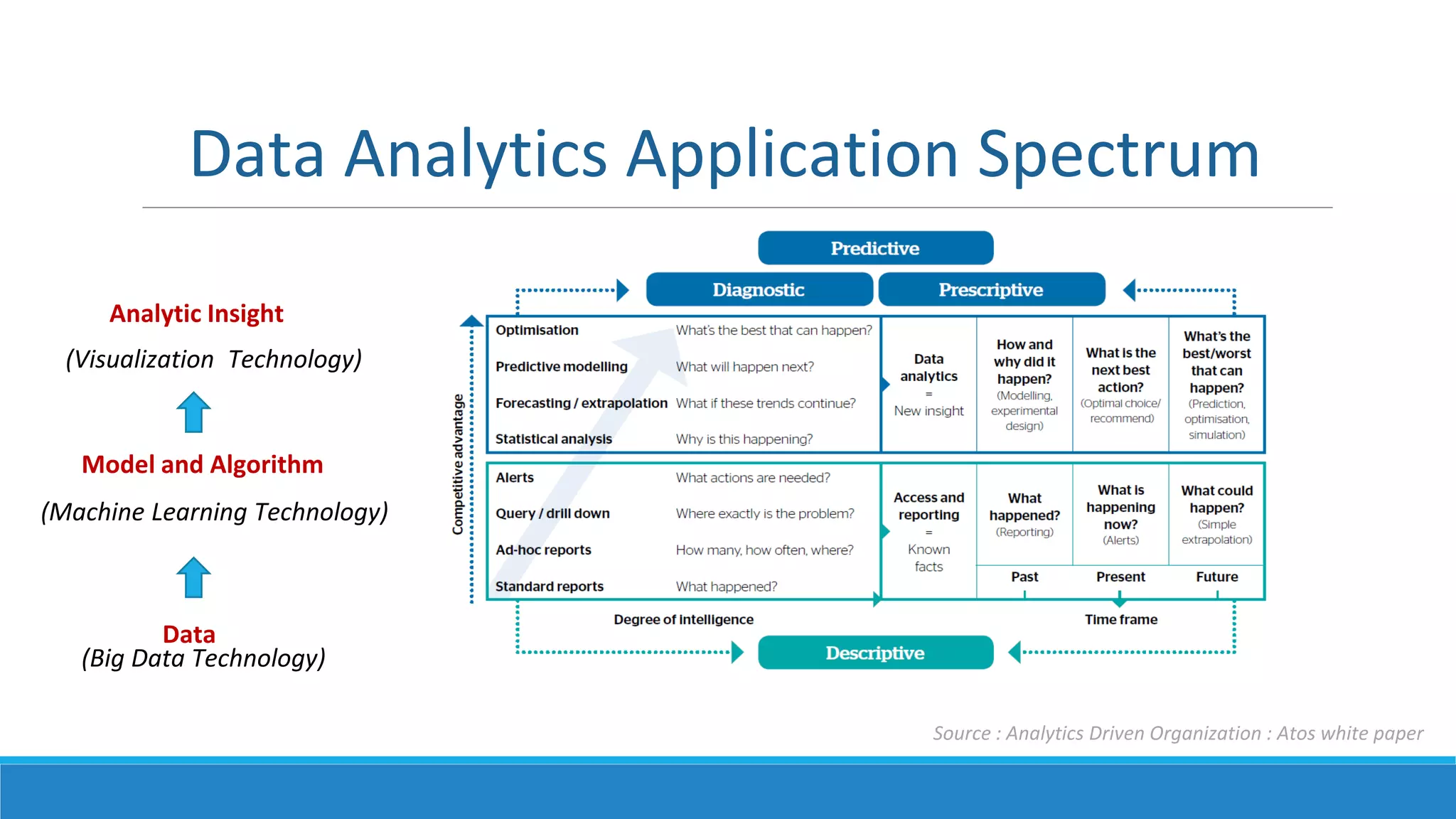
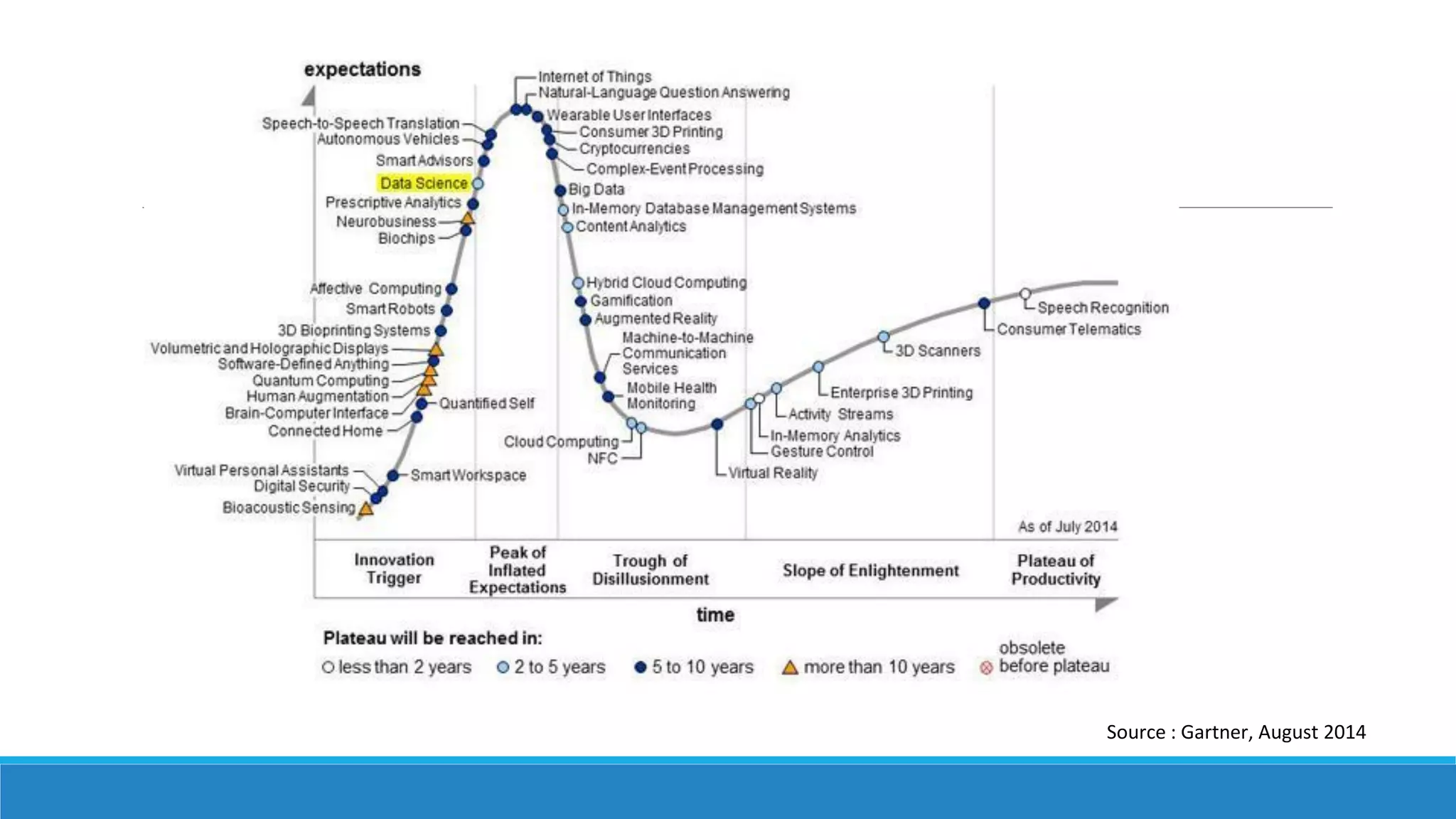
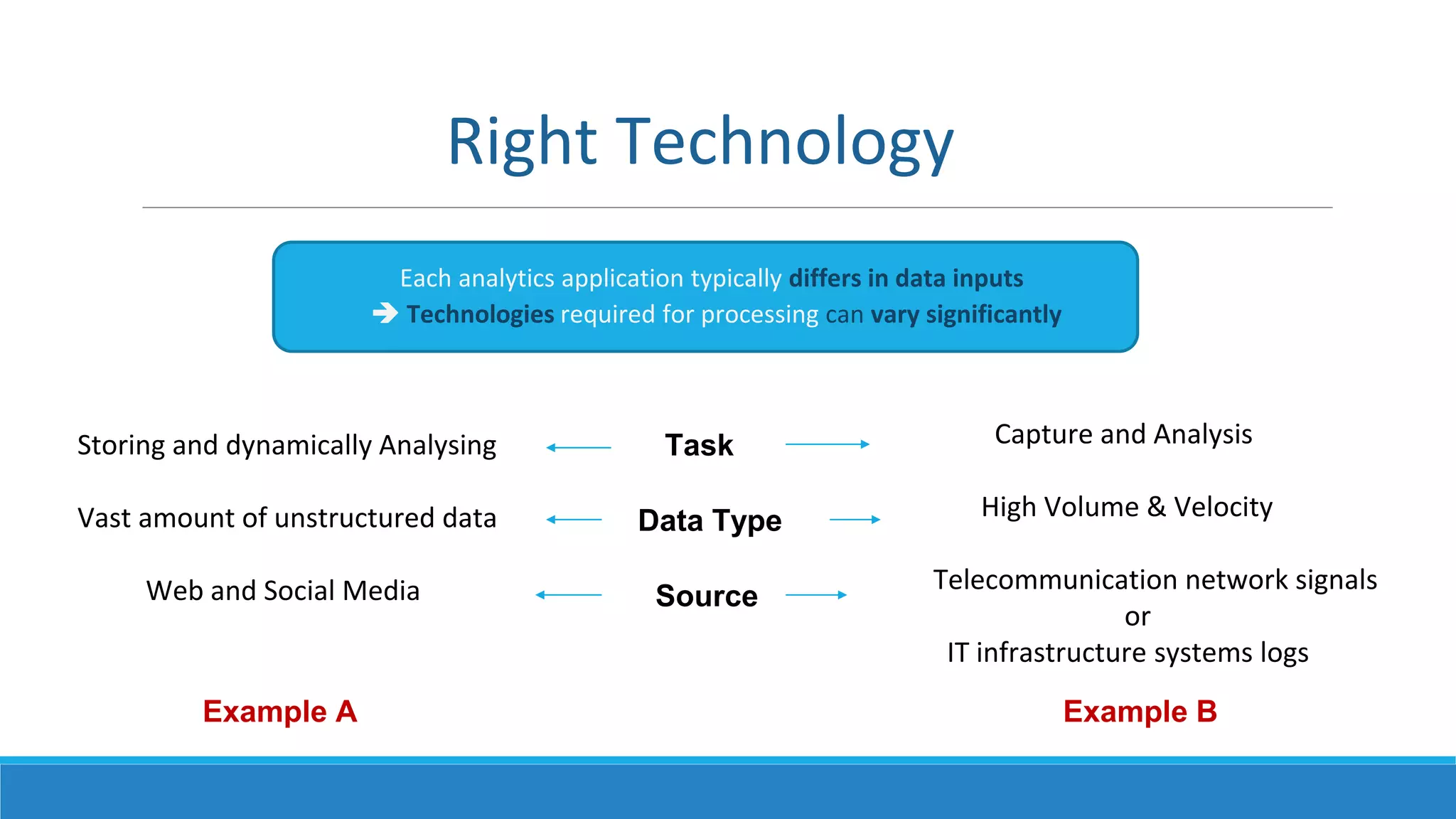
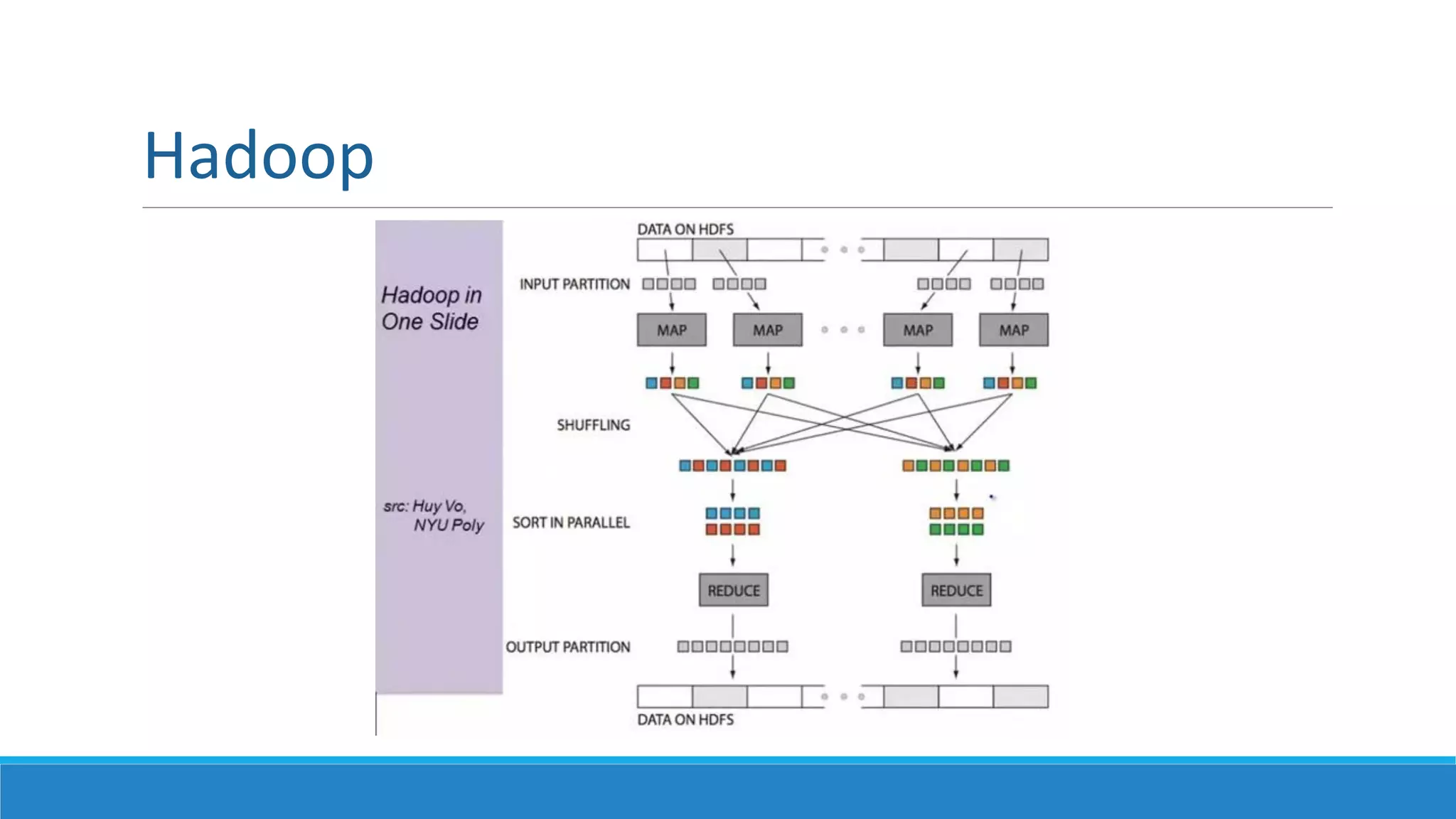
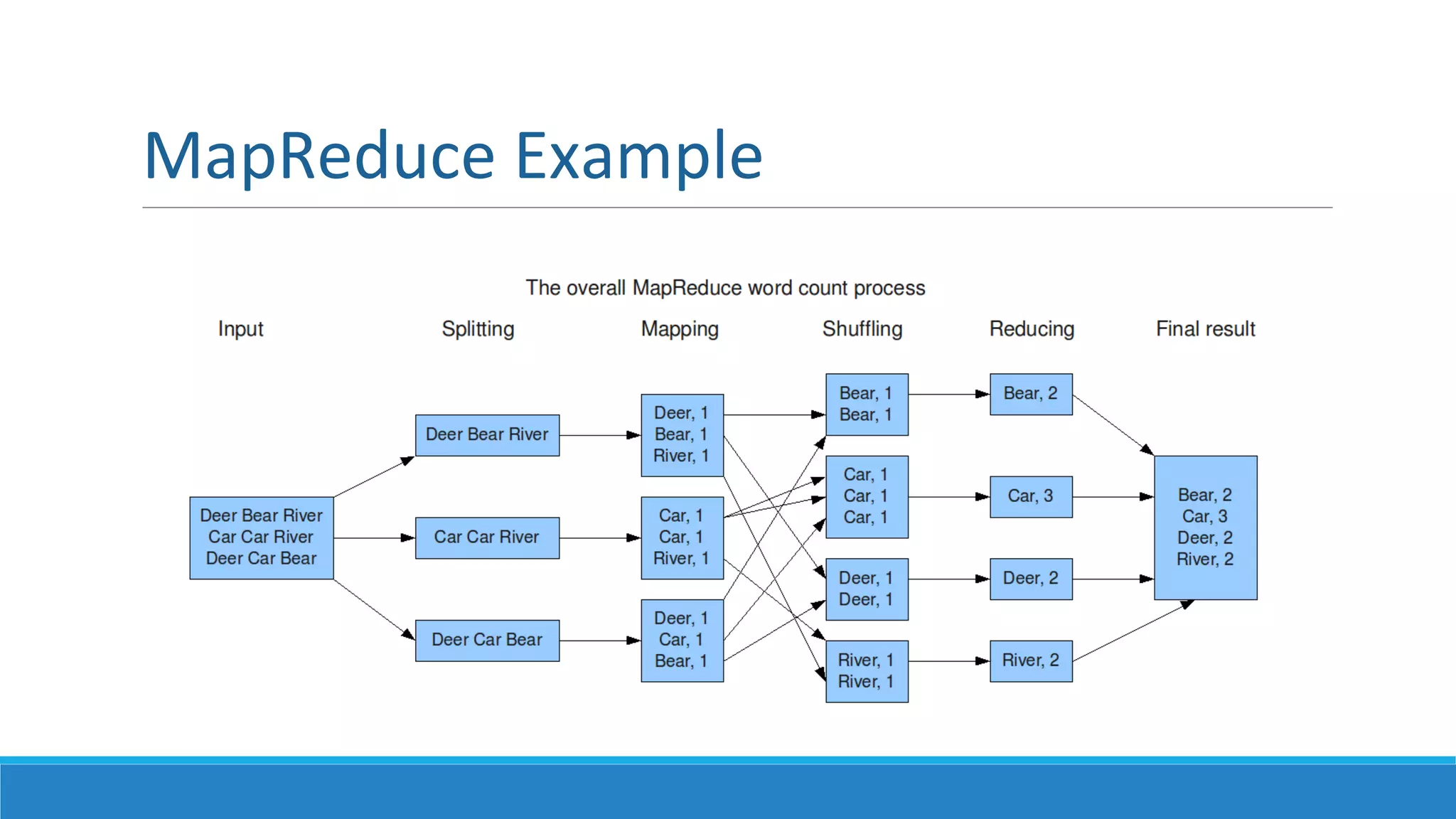
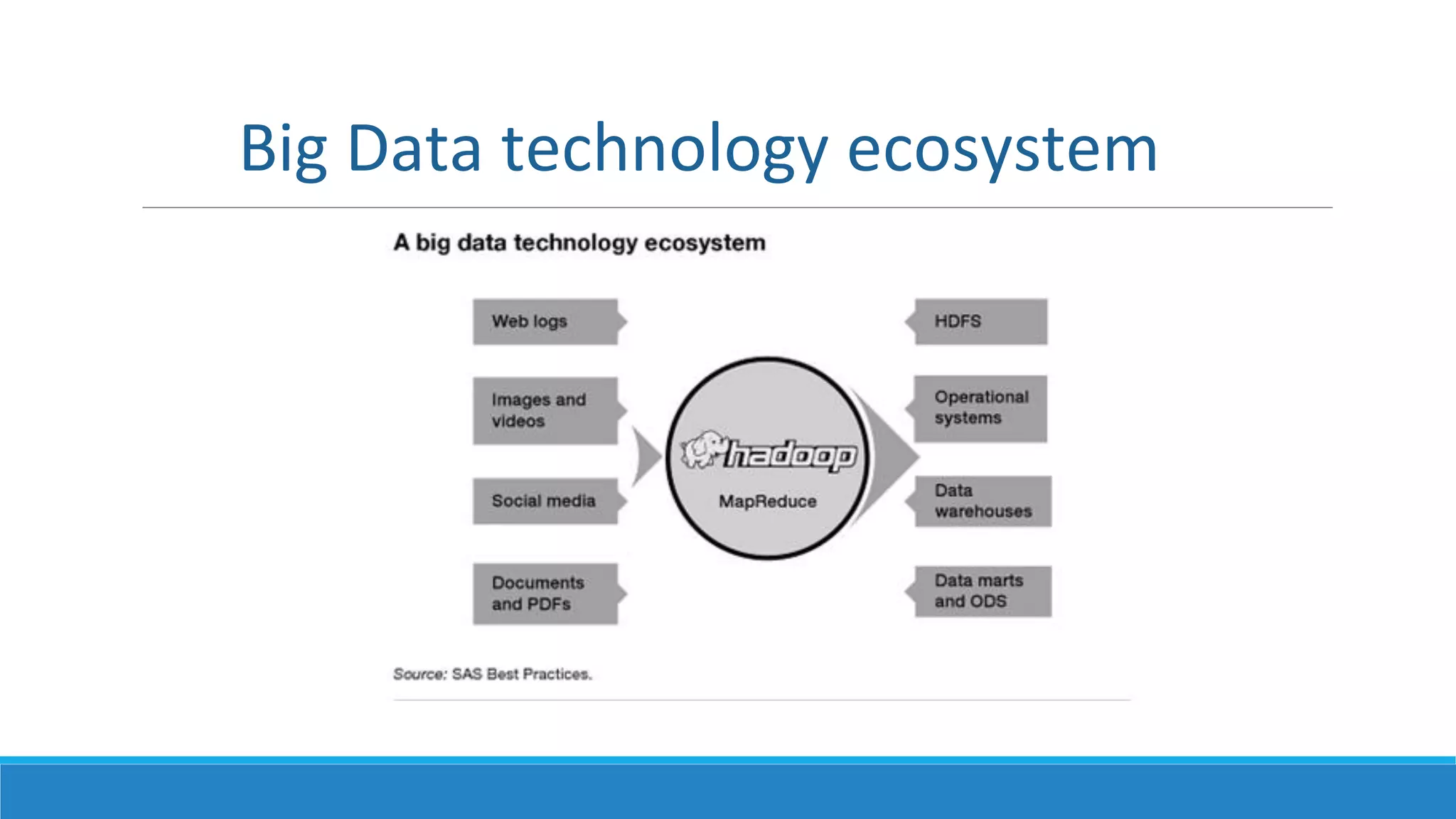
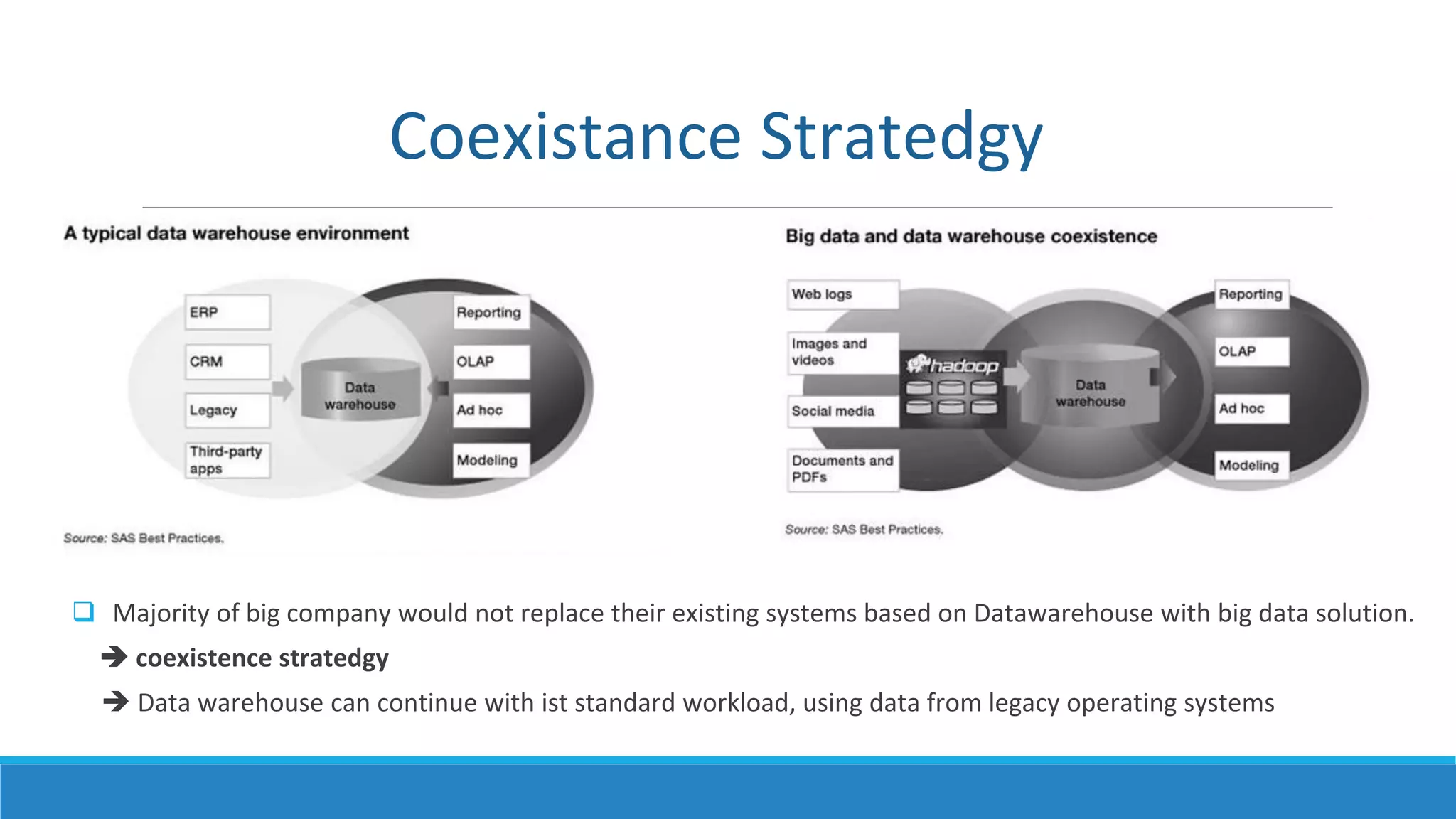
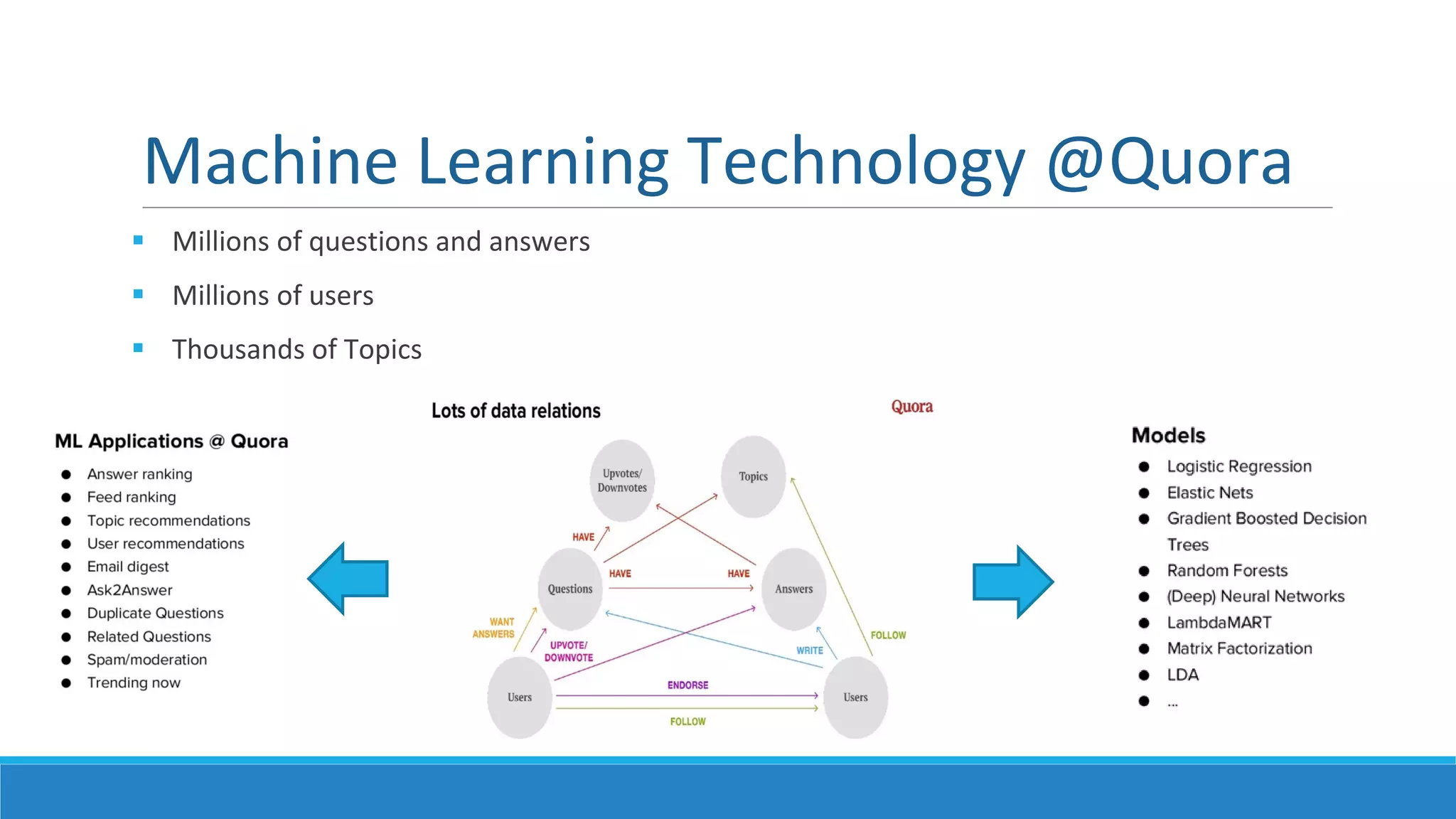
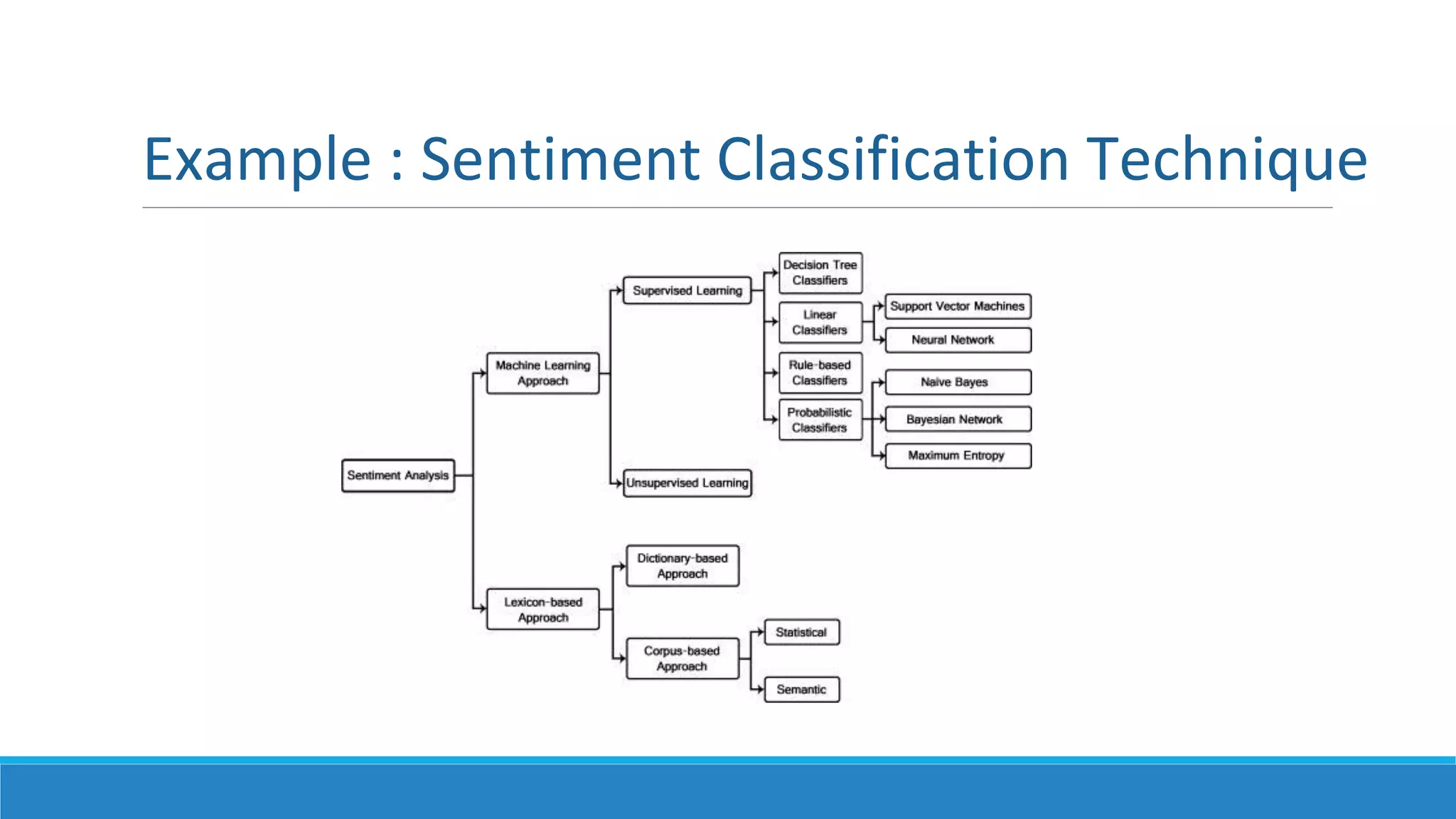
This document provides an overview of data science technology. It discusses big data technologies for storing, processing, and managing large amounts of data. It also covers machine learning technologies like supervised and unsupervised learning algorithms. Finally, it discusses visualization techniques for analyzing and communicating insights from big data, including tag clouds, clustergrams, and spatial information flows.