More Related Content

PDF
【論文レベルで理解しよう!】 大規模言語モデル(LLM)編 
PDF
Crypto民のためのAI Agent入門 - Solana Developer Hub 13 #SolDevHub 
PDF
生成AIとビジネス戦略 正しく恐れ正しく活用するために 東海国立大学機構技術発表会 & 岐阜地域産学官連携交流会 2025 講演資料 
PPTX
【DL輪読会】Toolformer: Language Models Can Teach Themselves to Use Tools 
PDF
Wandb LLM Webinar May 30 2023 (配布用).pdf 
PDF

PDF
AIで始めるRustプログラミング #SolDevHub 
PDF
個人または組織における仕事の成果につながる生成AI(主にChatGPT)入門講座 Similar to 【第3回】生成AIなんでもLT会 2024_0304なんでも生成AI_sergicalsix.pptx

PDF
LLM/生成AI&エージェントによるソフトウェア開発の実践と展望(SES2025チュートリアル) 
PDF
論文紹介:"Reflexion: language agents with verbal reinforcement learning", "MA-LMM... 
PDF

PDF

PDF

PPTX
生成AI・LLMシステムのセキュリティ:生成AI・LLMのAI倫理と機械学習システムセキュリティセッション 
PDF

PDF
Chainer with natural language processing hands on 
PDF
はじめての生成AIローカルLLM、llama.cppとllamafile。練習演習あり初心者向け講座 More from ARISE analytics

PDF
ARISE analytics 会社紹介パンフレット ~2025年度版~ ご自由にダウンロードください。 
PDF
AgentOps:AIエージェント時代の幕開けとガバナンスについて ~AgentOpsの体系的な理解を目指して~ 
PDF
【JSAI2024】学術論文の定量的評価と効果的な活用について Quantitative evaluation and effective utiliza... 
PDF
【JSAI2024】J-NER大規模言語モデルのための固有表現認識における拡張固有表現階層を考慮したベンチマークデータセット.pdf 
PDF
【JSAI2024】ブラックボックス大規模言語モデルにおけるHallucination検知手法の検討.pdf 
PDF
【JSAI2024】LLMエージェントの人間との対話における反芻的返答の親近感向上効果_v1.1.pdf 
PPTX
【第3回生成AIなんでもLT会資料】_動画生成AIと物理法則_v0.2.pptx 
PDF
めんどうな環境構築とはおさらば!Dockerの概要と使い方 
PDF

PDF
【論文読み会】Signing at Scale: Learning to Co-Articulate Signs for Large-Scale Pho... 
PDF
Hierarchical Metadata-Aware Document Categorization under Weak Supervision (... 
PDF
教師なしGNNによるIoTデバイスの異常通信検知の検討 
PPTX
【論文読み会】Pyraformer_Low-Complexity Pyramidal Attention for Long-Range Time Seri... 
PPTX
【論文読み会】Analytic-DPM_an Analytic Estimate of the Optimal Reverse Variance in D... 
PPTX
【論文読み会】Autoregressive Diffusion Models.pptx 
PPTX
【論文読み会】BEiT_BERT Pre-Training of Image Transformers.pptx 
PPTX
【論文読み会】PiCO_Contrastive Label Disambiguation for Partial Label Learning.pptx 
PPTX
【論文読み会】Deep Reinforcement Learning at the Edge of the Statistical Precipice 
PPTX
【論文読み会】Alias-Free Generative Adversarial Networks(StyleGAN3) 
PPTX
【論文読み会】On the Expressivity of Markov Reward 【第3回】生成AIなんでもLT会 2024_0304なんでも生成AI_sergicalsix.pptx
- 1.
- 2.
自己紹介
©2023 ARISE analyticsReserved. 1
sergicalsix
バックエンド開発&インフラ構築
発信
A R I S E a n a l y t i c s
note
生成AI系(本LT内容の詳細を展開)
Qiita
プログラム全般
Zenn
プログラムテクニック系
業務
バックグラウンド
修士:ニューラルネットワークの研究
- 3.
- 4.
- 5.
LLMとは
©2023 ARISE analyticsReserved. 4
*:厳密にはトークン
LLM(Large Language Model)とは、言語を単語*の確率として扱う大規模言語モデルである。LLMはモデルのパラ
メータ数の大幅な増加により性能が飛躍的に向上したことで、既存のPLM(Pre-trained Language Model)と区別す
る形で命名された。
LLM
PLM
ex. GPT-2 ex. GPT-3
1.5 B (15 億) パラメータ
数
175 B (1,750 億)
大規模化
言語モデル
言語を単語*の確率としてモデル化
言語モデ
ル
私の好きなスポーツ
は
サッカー(50 %)
野球(25 %)
バスケットボール
(15 %)
テニス(10 %)
- 6.
LLMのファインチューニング
©2023 ARISE analyticsReserved. 5
[1]:https://note.com/bbz662bbz/n/nb2f68451a2f0
[2]:https://qiita.com/takaaki_inada/items/9a9c07e85e46ec0e872e
LLMのカスタマイズ方法の一つにファインチューニングがある。ファインチューニングとは、事前学習済
みモデルに追加学習を行うことで、モデルの重みを微調整することである。ファインチューニングでは出
力の形式(例:口調)の変更などが可能である。
学習データ
LLMのファインチューニ
ング
事前学習済みLLM ファインチューニング済
みLLM
ファインチューニングでは、事前学習済みモデルに
対して追加学習を行い、LLMの重みの微調整を行う
モデル出力を任意の口調に調整
語尾をござる化[1]
ずんだもん化[2]
モデル出力を任意の構造化データ(ex. csv)に
調整
チャットの改善(ex. Vicuna: 会話履歴を学習
することで性能改善)
など
LLMのファインチューニングででき
ること
- 7.
LLMのファインチューニングの未解明事項及び本LT実施
内容
©2023 ARISE analyticsReserved. 6
LLMのファインチューニングにおいて情報がモデルのどの層に保存されているかは厳密には判明していな
い。実装コスト観点と面白さ(主観)からLLMの口調の学習で実験を行う。
「学習で獲得した口調などの情報が、どの層に保存されてい
るか」
「どの層に口調などの情報を保存できるか」
など
LLMのファインチューニングにおいて判明して
いないこと
本LT実験項目選定
チャットの改善
面白さ(主観)
モデル出力を
任意の口調に調整
モデル出力を任意の
構造化データに調整
コスト
項目
〇
〇
×
〇
△
〇
本LTの目的:層に着目したLLMの口調の学習の調査
- 8.
- 9.
手法サマリー
©2023 ARISE analyticsReserved. 8
[3]:https://huggingface.co/rinna/japanese-gpt-neox-3.6b, 詳細な引用は末尾
[4]:https://huggingface.co/datasets/bbz662bbz/databricks-dolly-15k-ja-gozaru, 詳細な引用は末尾
rinna社の3.6 BのLLMモデル[3]
日本語のdollyデータセットの語尾が「ござ
る」となっているデータセット[4]
事前学習モデル ファインチューニング用の口調データセット
学習 評価
学習対象の層を変えて学習
評価指標: ござる率
文中に「ござる」が含まれている出力の
割合
学習方法 ござる率
方法1 ??
方法2 ??
方法N ??
・
・
・
・
・
・
学習対象
学習対象でな
い
訓練に用いてい
ない検証用デー
タ
- 10.
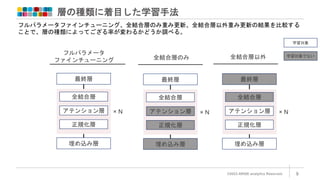
層の種類に着目した学習手法
©2023 ARISE analyticsReserved. 9
フルパラメータ
ファインチューニング
埋め込み層
最終層
全結合層
正規化層
アテンション層 × N
全結合層のみ
埋め込み層
最終層
全結合層
正規化層
アテンション層 × N
学習対象
学習対象でない
全結合層以外
埋め込み層
最終層
全結合層
正規化層
アテンション層 × N
フルパラメータファインチューニング、全結合層のみ重み更新、全結合層以外重み更新の結果を比較する
ことで、層の種類によってござる率が変わるかどうか調べる。
- 11.
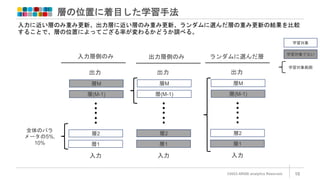
層の位置に着目した学習手法
©2023 ARISE analyticsReserved. 10
入力層側のみ
学習対象
学習対象でない
出力層側のみ
入力に近い層のみ重み更新、出力層に近い層のみ重み更新、ランダムに選んだ層の重み更新の結果を比較
することで、層の位置によってござる率が変わるかどうか調べる。
ランダムに選んだ層
入力
出力
層1
層2
層M
層(M-1)
入力
出力
層1
層2
層M
層(M-1)
全体のパラ
メータの5%,
10%
入力
出力
層1
層2
層M
層(M-1)
学習対象範囲
- 12.
- 13.
層の種類による結果の比較
©2023 ARISE analyticsReserved. 12
ござる率
学習方法
フルパラメータ
全結合層のみ
入力層側のみ
全結合層以外
重み更新率
入力層側のみ
出力層側のみ
出力層側のみ
ランダム(N=3)
ランダム(N=3)
1.00
0.65
0.35
0.05
0.05
0.05
0.10
0.10
0.10
0.87
0.95
0.92
0.74
0.88
0.83
0.93
0.90
0.86
観点
-
種類
種類
位置
位置
位置
位置
位置
位置
全結合層のみの重み更新と全結合層
以外の重み更新のござる率が、フル
パラメータチューニングと同等以上
である
→ 口調の獲得と層の種類(全結合層を
訓練するかどうか)に依存関係がない
可能性が示唆された
→「口調をござる」に変えるだけな
ら、フルパラメータチューニングの
必要はない*
*:汎化性能の低下・破壊的忘却については考慮外
- 14.
層の位置による結果の比較
©2023 ARISE analyticsReserved. 13
重みの更新率が0.10において時点で
は、学習対象の層の位置を変えた場
合でもフルパラメータチューニング
とほぼ同等のござる率であった
→ (重みの更新率が0.10の場合)、口調
の獲得と層の位置に依存関係はない
可能性が示唆された
→「口調をござる」に変えるだけな
ら、フルパラメータチューニングの
必要はない*(重みの更新量を1/10以上
抑えられる)
*:汎化性能の低下・破壊的忘却については考慮外
ござる率
学習方法
フルパラメータ
全結合層のみ
入力層側のみ
全結合層以外
重み更新率
入力層側のみ
出力層側のみ
出力層側のみ
ランダム(N=3)
ランダム(N=3)
1.00
0.65
0.35
0.05
0.05
0.05
0.10
0.10
0.10
0.87
0.95
0.92
0.74
0.88
0.83
0.93
0.90
0.86
観点
-
種類
種類
位置
位置
位置
位置
位置
位置
- 15.
- 16.
まとめ
©2023 ARISE analyticsReserved. 15
上記結果の他モデルや他タスクへの拡張するためには、詳細な実験・検証が必要である。
学習対象
学習対象でな
い
口調の獲得と層の種類(全結合層を訓練す
るかどうか)や位置に依存関係はない可能
性が示唆された
「口調をござる」に変えるだけなら、フ
ルパラメータチューニングの必要はない
[3]:https://huggingface.co/rinna/japanese-gpt-neox-3.6b, 詳細な引用は末尾
[4]:https://huggingface.co/datasets/bbz662bbz/databricks-dolly-15k-ja-gozaru, 詳細な引用は末尾
rinna社の3.6 BのLLMモデル[3]
日本語のdollyデータセットの語尾
が「ござる」となっているデータ
セット[4]
手法 結果
目的:層に着目したLLMの口調の学習の調査
- 17.
今後の展望
©2023 ARISE analyticsReserved. 16
汎化性能の調査
ファインチューニングのバリエーション追
加
[5]:https://huggingface.co/docs/peft/main/en/conceptual_guides/lora
LoRAの概念図[5]
- 18.
- 19.
引用
©2023 ARISE analyticsReserved. 18
- モデル:rinna/japanese-gpt-neox-3.6b
- 作成者: rinna株式会社
- ライセンス:MIT
- ライセンスリンク: こちら
- データセット: bbz662bbz/databricks-
dolly-15k-ja-gozaru
- bbz662bbz(HuggingFaceアカウント名)
- 最終更新日:2023年5月29日
- ライセンス: CC BY-SA 3.0
- ライセンスリンク: こちら
Editor's Notes
- #7 LLMのカスタマイズ方法の一つにファインチューニングがある。






![LLMのファインチューニング
©2023 ARISE analytics Reserved. 5
[1]:https://note.com/bbz662bbz/n/nb2f68451a2f0
[2]:https://qiita.com/takaaki_inada/items/9a9c07e85e46ec0e872e
LLMのカスタマイズ方法の一つにファインチューニングがある。ファインチューニングとは、事前学習済
みモデルに追加学習を行うことで、モデルの重みを微調整することである。ファインチューニングでは出
力の形式(例:口調)の変更などが可能である。
学習データ
LLMのファインチューニ
ング
事前学習済みLLM ファインチューニング済
みLLM
ファインチューニングでは、事前学習済みモデルに
対して追加学習を行い、LLMの重みの微調整を行う
モデル出力を任意の口調に調整
語尾をござる化[1]
ずんだもん化[2]
モデル出力を任意の構造化データ(ex. csv)に
調整
チャットの改善(ex. Vicuna: 会話履歴を学習
することで性能改善)
など
LLMのファインチューニングででき
ること](https://image.slidesharecdn.com/20240304aisergicalsix-240308012956-20783cc9/85/3-AI-LT-2024_0304-AI_sergicalsix-pptx-6-320.jpg)


![手法サマリー
©2023 ARISE analytics Reserved. 8
[3]:https://huggingface.co/rinna/japanese-gpt-neox-3.6b, 詳細な引用は末尾
[4]:https://huggingface.co/datasets/bbz662bbz/databricks-dolly-15k-ja-gozaru, 詳細な引用は末尾
rinna社の3.6 BのLLMモデル[3]
日本語のdollyデータセットの語尾が「ござ
る」となっているデータセット[4]
事前学習モデル ファインチューニング用の口調データセット
学習 評価
学習対象の層を変えて学習
評価指標: ござる率
文中に「ござる」が含まれている出力の
割合
学習方法 ござる率
方法1 ??
方法2 ??
方法N ??
・
・
・
・
・
・
学習対象
学習対象でな
い
訓練に用いてい
ない検証用デー
タ](https://image.slidesharecdn.com/20240304aisergicalsix-240308012956-20783cc9/85/3-AI-LT-2024_0304-AI_sergicalsix-pptx-9-320.jpg)




![まとめ
©2023 ARISE analytics Reserved. 15
上記結果の他モデルや他タスクへの拡張するためには、詳細な実験・検証が必要である。
学習対象
学習対象でな
い
口調の獲得と層の種類(全結合層を訓練す
るかどうか)や位置に依存関係はない可能
性が示唆された
「口調をござる」に変えるだけなら、フ
ルパラメータチューニングの必要はない
[3]:https://huggingface.co/rinna/japanese-gpt-neox-3.6b, 詳細な引用は末尾
[4]:https://huggingface.co/datasets/bbz662bbz/databricks-dolly-15k-ja-gozaru, 詳細な引用は末尾
rinna社の3.6 BのLLMモデル[3]
日本語のdollyデータセットの語尾
が「ござる」となっているデータ
セット[4]
手法 結果
目的:層に着目したLLMの口調の学習の調査](https://image.slidesharecdn.com/20240304aisergicalsix-240308012956-20783cc9/85/3-AI-LT-2024_0304-AI_sergicalsix-pptx-16-320.jpg)
![今後の展望
©2023 ARISE analytics Reserved. 16
汎化性能の調査
ファインチューニングのバリエーション追
加
[5]:https://huggingface.co/docs/peft/main/en/conceptual_guides/lora
LoRAの概念図[5]](https://image.slidesharecdn.com/20240304aisergicalsix-240308012956-20783cc9/85/3-AI-LT-2024_0304-AI_sergicalsix-pptx-17-320.jpg)

