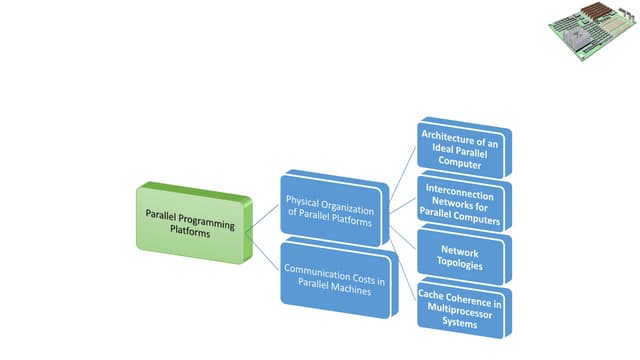
This document provides an overview of parallel and distributed computing concepts including Flynn's taxonomy, shared memory organization, message passing organization, and interconnection networks. Flynn's taxonomy classifies computer architectures into four categories based on their instruction and data streams: SISD, SIMD, MISD, and MIMD. Shared memory systems can be UMA, NUMA, or COMA based on memory access uniformity. Message passing systems use send/receive operations for communication between nodes with local memory. Interconnection networks are discussed in terms of their mode of operation, control strategy, switching technique, and topology for connecting processors in shared and message passing systems.