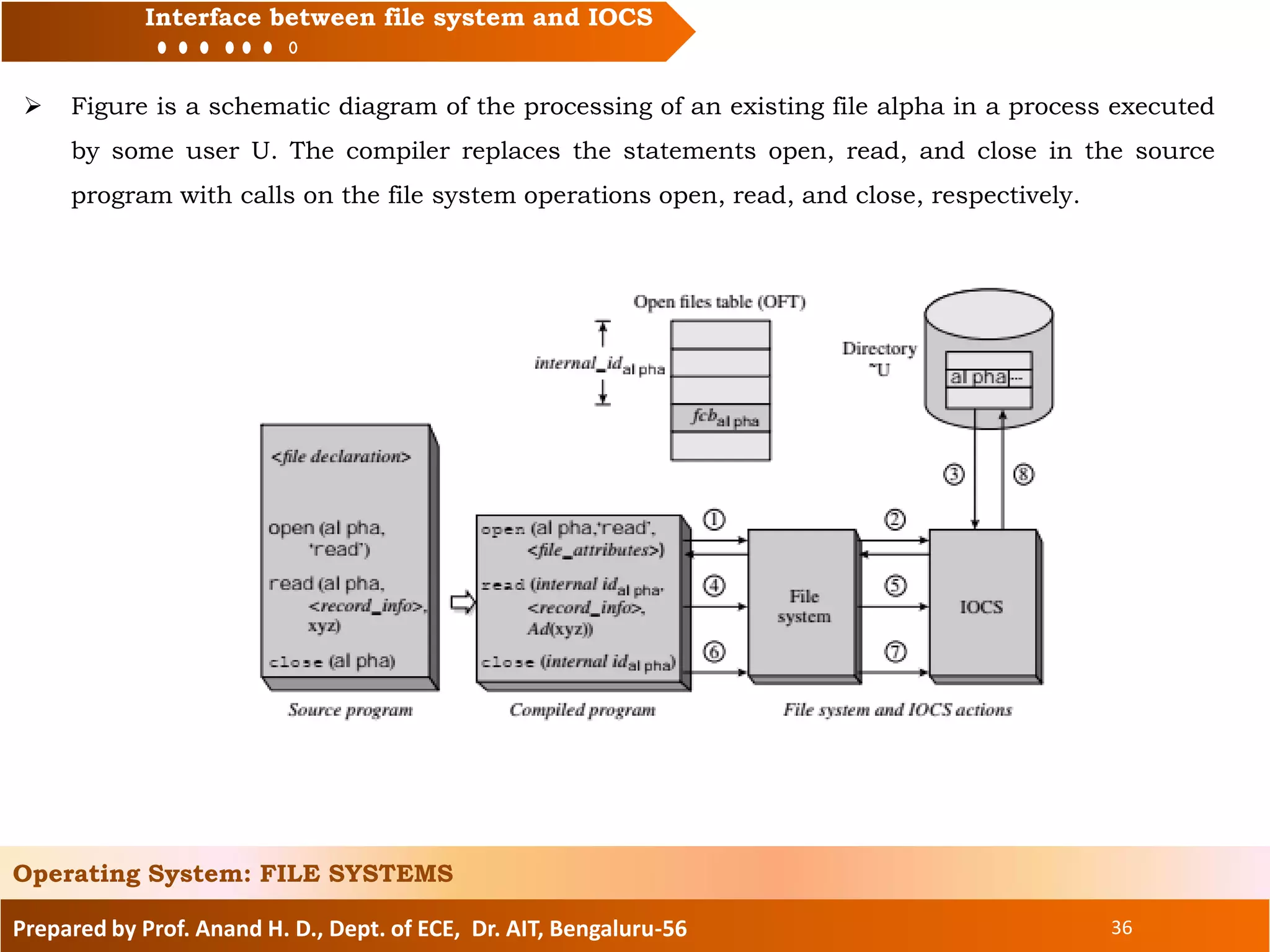
Download as PDF, PPTX












![Prepared by Prof. Anand H. D., Dept. of ECE, Dr. AIT, Bengaluru-56 13
Fundamentals of file organizations
Direct File Organization
The direct file organization provides convenience and efficiency of file processing when records
are accessed in a random order. To access a record, a read/write command needs to mention
the value in its key field. We refer to such files as direct-access files.
A direct-access file is implemented as follows: When a process provides the key value of a
record to be accessed, the access method module for the direct file organization applies a
transformation to the key value that generates the address of the record in the storage
medium.
If the file is organized on a disk, he transformation generates a (track_no, record_no) address.
The disk heads are now positioned on the track track_no before a read or write command is
issued on the record record_no.
Consider a file of employee information organized as a direct-access file. Let p records be
written on one track of the disk. Assuming the employee numbers and the track and record
numbers of the file to start from 1, the address of the record for employee number n is (track
number (tn), record number (rn)) where
and [. . ] indicates a rounded-up integer value.
Operating System: FILE SYSTEMS](https://image.slidesharecdn.com/osfilesystems-210510085819/75/OS-file-systems-13-2048.jpg)




































The document prepared by Prof. Anand H. D. discusses the file systems in operating systems, covering topics such as file organization, directory structures, file protection, and disk space allocation. It explains the differences between file systems and input/output control systems (IOCS), emphasizing the importance of efficient data access, file attributes, and operations. Various file organization methods, including sequential and direct access, are analyzed along with access methods that enhance file processing efficiency.























































































