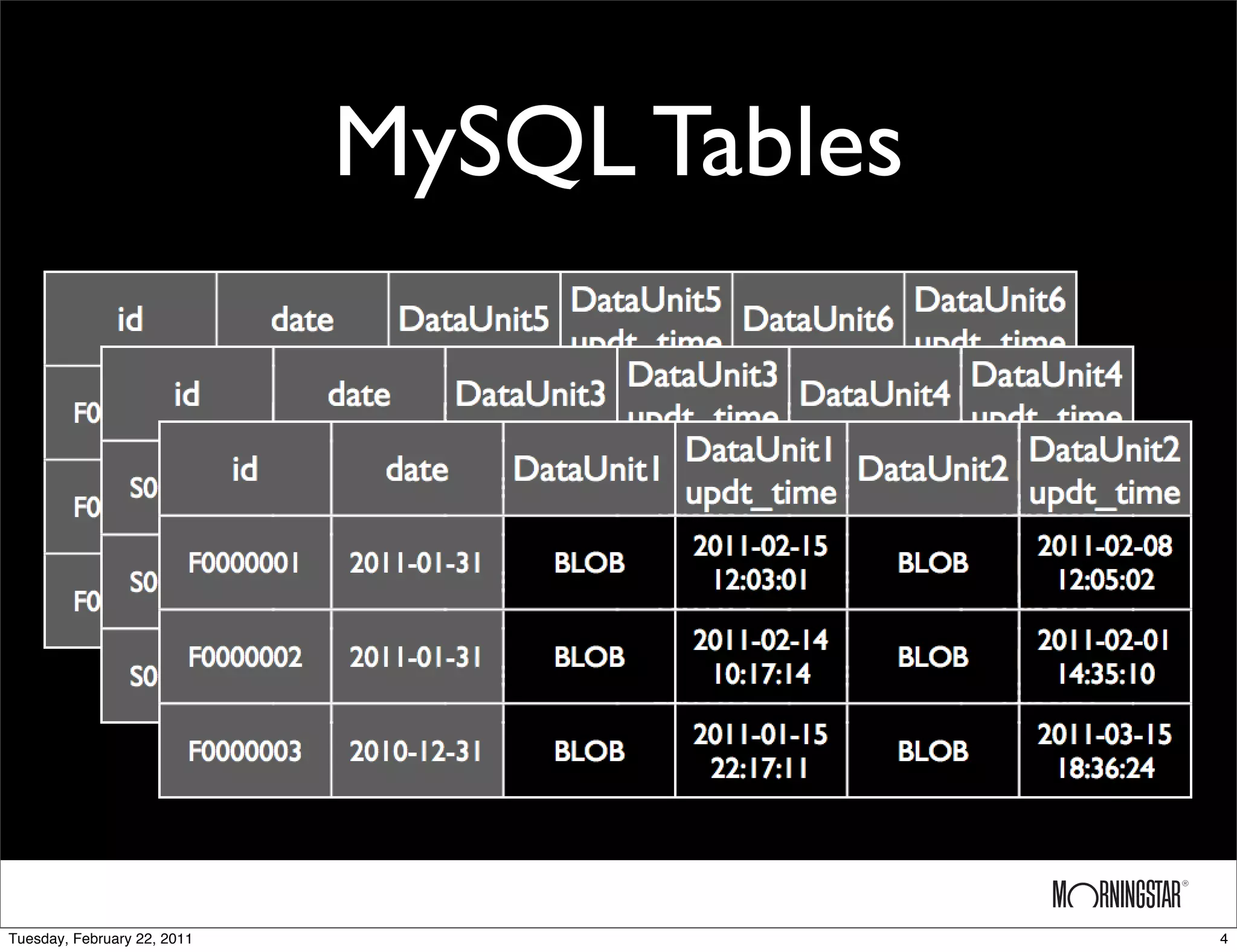
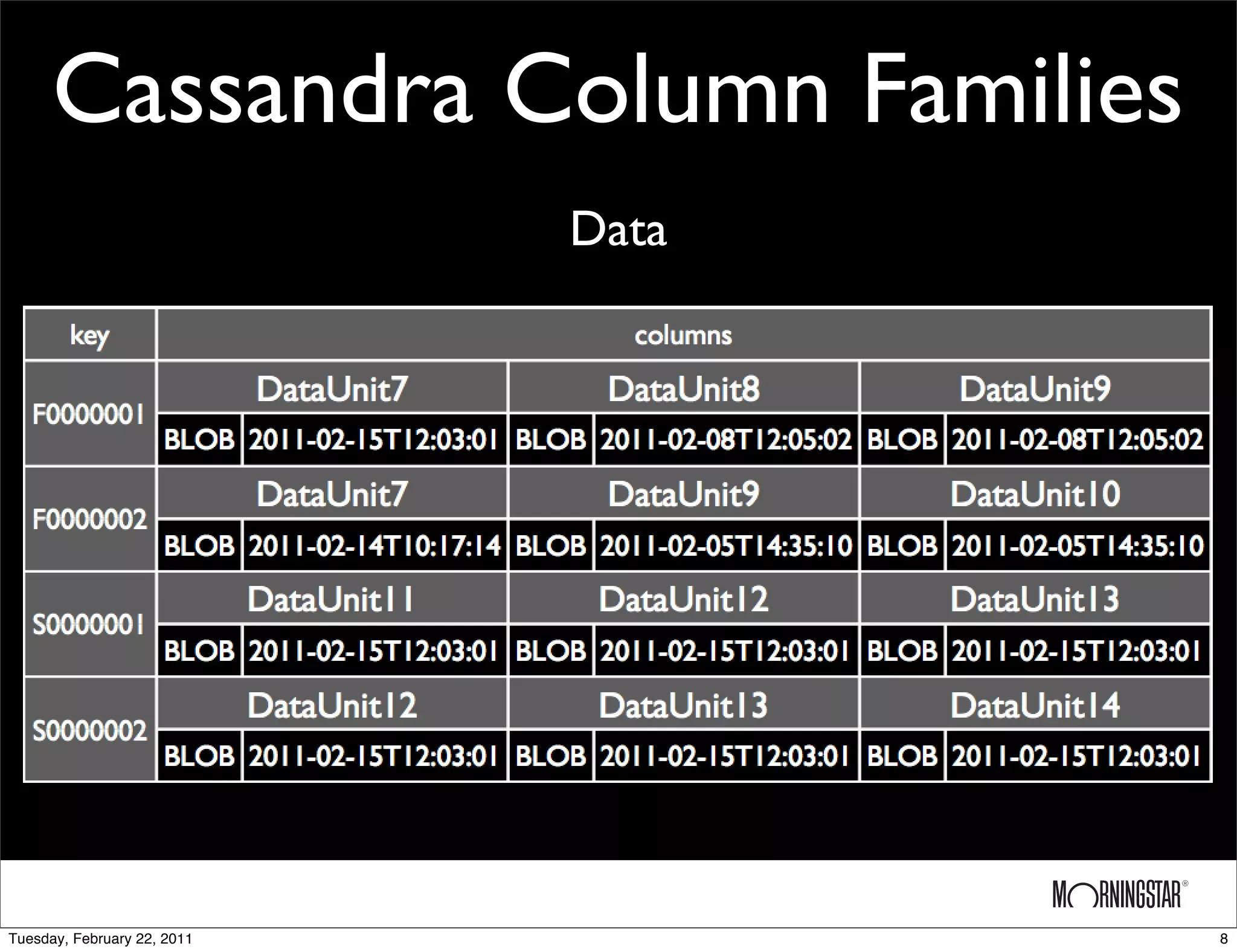
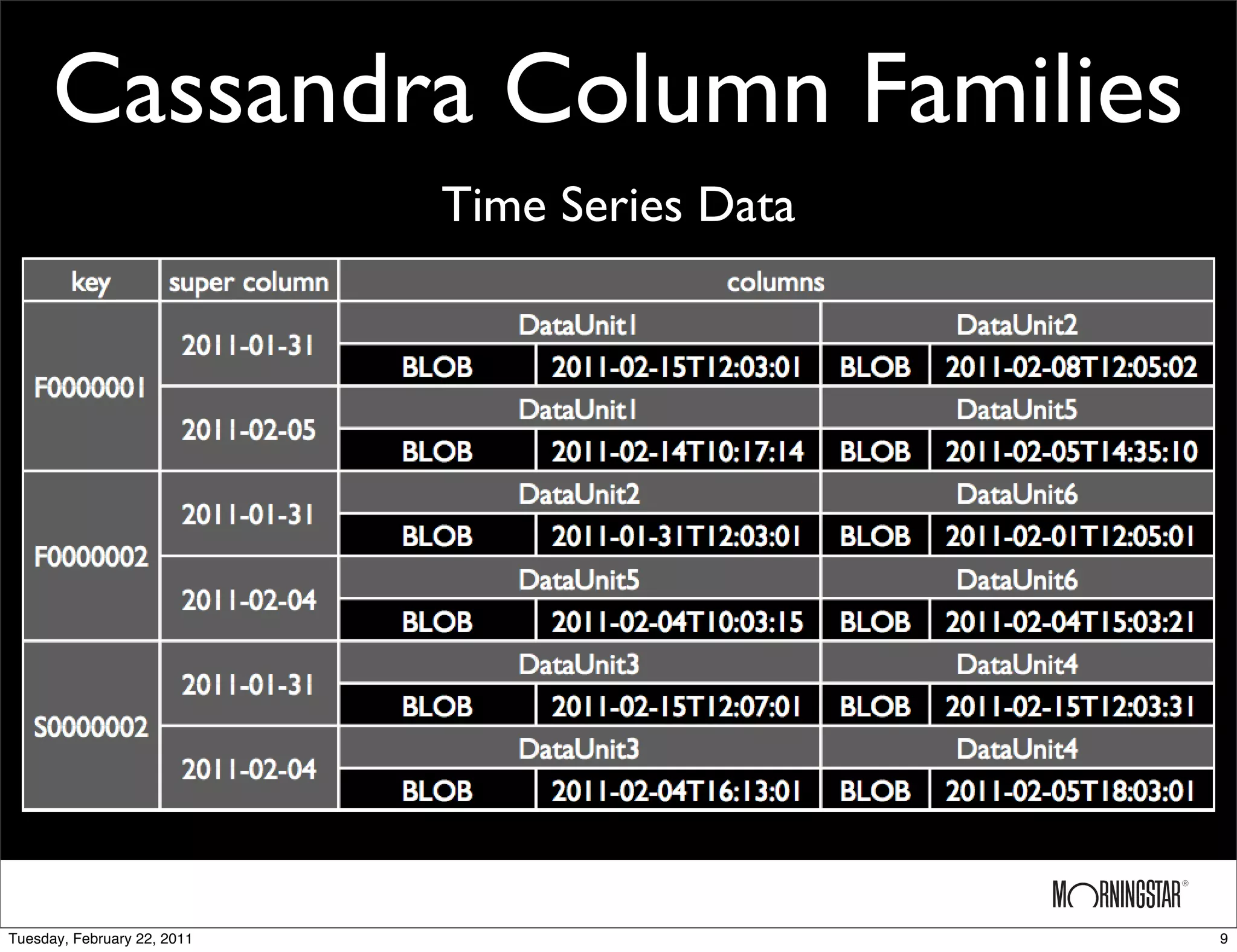
The document outlines the evolution of a data storage system from a MySQL implementation to a Cassandra-based implementation, detailing initial requirements and challenges encountered. While the MySQL setup faced issues with scalability and slow multi-site replication, the Cassandra system offered improved scalability and ease of multi-site replication but struggled with arbitrary queries and monitoring. Future plans include upgrading Cassandra and expanding the cluster globally.











































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)












