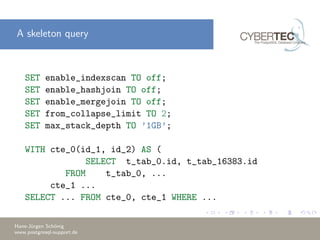
The document discusses the challenges and solutions encountered while attempting to create and join 1 million tables in PostgreSQL. It details the limitations of the database, including memory constraints and planning time, and explores workarounds such as adjusting configurations and using Common Table Expressions (CTEs) for better performance. Ultimately, after significant adjustments, the task was successfully completed with a substantial runtime and memory requirement.

















![This is how PostgreSQL joins tables:
Tables a, b, c, d form the following joins of 2:
[a, b], [a, c], [a, d], [b, c], [b, d], [c, d]
By adding a single table to each group, the following joins of 3 are
constructed:
[[a, b], c], [[a, b], d], [[a, c], b], [[a, c], d], [[a, d], b], [[a, d], c], [[b,
c], a], [[b, c], d], [[b, d], a], [[b, d], c], [[c, d], a], [[c, d], b]
Hans-J¨urgen Sch¨onig
www.postgresql-support.de](https://image.slidesharecdn.com/1million-150312025557-conversion-gate01/85/PostgreSQL-Joining-1-million-tables-19-320.jpg)
![More joining
Likewise, add a single table to each to get the final joins:
[[[a, b], c], d], [[[a, b], d], c], [[[a, c], b], d], [[[a, c], d], b], [[[a, d],
b], c], [[[a, d], c], b], [[[b, c], a], d], [[[b, c], d], a], [[[b, d], a], c],
[[[b, d], c], a], [[[c, d], a], b], [[[c, d], b], a]
Got it? ;)
Hans-J¨urgen Sch¨onig
www.postgresql-support.de](https://image.slidesharecdn.com/1million-150312025557-conversion-gate01/85/PostgreSQL-Joining-1-million-tables-20-320.jpg)
![A little patching
A little patch ensures that the list of tables is grouped into
“sub-lists”, where the length of each sub-list is equal to
from collapse limit. If from collapse limit is 2, the list of 4
becomes . . .
[[a, b], [c, d]]
[a, b] and [c, d] are joined separately, so we only get
one “path”:
[[a, b], [c, d]]
Hans-J¨urgen Sch¨onig
www.postgresql-support.de](https://image.slidesharecdn.com/1million-150312025557-conversion-gate01/85/PostgreSQL-Joining-1-million-tables-21-320.jpg)

















![[NDC17] Kubernetes로 개발서버 간단히 찍어내기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-170529041601-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Pgday.Seoul 2017] 6. GIN vs GiST 인덱스 이야기 - 박진우](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-171106044702-thumbnail.jpg?width=640&height=640&fit=bounds)












































![[PGDay.Seoul 2020] PostgreSQL 13 New Features](https://cdn.slidesharecdn.com/ss_thumbnails/2020pgdayseoulpostgresql13newfeatures-201116014501-thumbnail.jpg?width=640&height=640&fit=bounds)


![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)

















