Downloaded 13 times



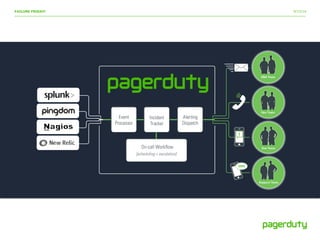











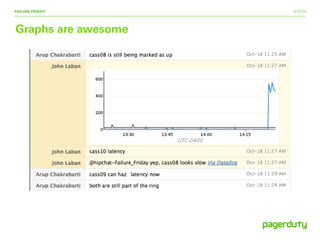















The document discusses insights from the 'Failure Friday' event at DevOpsDays Toronto 2014, emphasizing the importance of testing failure handling in systems to prepare for inevitable failures. It highlights various attack strategies, the cultural impact of knowledge sharing on failure management, and encourages proactive automation of failure testing. Overall, it advocates for continuous improvement in reliability and response to outages within development and operations teams.

























































