Downloaded 21 times









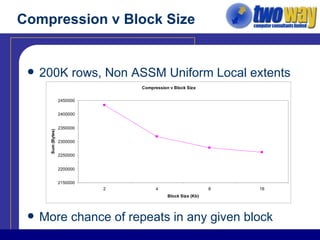
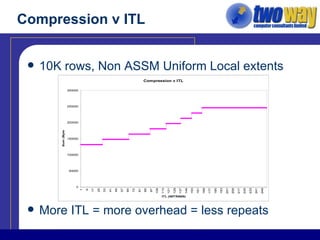
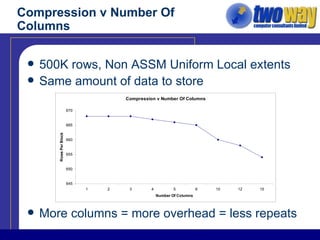
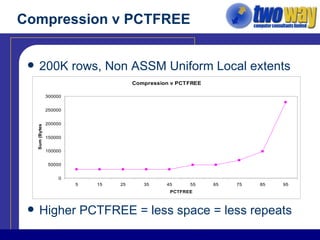
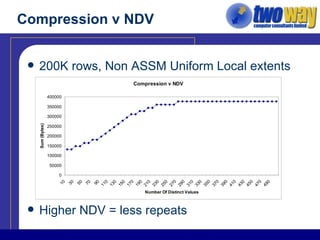
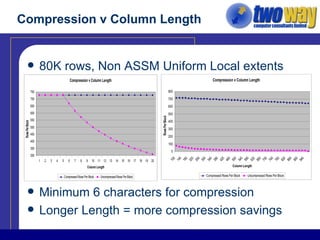

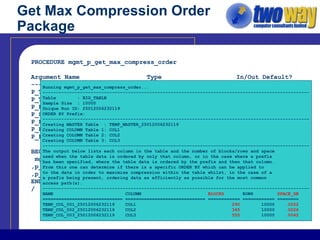






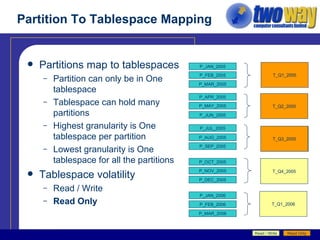





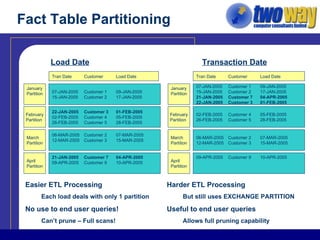






The document discusses techniques for optimizing storage in Oracle databases for data warehousing workloads. It covers data segment compression, which can reduce the storage space required by eliminating repeated column values within database blocks. It also discusses partitioning tables, which can improve query performance, manageability, scalability and availability by dividing tables into smaller, more manageable parts. Key recommendations include ordering data to maximize compression, using appropriate partitioning strategies like partitioning on a transaction date for fact tables, and ensuring statistics are gathered after maintenance operations.


























![Les17[1] Writing Executable Statements](https://cdn.slidesharecdn.com/ss_thumbnails/les171-220214161621-thumbnail.jpg?width=640&height=640&fit=bounds)













































