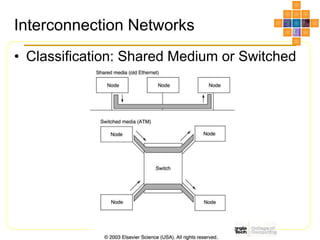
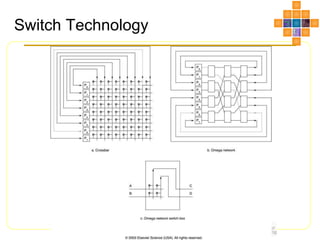
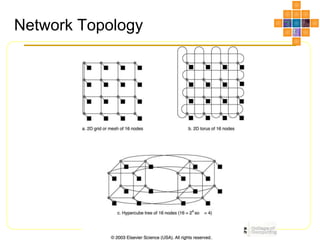
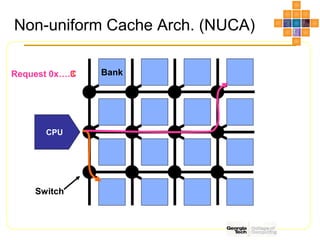
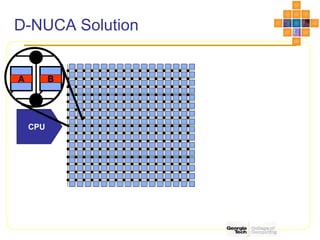
This document discusses interconnect networks for many-core processors. It describes shared and switched network topologies, including different arbitration, routing, and switching techniques. Key points covered include distributed arbitration for shared networks, routing methods like source-based and destination-based, and switch technologies like crossbars and Omega networks. Network performance factors like latency, bandwidth, and contention are also summarized. Cache coherence issues for on-chip networks are briefly discussed, along with solutions like non-uniform cache architectures and directory-based caching.