Downloaded 212 times




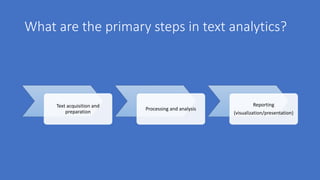





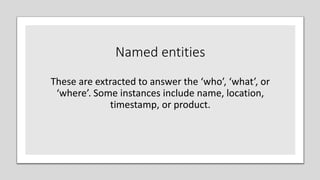















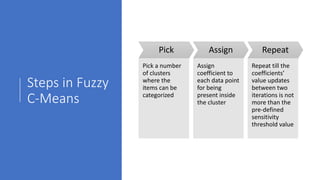


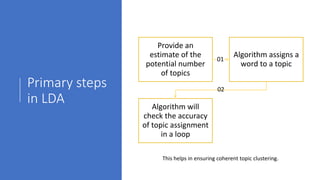



Text analytics is used to extract structured data from unstructured text sources like social media posts, reviews, emails and call center notes. It involves acquiring and preparing text data, processing and analyzing it using algorithms like decision trees, naive bayes, support vector machines and k-nearest neighbors to extract terms, entities, concepts and sentiment. The results are then visualized to support data-driven decision making for applications like measuring customer opinions and providing search capabilities. Popular tools for text analytics include RapidMiner, KNIME, SPSS and R.























































































