











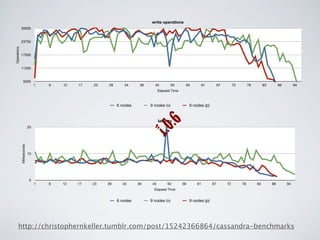



















Christopher Keller works as a solutions architect at NASA Ames researching the use of Cassandra to store and analyze security event data. He set up a 3 node Cassandra cluster on virtual machines and found it provided fast writes, no single point of failure, and flexibility as requirements evolved. Through trial and error, he optimized the data schema to match the questions they plan to ask. While there were some bugs encountered, Cassandra overall proved capable of handling their workload.



































































