Download as PDF, PPTX






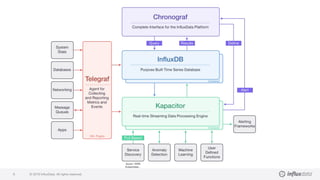

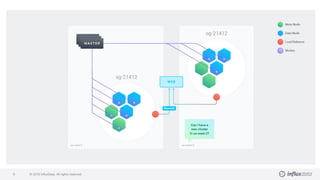









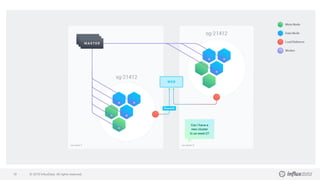
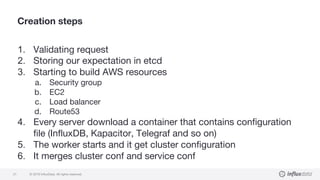


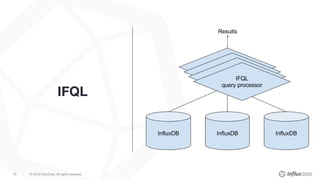





The document details a workshop led by Gianluca Arbezzano, a Site Reliability Engineer at InfluxData, focusing on database orchestration and infrastructure management using cloud services like AWS and DigitalOcean. It covers orchestration methods such as using EC2 and container management, emphasizing the importance of building scalable architectures and maintaining desired system states. Additionally, it highlights best practices for monitoring and managing logs, alongside various tools utilized in the orchestration process.
































![Gilmore, Palani [InfluxData] | Use Case: Monitoring / Observability | InfluxD...](https://cdn.slidesharecdn.com/ss_thumbnails/usecasemonitoringobservabilityreviewed-221020212958-9acef1d5-thumbnail.jpg?width=640&height=640&fit=bounds)






























![Ward Bowman [PTC] | ThingWorx Long-Term Data Storage with InfluxDB | InfluxDa...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays-221027185325-5d2f430b-thumbnail.jpg?width=640&height=640&fit=bounds)
![Scott Anderson [InfluxData] | New & Upcoming Flux Features | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022-fluxupdates-scott-221021210238-9d323cba-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday2-221020220104-abde55ea-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Welcome to InfluxDays 2022 - Day 2 | Influ...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022welcometoday2-221020215815-c8463942-thumbnail.jpg?width=640&height=640&fit=bounds)
![Steinkamp, Clifford [InfluxData] | Closing Thoughts Day 1 | InfluxDays 2022](https://cdn.slidesharecdn.com/ss_thumbnails/influxdays2022closingthoughtsday1-221020215301-f8040e1f-thumbnail.jpg?width=640&height=640&fit=bounds)



