Downloaded 20 times







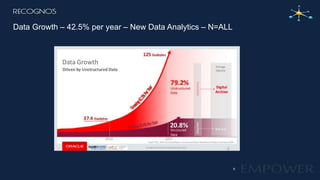




























































This document provides an overview of how to prepare unstructured data for business intelligence and data analytics. It discusses structured, semi-structured, and unstructured data types. It then introduces Recognos' platform called ETI, which uses human-assisted machine learning to extract and integrate data from unstructured documents. ETI can extract data from documents that contain classifiable content through predefined field definitions and templates. It also discusses the challenges of extracting tables and derived fields that require semantic analysis. The document concludes with examples of using extracted data for compliance applications and creating data teams to manage the extraction process over time.











































































