28/75] map+reduce [22/75] map+reduce [32/75] map+reduce [20/75] map+reduce [31/75] map+reduce [33/75] map+reduce [29/75] map+reduce [34/75] map+reduce [35/75] map+reduce [30/75] map+reduce
[7/75] map+reduce [2/75] map+reduce [8/75] map+reduce [10/75] map+reduce [9/75] map+reduce [5/75] map+reduce [3/75] map+reduce [11/75] map+reduce [6/75] map+reduce [13/75] map+reduce [4/75] map+reduce [16/75] map+reduce [14/75] map+reduce [15/75] map+reduce [17/75] map+reduce [18/75] map+reduce [12/75] map+reduce
[60/75] map [62/75] map [61/75] map [58/75] map [55/75] map [56/75] map+reduce [57/75] map [71/75] map [72/75] map
[59/75] map
[64/75] map+reduce [63/75] map+reduce [65/75] map+reduce [68/75] map+reduce [67/75] map+reduce [70/75] map+reduce [69/75] map+reduce [73/75] map+reduce [66/75] map+reduce [74/75] map+reduce
[75/75] map+reduce
[1/75] map+reduce
1 app, 75 jobs
green = map + reduce
purple = map
blue = join/merge
orange = map split
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-11-320.jpg)








![Composite Keys/Values
[K1,V1] <A1,B1,C1,...>
• It is easier to think in columns/fields
• e.g. “firstname” & “lastname”, not “line”
• Whether a set of columns are Keys or Values is
arbitrary
• Keys become a means to piggyback the
properties of MR and become an impl detail
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-20-320.jpg)
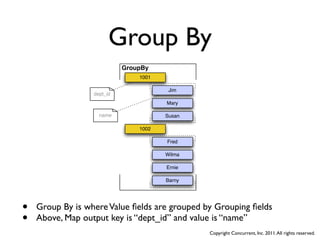
![Group By
Mapper Reducer
Piggyback Code [K1,V1] [K2,{V2,V2,....}]
[K1,V1] -> <A1,B1,C1,D1> [K2,V2] -> <A2,B2,{<C2,D2>,...}>
User Code
Map Reduce
<A2,B2> -> K2, <C2,D2> -> V2 <A3,B3> -> K3, <C3,D3> -> V3
[K2,V2] [K3,V3]
• So the K2 key becomes a composite Key of
• key: [grouping], value: [values]
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-22-320.jpg)
![Unique
Mapper
[0, "when in the course of
human events"] Map ["when",null] ["in",null] [...,null]
["when",1]
["when",1]
["when",1]
["when",1] Group ["when",{nulls}]
["when",null]
Reducer
["when",{nulls}] Reduce ["when",null]
• Or Distinct (as in SQL)
• Globally finding all the unique values in a dataset
• Usually finding unique values in a column
• Often used to filter a second dataset using a join
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-23-320.jpg)

![Secondary Sort
Mapper Reducer
[K1,V1] [K2,{V2,V2,....}]
[K1,V1] -> <A1,B1,C1,D1> [K2,V2] -> <A2,B2,{<C2,D2>,...}>
Map Reduce
<A2,B2><C2> -> K2, <D2> -> V2 <A3,B3> -> K3, <C3,D3> -> V3
[K2,V2] [K3,V3]
• So the K2 key becomes a composite Key of
• key: [grouping, secondary], value: [remaining values]
• The trick is to piggyback the Reduce sort yet not be compared
during the unique key comparison
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-25-320.jpg)
![Secondary Unique
Mapper Assume Secondary Sorting
magic happens here
[0, "when in the course of
human events"] Map [0, "when"] [0, "in"] [0,"the"] [0,...]
["when",1]
["when",1]
["when",1]
["when",1] Group [0,{"in","in","the","when","when",...}]
[0,"when"]
Reducer
[0,{"in","in","the","when","when",...}] Reduce ["in",null] ["the",null] ["when",null]
• Secondary Unique is where the grouping values are uniqued
• .... in a “scale free” way
• Perform a Secondary Sort...
• Reducer removes duplicates by discarding every value that
matches the previous value
• since values are now ordered, no need to maintain a Set of
values
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-26-320.jpg)
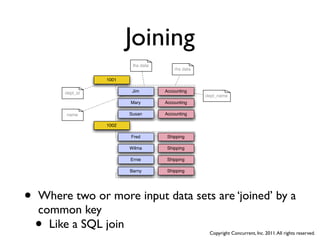
![Join Definitions
• Consider the input data [key, value]:
• LHS = [0,a] [1,b] [2,c]
• RHS = [0,A] [2,C] [3,D]
• Joins on the key:
• Inner
• [0,a,A] [2,c,C]
• Outer (Left Outer, Right Outer)
• [0,a,A] [1,b,null] [2,c,C] [3,null,D]
• Left (Left Inner, Right Outer)
• [0,a,A] [1,b,null] [2,c,C]
• Right (Left Outer, Right Inner)
• [0,a,A] [2,c,C] [3,null,D]
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-28-320.jpg)

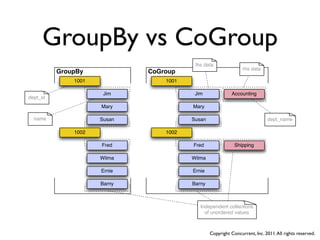
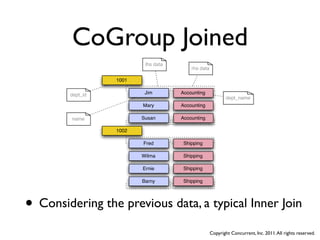
![CoGrouping
Mapper [n] [n+1] Reducer
[K1,V1] [K1',V1'] [K2,{V2,V2,....}]
[K2,V2] -> <A2,B2,{<C2,D2,C2',D2'>,...}>
[K1,V1] -> <A1,B1,C1,D1> [K1',V1'] -> <A1',B1',C1',D1'>
Reduce
Map
<A3,B3> -> K3, <C3,D3> -> V3
<A2,B2> -> K2, [n]<C2,D2> -> V2
[K2,V2] [K3,V3]
• Maps must run for each input set in same Job (n, n+1, etc)
• CoGrouping must happen against each common key
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-32-320.jpg)
![Joining
Reducer
[K2,{V2,V2,....}]
<A2,B2,{[n]<C2,D2>,[n+1]..}>
[K2,V2] -> <A2,B2,{<C2,D2,C2',D2'>,...}>
<A2,B2,{<C2,D2>,...},{<C2',D2'>,...}>
Reduce
{<C2,D2>,...} Join {<C2',D2'>,...}
<A3,B3> -> K3, <C3,D3> -> V3 <C2,D2,C2',D2'>
[K3,V3] <A2,B2,{<C2,D2,C2',D2'>,...}>
• The CoGroups must be joined
• Finally the Reduce can be applied
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-33-320.jpg)

![Identity Mapper [head]
Dfs['TextLine[['offset', 'line']->[ALL]]']['/logs/stumbles/short-stumbles-20090504.log']']
[{2}:'offset', 'line']
[{2}:'offset', 'line']
Each('import')[RegexParser[decl:'day', 'urlid', 'method'][args:1]]
[{3}:'day', 'urlid', 'method']
[{3}:'day', 'urlid', 'method']
Each('import')[ExpressionFilter[decl:'day', 'urlid', 'method']]
[{3}:'day', 'urlid', 'method']
[{3}:'day', 'urlid', 'method']
TempHfs['SequenceFile[['day', 'urlid', 'method']]'][import/71897/]
[{3}:'day', 'urlid', 'method']
[{3}:'day', 'urlid', 'method']
[{3}:'day', 'urlid', 'method']
identity [{3}:'day', 'urlid', 'method']
Each('paidCount')[Not[decl:'day', 'urlid', 'method']]
function [{3}:'day', 'urlid', 'method']
[{3}:'day', 'urlid', 'method']
Each('organicCount')[OrganicFilter[decl:'day', 'urlid', 'method']]
[{3}:'day', 'urlid', 'method']
GroupBy('paidCount')[by:['day', 'urlid']]
[{3}:'day', 'urlid', 'method']
paidCount[{2}:'day', 'urlid']
GroupBy('organicCount')[by:['day', 'urlid']]
[{3}:'day', 'urlid', 'method']
organicCount[{2}:'day', 'urlid']
Every('paidCount')[Count[decl:'count']]
[{3}:'day', 'urlid', 'method']
[{3}:'day', 'urlid', 'count']
Every('organicCount')[Count[decl:'count']]
•
[{3}:'day', 'urlid', 'method']
Move Map operations to the
Each('paidCount')[Identity[decl:'paid_day', 'paid_urlid', 'paid_count']]
[{3}:'day', 'urlid', 'count']
[{3}:'day', 'urlid', 'method']
[{3}:'paid_day', 'paid_urlid', 'paid_count']
[{3}:'paid_day', 'paid_urlid', 'paid_count']
TempHfs['SequenceFile[['paid_day', 'paid_urlid', 'paid_count']]'][paidCount/33072/] TempHfs['SequenceFile[['day', 'urlid', 'count']]'][organicCount/97544/]
[{3}:'paid_day', 'paid_urlid', 'paid_count'] [{3}:'paid_day', 'paid_urlid', 'paid_count']
previous Reduce
[{3}:'paid_day', 'paid_urlid', 'paid_count'] [{3}:'day', 'urlid', 'count']
[{3}:'paid_day', 'paid_urlid', 'paid_count'] [{3}:'day', 'urlid', 'count']
[{3}:'day', 'urlid', 'count']
[{3}:'day', 'urlid', 'count']
CoGroup('organicCount*paidCount')[by:organicCount:['day', 'urlid']paidCount:['paid_day', 'paid_urlid']] Each('paidDomainCount')[LookupDomainFunction[decl:'domainid'][args:1]]
organicCount[{2}:'day', 'urlid'],paidCount[{2}:'paid_day', 'paid_urlid'] [{4}:'paid_day', 'paid_urlid', 'paid_count', 'domainid']
Each('organicDomainCount')[LookupDomainFunction[decl:'domainid'][args:1]]
[{6}:'day', 'urlid', 'count', 'paid_day', 'paid_urlid', 'paid_count'] [{4}:'paid_day', 'paid_urlid', 'paid_count', 'domainid']
[{4}:'day', 'urlid', 'count', 'domainid']
Each('organicCount*paidCount')[ExpressionFunction[decl:'urlid_day']] GroupBy('paidDomainCount')[by:['paid_day', 'domainid']]
[{4}:'day', 'urlid', 'count', 'domainid']
•
[{7}:'day', 'urlid', 'count', 'paid_day', 'paid_urlid', 'paid_count', 'urlid_day'] paidDomainCount[{2}:'paid_day', 'domainid']
GroupBy('organicDomainCount')[by:['day', 'domainid']]
[{7}:'day', 'urlid', 'count', 'paid_day', 'paid_urlid', 'paid_count', 'urlid_day'] [{4}:'paid_day', 'paid_urlid', 'paid_count', 'domainid']
Replace with an Identity
organicDomainCount[{2}:'day', 'domainid']
Each('organicCount*paidCount')[ExpressionFunction[decl:'fixed_count']] Every('paidDomainCount')[Sum[decl:'sum'][args:1]]
[{4}:'day', 'urlid', 'count', 'domainid']
[{8}:'day', 'urlid', 'count', 'paid_day', 'paid_urlid', 'paid_count', 'urlid_day', 'fixed_count'] [{3}:'paid_day', 'domainid', 'sum']
Every('organicDomainCount')[Sum[decl:'sum'][args:1]]
[{8}:'day', 'urlid', 'count', 'paid_day', 'paid_urlid', 'paid_count', 'urlid_day', 'fixed_count'] [{4}:'paid_day', 'paid_urlid', 'paid_count', 'domainid']
function
[{3}:'day', 'domainid', 'sum']
Each('organicCount*paidCount')[ExpressionFunction[decl:'fixed_paid_count']] Each('paidDomainCount')[Identity[decl:'paid_day', 'paid_domainid', 'paid_sum']]
[{4}:'day', 'urlid', 'count', 'domainid']
[{9}:'day', 'urlid', 'count', 'paid_day', 'paid_urlid', 'paid_count', 'urlid_day', 'fixed_count', 'fixed_paid_count'] [{3}:'paid_day', 'paid_domainid', 'paid_sum']
TempHfs['SequenceFile[['day', 'domainid', 'sum']]'][organicDomainCount/49784/]
[{9}:'day', 'urlid', 'count', 'paid_day', 'paid_urlid', 'paid_count', 'urlid_day', 'fixed_count', 'fixed_paid_count'] [{3}:'paid_day', 'paid_domainid', 'paid_sum']
Each('organicCount*paidCount')[Identity[decl:'urlid_day', 'default:organic_stumbles', 'default:paid_stumbles']] TempHfs['SequenceFile[['paid_day', 'paid_domainid', 'paid_sum']]'][paidDomainCount/54349/]
[{3}:'paid_day', 'paid_domainid', 'paid_sum'] [{3}:'day', 'domainid', 'sum']
•
[{3}:'paid_day', 'paid_domainid', 'paid_sum'] [{3}:'day', 'domainid', 'sum']
[{3}:'urlid_day', 'default:organic_stumbles', 'default:paid_stumbles']
[{3}:'urlid_day', 'default:organic_stumbles', 'default:paid_stumbles']
CoGroup('organicDomainCount*paidDomainCount')[by:organicDomainCount:['day', 'domainid']paidDomainCount:['paid_day', 'paid_domainid']]
Assumes Map operations cascading.hbase.HBaseTap@d9a475a0
organicDomainCount[{2}:'day', 'domainid'],paidDomainCount[{2}:'paid_day', 'paid_domainid']
[{6}:'day', 'domainid', 'sum', 'paid_day', 'paid_domainid', 'paid_sum']
Each('organicDomainCount*paidDomainCount')[ExpressionFunction[decl:'domainid_day']]
reduce the data
[{7}:'day', 'domainid', 'sum', 'paid_day', 'paid_domainid', 'paid_sum', 'domainid_day']
[{7}:'day', 'domainid', 'sum', 'paid_day', 'paid_domainid', 'paid_sum', 'domainid_day']
[{3}:'urlid_day', 'default:organic_stumbles', 'default:paid_stumbles']
Each('organicDomainCount*paidDomainCount')[ExpressionFunction[decl:'fixed_sum']]
[{3}:'urlid_day', 'default:organic_stumbles', 'default:paid_stumbles']
[{8}:'day', 'domainid', 'sum', 'paid_day', 'paid_domainid', 'paid_sum', 'domainid_day', 'fixed_sum']
[{8}:'day', 'domainid', 'sum', 'paid_day', 'paid_domainid', 'paid_sum', 'domainid_day', 'fixed_sum']
Each('organicDomainCount*paidDomainCount')[ExpressionFunction[decl:'fixed_paid_sum']]
[{9}:'day', 'domainid', 'sum', 'paid_day', 'paid_domainid', 'paid_sum', 'domainid_day', 'fixed_sum', 'fixed_paid_sum']
[{9}:'day', 'domainid', 'sum', 'paid_day', 'paid_domainid', 'paid_sum', 'domainid_day', 'fixed_sum', 'fixed_paid_sum']
Each('organicDomainCount*paidDomainCount')[Identity[decl:'domainid_day', 'default:organic_stumbles', 'default:paid_stumbles']]
[{3}:'domainid_day', 'default:organic_stumbles', 'default:paid_stumbles']
[{3}:'domainid_day', 'default:organic_stumbles', 'default:paid_stumbles']
cascading.hbase.HBaseTap@3d07f00
[{3}:'domainid_day', 'default:organic_stumbles', 'default:paid_stumbles']
[{3}:'domainid_day', 'default:organic_stumbles', 'default:paid_stumbles']
[tail]
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-35-320.jpg)

![Combiners
Mapper
[0, "when in the course of
human events"] Map ["when",1] ["in",1] ["the",1] [...,1]
Combiner
["when",1]
["when",1] Group ["when",{1,1}]
["when",{1,1}] Reduce ["when",2]
Same Implementation
["when",1]
["when",1] Group ["when",{2,1,2}]
["when",2]
Reducer
["when",{2,1,2}] Reduce ["when",5]
• Where Reduce runs Map side, and again Reduce side
• Only works if Reduce is commutative and associative
• Reduces bandwidth by trading CPU for IO
• Serialization/deserialization during local sorting before combining
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-37-320.jpg)
![Partial Aggregates
Mapper
[0, "when in the course of
human events"] ["when",1] ["in",1] ["the",1] [...,1]
Map
Partial
Provides an opportunity to
["when",1]
["when",1] ["when",2] promote the functionality of
the next Map to this Reduce
["when",1]
["when",1] Group ["when",{2,1,2}]
["when",2]
Reducer
["when",{2,1,2}] Reduce ["when",5]
• Supports any aggregate type, while being composable with other
aggregates
• Reduces bandwidth by trading Memory for IO
• Very important for a CPU constrained cluster
• Use a bounded LRU to keep constant memory (requires tuning)
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-38-320.jpg)
![Partial Aggregates
[a,b,c,a,a,b]
[a,b,c,a,a,b] partial unique
partial unique [a,b,c,a,b]
[a,b,c,a,b]
[a,b,c,a,a,b]
[a,b,c,a,a,b] partial unique
partial unique [a,b,c,a,b]
[a,b,c,a,b]
LRU*
{_,_}
*cache size of 2
a -> {a,_} -> _
b -> {b,a} -> _
incoming discarded
c -> {c,b} -> a
value value
a -> {a,c} -> b
a -> {a,c}
b -> {b,a} -> c
• OK that dupes emit from a Mapper and across
Mappers (or prev Reducers!)
• Final aggregation happens in Reducer
• Larger the cache, fewer dupes Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-39-320.jpg)



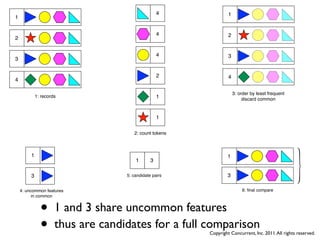
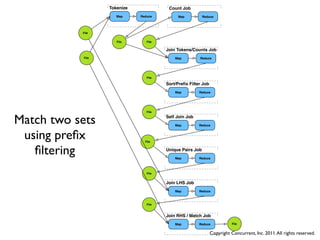







![Why Sorting Isn’t
“Total”
[aaa,aab,aac] Mapper
aaa
Mapper aac Reducer [aaa,zzx]
aab
Mapper Reducer [aac,zzz]
zzx
Mapper zzz Reducer [aab,zzy]
zzy
[zzx,zzy,zzz] Mapper
• Keys emitted from Map are naturally sorted at a given Reducer
• But are Partitioned to Reducers in a random way
• Thus, only one Reducer can be used for a total sort
Copyright Concurrent, Inc. 2011. All rights reserved.](https://image.slidesharecdn.com/buzzwords-110720143439-phpapp02/85/Buzz-words-52-320.jpg)


































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)
















