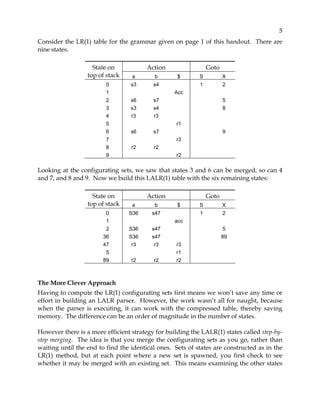
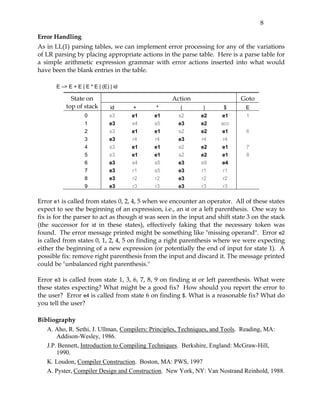
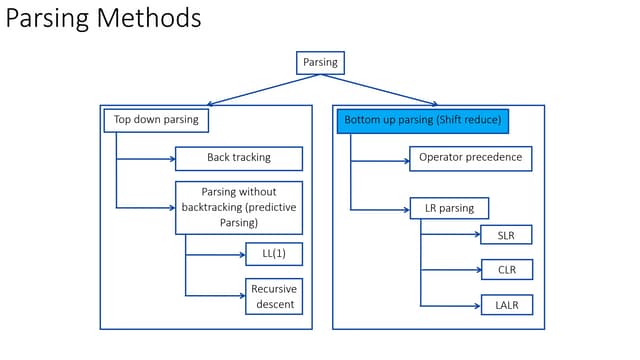
This document provides an overview of LALR parsing. It begins by motivating the need for LALR parsing by explaining limitations of LR(1) parsing which can result in many states. It then explains that LALR parsing attempts to reduce the number of states by merging similar LR(1) states. This can result in the same number of states as SLR(1) parsing but retains some LR(1) lookahead abilities. The document provides examples to illustrate LALR state merging and how it can avoid some SLR conflicts. It also notes that state merging can potentially introduce new reduce-reduce conflicts. The document describes two approaches to constructing LALR parsing tables and defines what constitutes a LALR