公開URL:http://fastdepth.mit.edu/2019_icra_fastdepth.pdf
出典:Diana Wofk, Fangchang Ma, Tien-Ju Yang, Sertac Karaman, FastDepth: Fast Monocular Depth Estimation on Embedded Systems, 2019 International Conference on Robotics and Automation (ICRA), Montreal, Canada (2019)
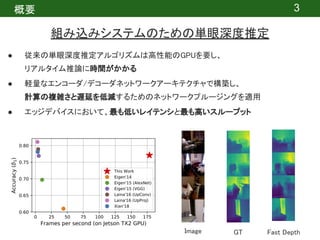
概要:深度推定は、マッピングや障害物検出などのロボットタスクにおいて重要な機能です。最近では、高コストな深度センサによる深度推定ではなく、安価な単眼カメラによる深度推定に関心が寄せられています。しかし、最先端の単眼深度推定は複雑なディープラーニングネットワークをベースにしており、リアルタイム推論に時間がかかります。このような背景から、組み込みシステム上での高速深度推定の問題に取り組み、軽量なエンコーダ/デコーダネットワークを提案しています。




![関連研究 | 単眼深度推定
Monocular Relative Depth Perception with Web
Stereo Data Supervision [1]
6
Deeper Depth Prediction with Fully
Convolutional Residual Networks[2]
関連研究 | 単眼深度推定 (Monocular Depth Estimation)
どちらも高精度なモデルを作成するアプローチ
[1] Xian, Ke, et al. "Monocular relative depth perception with web stereo data supervision." Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition. 2018.
[2] Laina, Iro, et al. "Deeper depth prediction with fully convolutional residual networks." 2016 Fourth international conference on 3D vision (3DV). IEEE, 2016.](https://image.slidesharecdn.com/20200715dlseminermori-200715064339/85/FastDepth-Fast-Monocular-Depth-Estimation-on-Embedded-Systems-6-320.jpg)

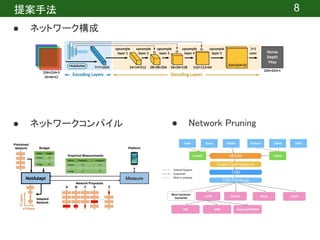
![提案手法 | ネットワーク構成
9
Fully convolutional encoder-decoder
入力サイズと同じ出力サイズを出力するには、”Fully Convolutional”が効果的[3]
全結合層を1×1の畳み込みで置き換える
[3] Long, Jonathan, Evan Shelhamer, and Trevor Darrell. "Fully convolutional networks for semantic
segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.](https://image.slidesharecdn.com/20200715dlseminermori-200715064339/85/FastDepth-Fast-Monocular-Depth-Estimation-on-Embedded-Systems-9-320.jpg)
![提案手法 | ネットワーク構成
10
● 低レイテンシを目標とし、MobileNet_v1[4]を採用
[4] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “MobileNets: Efficient
convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861, 2017.
(a) 通常の畳み込み演算
(b) 下がMobileNetの畳み込み演算
空間方向とチャネル方向の畳み込みを同時に行わず、
Depthwise(空間方向)とPointwise(チャネル方向)を順に行う
m×m×nの標準的な畳込みレイヤの場合
MAC(積和演算)の回数がm 倍少ない
2](https://image.slidesharecdn.com/20200715dlseminermori-200715064339/85/FastDepth-Fast-Monocular-Depth-Estimation-on-Embedded-Systems-10-320.jpg)


![提案手法 | ネットワークコンパイル
● TVMコンパイラスタック[5]を使用
○ ハードウェア上でのランタイム削減のために最適化
13
[5] T. Chen, T. Moreau, Z. Jiang, L. Zheng, E. Yan, H. Shen, M. Cowan, L. Wang, Y. Hu, L. Ceze et al., “TVM: An
Automated End-to-End Optimizing Compiler for Deep Learning,” in 13th USENIX Symposium on Operating Systems
Design and Implementation (OSDI 18), 2018, pp. 578–594.
web: https://tvm.apache.org/2017/10/06/nnvm-compiler-announcement](https://image.slidesharecdn.com/20200715dlseminermori-200715064339/85/FastDepth-Fast-Monocular-Depth-Estimation-on-Embedded-Systems-13-320.jpg)
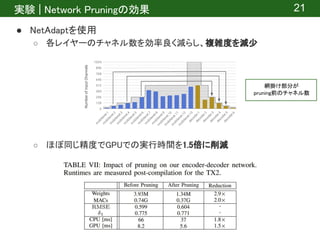
![提案手法 | Network Pruning
● NetAdapt[6]を使用
○ 使用率の低いアクティベーションチャネルを減少させる
○ 精度と複雑さのトレードオフで最も良いネットワーク提案
14
[6] T.-J. Yang, A. Howard, B. Chen, X. Zhang, A. Go, M. Sadler, V. Sze, and H. Adam, “NetAdapt: PlatformAware Neural Network
Adaptation for Mobile Applications,” in European Conference on Computer Vision (ECCV), 2018.
・github | https://github.com/denru01/netadapt/](https://image.slidesharecdn.com/20200715dlseminermori-200715064339/85/FastDepth-Fast-Monocular-Depth-Estimation-on-Embedded-Systems-14-320.jpg)
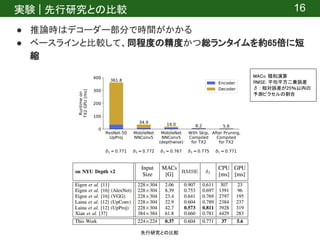
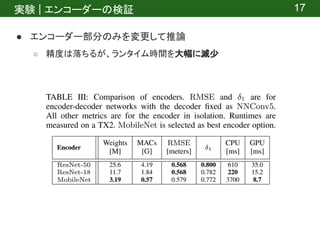
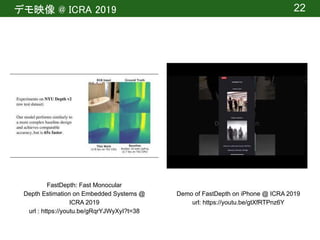
![実験 | 設定
● データセット
○ NYU Depth Dataset v2 [7]
■ Microsoft Kinectで撮影した室内の画像(1449個)
■ ダウンロードurl: https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
● エンコーダー
○ ImageNetで事前学習
● プラットフォーム
○ Jetson TX2
● 実験概要
○ 先行研究との比較
○ エンコーダーの検証
○ デコーダーの検証
○ Network Pruningの効果
15
[7] N. Silberman, D. Hoiem, P. Kohli, and R. Fergus, “Indoor segmentation and support inference from RGBD images,” in
European Conference on Computer Vision (ECCV), 2012, pp. 746–760.
サンプル画像
推論の時間と精度を確認](https://image.slidesharecdn.com/20200715dlseminermori-200715064339/85/FastDepth-Fast-Monocular-Depth-Estimation-on-Embedded-Systems-15-320.jpg)








![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Model soups: averaging weights of multiple fine-tuned models improves ...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0401-220405031053-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Geometric Unsupervised Domain Adaptation for Semantic Segmentation](https://cdn.slidesharecdn.com/ss_thumbnails/20220121gudalin-220121050547-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Depth Prediction Without the Sensors: Leveraging Structure for Unsuper...](https://cdn.slidesharecdn.com/ss_thumbnails/struct2depth0301-190304050917-thumbnail.jpg?width=640&height=640&fit=bounds)

![[CVPR2020読み会@CV勉強会] 3D Packing for Self-Supervised Monocular Depth Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/202007043dpackingforself-supervisedmonoculardepthestimation-200704035538-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Deep Face Recognition: A Survey](https://cdn.slidesharecdn.com/ss_thumbnails/20181221-181221023935-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Unsupervised Learning of 3D Structure from Images](https://cdn.slidesharecdn.com/ss_thumbnails/sugihara-161213071700-thumbnail.jpg?width=640&height=640&fit=bounds)





















