Download to read offline










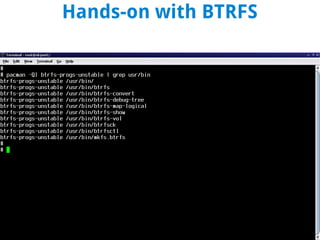
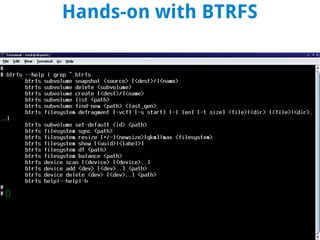
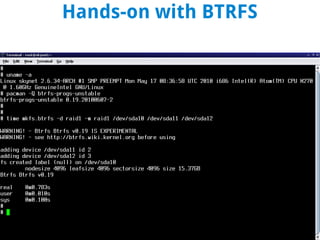
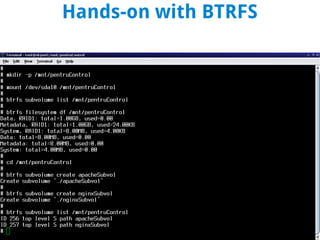
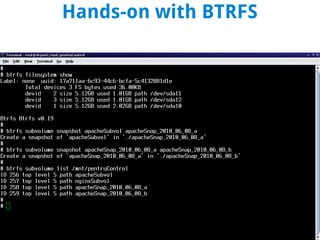



BTRFS is a copy-on-write filesystem for Linux that aims to provide scalable storage, simplified administration, fault tolerance, and easy snapshots. It combines the functionality of a filesystem, volume manager, and RAID controller. While not fully implemented yet, BTRFS goals include self-healing capabilities to avoid data corruption, dynamic allocation of inodes, and space-efficient storage of small files. It shares some similarities with ZFS but was designed for the Linux kernel. Subvolumes allow independent filesystem-like structures that share storage. Snapshots capture the state of subvolumes but writable snapshots are currently the only option. BTRFS continues developing features like read-only snapshots and self-healing capabilities.


























































































