Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
ARISE analytics
PPTX, PDF
804 views
【論文読み会】PiCO_Contrastive Label Disambiguation for Partial Label Learning.pptx
社内で行った「International Conference on Learning Represantation (ICLR)2022読み会」でまとめた資料です。
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 21
2
/ 21
3
/ 21
4
/ 21
5
/ 21
6
/ 21
7
/ 21
8
/ 21
9
/ 21
10
/ 21
11
/ 21
12
/ 21
13
/ 21
14
/ 21
15
/ 21
16
/ 21
17
/ 21
18
/ 21
19
/ 21
20
/ 21
21
/ 21
More Related Content
PDF
時系列予測にTransformerを使うのは有効か?
by
Fumihiko Takahashi
PDF
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
by
Deep Learning JP
PPTX
画像キャプションの自動生成
by
Yoshitaka Ushiku
PDF
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
PPTX
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
PDF
Kaggle Happywhaleコンペ優勝解法でのOptuna使用事例 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
PDF
アンサンブル木モデル解釈のためのモデル簡略化法
by
Satoshi Hara
PDF
Cosine Based Softmax による Metric Learning が上手くいく理由
by
tancoro
時系列予測にTransformerを使うのは有効か?
by
Fumihiko Takahashi
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
by
Deep Learning JP
画像キャプションの自動生成
by
Yoshitaka Ushiku
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
Kaggle Happywhaleコンペ優勝解法でのOptuna使用事例 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
アンサンブル木モデル解釈のためのモデル簡略化法
by
Satoshi Hara
Cosine Based Softmax による Metric Learning が上手くいく理由
by
tancoro
What's hot
PDF
ブースティング入門
by
Retrieva inc.
PDF
Graph Attention Network
by
Takahiro Kubo
PDF
SSII2022 [OS3-02] Federated Learningの基礎と応用
by
SSII
PDF
幾何と機械学習: A Short Intro
by
Ichigaku Takigawa
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PPTX
近年のHierarchical Vision Transformer
by
Yusuke Uchida
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PDF
[DL輪読会]Disentangling by Factorising
by
Deep Learning JP
PDF
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
PDF
ICML2021の連合学習の論文
by
Katsuya Ito
PDF
CF-FinML 金融時系列予測のための機械学習
by
Katsuya Ito
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
PDF
DSIRNLP#1 ランキング学習ことはじめ
by
sleepy_yoshi
PPTX
これからの Vision & Language ~ Acadexit した4つの理由
by
Yoshitaka Ushiku
PDF
Recent Advances on Transfer Learning and Related Topics Ver.2
by
Kota Matsui
PPTX
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
PDF
データに内在する構造をみるための埋め込み手法
by
Tatsuya Shirakawa
PPTX
差分プライバシーとは何か? (定義 & 解釈編)
by
Kentaro Minami
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
ブースティング入門
by
Retrieva inc.
Graph Attention Network
by
Takahiro Kubo
SSII2022 [OS3-02] Federated Learningの基礎と応用
by
SSII
幾何と機械学習: A Short Intro
by
Ichigaku Takigawa
Transformer メタサーベイ
by
cvpaper. challenge
近年のHierarchical Vision Transformer
by
Yusuke Uchida
機械学習モデルの判断根拠の説明
by
Satoshi Hara
[DL輪読会]Disentangling by Factorising
by
Deep Learning JP
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
ICML2021の連合学習の論文
by
Katsuya Ito
CF-FinML 金融時系列予測のための機械学習
by
Katsuya Ito
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
DSIRNLP#1 ランキング学習ことはじめ
by
sleepy_yoshi
これからの Vision & Language ~ Acadexit した4つの理由
by
Yoshitaka Ushiku
Recent Advances on Transfer Learning and Related Topics Ver.2
by
Kota Matsui
【DL輪読会】Flow Matching for Generative Modeling
by
Deep Learning JP
データに内在する構造をみるための埋め込み手法
by
Tatsuya Shirakawa
差分プライバシーとは何か? (定義 & 解釈編)
by
Kentaro Minami
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
More from ARISE analytics
PDF
ARISE analytics 会社紹介パンフレット ~2025年度版~ ご自由にダウンロードください。
by
ARISE analytics
PDF
AgentOps:AIエージェント時代の幕開けとガバナンスについて ~AgentOpsの体系的な理解を目指して~
by
ARISE analytics
PDF
【JSAI2024】学術論文の定量的評価と効果的な活用について Quantitative evaluation and effective utiliza...
by
ARISE analytics
PDF
【JSAI2024】J-NER大規模言語モデルのための固有表現認識における拡張固有表現階層を考慮したベンチマークデータセット.pdf
by
ARISE analytics
PDF
【JSAI2024】ブラックボックス大規模言語モデルにおけるHallucination検知手法の検討.pdf
by
ARISE analytics
PDF
【JSAI2024】LLMエージェントの人間との対話における反芻的返答の親近感向上効果_v1.1.pdf
by
ARISE analytics
PPTX
【第3回生成AIなんでもLT会資料】_動画生成AIと物理法則_v0.2.pptx
by
ARISE analytics
PPTX
【第3回】生成AIなんでもLT会 2024_0304なんでも生成AI_sergicalsix.pptx
by
ARISE analytics
PDF
めんどうな環境構築とはおさらば!Dockerの概要と使い方
by
ARISE analytics
PDF
【論文レベルで理解しよう!】 欠測値処理編
by
ARISE analytics
PDF
【論文レベルで理解しよう!】 大規模言語モデル(LLM)編
by
ARISE analytics
PDF
【論文読み会】Signing at Scale: Learning to Co-Articulate Signs for Large-Scale Pho...
by
ARISE analytics
PDF
Hierarchical Metadata-Aware Document Categorization under Weak Supervision (...
by
ARISE analytics
PDF
教師なしGNNによるIoTデバイスの異常通信検知の検討
by
ARISE analytics
PPTX
【論文読み会】Pyraformer_Low-Complexity Pyramidal Attention for Long-Range Time Seri...
by
ARISE analytics
PPTX
【論文読み会】Analytic-DPM_an Analytic Estimate of the Optimal Reverse Variance in D...
by
ARISE analytics
PPTX
【論文読み会】Autoregressive Diffusion Models.pptx
by
ARISE analytics
PPTX
【論文読み会】BEiT_BERT Pre-Training of Image Transformers.pptx
by
ARISE analytics
PPTX
【論文読み会】Deep Reinforcement Learning at the Edge of the Statistical Precipice
by
ARISE analytics
PPTX
【論文読み会】Alias-Free Generative Adversarial Networks(StyleGAN3)
by
ARISE analytics
ARISE analytics 会社紹介パンフレット ~2025年度版~ ご自由にダウンロードください。
by
ARISE analytics
AgentOps:AIエージェント時代の幕開けとガバナンスについて ~AgentOpsの体系的な理解を目指して~
by
ARISE analytics
【JSAI2024】学術論文の定量的評価と効果的な活用について Quantitative evaluation and effective utiliza...
by
ARISE analytics
【JSAI2024】J-NER大規模言語モデルのための固有表現認識における拡張固有表現階層を考慮したベンチマークデータセット.pdf
by
ARISE analytics
【JSAI2024】ブラックボックス大規模言語モデルにおけるHallucination検知手法の検討.pdf
by
ARISE analytics
【JSAI2024】LLMエージェントの人間との対話における反芻的返答の親近感向上効果_v1.1.pdf
by
ARISE analytics
【第3回生成AIなんでもLT会資料】_動画生成AIと物理法則_v0.2.pptx
by
ARISE analytics
【第3回】生成AIなんでもLT会 2024_0304なんでも生成AI_sergicalsix.pptx
by
ARISE analytics
めんどうな環境構築とはおさらば!Dockerの概要と使い方
by
ARISE analytics
【論文レベルで理解しよう!】 欠測値処理編
by
ARISE analytics
【論文レベルで理解しよう!】 大規模言語モデル(LLM)編
by
ARISE analytics
【論文読み会】Signing at Scale: Learning to Co-Articulate Signs for Large-Scale Pho...
by
ARISE analytics
Hierarchical Metadata-Aware Document Categorization under Weak Supervision (...
by
ARISE analytics
教師なしGNNによるIoTデバイスの異常通信検知の検討
by
ARISE analytics
【論文読み会】Pyraformer_Low-Complexity Pyramidal Attention for Long-Range Time Seri...
by
ARISE analytics
【論文読み会】Analytic-DPM_an Analytic Estimate of the Optimal Reverse Variance in D...
by
ARISE analytics
【論文読み会】Autoregressive Diffusion Models.pptx
by
ARISE analytics
【論文読み会】BEiT_BERT Pre-Training of Image Transformers.pptx
by
ARISE analytics
【論文読み会】Deep Reinforcement Learning at the Edge of the Statistical Precipice
by
ARISE analytics
【論文読み会】Alias-Free Generative Adversarial Networks(StyleGAN3)
by
ARISE analytics
【論文読み会】PiCO_Contrastive Label Disambiguation for Partial Label Learning.pptx
1.
PiCO: Contrastive Label Disambiguation
for Partial Label Learning ©2022 ARISE analytics Reserved. ARISE analytics 近藤 真暉
2.
発表文献 ©2022 ARISE analytics
Reserved. 1 【本発表の対象】 論文:https://arxiv.org/pdf/2201.08984v2.pdf 特に注釈のない画像は、上記からの引用です。 【補足資料】 PJページ:https://hbzju.github.io/pico/ スライド:https://iclr.cc/media/iclr-2022/Slides/6038.pdf 発表動画:https://iclr.cc/virtual/2022/poster/6038
3.
論文概要 ©2022 ARISE analytics
Reserved. 2 画像引用:https://dognoie.com/blog/dog-picturebook/alaskaanmalamute-siberianhusky/ シベリアンハスキー(左)とアラスカンマラミュート(右)が曖昧でもうまく分 離できる手法を提案 → ICLR 2022 Outstanding Paper Honorable Mentions(優 秀賞) 主な貢献 ① Partial Label Learning への対照学習の導入 ② Partial Label Learning における性能向上とより難しいタスクへの挑戦 ③ PiCOの理論的な解析
4.
Partial Label Learning(PLL:部分ラベル学習) ©2022
ARISE analytics Reserved. 3 複数のラベル候補(あいまいなラベル)を用いて行われる学習 GT∈ラベル候補Yi であることを前提とし、真のラベルを特定することが目的 アノテーションコストが低いため、応用が効きやすい ラベル候補Yi:Hasky/Malamute/Samoyed GT:Malamute Supervised Learning Partial Label Learning
5.
ラベルの曖昧さ問題の例 ©2022 ARISE analytics
Reserved. 4 画像引用:Learning from Partial Labels(JMLR 2011) 別目的からのアノテーション流用においてもラベルの曖昧さ問題は発生。修正 はコスト大 → PLL問題として解くことで、アノテーション流用を容易にしコストを下げる ことができる 字幕・キャプションを用いて人物ラベル付与し たい場合、 どちらのラベルを付与すればよいか?
6.
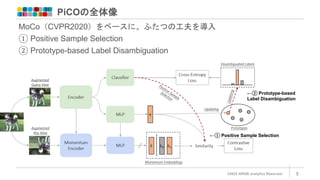
PiCOの全体像 ©2022 ARISE analytics
Reserved. 5 MoCo(CVPR2020)をベースに、ふたつの工夫を導入 ① Positive Sample Selection ② Prototype-based Label Disambiguation ←① Positive Sample Selection ←② Prototype-based Label Disambiguation
7.
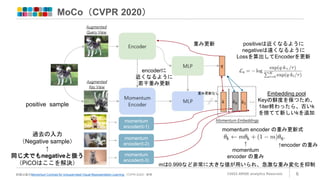
MoCo(CVPR 2020) ©2022 ARISE
analytics Reserved. 6 詳細は論文Momentum Contrast for Unsupervised Visual Representation Learning(CVPR 2020)参照 過去の入力 (Negative sample) ↑ 同じ犬でもnegativeと扱う (PiCOはここを解決) momentum encoder(t-1) momentum encoder(t-2) momentum encoder(t-3) positive sample Embedding pool Keyの鮮度を保つため、 1iter終わったら、古いk を捨てて新しいkを追加 positiveは近くなるように negativeは遠くなるように Lossを算出してEncoderを更新 重み更新 encoderに 近くなるように 若干重み更新 momentum encoder の重み更新式 ↑encoder の重み ↑ momentum encoder の重み mは0.999など非常に大きな値が用いられ、急激な重み変化を抑制 重み更新なし
8.
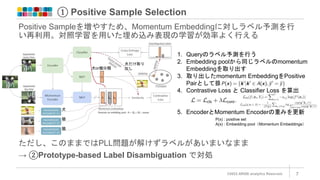
① Positive Sample
Selection ©2022 ARISE analytics Reserved. 7 Positive Sampleを増やすため、Momentum Embeddingに対しラベル予測を行 い再利用。対照学習を用いた埋め込み表現の学習が効率よく行える ただし、このままではPLL問題が解けずラベルがあいまいなまま → ②Prototype-based Label Disambiguation で対処 P(x) : positive set A(x) : Embedding pool(Momentum Embeddings) 1. Queryのラベル予測を行う 2. Embedding poolから同じラベルのmomentum Embeddingを取り出す 3. 取り出したmomentum EmbeddingをPositive Pairとして扱う 4. Contrastive Loss と Classifier Loss を算出 5. EncoderとMomentum Encoderの重みを更新 犬 猫 猫 犬だけ取り 出し 犬or猫分類
9.
② Prototype-based Label
Disambiguation ©2022 ARISE analytics Reserved. 8 一部、論文の図と発表スライドの図を組み合わせて加工 Prototype Embedding Vector を導入し、クラスタリングによってラベル割り当 て Prototype Embedding Vectorは都度更新されるため、Contrasitive Learningによ る埋め込み表現が反映される 1. Queryのラベル予測モデルの学習に用いる疑似ラ ベル(Disambiguated Labels)を一様分布で初期 化(※one-hotではなく連続値を用いる) 2. Queryの埋め込み特徴を取得 3. 最も近いPrototype Embeddig Vector u_jを探索 4. 移動平均法を用いてPrototype Embedding Vector u_jを更新 5. Prototype Embedding Vector u_j に対応するクラ スが大きくなるよう、それ以外は小さくなるよう に疑似ラベルを更新 ※Φは0~1の範囲で指定する疑似ラベルの更新量 を調整するためのモメンタム係数(超パラメ タ)
10.
2つの改良による効果 ©2022 ARISE analytics
Reserved. 9 一見関係なさそうな①②の改良 お互いにうまく協調して学習できる ①によるContrasitive Learningで埋め込み空間を学習 ↓ 埋め込み空間が適切に学習されることで、うまくクラスタリングできるように なる ↓ クラスタリング効果が発揮されると、②Prototype Embedding Vectorがきれい に収束 ↓ Prototype Embedding Vectorが適切に設定されると、①のPositive Sample Selectionで正しいサンプルを選択できる ↓ これを繰り返すことで、相互的に補完しあい学習プロセス全体が収束 PiCOは教師ありと教師なしクラスタリングのハイブリッド 学習初期は学習初期はラベル候補の信頼度が高い 学習が進むにつれてプロトタイプの信頼度が高くなる 移動平均方式で擬似ターゲットを更新することで、スムーズに 改善される
11.
PiCOの具体的な処理フロー ©2022 ARISE analytics
Reserved. 10 ミニバッチ取 得 ミニバッチからサンプル取得し、Augmentation →MLPを通し埋め込み特徴を取得 取得した埋め込み特徴とキュー(Embedding Pool)の埋め込み特徴をまと める ミニバッチから取得したサンプルに対し、queryと同じAugumentationを実施してからクラス分類(Bqと は別) クラス分類の結果に応じて、Prototype Embedding Vectorを移動平均法で更新 まとめた埋め込み特徴から同じクラスのものを取り出し、Positive Sampleとして扱う Prototype Embedding Vector からクエリに最も近いものを選択し、One-hot-vectorで表現 queryに対応する疑似ラベルを更新 : s_iの初期値は1/(ラベル数)で初期化された一様分布 Contrastive Lossを算出 Classfication Lossを算出 ふたつのLossをもとに、Encoderの重み を更新 移動平均法に基づき、Momentum Encoderの重みを更新 Momentum Encoderで取得した埋め込み特徴と分類結果をキューに追加し、古い埋め込み特徴を捨 てる
12.
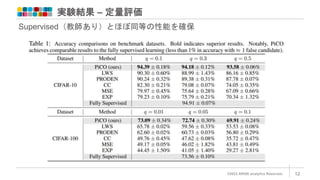
実験設定 ©2022 ARISE analytics
Reserved. 11 画像引用:CIFAR-10 and CIFAR-100 dataset CIFAR-10/100で評価 正しいラベル+ダミーのラベルをランダムに選択してラベル候補を構築(PLL 問題にする) 正しいラベル GT = Airplane ↓ ラベル候補Yi = [Airplane, Bird, Deer, Dog, Horse] ダミーのラベル数はPartial Rate qで決定 CIFAR-10 : q ∈ {0.1, 0.3, 0.5} CIFAR-100 : q ∈ {0.01, 0.05, 0.1}
13.
実験結果 – 定量評価 ©2022
ARISE analytics Reserved. 12 Supervised(教師あり)とほぼ同等の性能を確保
14.
実験結果 – 定性評価 ©2022
ARISE analytics Reserved. 13 t-SNEで可視化。(a)Uniform featuresは一様分布で初期化された疑似ラベルを 用いたものであり、うまく分離できていない。先行研究で最も良かった (b)PRODEN featuresではdog-cat-frogやairplane-shipが混ざっている。(c)PiCO featuresはきれいに分離されている。高品質な埋め込み表現を学習できている ことを示す
15.
実験結果 – 改良効果分析 ©2022
ARISE analytics Reserved. 14 今回の改良のうち、どの改良が寄与したかを分析 ②Prototype-based Label Disambiguation の工夫よりも、① Positive Sample Selection(対照学習 L_cont)の有無が性能向上に寄与 モメンタム係数Φ=0のときの②疑似ラベル更新については、Softmaxによるク ラス確率またはOne-hotで更新したほうが効果的・モメンタム係数は0.9が良い
16.
実験結果 – より難しい問題設定では? ©2022
ARISE analytics Reserved. 15 画像引用:Fine-grained Visual-textual Representation Learning(CVPR2020), CIFAR-10 and CIFAR-100 dataset CUB-200/CIFAR-100-Hでも実験 他手法と比べ最も良い性能が得られることを確認 CUB-200:200種類の鳥画像 CIFAR-100-H :CIFAR-100と同じだが、同じ superclassだけで部分ラベルを構築
17.
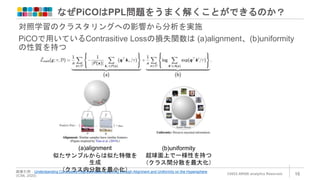
なぜPiCOはPPL問題をうまく解くことができるのか? ©2022 ARISE analytics
Reserved. 16 画像引用:Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere (ICML 2020) 対照学習のクラスタリングへの影響から分析を実施 PiCOで用いているContrasitive Lossの損失関数は (a)alignment、(b)uniformity の性質を持つ (a)alignment 似たサンプルからは似た特徴を 生成 (クラス内分散を最小化) (b)uniformity 超球面上で一様性を持つ (クラス間分散を最大化)
18.
なぜPiCOはPPL問題をうまく解くことができるのか? ©2022 ARISE analytics
Reserved. 17 (a)alignment に注目して解析した結果、 「(a)を最小化すると、式(10)の尤度の下限も最大化する」という定理を発見(証 明省略) 式(10)の尤度の下限が最大化されると、クラス内密度が高くなる(平均ベクト ルのノルムが小さくなる)効果がある → PiCOはコンパクトかつ良い表現を獲得 できる ノルム大きい (密度薄い) ノルム小さい (密度高い)
19.
まとめ ©2022 ARISE analytics
Reserved. 18 画像引用:Learning from Partial Labels(JMLR 2011) PiCOの主な貢献 ① Partial Label Learning への対照学習の導入 ② Partial Label Learning における性能向上とより難しいタスクへの挑戦 ③ PiCOの理論的な解析 → 教師あり学習と同等の性能を達成 他タスクのアノテーション流用によるモデルの高精度化が期待できるように
20.
参考文献 ©2022 ARISE analytics
Reserved. 19 【本発表の対象】 論文:https://arxiv.org/pdf/2201.08984v2.pdf 【補足資料】 PJページ:https://hbzju.github.io/pico/ スライド:https://iclr.cc/media/iclr-2022/Slides/6038.pdf 発表動画:https://iclr.cc/virtual/2022/poster/6038 【その他参考文献】 Learning from Partial Labels(JMLR 2011) Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere (ICML 2020) Fine-grained Visual-textual Representation Learning(CVPR2020) Momentum Contrast for Unsupervised Visual Representation Learning(CVPR 2020) A Simple Framework for Contrastive Learning of Visual Representations(ICML 2020) Advancing Self-Supervised and Semi-Supervised Learning with SimCLR [CVPR2020読み会@オンライン(前編)]Momentum Contrast for Unsupervised Visual Representation Learning CIFAR-10 and CIFAR-100 dataset
21.
Best Partner for
innovation, Best Creator for the future.
Download








![実験設定
©2022 ARISE analytics Reserved. 11
画像引用:CIFAR-10 and CIFAR-100 dataset
CIFAR-10/100で評価
正しいラベル+ダミーのラベルをランダムに選択してラベル候補を構築(PLL
問題にする)
正しいラベル GT = Airplane
↓
ラベル候補Yi = [Airplane, Bird, Deer, Dog, Horse]
ダミーのラベル数はPartial Rate qで決定
CIFAR-10 : q ∈ {0.1, 0.3, 0.5}
CIFAR-100 : q ∈ {0.01, 0.05, 0.1}](https://image.slidesharecdn.com/picocontrastivelabeldisambiguationforpartiallabellearning-221031053104-55da8a83/85/PiCO_Contrastive-Label-Disambiguation-for-Partial-Label-Learning-pptx-12-320.jpg)




![参考文献
©2022 ARISE analytics Reserved. 19
【本発表の対象】
論文:https://arxiv.org/pdf/2201.08984v2.pdf
【補足資料】
PJページ:https://hbzju.github.io/pico/
スライド:https://iclr.cc/media/iclr-2022/Slides/6038.pdf
発表動画:https://iclr.cc/virtual/2022/poster/6038
【その他参考文献】
Learning from Partial Labels(JMLR 2011)
Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere (ICML 2020)
Fine-grained Visual-textual Representation Learning(CVPR2020)
Momentum Contrast for Unsupervised Visual Representation Learning(CVPR 2020)
A Simple Framework for Contrastive Learning of Visual Representations(ICML 2020)
Advancing Self-Supervised and Semi-Supervised Learning with SimCLR
[CVPR2020読み会@オンライン(前編)]Momentum Contrast for Unsupervised Visual Representation Learning
CIFAR-10 and CIFAR-100 dataset](https://image.slidesharecdn.com/picocontrastivelabeldisambiguationforpartiallabellearning-221031053104-55da8a83/85/PiCO_Contrastive-Label-Disambiguation-for-Partial-Label-Learning-pptx-20-320.jpg)



![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Disentangling by Factorising](https://cdn.slidesharecdn.com/ss_thumbnails/20180720disentanglingbyfactorising-180720000930-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)



























