Download as PDF, PPTX



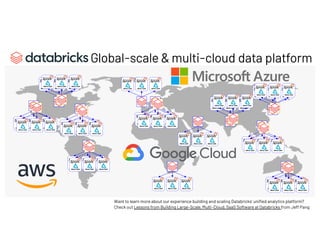
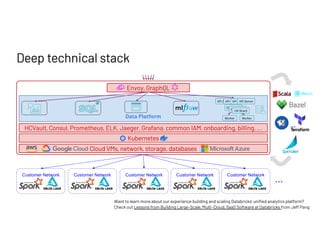
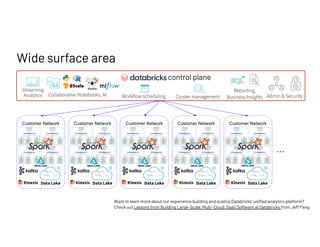
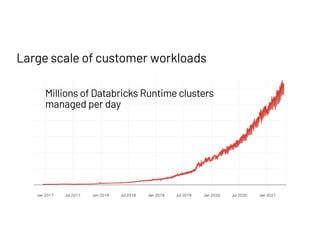
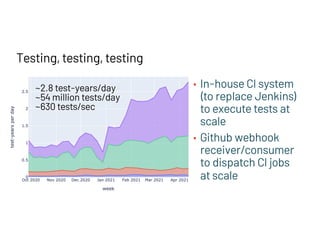
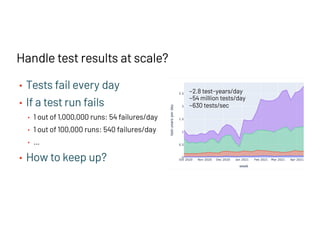




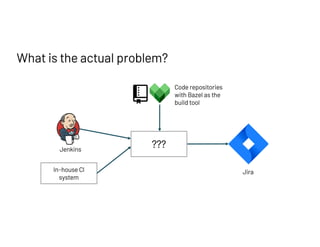
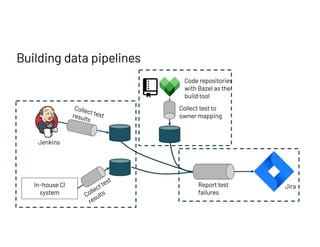


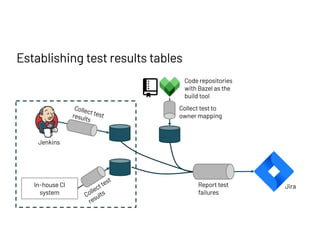


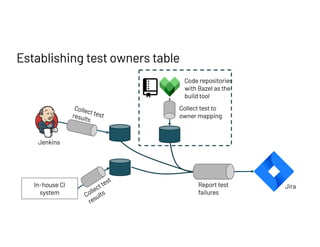


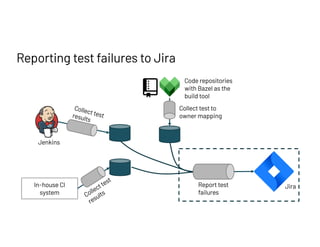
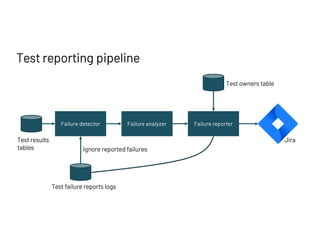
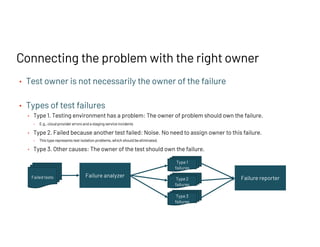






The document discusses managing millions of tests at Databricks, highlighting the implementation of a CI system to automate the execution and reporting of tests at scale. It emphasizes the importance of triaging test failures to the correct owners in a developer-friendly manner and outlines the use of various technologies and methodologies to enhance testing and reporting processes. The presentation also touches on future goals, such as building holistic views of CI/CD activities and improving engineering practices based on CI/CD insights.




![[DSC Europe 22] Overview of the Databricks Platform - Petar Zecevic](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-databricksoverview-221130080703-c60d93de-thumbnail.jpg?width=640&height=640&fit=bounds)

































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)
















