Downloaded 50 times



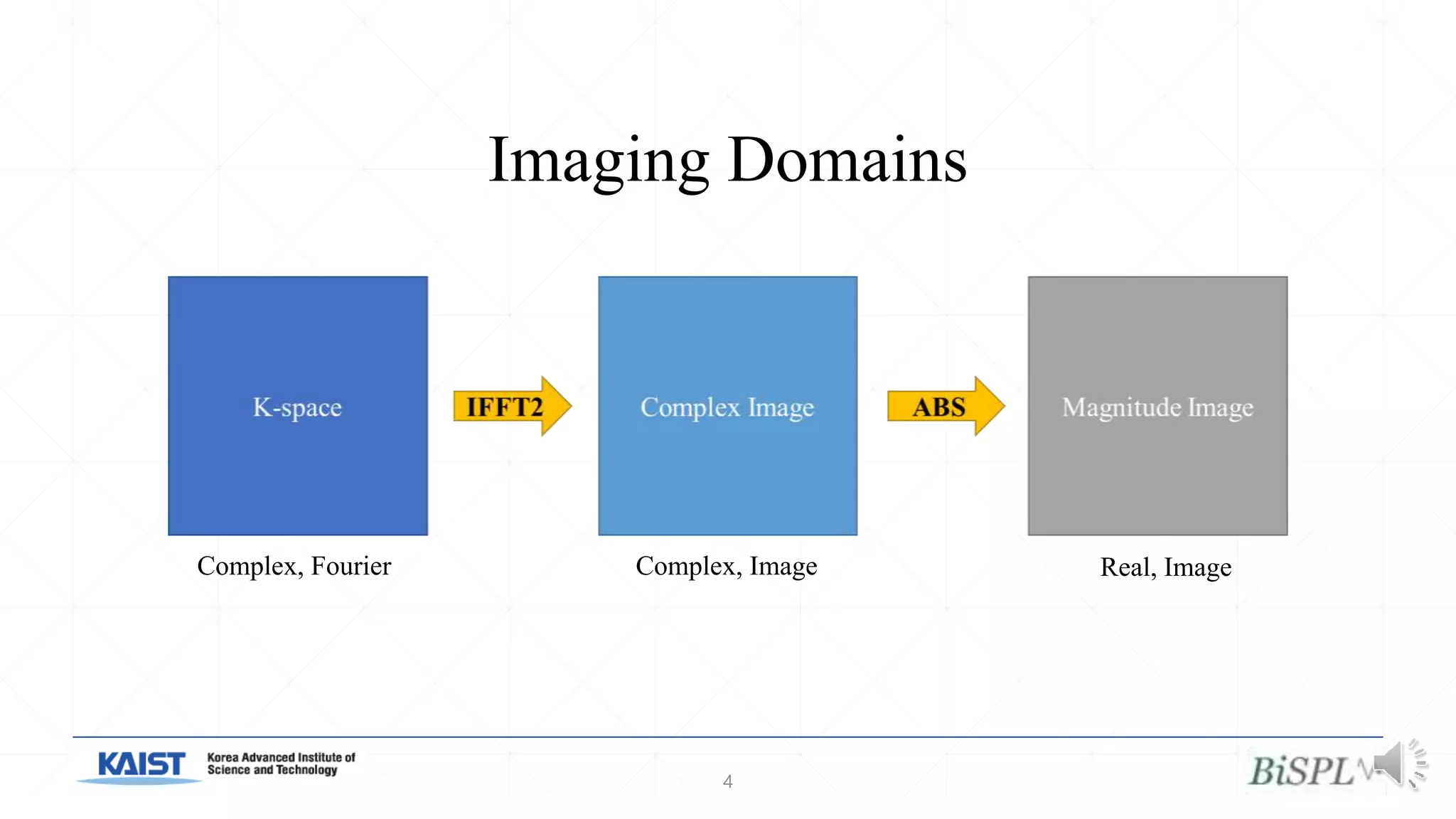
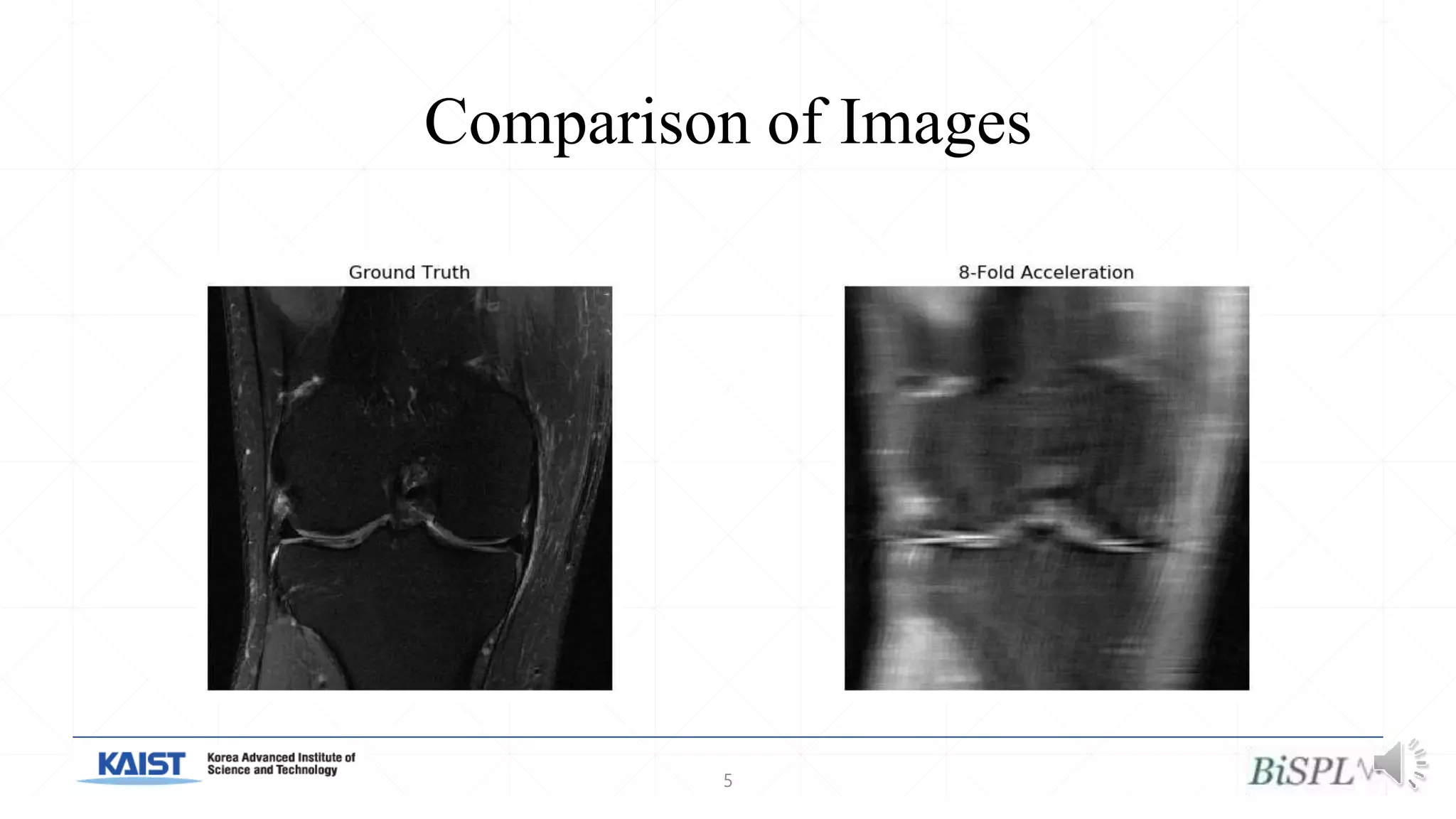



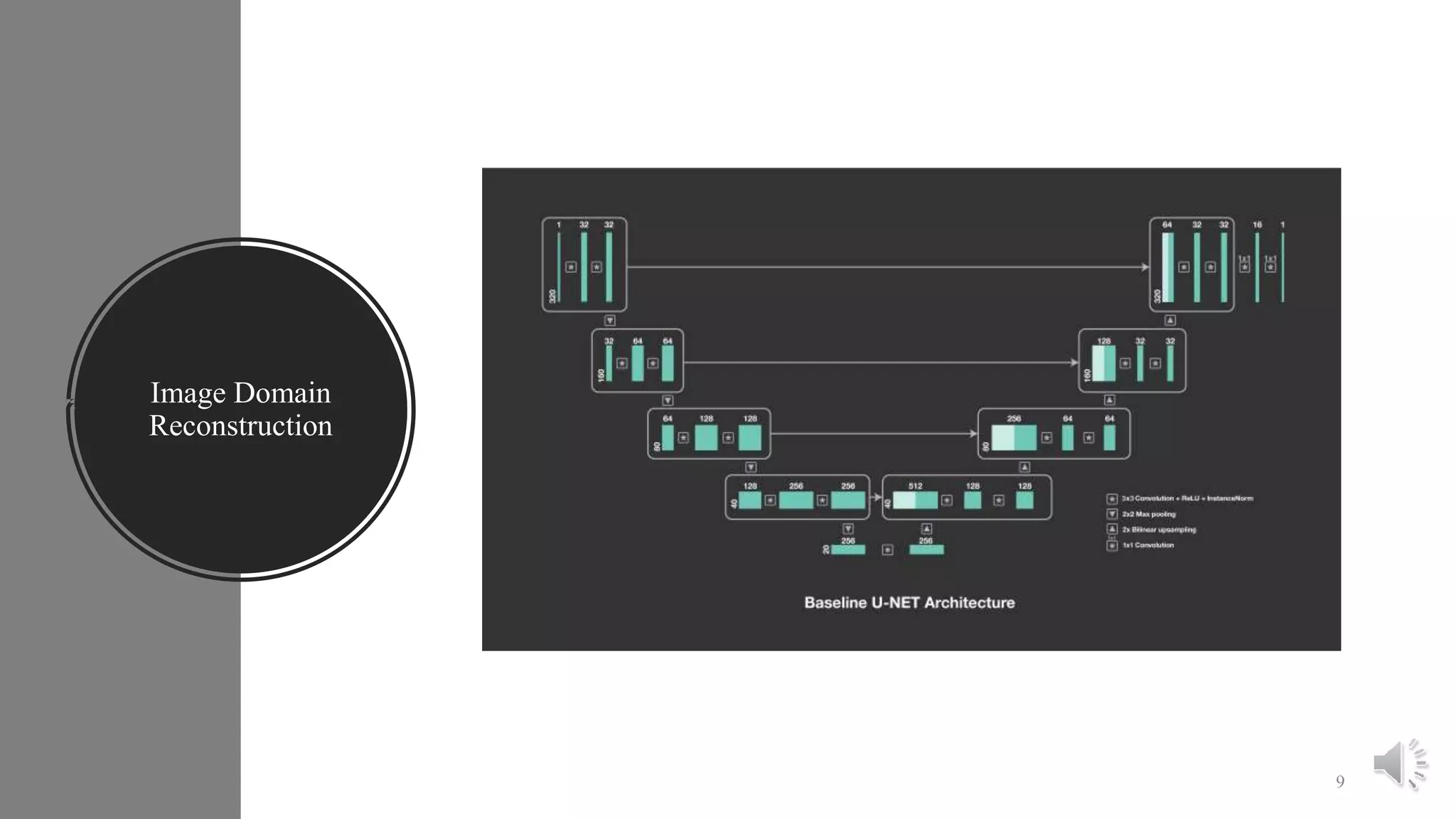
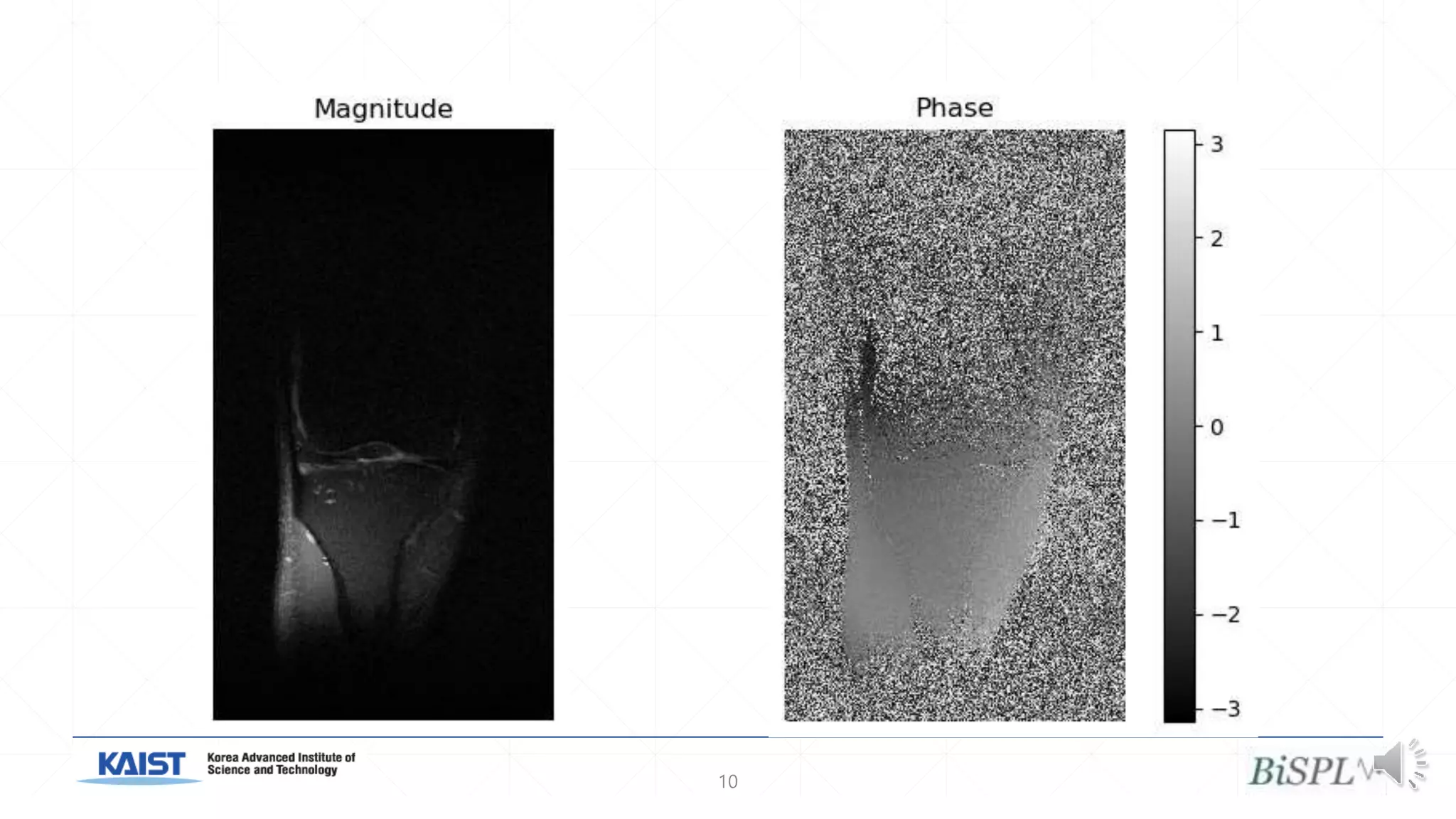
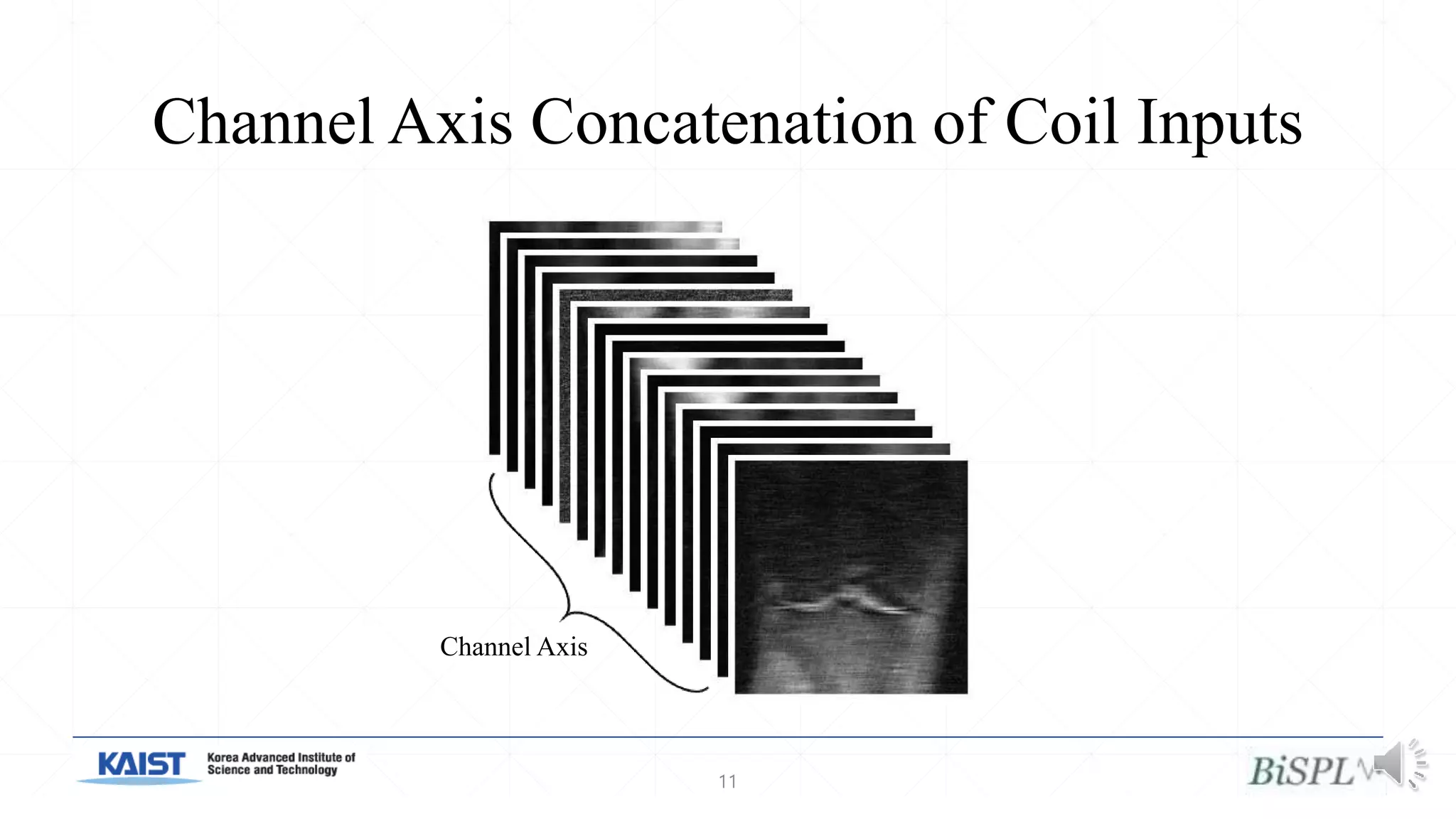
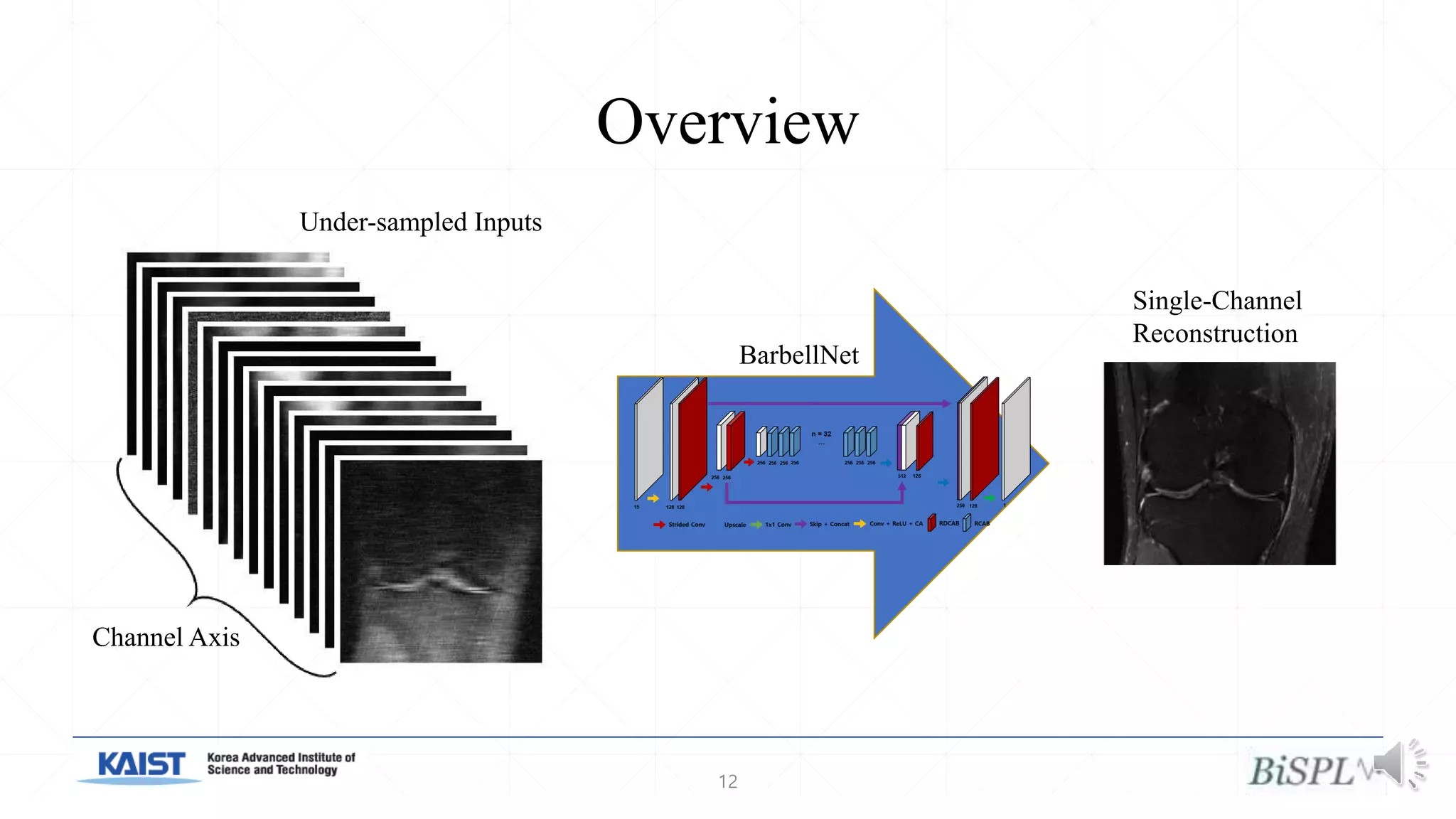
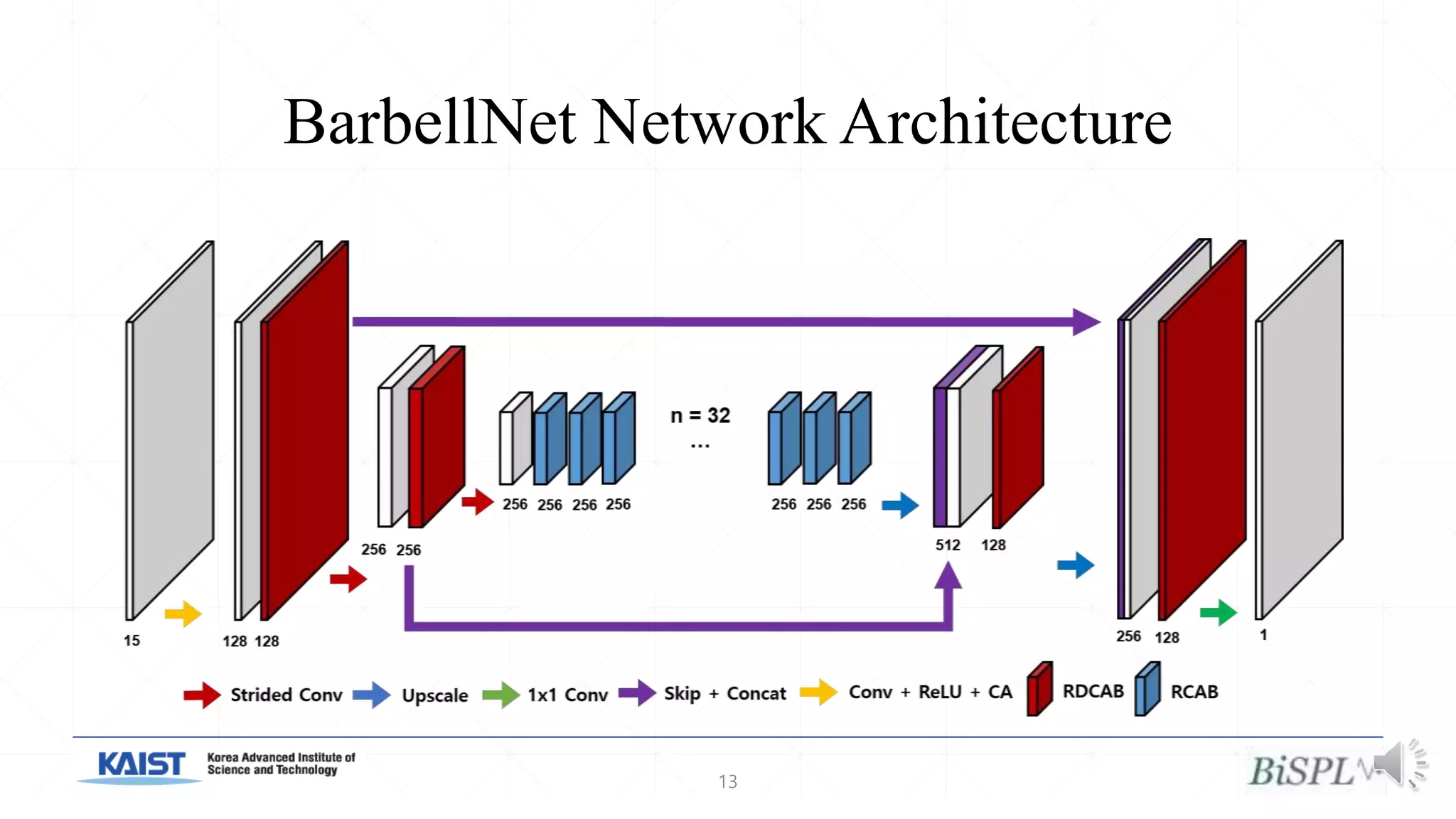



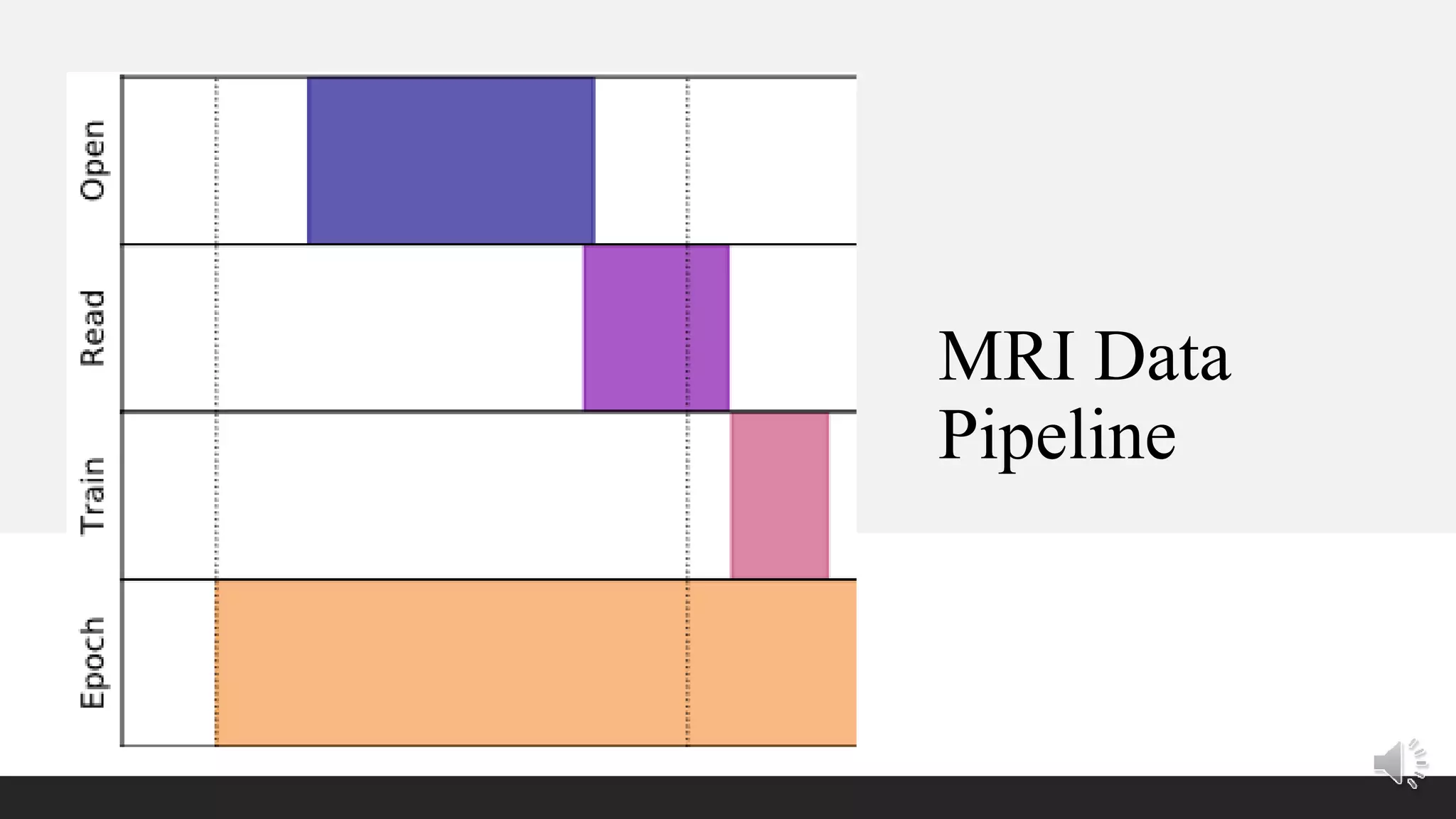


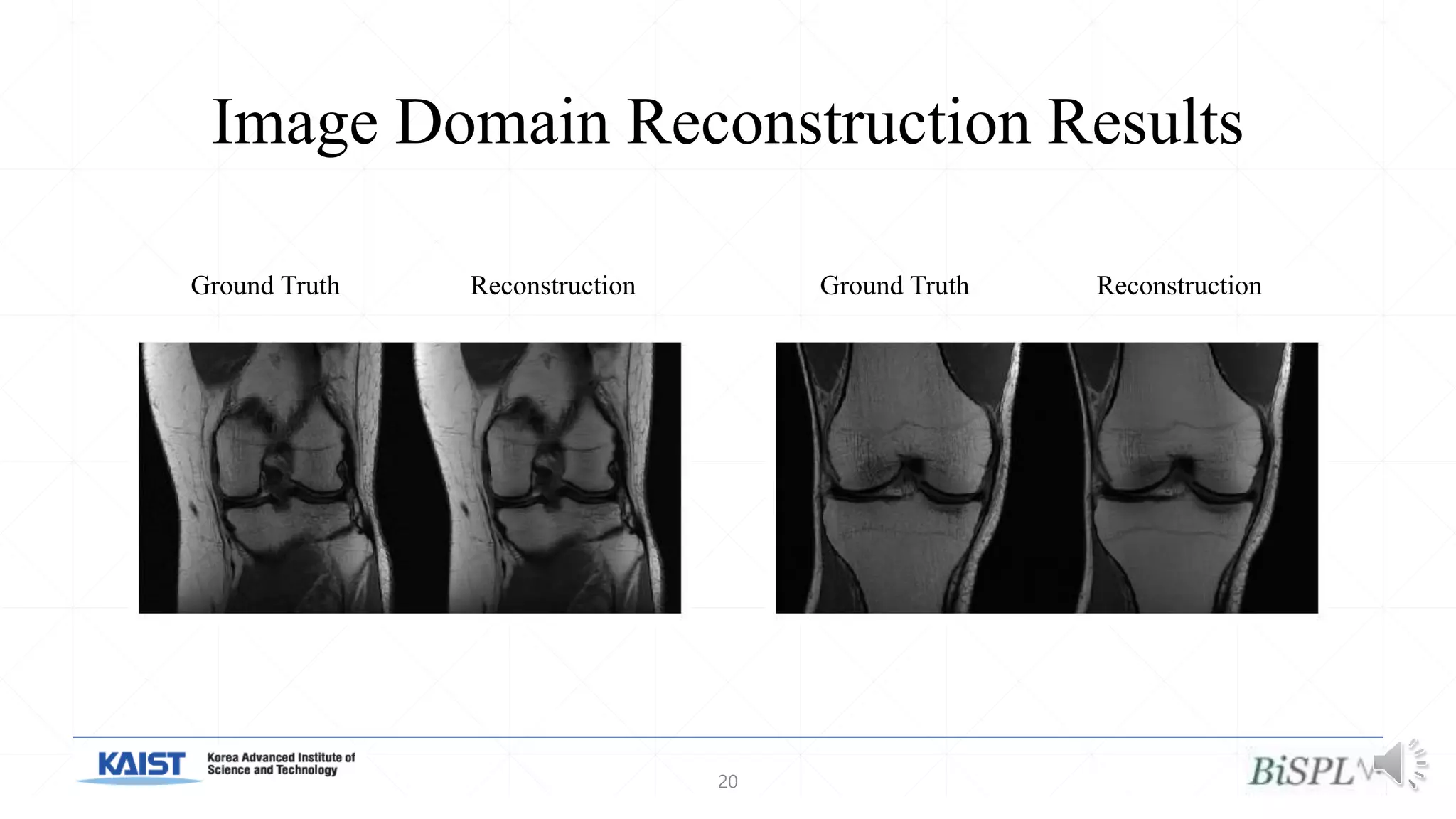
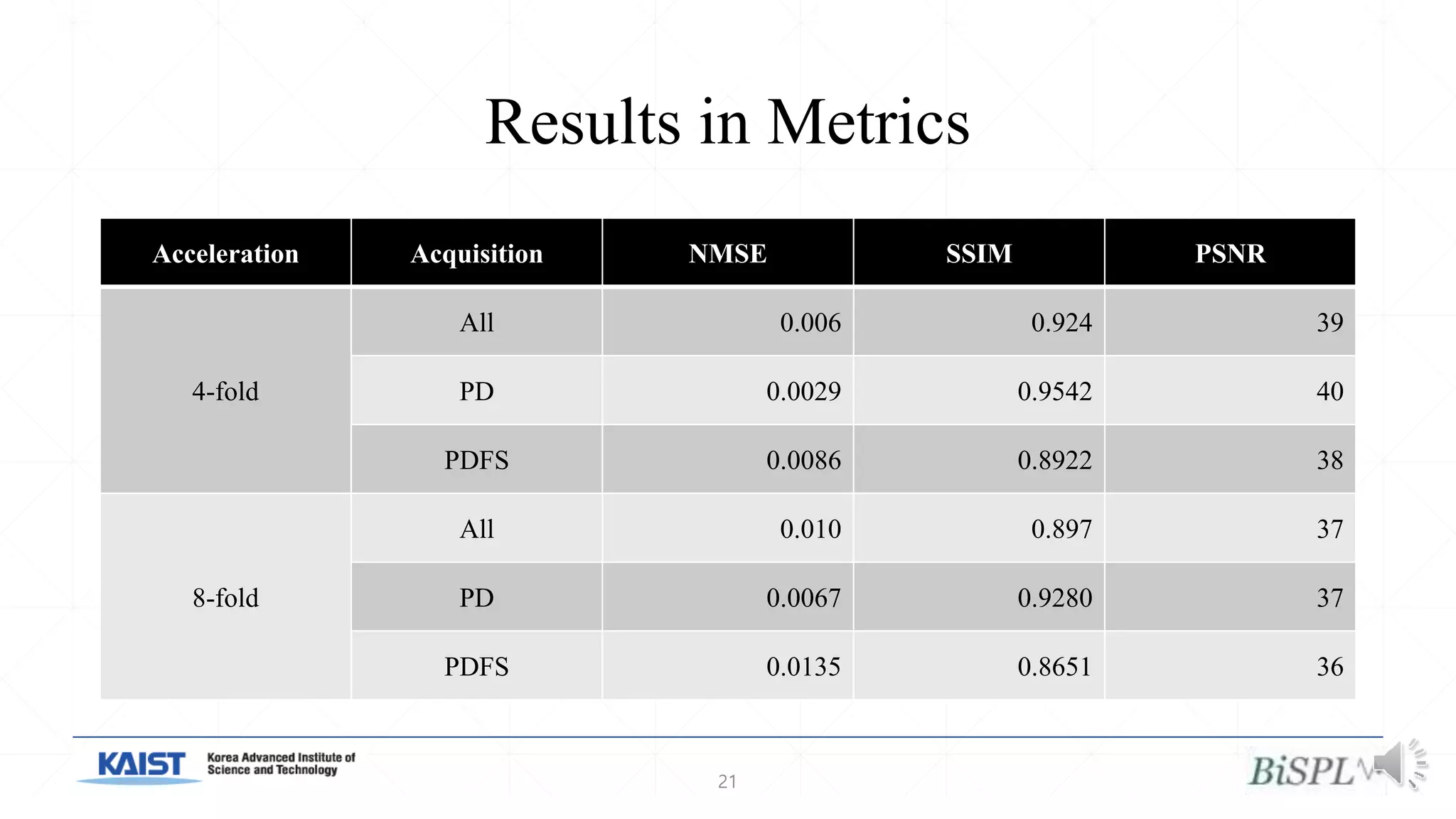
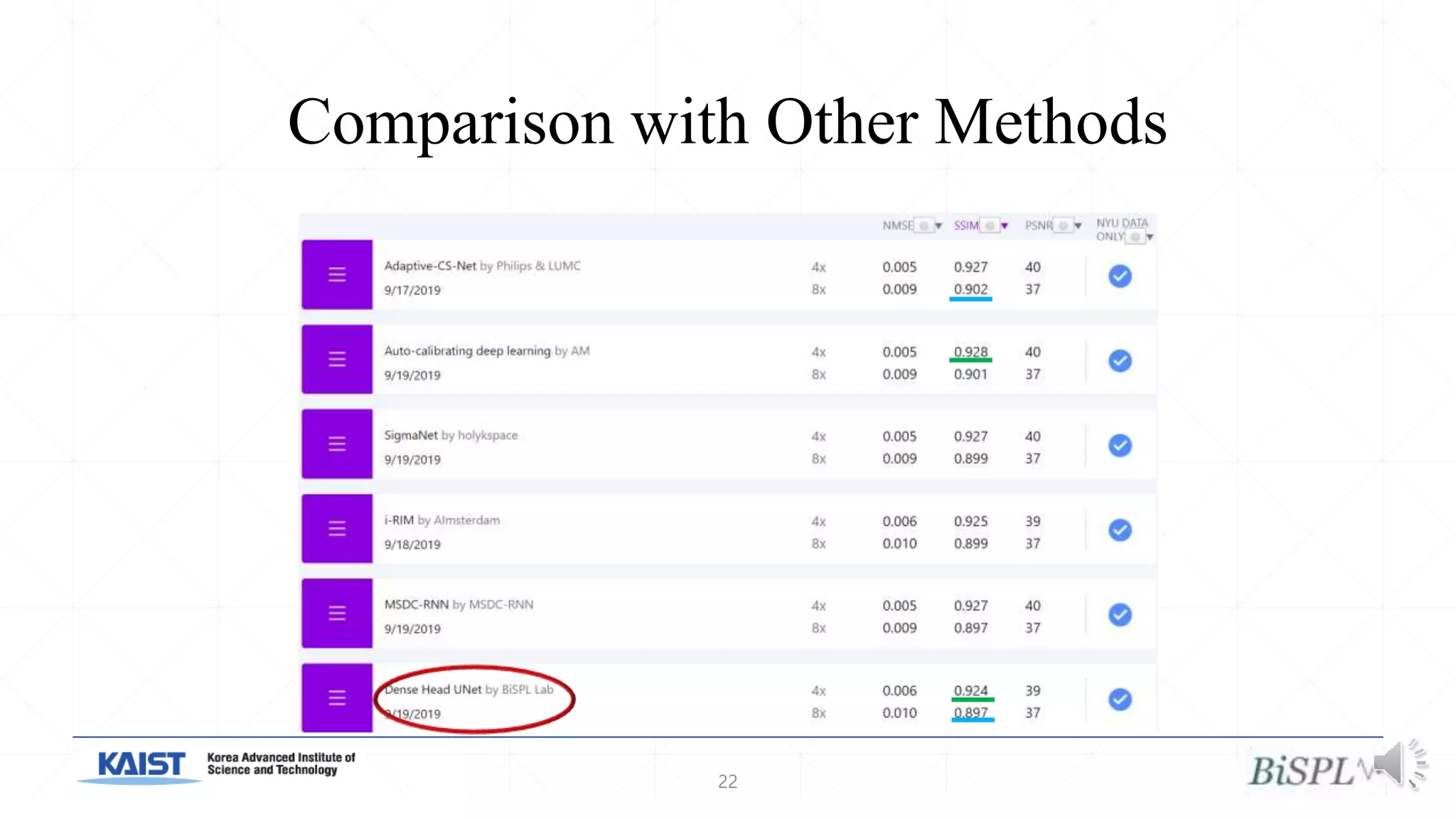

The document presents a method for accelerated parallel MRI using deep learning and discusses the challenges of using k-space data, which comprises complex values. Solutions include concatenating coil inputs, using magnitude images as input, and implementing a specific network architecture for reconstruction. Practical implementation tips and results from image domain reconstruction experiments are also provided, showcasing various performance metrics.

![[MICCAI 2022] Meta-hallucinator: Towards Few-Shot Cross-Modality Cardiac Imag...](https://cdn.slidesharecdn.com/ss_thumbnails/presentation-copy-220925094724-ff51f7fd-thumbnail.jpg?width=640&height=640&fit=bounds)












































































