Download as PDF, PPTX














![reducer.py
#!/usr/bin/python
import sys
subTotals = {}
for line in sys.stdin:
line = line.strip()
word = line.split('t')[0]
count = int(line.split('t')[1])
subTotals[word] = subTotals.get(word, 0) + count
for k, v in subTotals.items():
print "%st%s" % (k, v)](https://image.slidesharecdn.com/prezentare-hadoop-100816052218-phpapp01/75/Amazon-style-shopping-cart-analysis-using-MapReduce-on-a-Hadoop-cluster-31-2048.jpg)
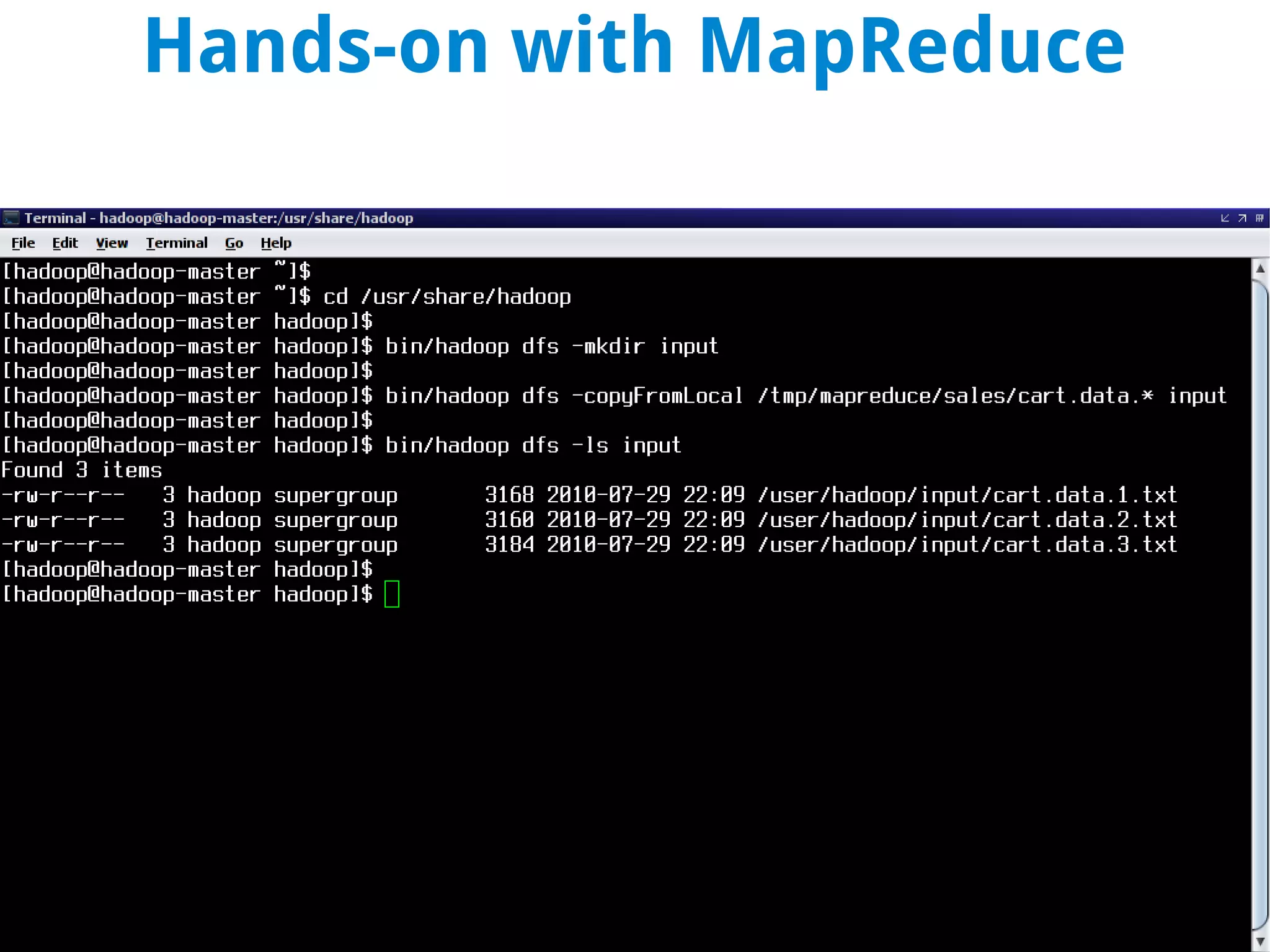
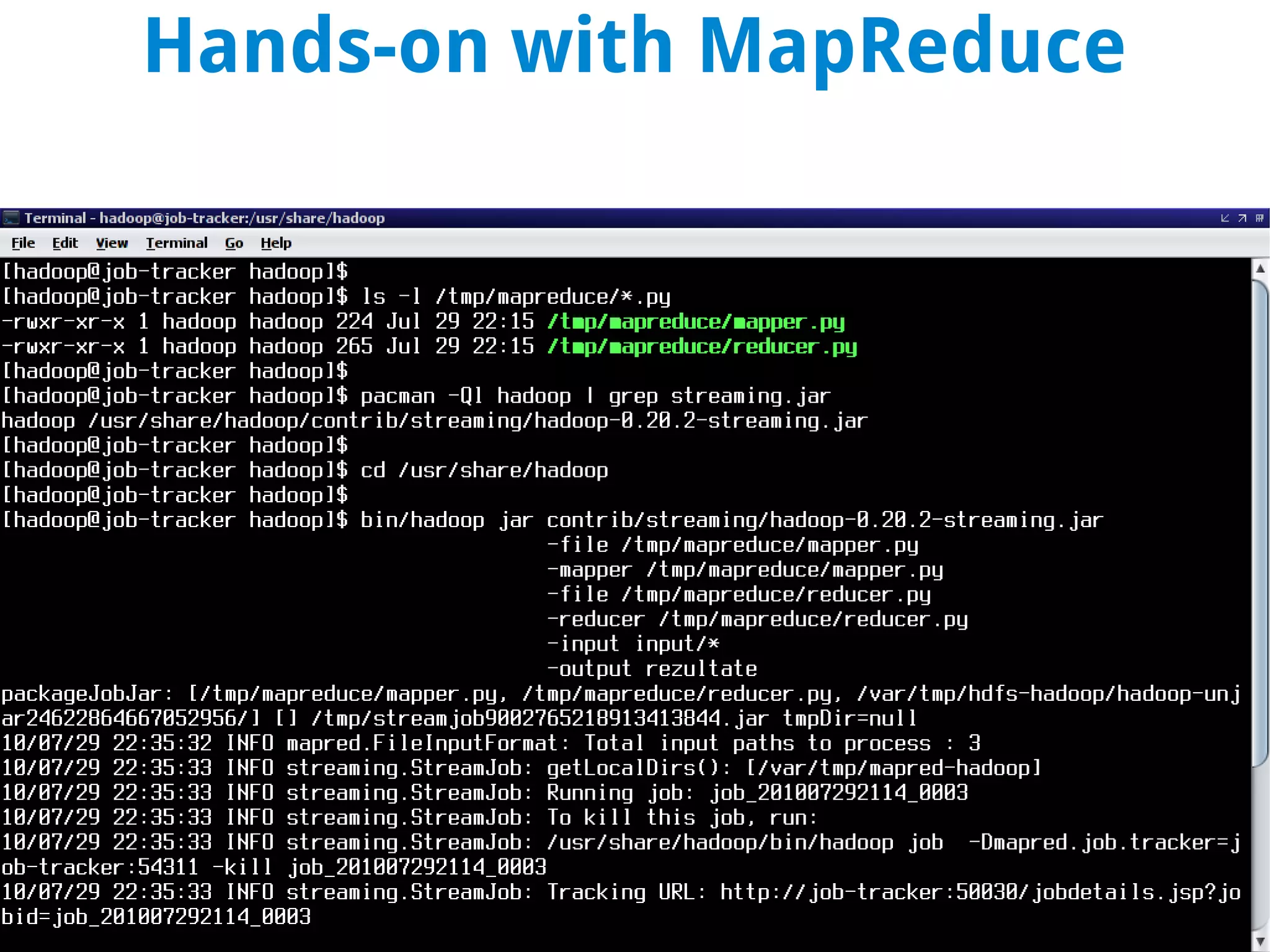
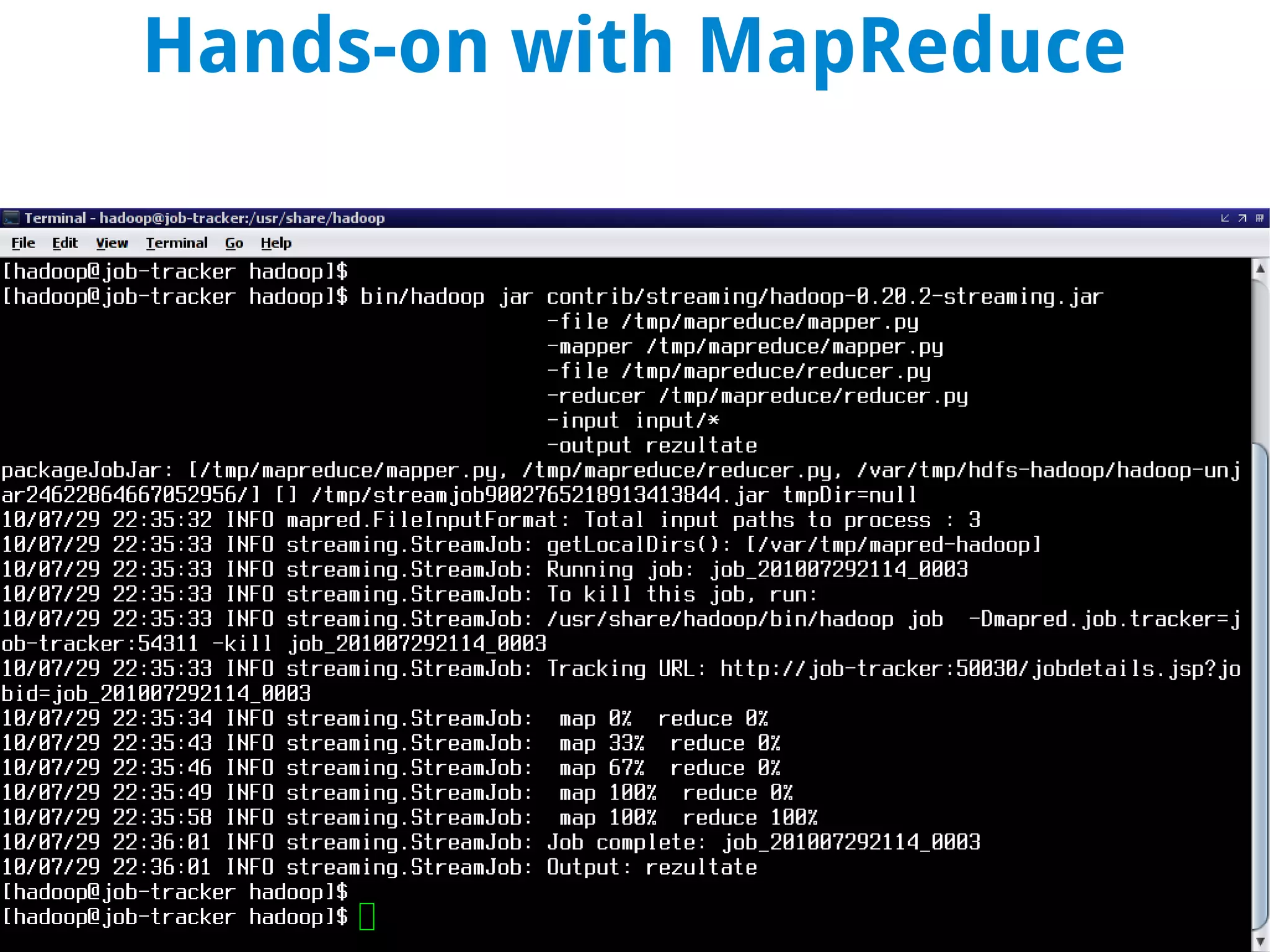
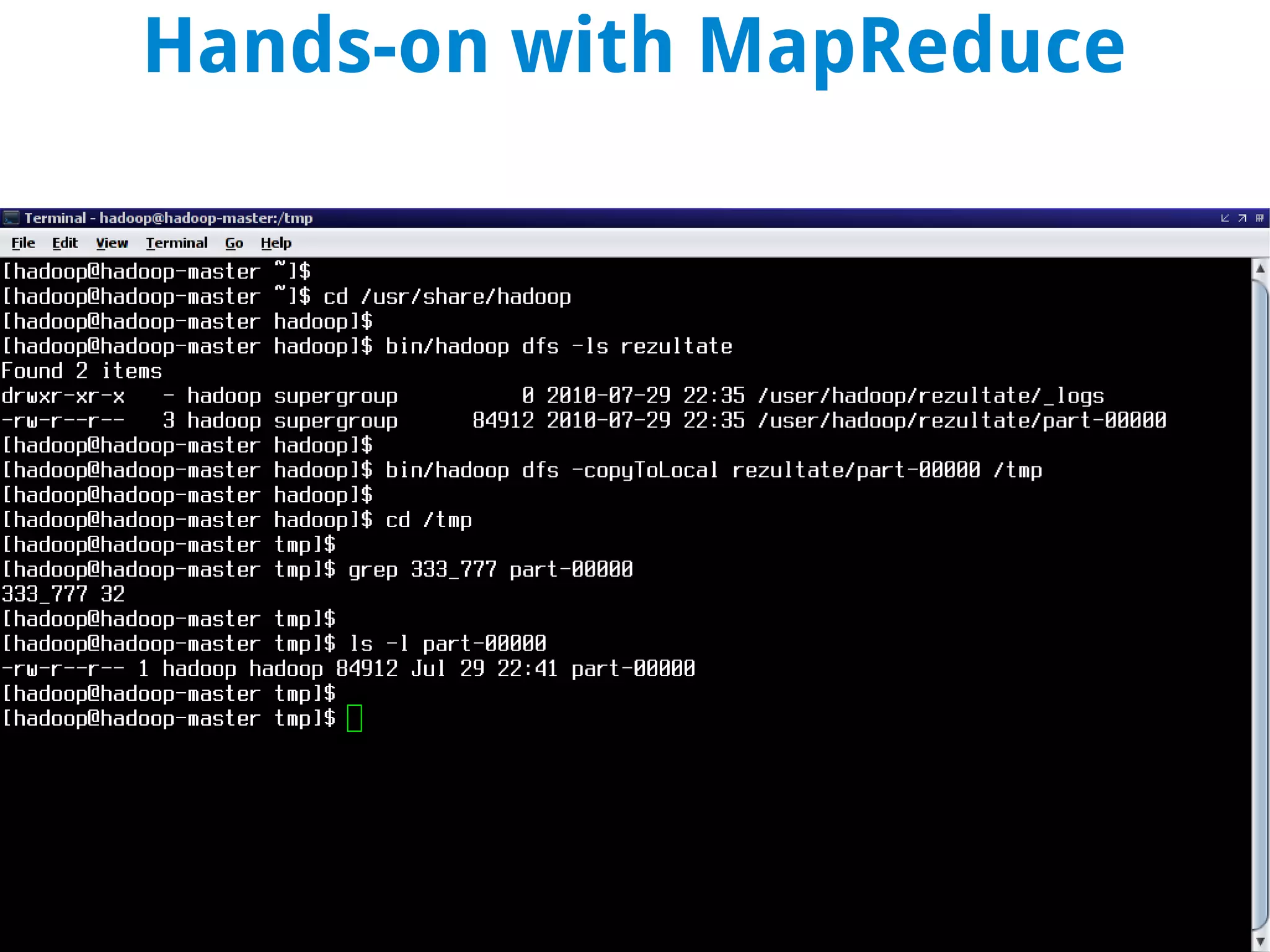
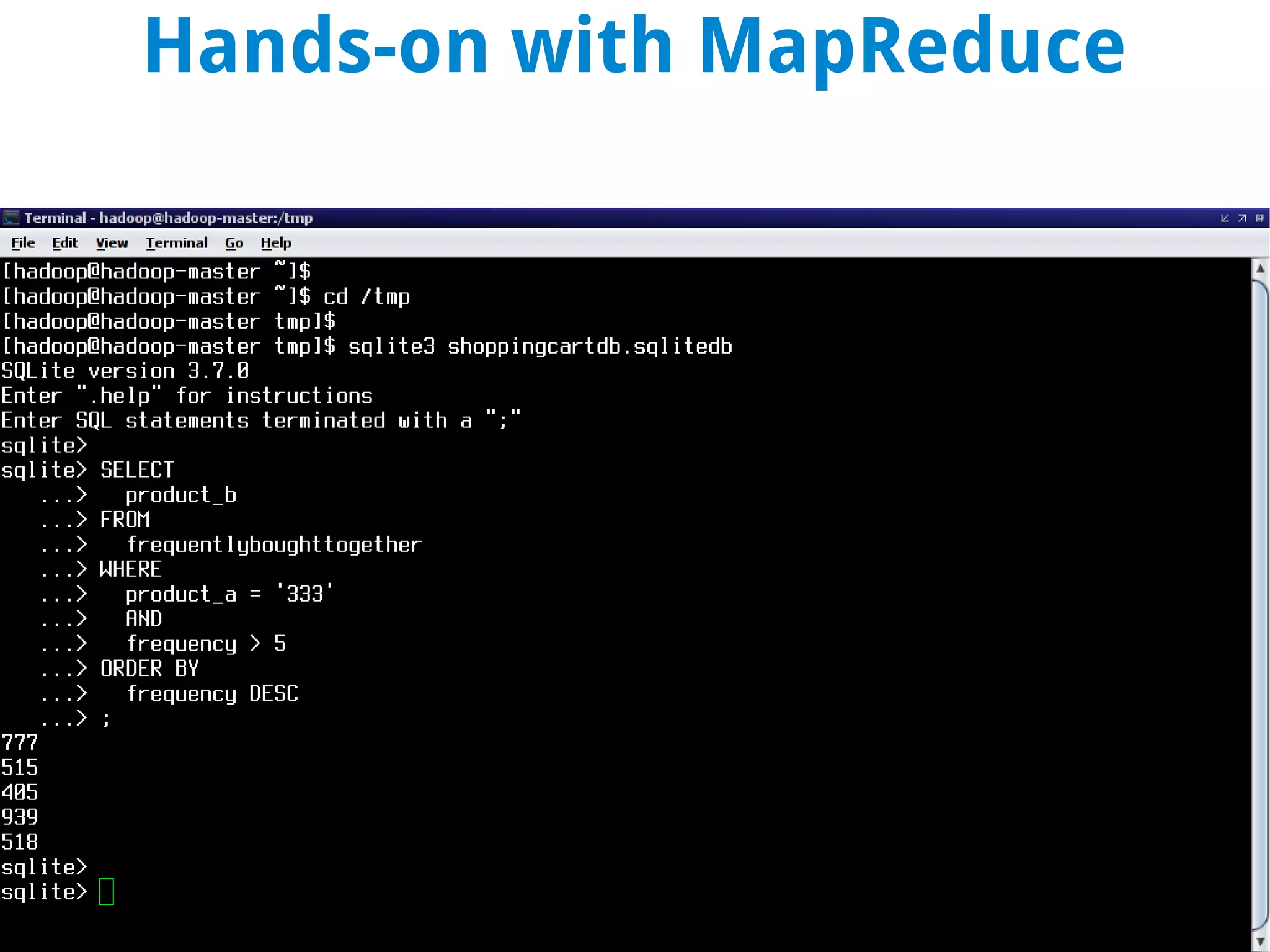


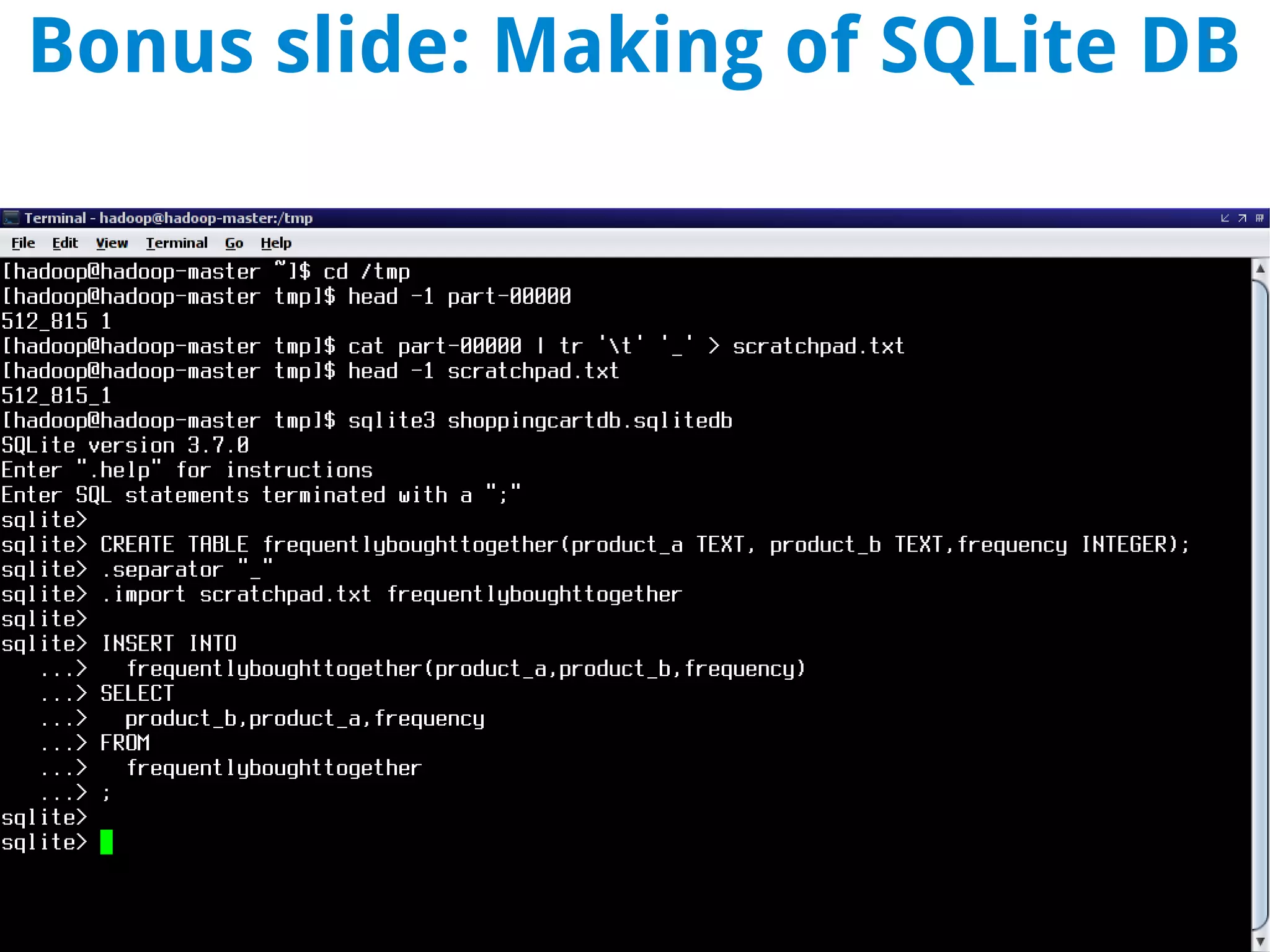

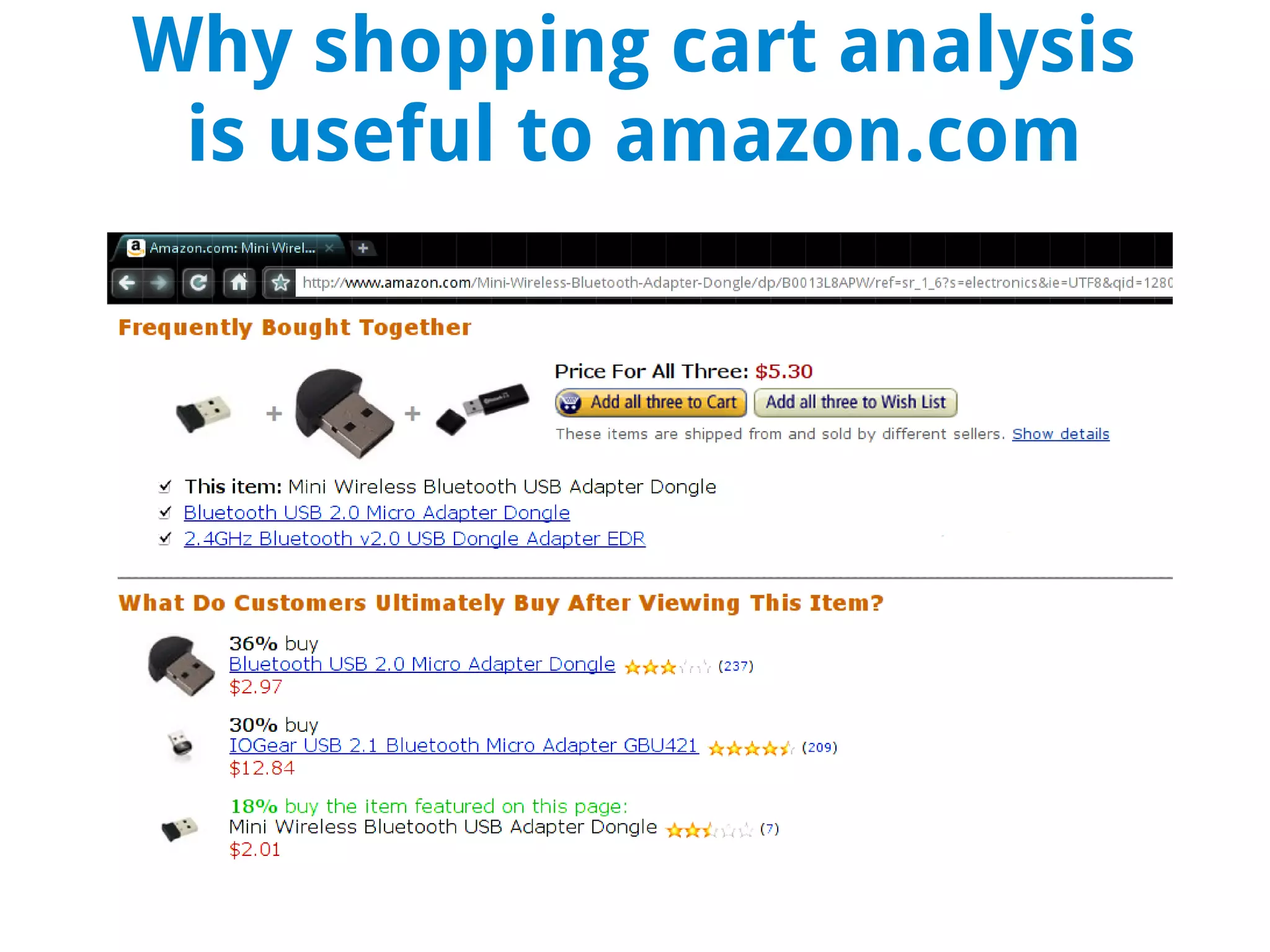
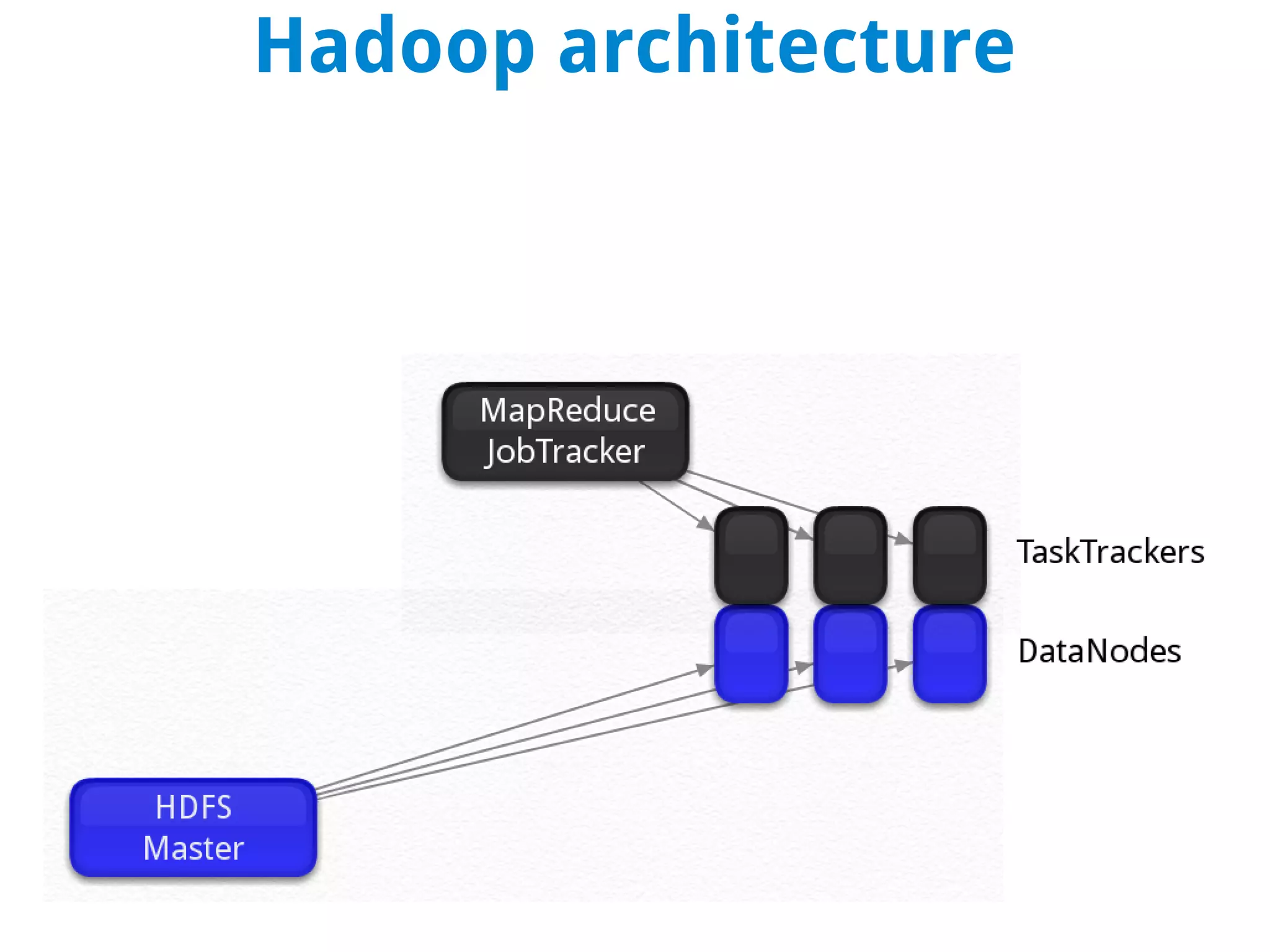
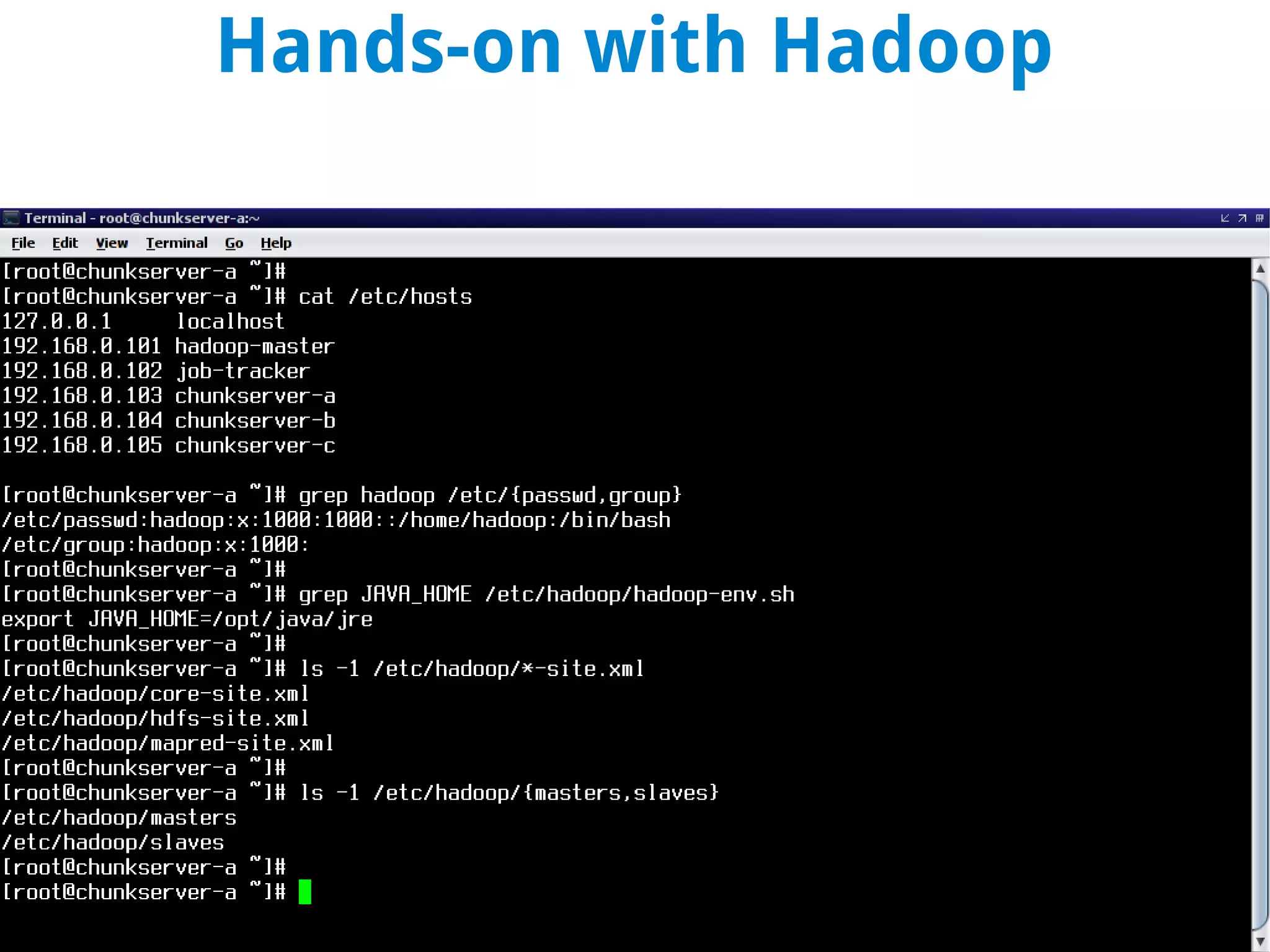
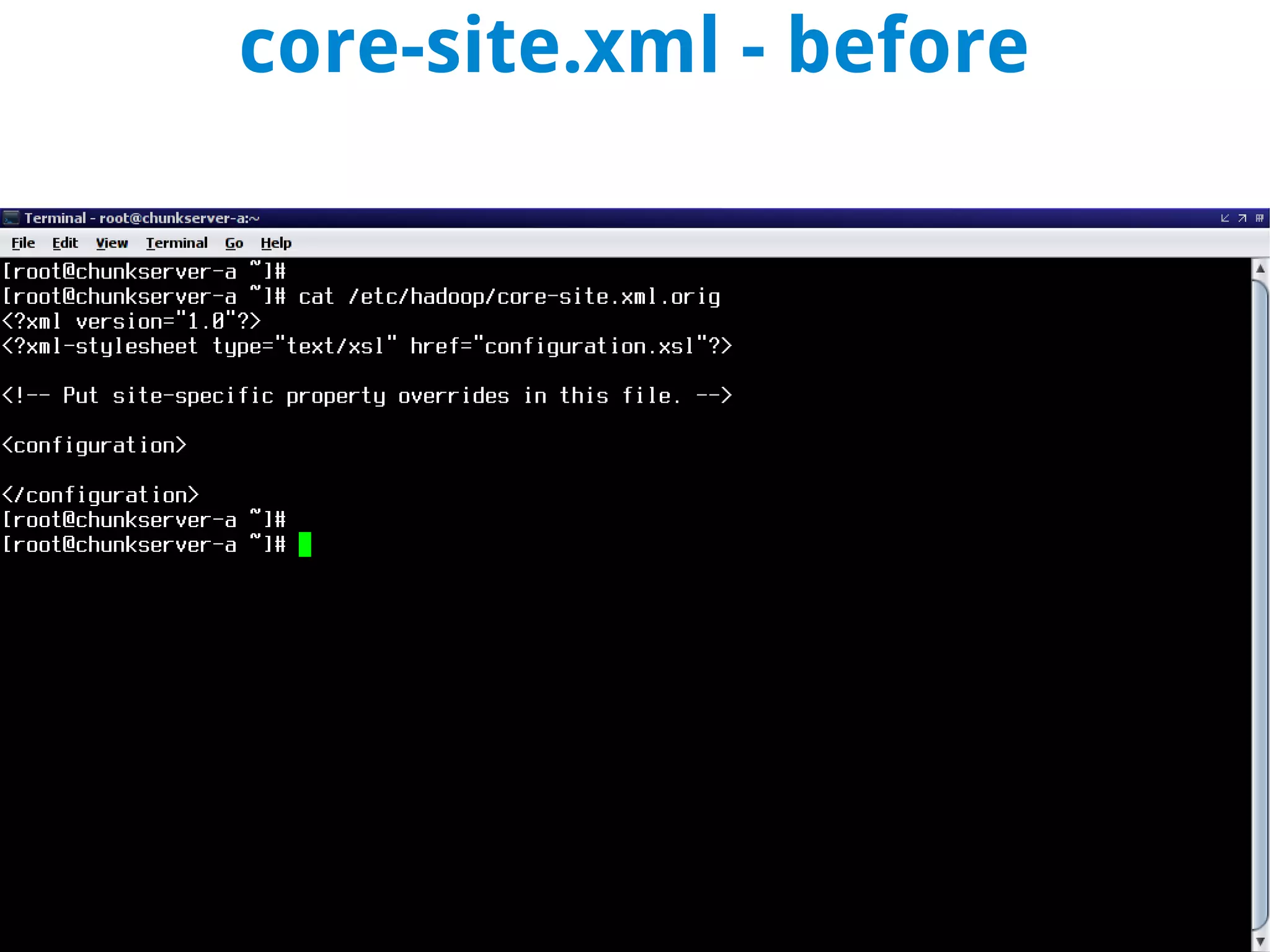
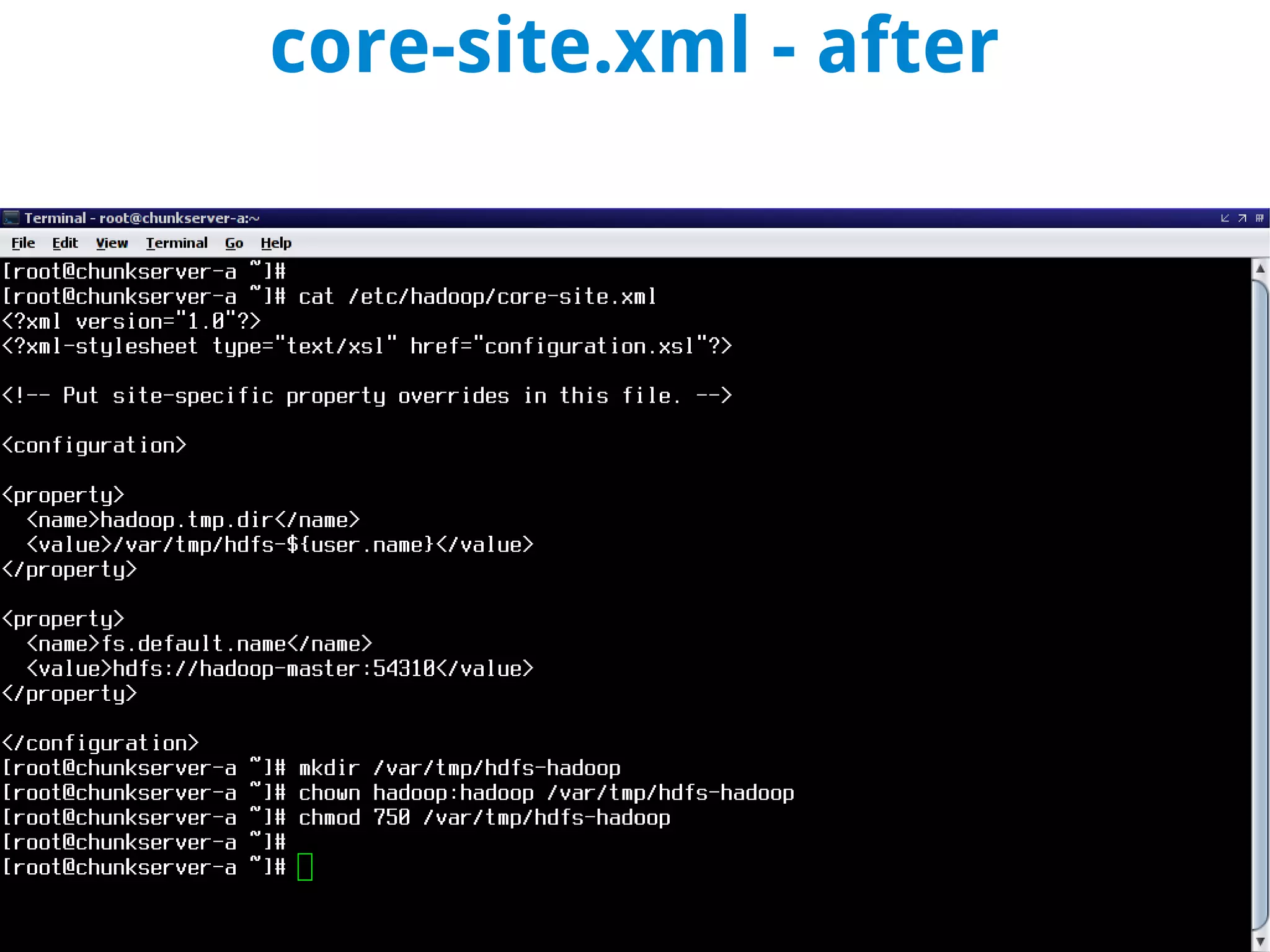
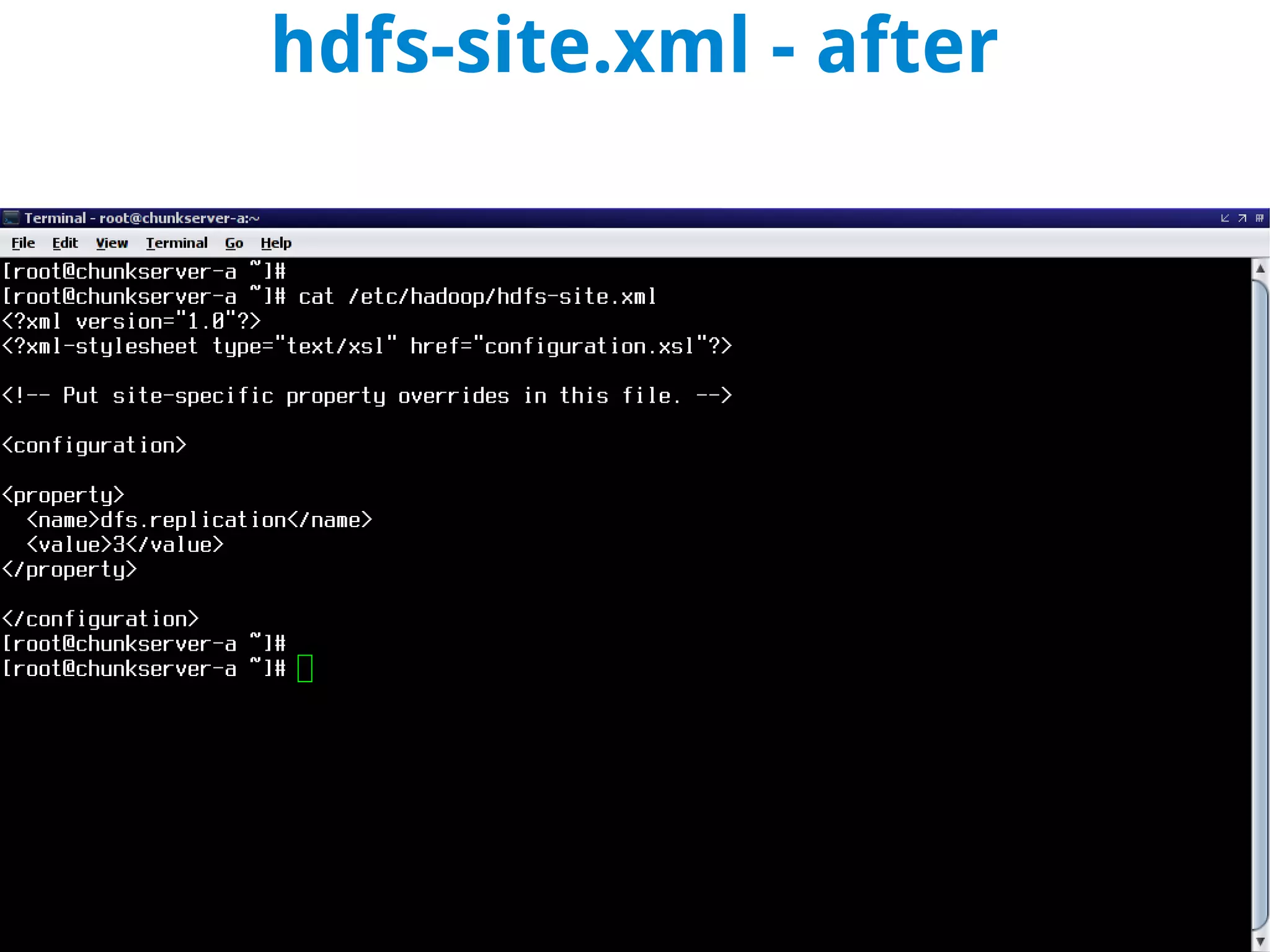
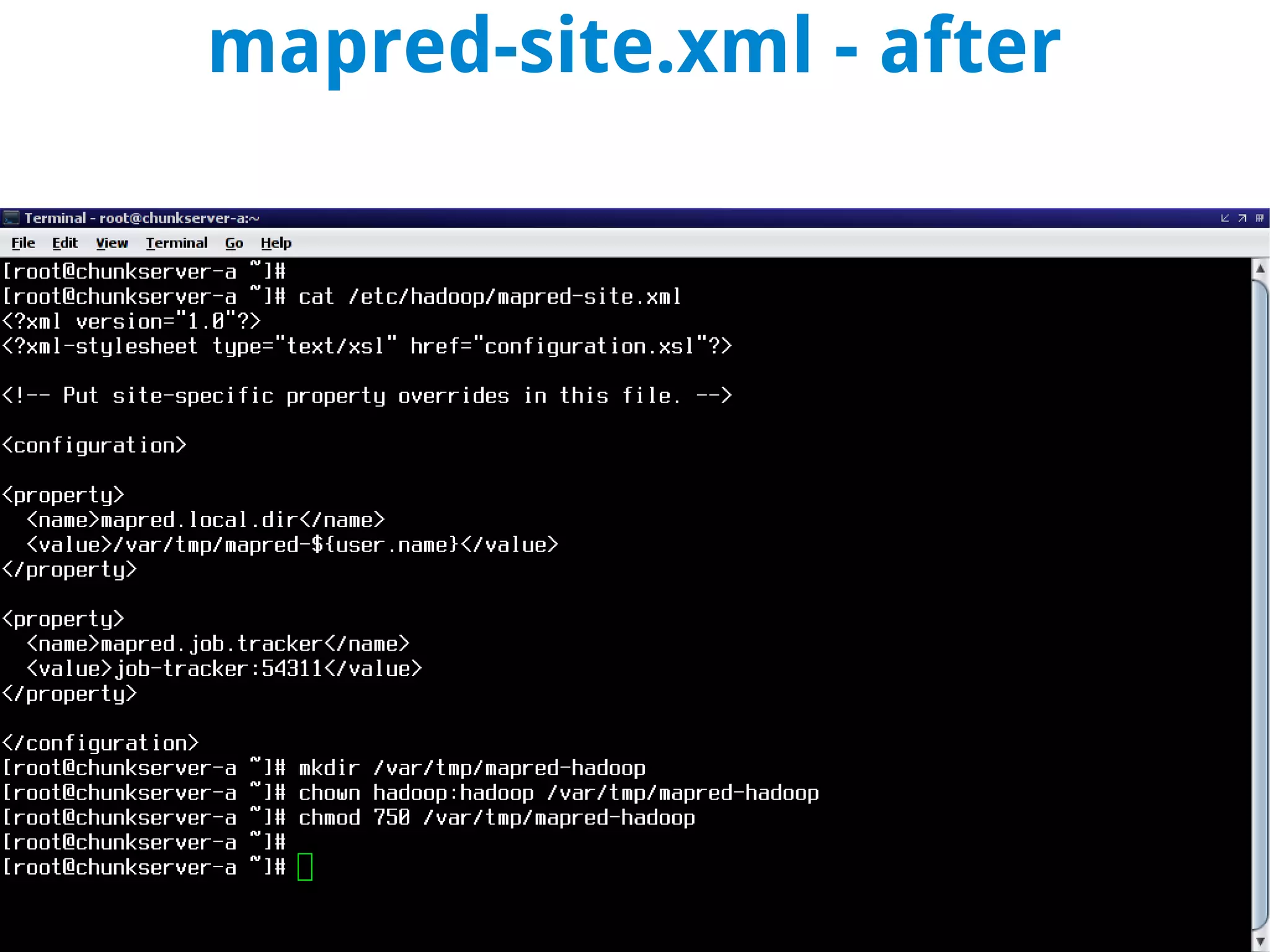
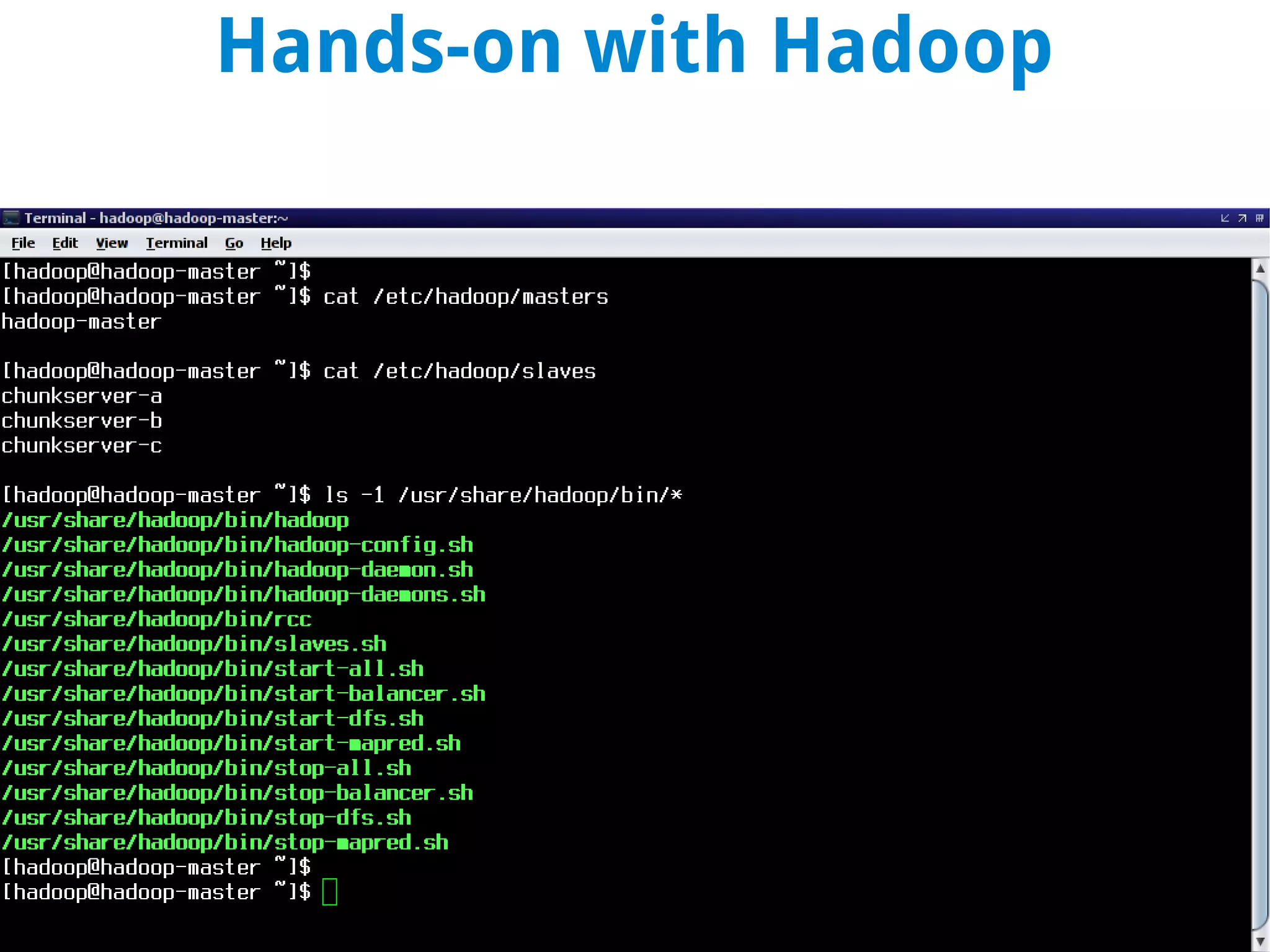
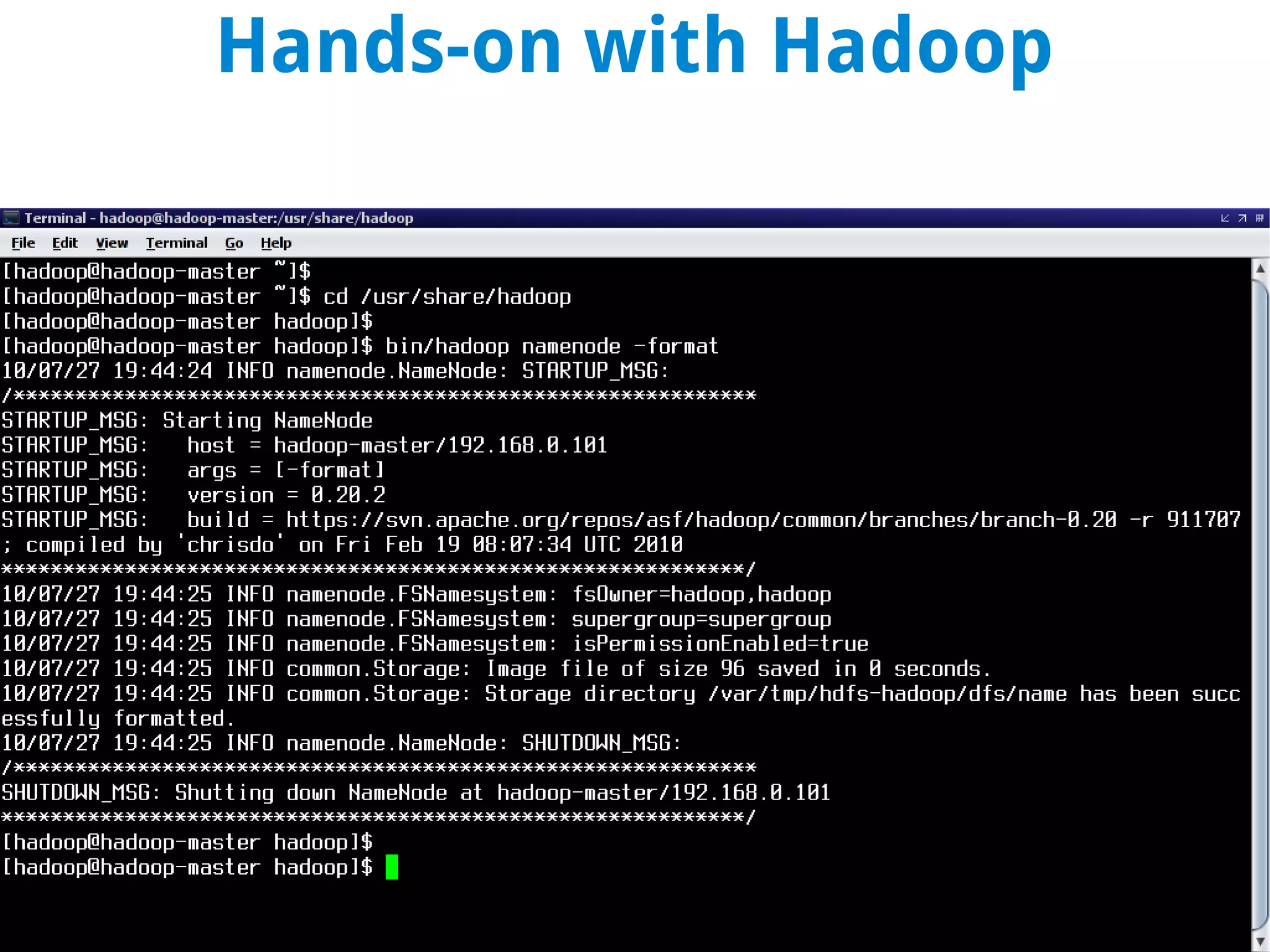
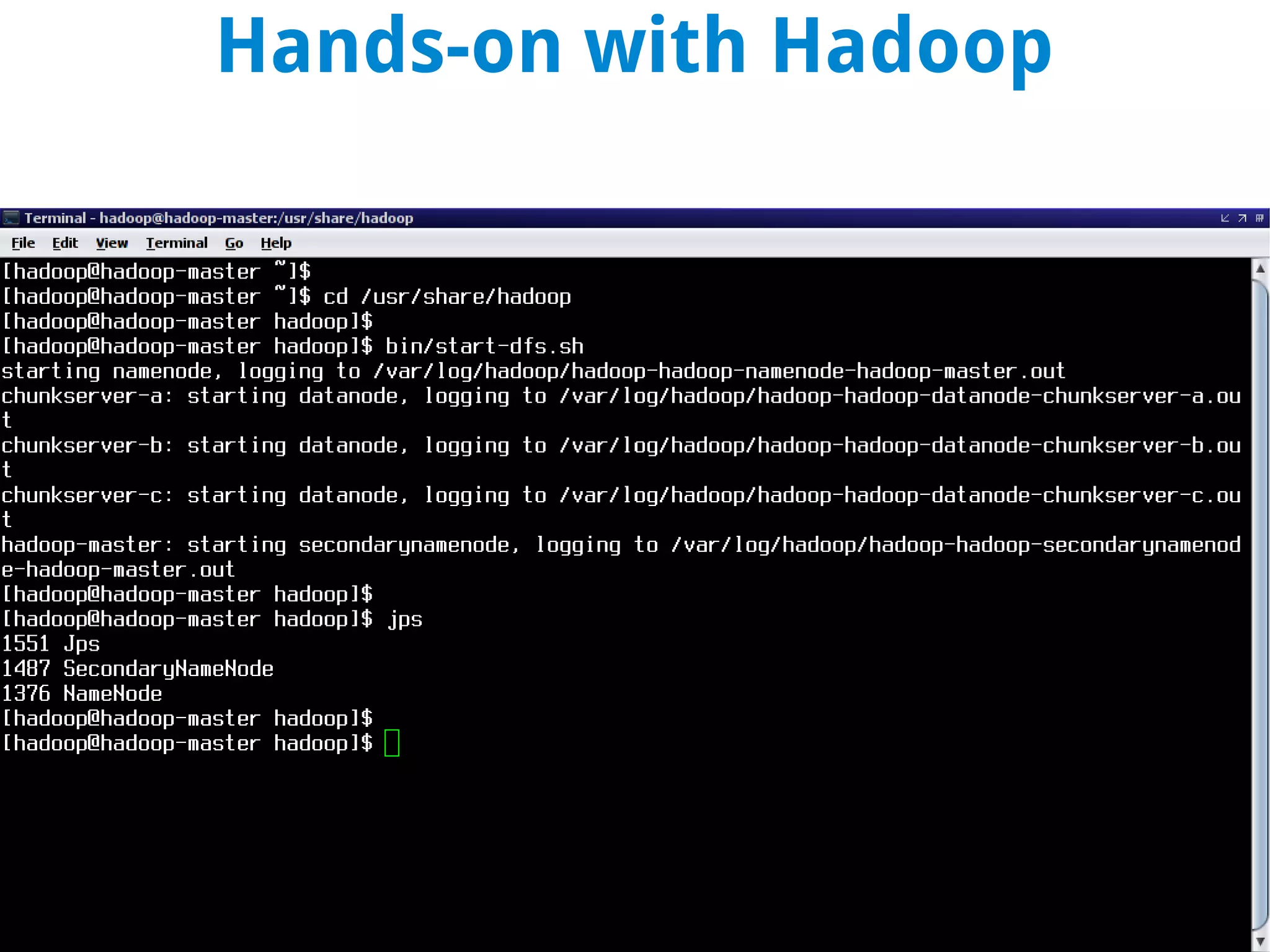
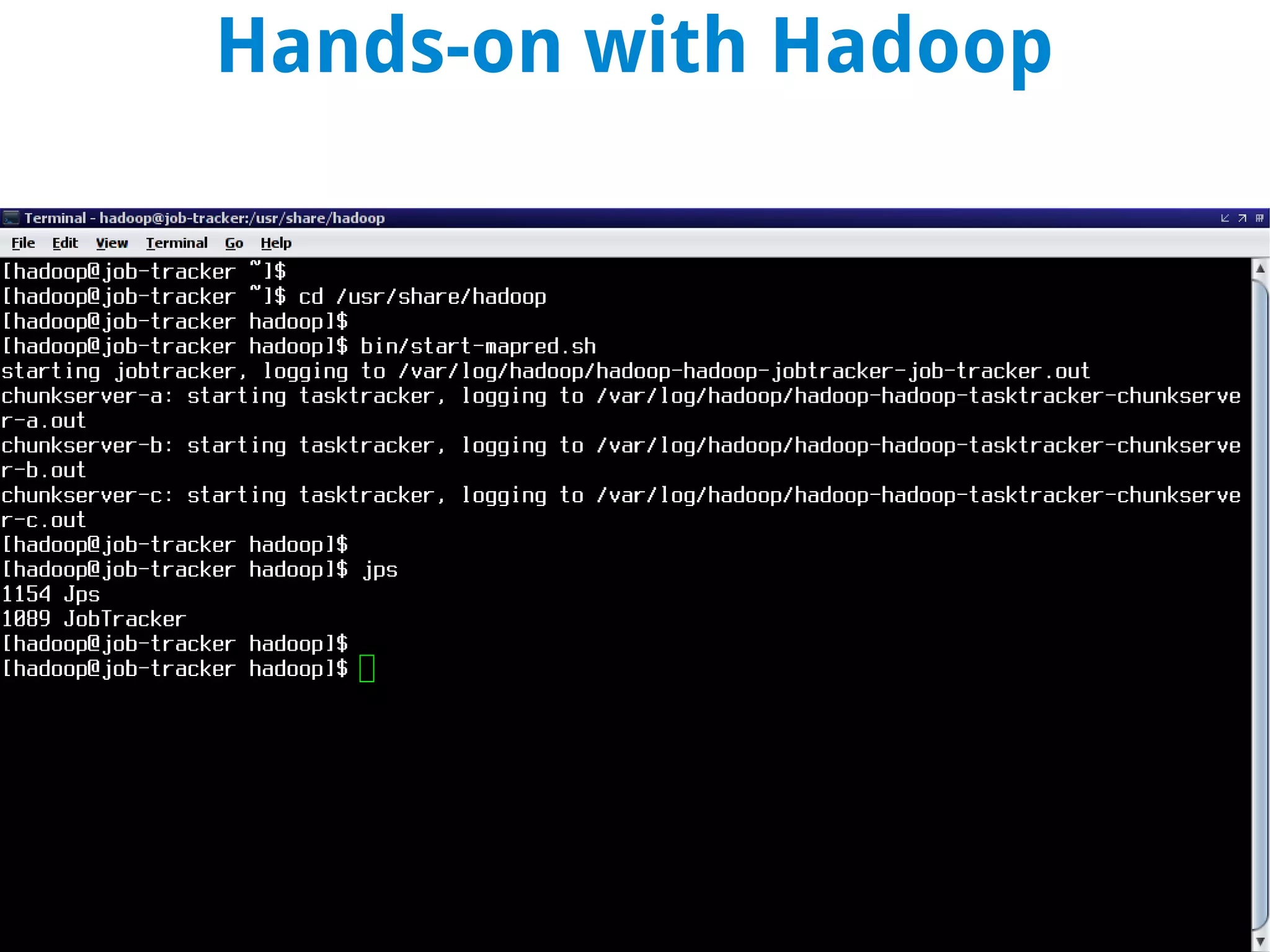
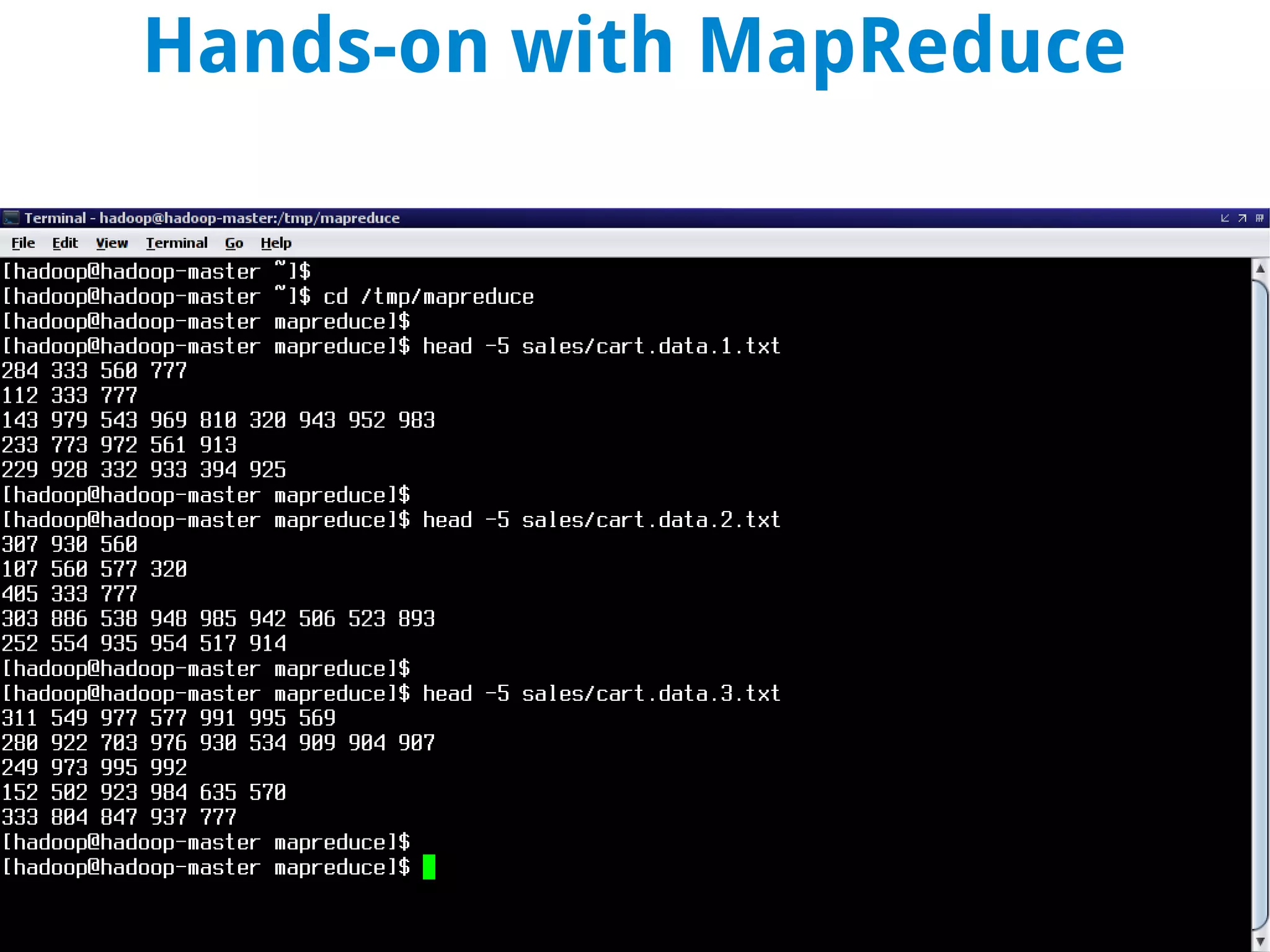
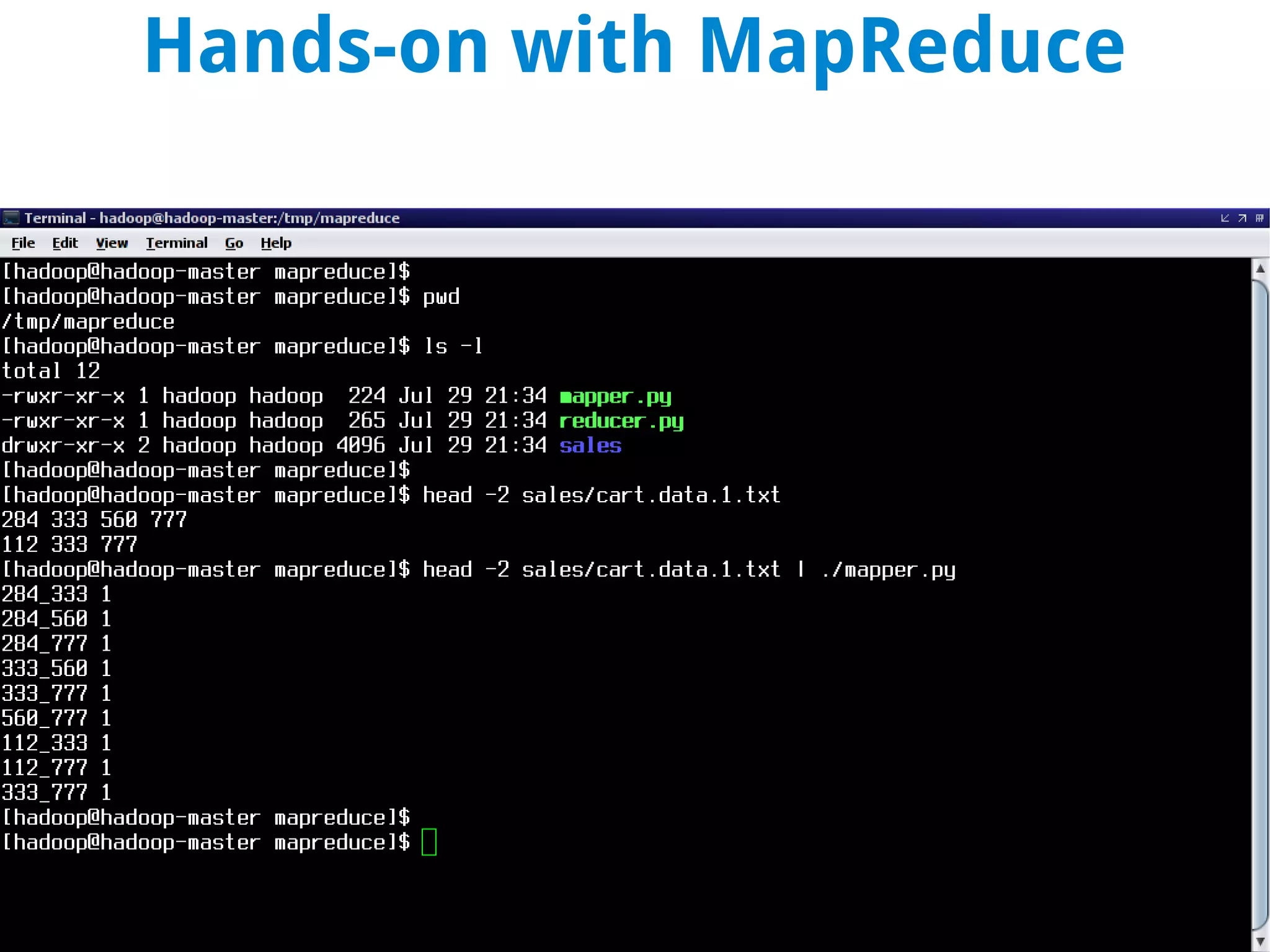
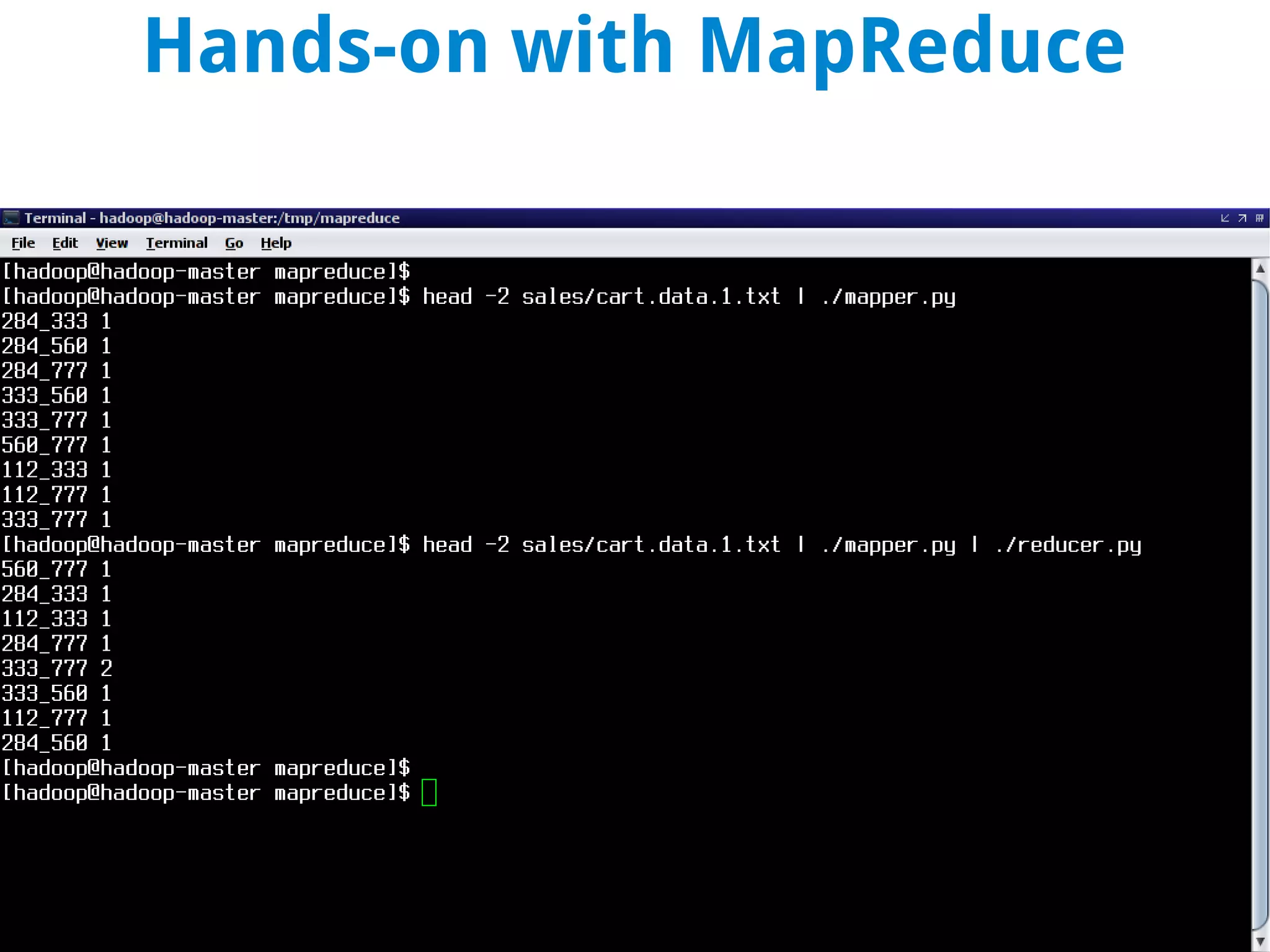
This document discusses using MapReduce on a Hadoop cluster to analyze shopping cart data similar to what Amazon analyzes. It begins with an agenda that includes deploying Hadoop and using MapReduce for machine learning. It then discusses the origins of Hadoop from the Nutch project and key facts about Hadoop architecture. Part 1 explains how to configure and deploy a Hadoop cluster. Part 2 demonstrates hands-on use of MapReduce to analyze sample data, providing example Mapper and Reducer Python scripts. It concludes with other real-world uses of MapReduce.

![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)








![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)








