Downloaded 80 times







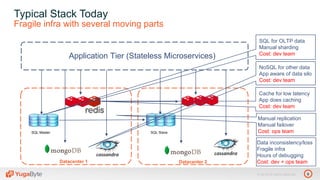
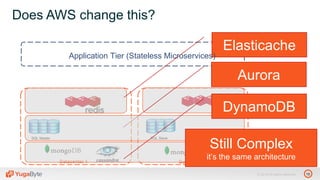





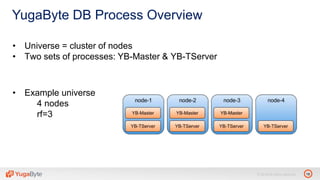
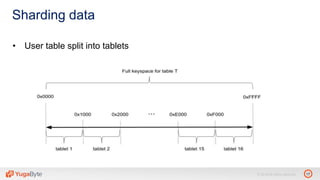
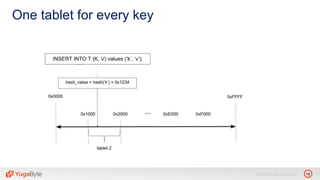
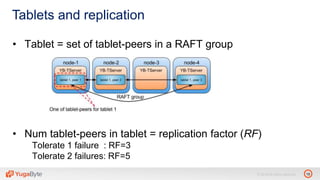
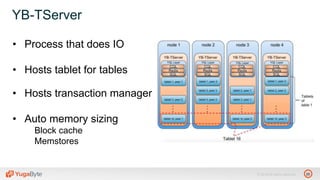
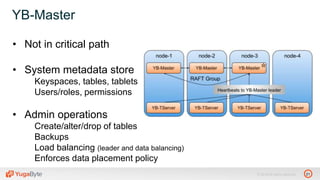

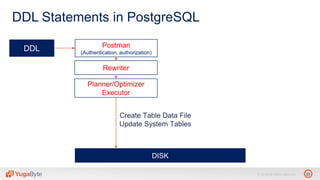
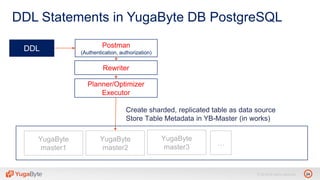
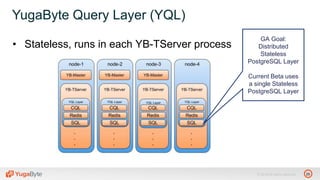

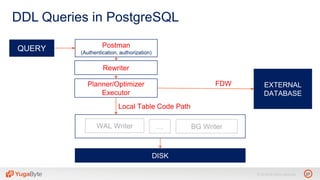
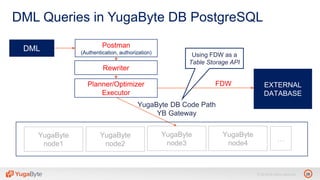







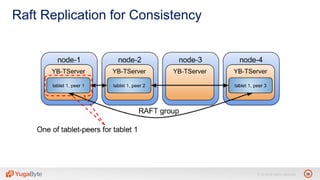
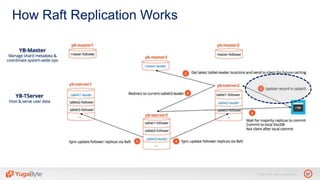
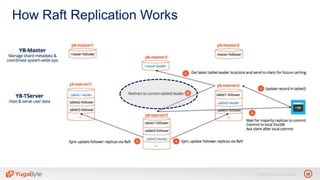
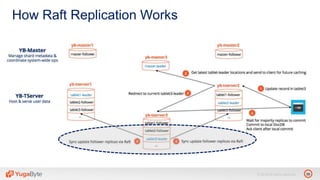
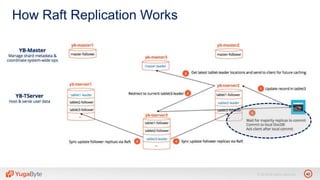


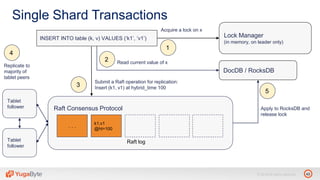



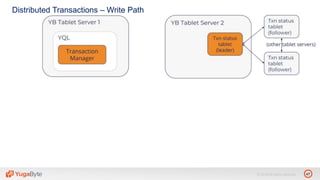
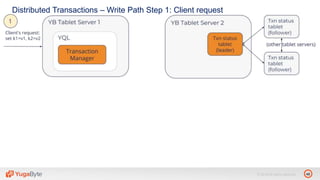
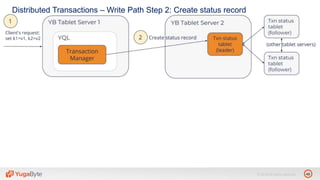
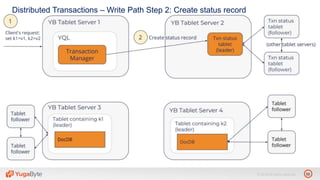
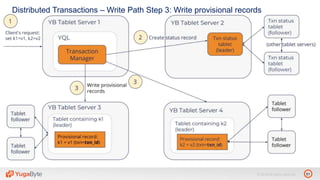
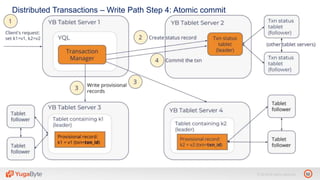
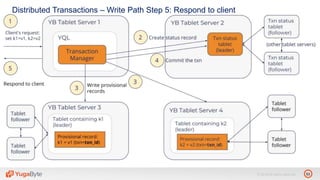
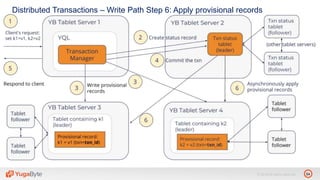


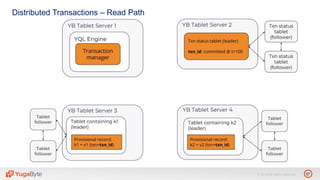
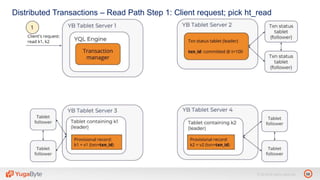
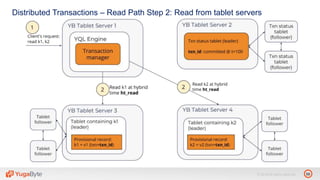
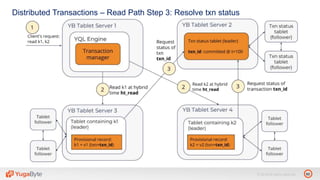
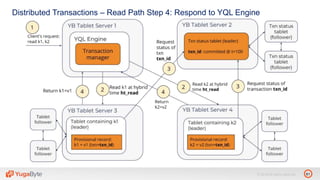
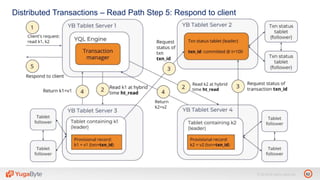




The document discusses YugabyteDB, a transactional database designed for high-performance cloud services, founded by engineers with experience at companies like Facebook and Oracle. It covers its unique architecture, which features automatic sharding, fault tolerance, and a focus on cloud-native deployment, as well as the transaction processing capabilities, including single and distributed transactions. A workshop agenda is outlined, including practical exercises aimed at demonstrating YugabyteDB's capabilities and functionality.





















![[Meetup] a successful migration from elastic search to clickhouse](https://cdn.slidesharecdn.com/ss_thumbnails/meetupasuccessfulmigrationfromelasticsearchtoclickhouse-191004114403-thumbnail.jpg?width=640&height=640&fit=bounds)












































