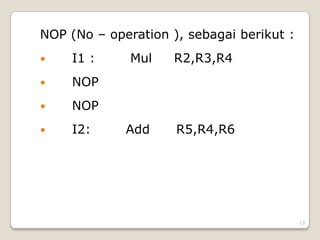
Dokumen tersebut membahas tentang konsep pipelining pada prosesor komputer. Pipelining digunakan untuk melakukan beberapa tahap pengolahan instruksi secara bersamaan dengan mengalirkannya ke berbagai stage secara berkelanjutan untuk meningkatkan throughput meskipun waktu penyelesaian setiap instruksi tetap sama. Hal ini menimbulkan tantangan seperti data hazard dan instruction hazard yang dapat ditangani dengan teknik seperti forwarding, branch prediction, dan