Download as PDF, PPTX








![EXTRACTING BLACK ROOKS
object BlackRook {
def unapply(rook: Rook): Option[(Int, Int)] =
if (rook.isBlack) Some((rook.x, rook.y)) else None
}](https://image.slidesharecdn.com/hpswt-scala-days-berlin-2018-180527172351/85/High-Performance-Systems-Without-Tears-Scala-Days-Berlin-2018-8-320.jpg)
![EXTRACTING BLACK ROOKS
public unapply(Lextractors/Rook;)Lscala/Option;
L0
LINENUMBER 5 L0
ALOAD 1
INVOKEVIRTUAL extractors/Rook.isBlack ()Z
IFEQ L1
NEW scala/Some
DUP
NEW scala/Tuple2$mcII$sp
DUP
. . .
object BlackRook {
def unapply(rook: Rook): Option[(Int, Int)] =
if (rook.isBlack) Some((rook.x, rook.y)) else None
}](https://image.slidesharecdn.com/hpswt-scala-days-berlin-2018-180527172351/85/High-Performance-Systems-Without-Tears-Scala-Days-Berlin-2018-9-320.jpg)
![EXTRACTING BLACK ROOKS
public unapply(Lextractors/Rook;)Lscala/Option;
L0
LINENUMBER 5 L0
ALOAD 1
INVOKEVIRTUAL extractors/Rook.isBlack ()Z
IFEQ L1
NEW scala/Some
DUP
NEW scala/Tuple2$mcII$sp
DUP
. . .
object BlackRook {
def unapply(rook: Rook): Option[(Int, Int)] =
if (rook.isBlack) Some((rook.x, rook.y)) else None
}](https://image.slidesharecdn.com/hpswt-scala-days-berlin-2018-180527172351/85/High-Performance-Systems-Without-Tears-Scala-Days-Berlin-2018-10-320.jpg)

 extends AnyVal {
def isEmpty: Boolean = extraction eq null
def get: T = extraction
}
def unapply(rook: Rook): Extractor[(Int, Int)] =
if (rook.isBlack)
new Extractor((rook.x, rook.y))
else
new Extractor(null)
}](https://image.slidesharecdn.com/hpswt-scala-days-berlin-2018-180527172351/85/High-Performance-Systems-Without-Tears-Scala-Days-Berlin-2018-12-320.jpg)












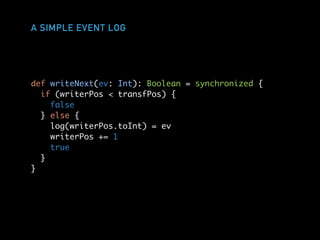
![A SIMPLE EVENT LOG
trait EventLog[T] {
def writeNext(ev: T): Boolean
def transformNext(f: T => T): Boolean
}](https://image.slidesharecdn.com/hpswt-scala-days-berlin-2018-180527172351/85/High-Performance-Systems-Without-Tears-Scala-Days-Berlin-2018-43-320.jpg)
](https://image.slidesharecdn.com/hpswt-scala-days-berlin-2018-180527172351/85/High-Performance-Systems-Without-Tears-Scala-Days-Berlin-2018-44-320.jpg)
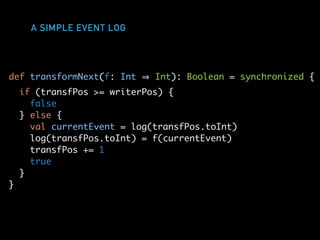




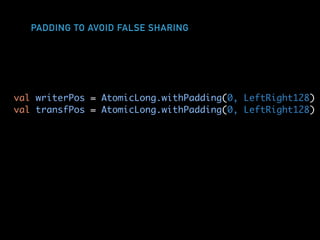
def writeNext(ev: Int): Boolean = {
val currentWriterPos = writerPos.get
if (currentWriterPos < transfPos.get) {
false
} else {
log(currentWriterPos.toInt) = ev
writerPos.lazySet(currentWriterPos + 1)
true
}
}](https://image.slidesharecdn.com/hpswt-scala-days-berlin-2018-180527172351/85/High-Performance-Systems-Without-Tears-Scala-Days-Berlin-2018-53-320.jpg)







![CLIENT ACTOR
class UserQueryActor(latch: CountDownLatch,
numQueries: Int,
numUsersInDB: Int) extends Actor {
private var left = numQueries
private val receivedUsers: mutable.Map[Int, User] = mutable.Map()
private val randGenerator = new Random()
override def receive: Receive = {
case u: User {
receivedUsers.put(u.userId, u)
if (left == 0) {
latch.countDown()
context stop self
} else {
sender() ! Request(randGenerator.nextInt(numUsersInDB))
}
left -= 1
}
}
}](https://image.slidesharecdn.com/hpswt-scala-days-berlin-2018-180527172351/85/High-Performance-Systems-Without-Tears-Scala-Days-Berlin-2018-70-320.jpg)
![SERVICE ACTOR
class UserServiceActor(userDb: Map[Int, User],
latch: CountDownLatch,
numQueries: Int) extends Actor {
private var left = numQueries
def receive = {
case Request(id)
userDb.get(id) match {
case Some(u) sender() ! u
case None
}
if (left == 0) {
latch.countDown()
context stop self
}
left -= 1
}
}](https://image.slidesharecdn.com/hpswt-scala-days-berlin-2018-180527172351/85/High-Performance-Systems-Without-Tears-Scala-Days-Berlin-2018-71-320.jpg)
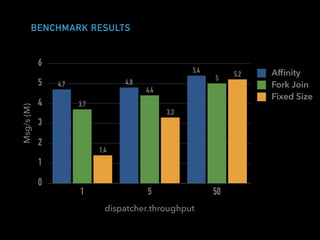



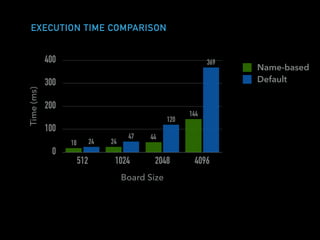
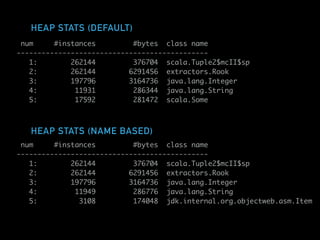
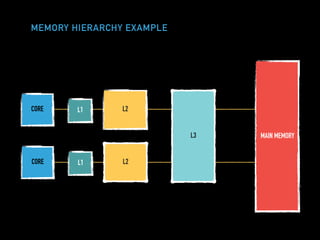
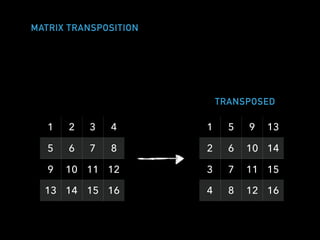
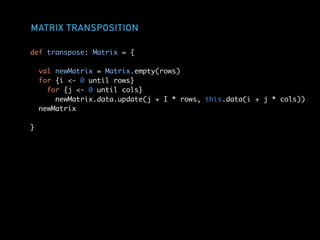
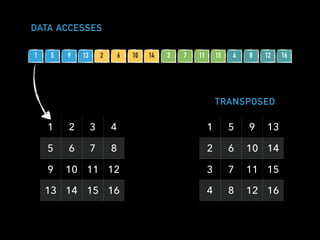
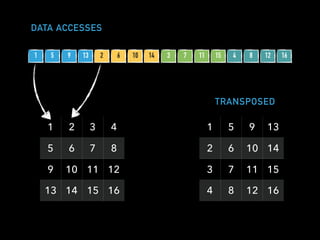
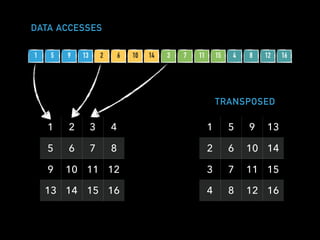
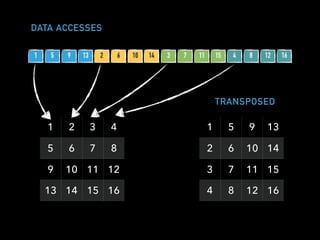
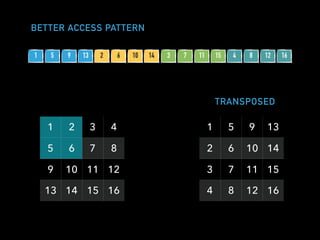
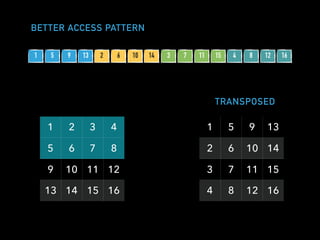
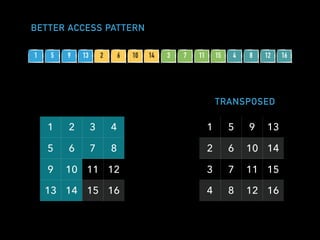
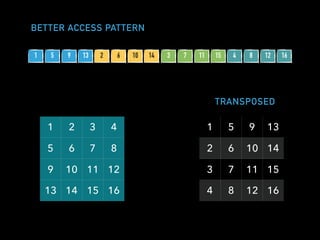
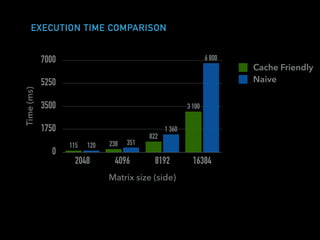
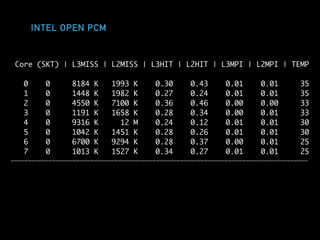
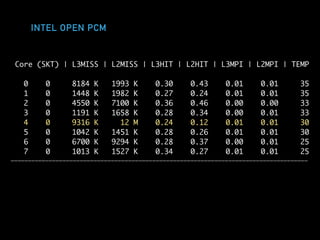
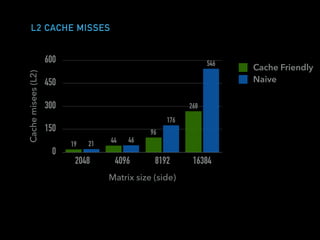
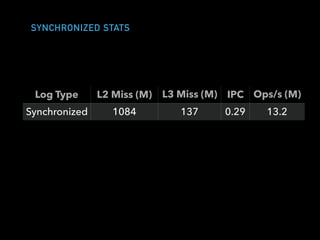
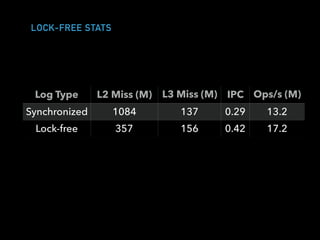
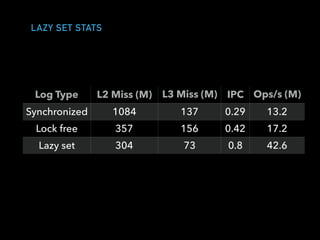
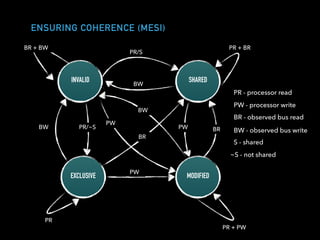
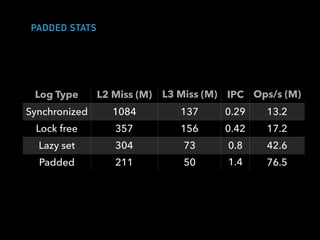
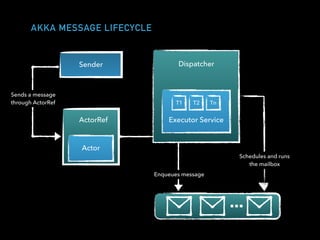
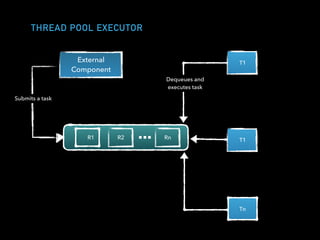
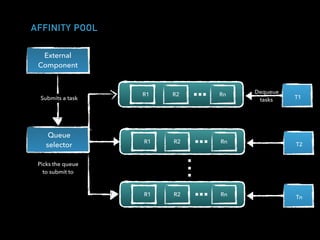
The document discusses techniques for improving performance in Scala applications by reducing object allocation and improving data locality. It describes how excessive object instantiation can hurt performance by increasing garbage collection work and introducing non-determinism. Extractor objects are presented as a tool for pattern matching that can improve brevity and expressiveness. Name-based extractors introduced in Scala 2.11 avoid object allocation. The talk also covers how caching hierarchies work to reduce memory access latency and the importance of data access patterns for effective cache utilization. Cache-oblivious algorithms are designed to optimize memory hierarchy usage without knowing cache details. Synchronization is noted to have performance costs as well in an example event log implementation.










![Pepe Vila - Cache and Syphilis [rooted2019]](https://cdn.slidesharecdn.com/ss_thumbnails/cacheandsyphilisfinal-190403201112-thumbnail.jpg?width=640&height=640&fit=bounds)































![[Paper reading] Interleaving with Coroutines: A Practical Approach for Robust...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadinginterleavingwithcoroutinesapracticalapproachforrobustindexjoin-211011055753-thumbnail.jpg?width=640&height=640&fit=bounds)
























