Download as PDF, PPTX






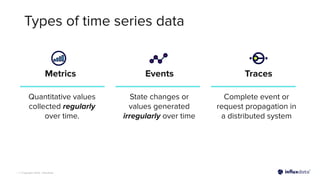






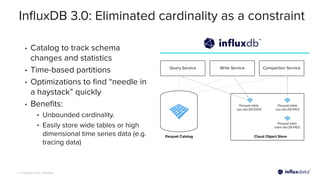
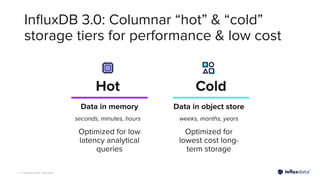
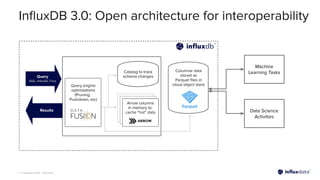
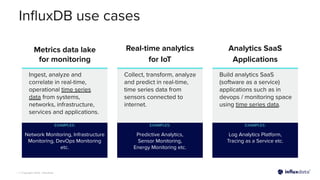
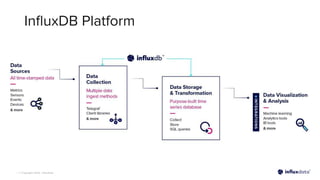






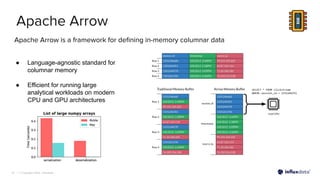

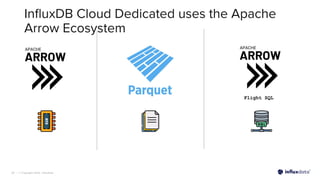





The document introduces InfluxDB 3.0 and InfluxDB Cloud Dedicated, highlighting their optimizations for handling time series data at scale, with features like sub-second query responses and built-in data lifecycle management. It emphasizes the platform's adaptability for various workloads, security, and cost-effectiveness, alongside its use of modern technologies such as Apache Arrow and Parquet for efficient data processing. The target industries for adoption include gaming, fintech, and industrial IoT, showcasing its versatility across different applications.












![Paul Dix [InfluxData] | InfluxDays Opening Keynote | InfluxDays Virtual Exper...](https://cdn.slidesharecdn.com/ss_thumbnails/2020-11-10influxdays-introducinginfluxdbiox-201110182839-thumbnail.jpg?width=640&height=640&fit=bounds)










![Paul Dix [InfluxData] | InfluxDays Keynote: Future of InfluxDB | InfluxDays N...](https://cdn.slidesharecdn.com/ss_thumbnails/2021-10-26whytimeseries-influxdaysna-211026005527-thumbnail.jpg?width=640&height=640&fit=bounds)

![Tobias Braun [Herrenknecht AG] | Going Underground with InfluxDB | InfluxDays...](https://cdn.slidesharecdn.com/ss_thumbnails/tobiasbrauninfluxdays-goingundergroundwithinfluxdb-211005172827-thumbnail.jpg?width=640&height=640&fit=bounds)














![Ward Bowman [PTC] | ThingWorx Long-Term Data Storage with InfluxDB | InfluxDa...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays-221027185325-5d2f430b-thumbnail.jpg?width=640&height=640&fit=bounds)
![Scott Anderson [InfluxData] | New & Upcoming Flux Features | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022-fluxupdates-scott-221021210238-9d323cba-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday2-221020220104-abde55ea-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Welcome to InfluxDays 2022 - Day 2 | Influ...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022welcometoday2-221020215815-c8463942-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts Day 1 | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday1-221020215301-f8040e1f-thumbnail.jpg?width=640&height=640&fit=bounds)
![Paul Dix [InfluxData] The Journey of InfluxDB | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/2022-11-02influxdays-journeyofinfluxdb-221020214252-ff7c76c5-thumbnail.jpg?width=640&height=640&fit=bounds)
![Jay Clifford [InfluxData] | Tips & Tricks for Analyzing IIoT in Real-Time | I...](https://cdn.slidesharecdn.com/ss_thumbnails/newdem21tipsandtricksforanalyzingiiotinrealtimejayclifford-221020213303-a3258e00-thumbnail.jpg?width=640&height=640&fit=bounds)
![Brian Gilmore [InfluxData] | Use Case: IIoT Overview | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/usecaseiiot-gilmorereviewed-221020213120-a1d11a74-thumbnail.jpg?width=640&height=640&fit=bounds)



















