Downloaded 44 times














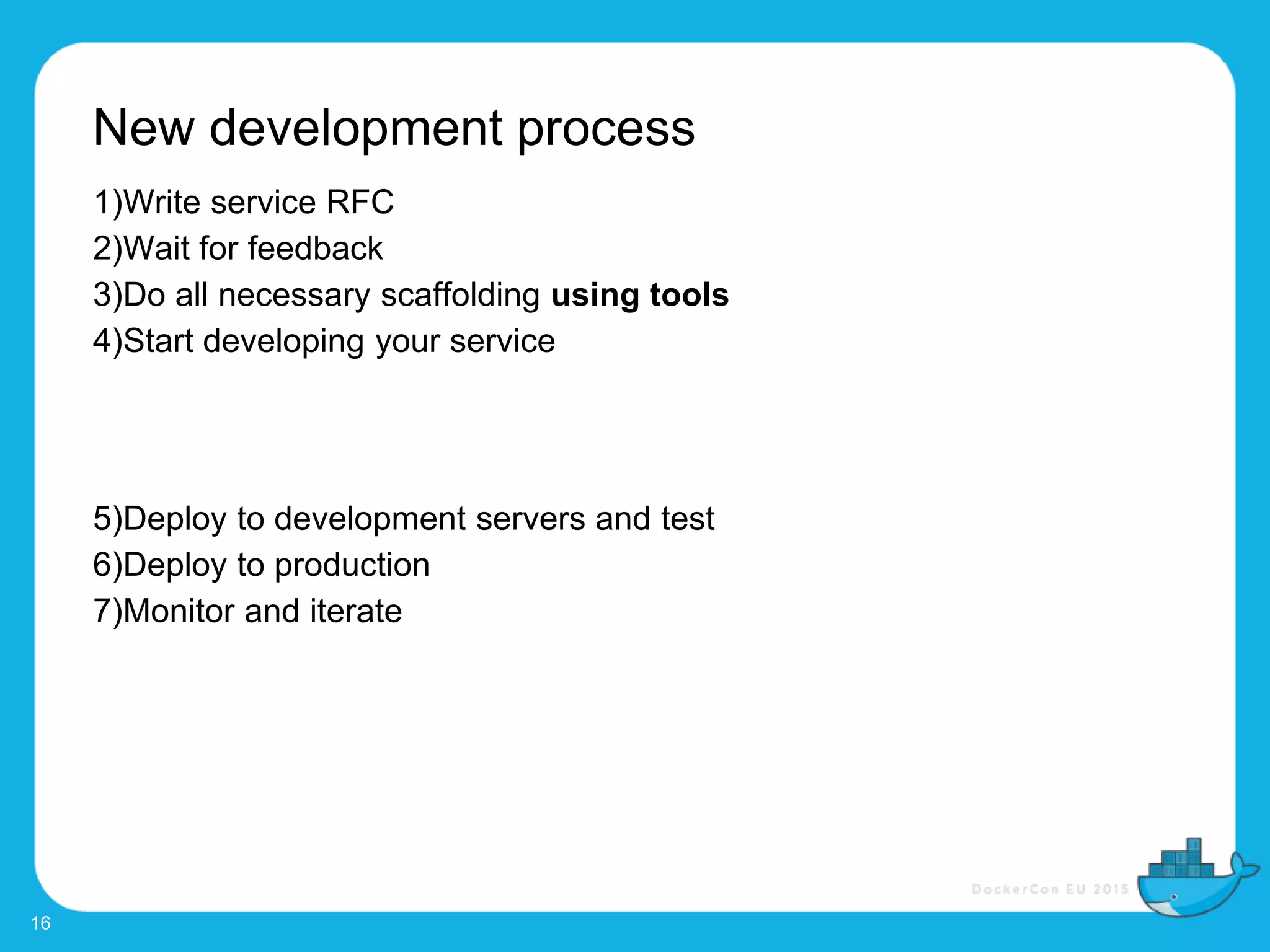





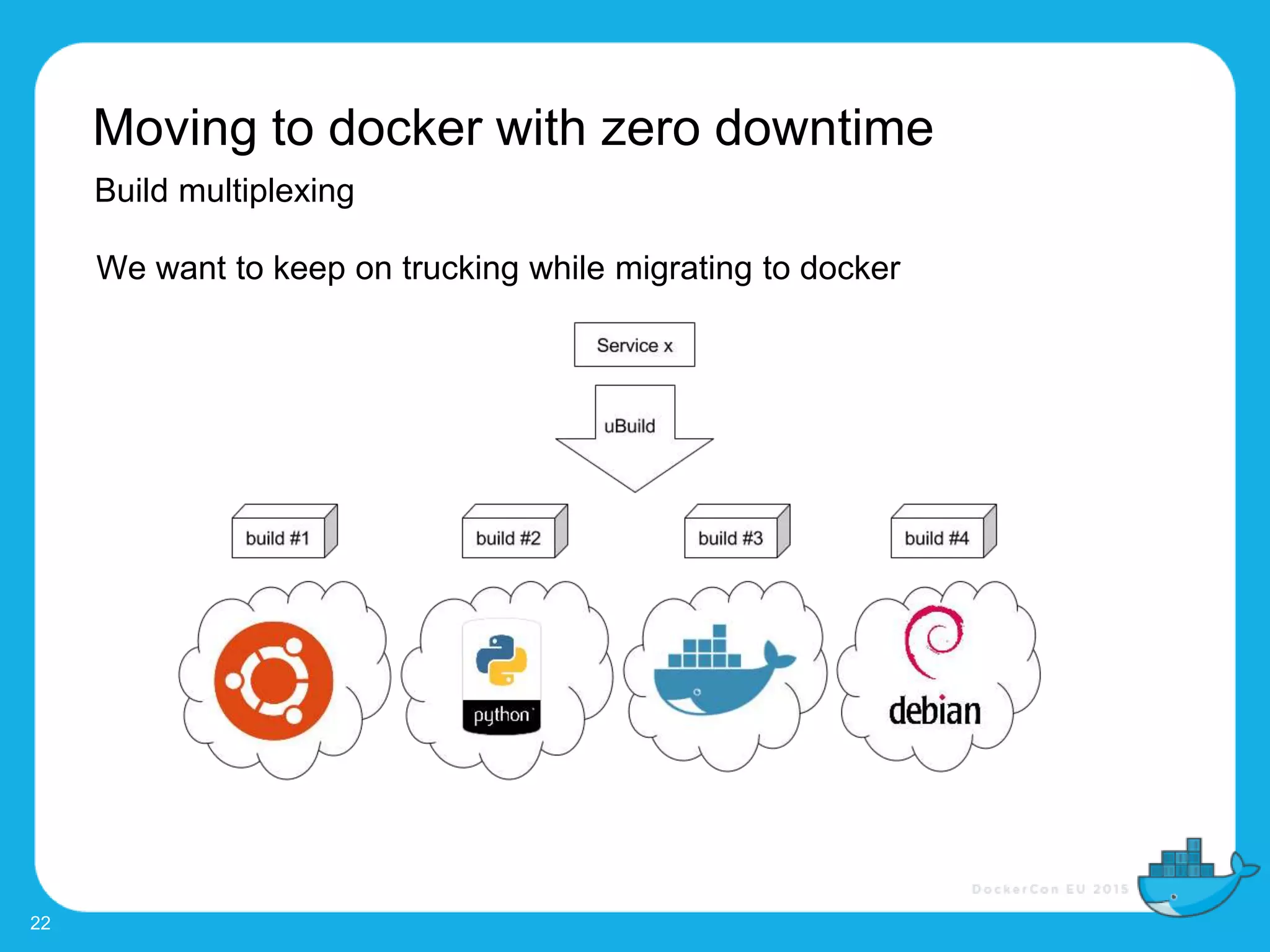








The document outlines the challenges and evolution of Uber's software development process, detailing the shift from a cumbersome and slow system to a more efficient model for service deployment and management. The migration to Docker has allowed for significant improvements in provisioning time, enabling greater freedom for developers and streamlined service management. Key features of the new development process include the ability to deploy services quickly, manage environments, and automate scaling, with a goal of transitioning all services to Docker.











































































































