Download as PDF, PPTX



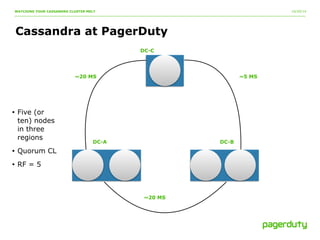

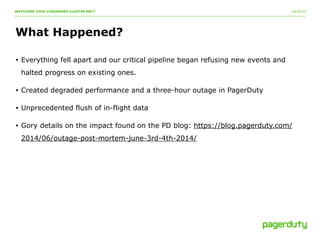

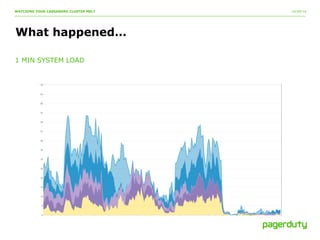



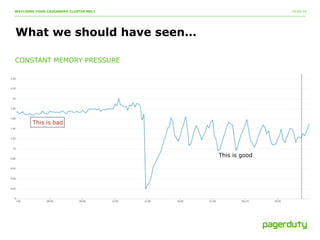





The document discusses a critical incident at PagerDuty involving their Cassandra cluster, which experienced a three-hour outage due to performance degradation and excessive memory pressure from multi-tenancy and underprovisioning. The team attempted various mitigation strategies but ultimately had to delete all data and restart the system, after which performance improved significantly. Key lessons emphasized include the importance of monitoring, scaling ahead of demand, and avoiding multi-tenancy in Cassandra deployments.



























































