
Download as PDF, PPTX






































































































































![Dining-Philosophers Problem
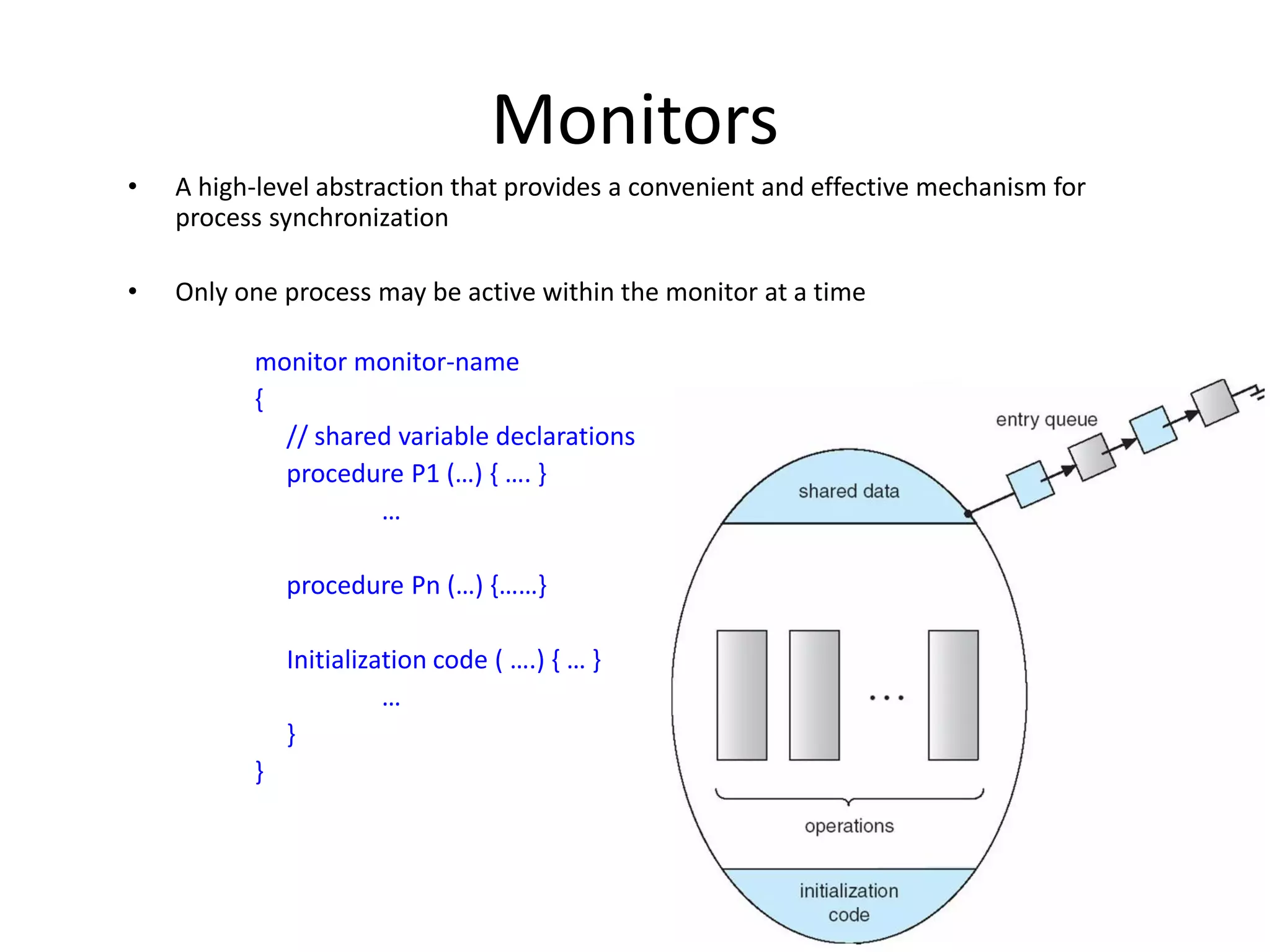
• Shared data
– Bowl of rice (data set)
– Semaphore chopstick [5] initialized to 1](https://image.slidesharecdn.com/301-181205070718/75/Operating-System-158-2048.jpg)

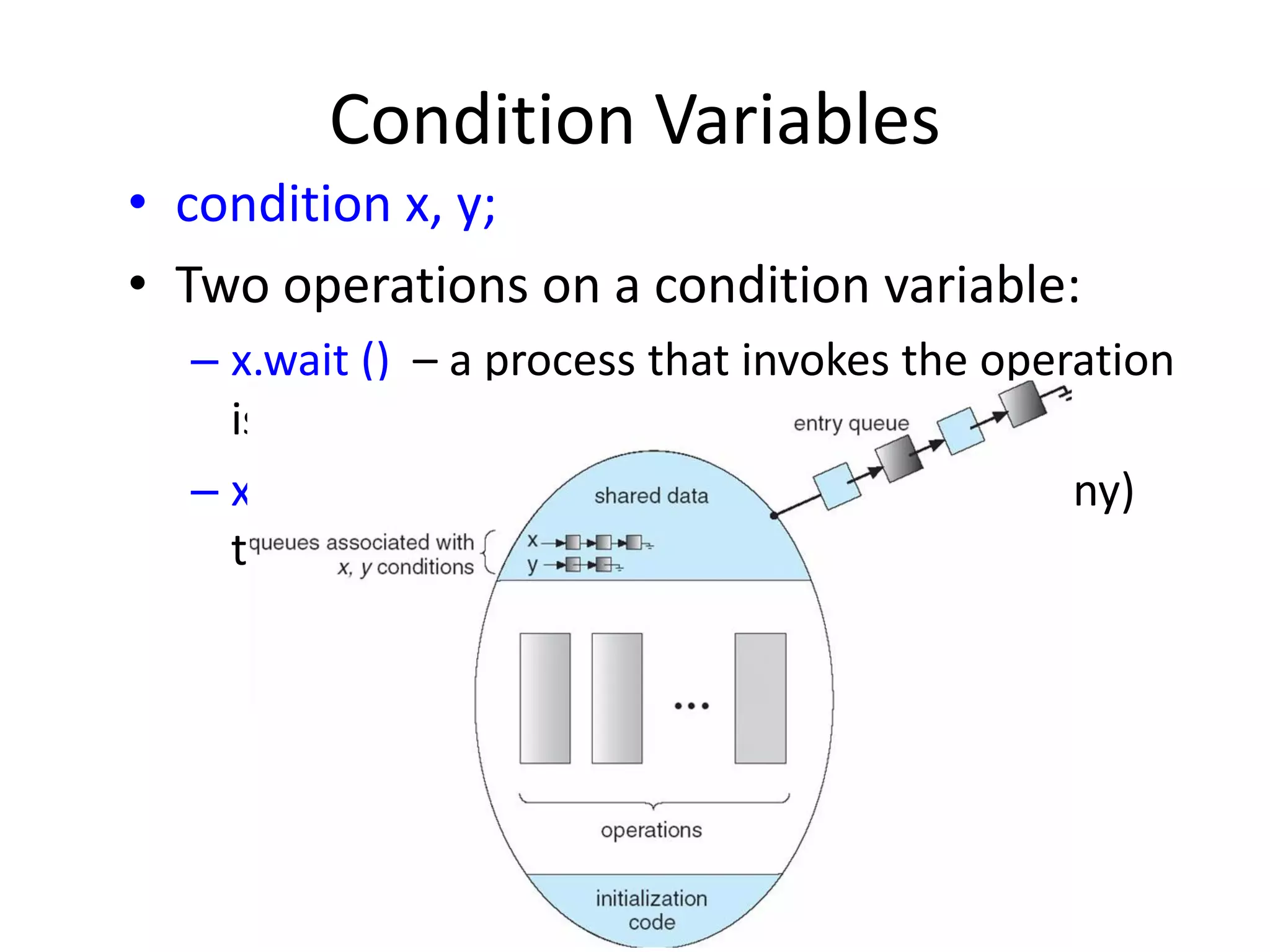







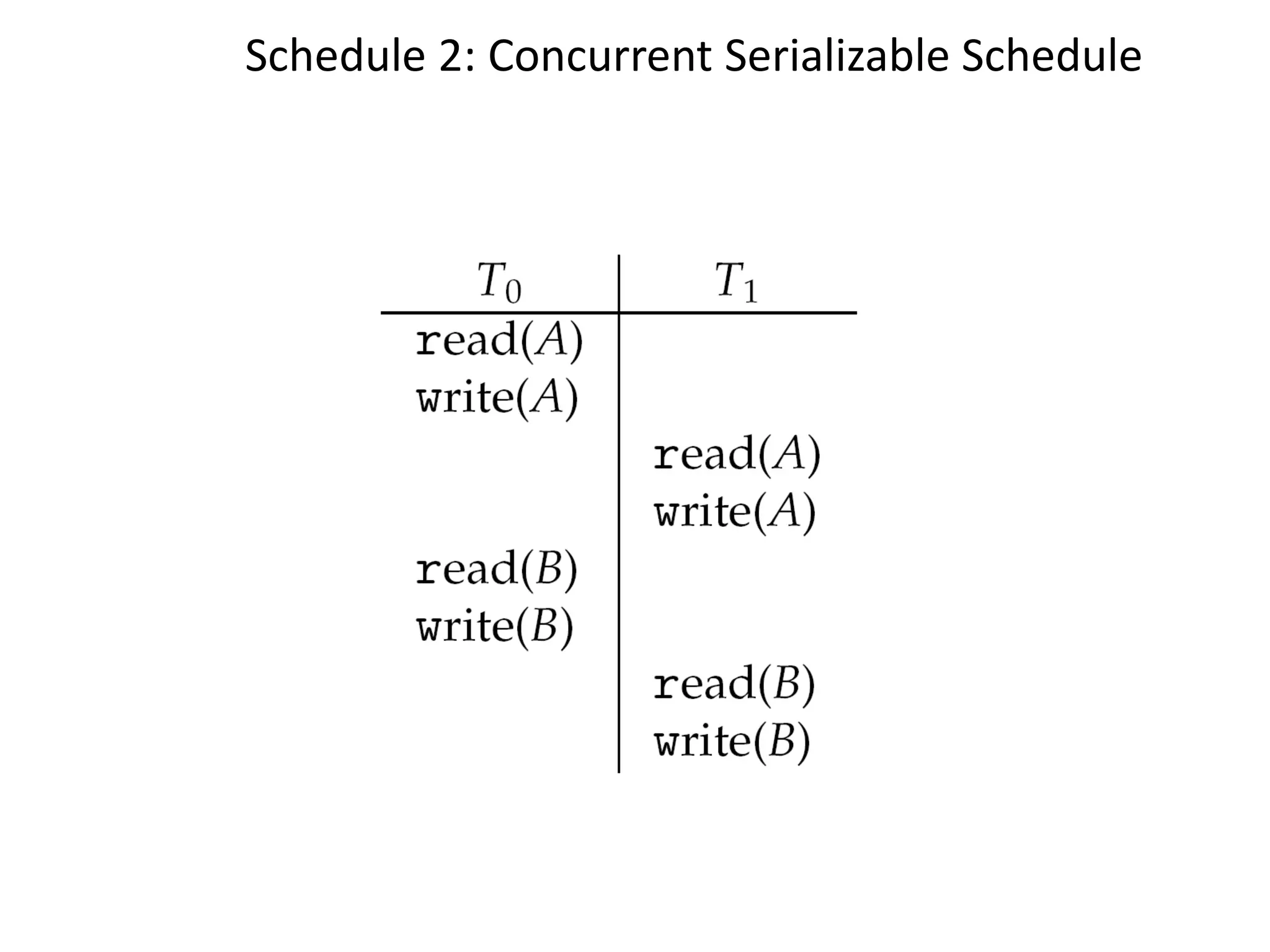













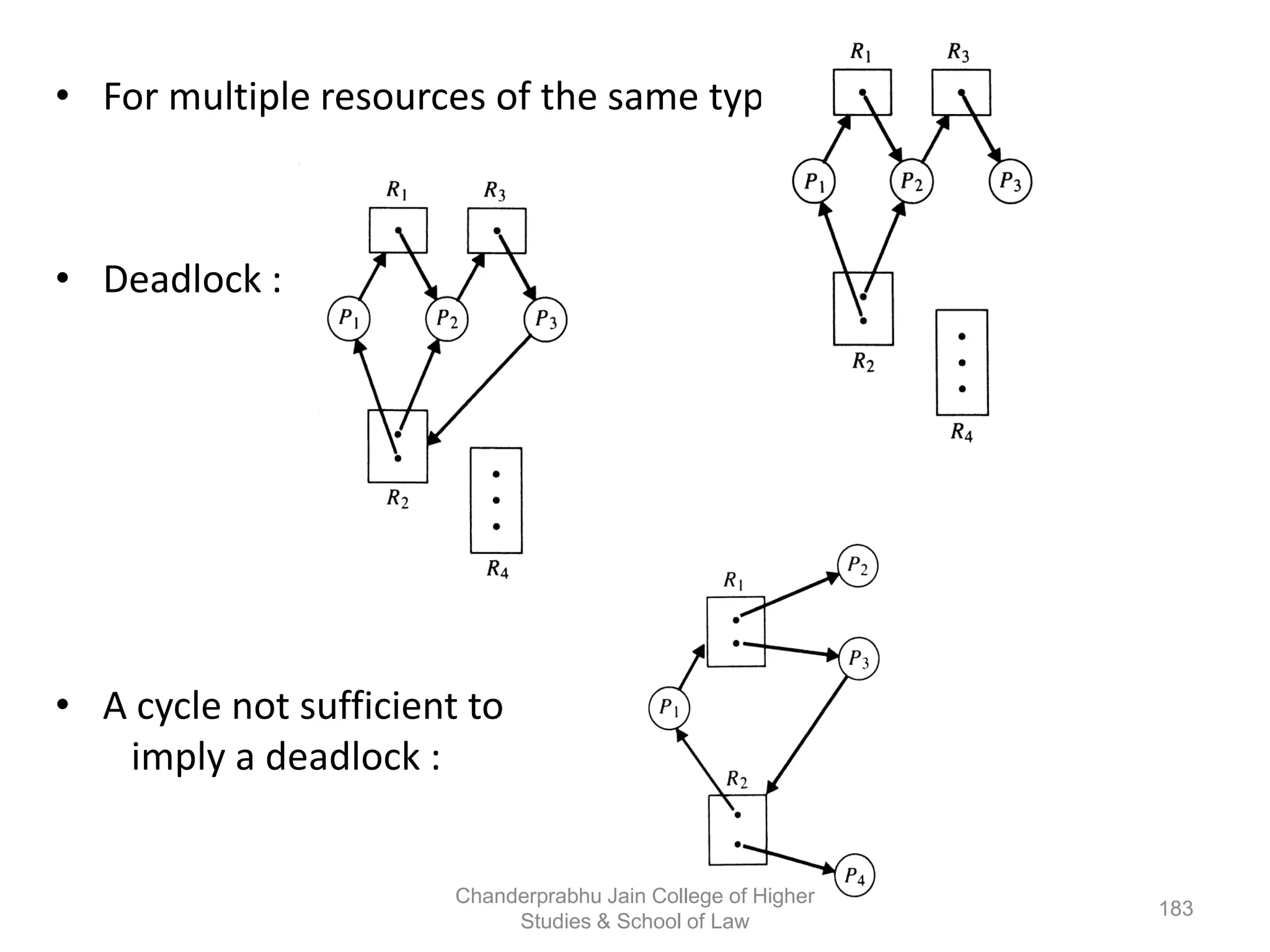


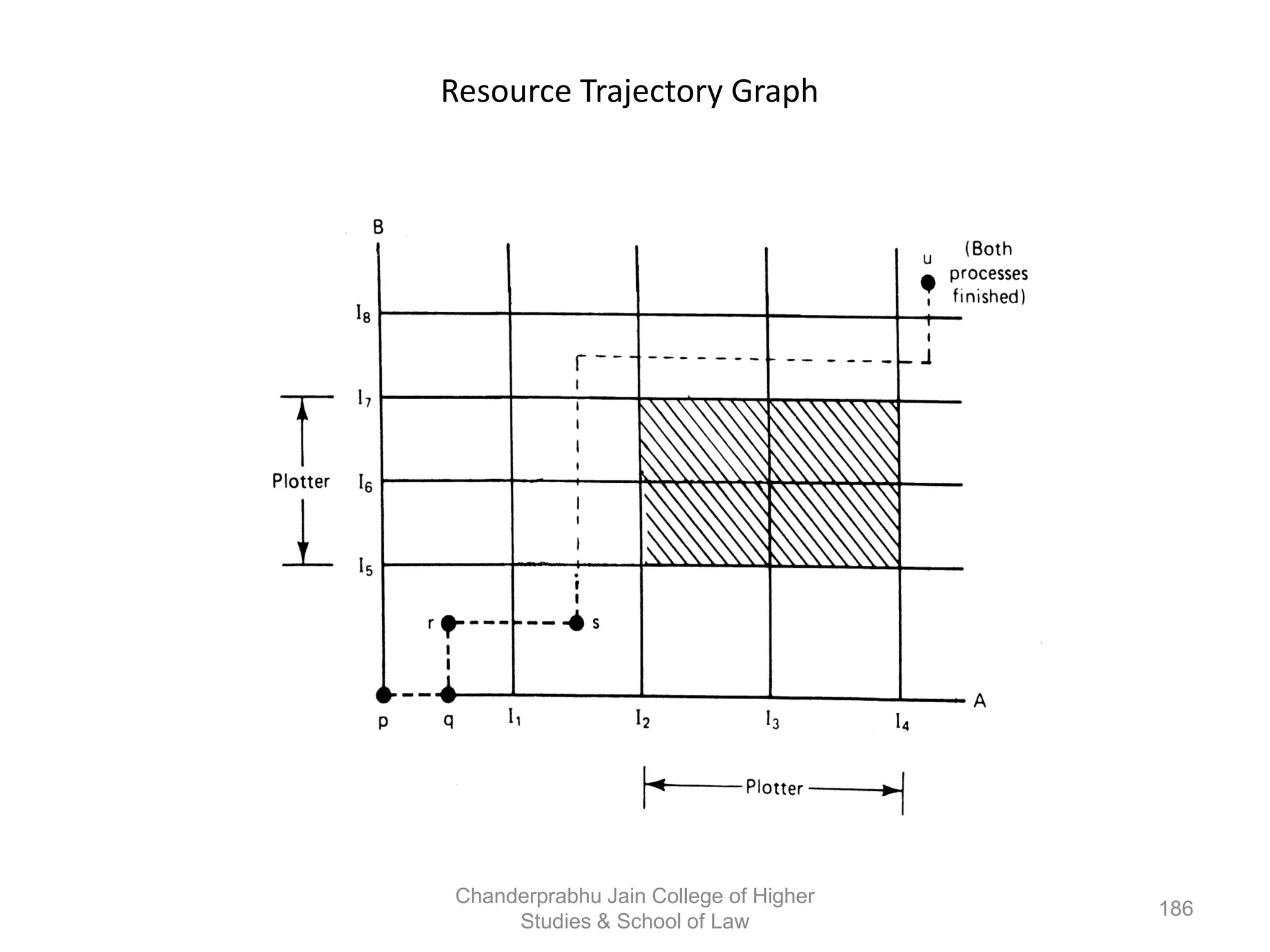
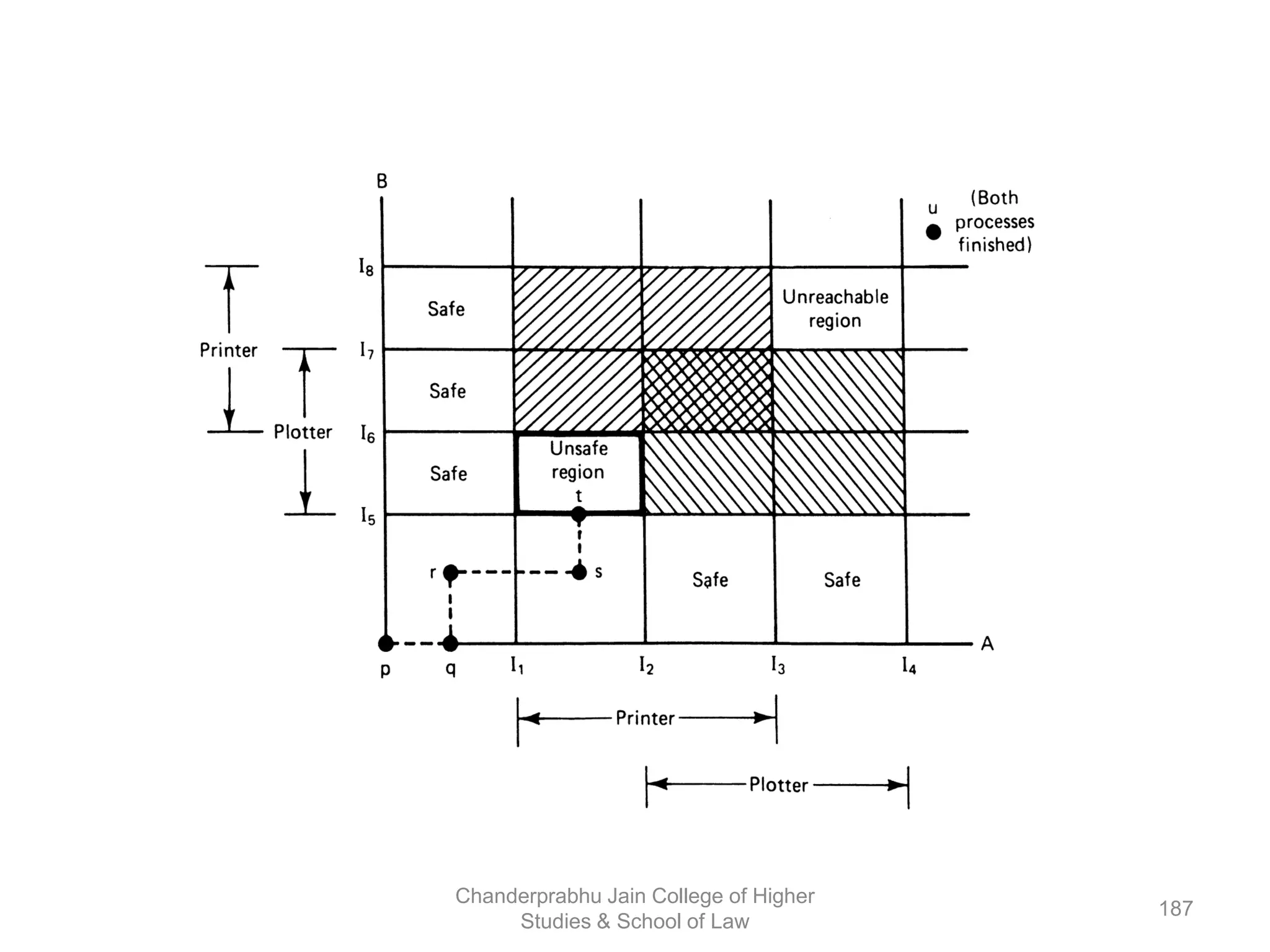




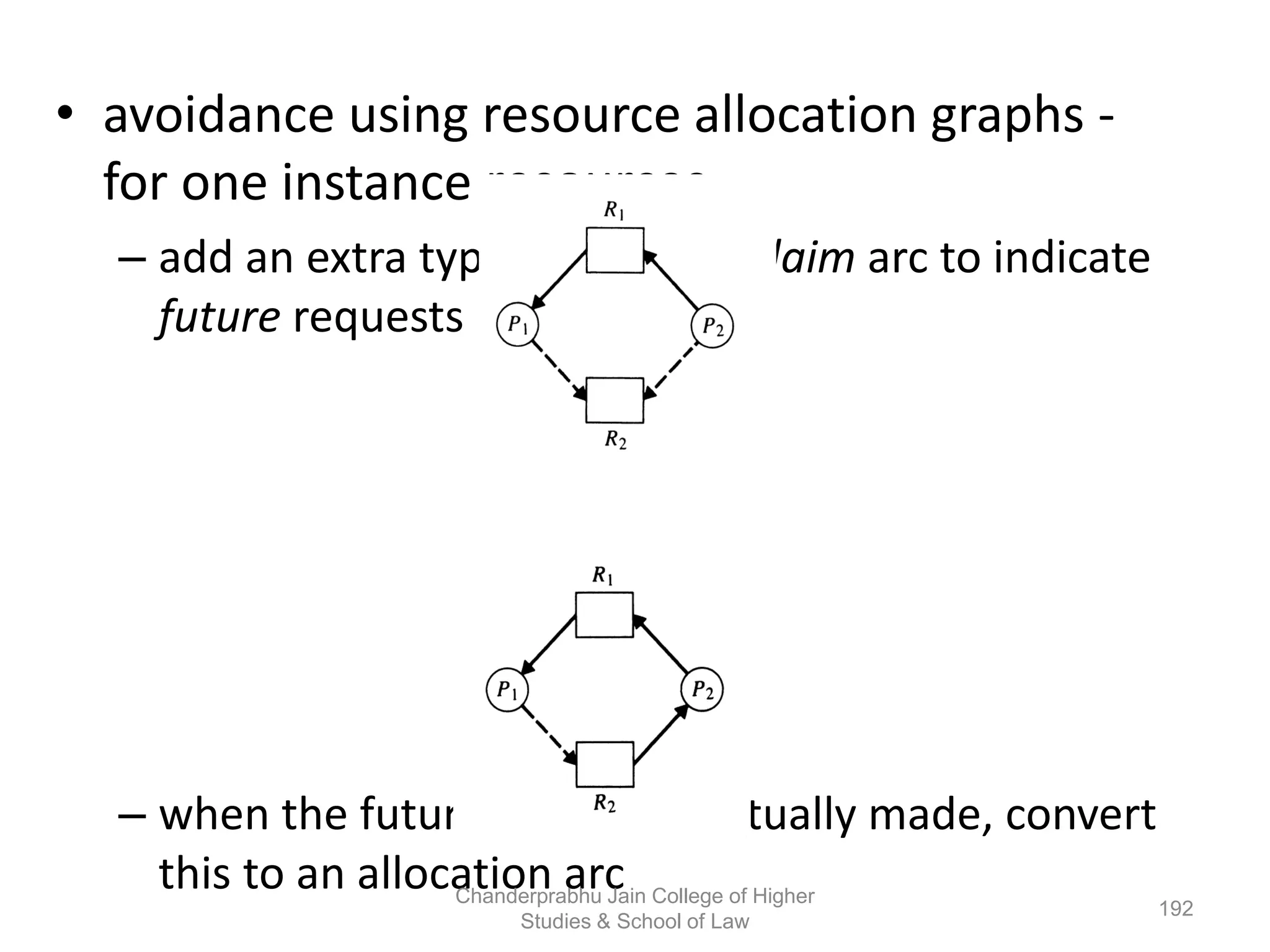





































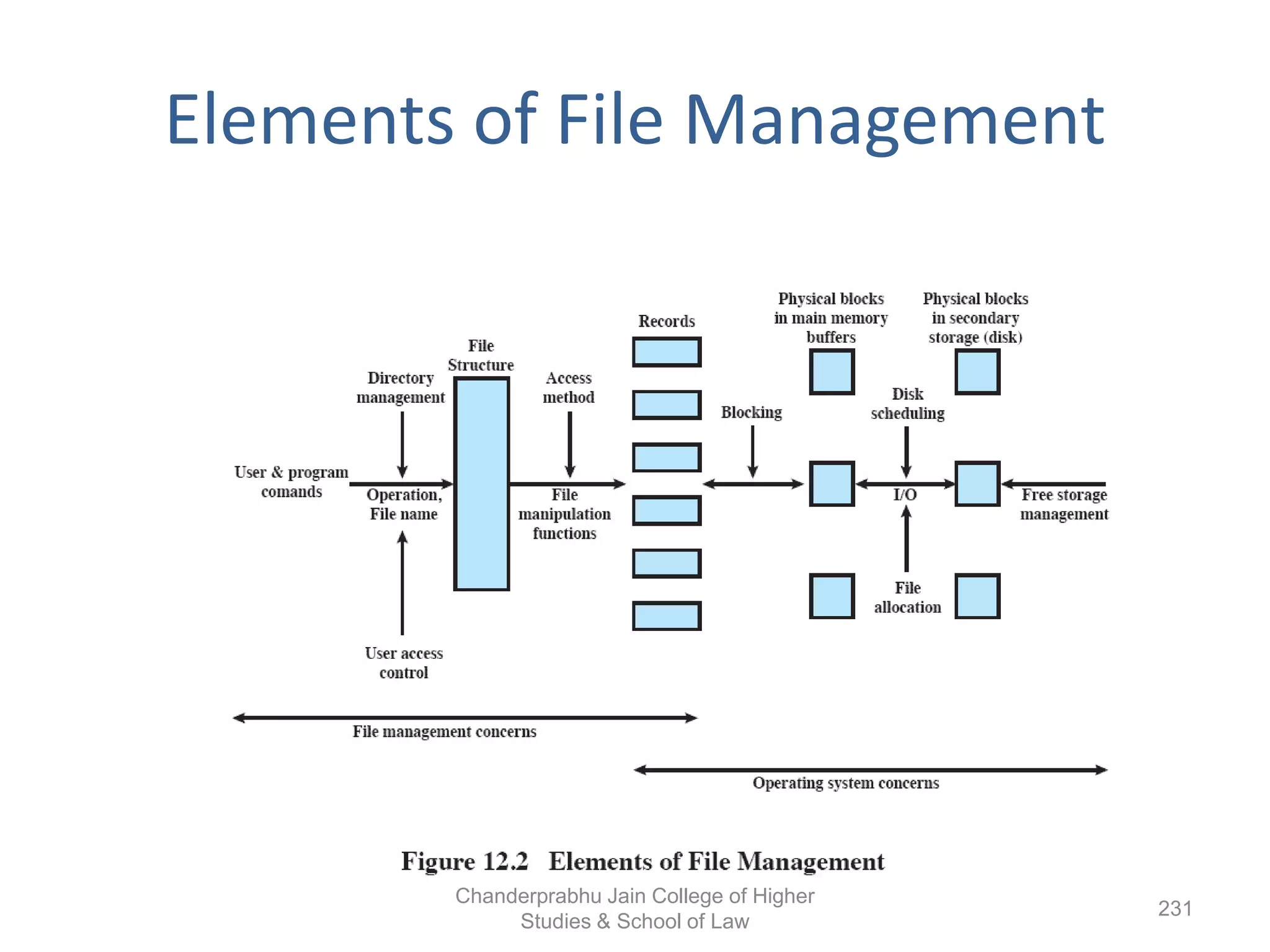

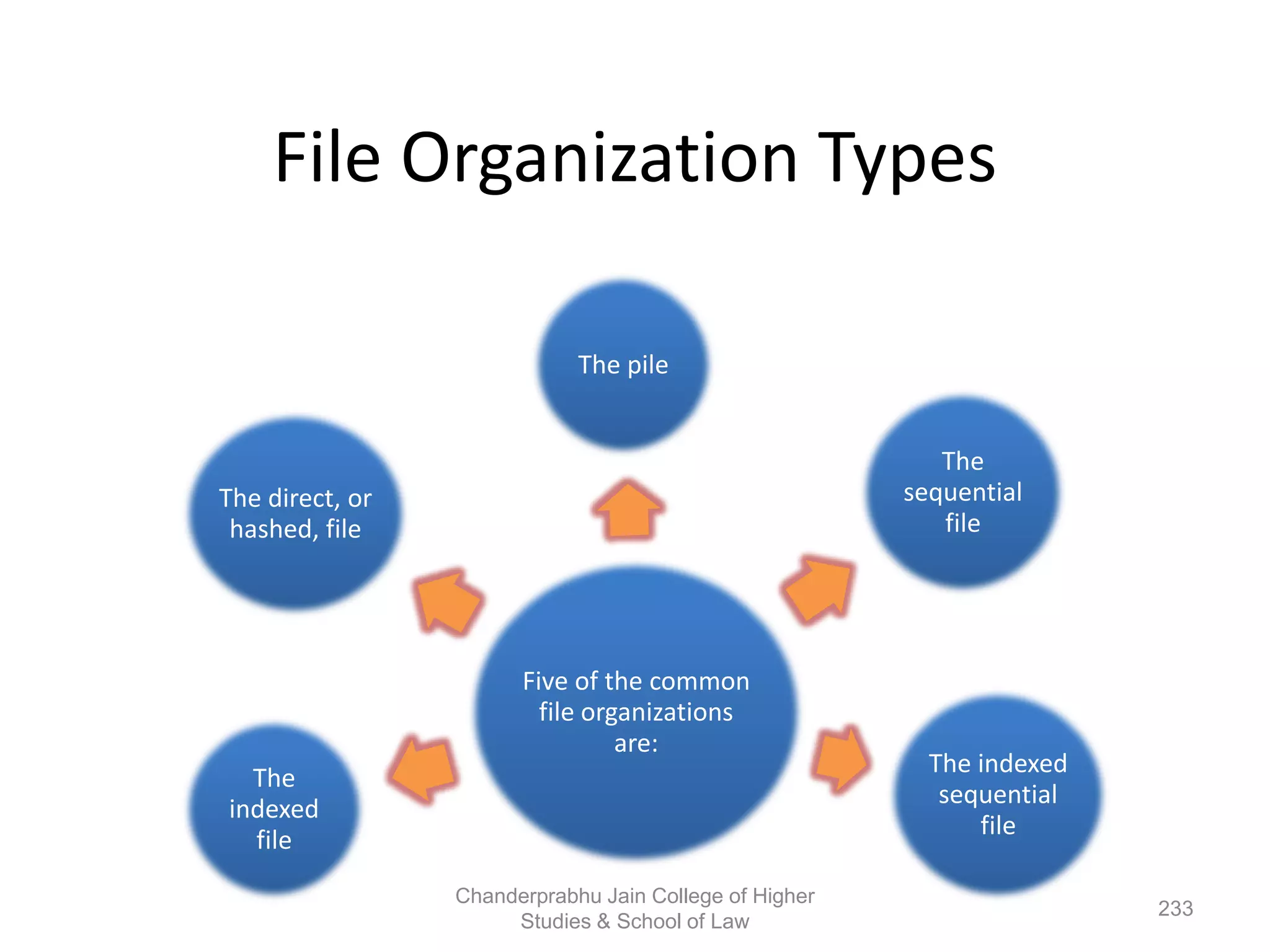



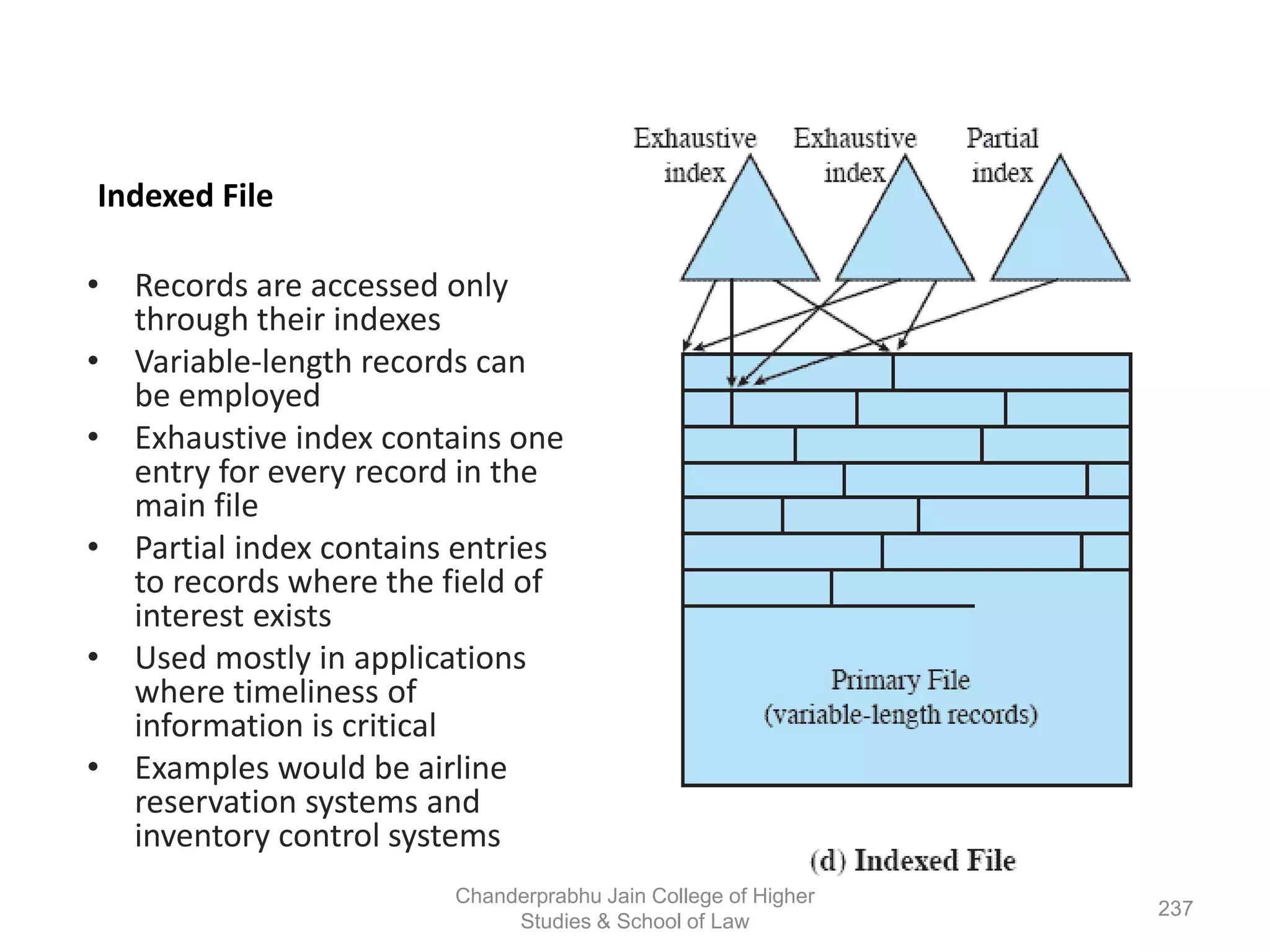








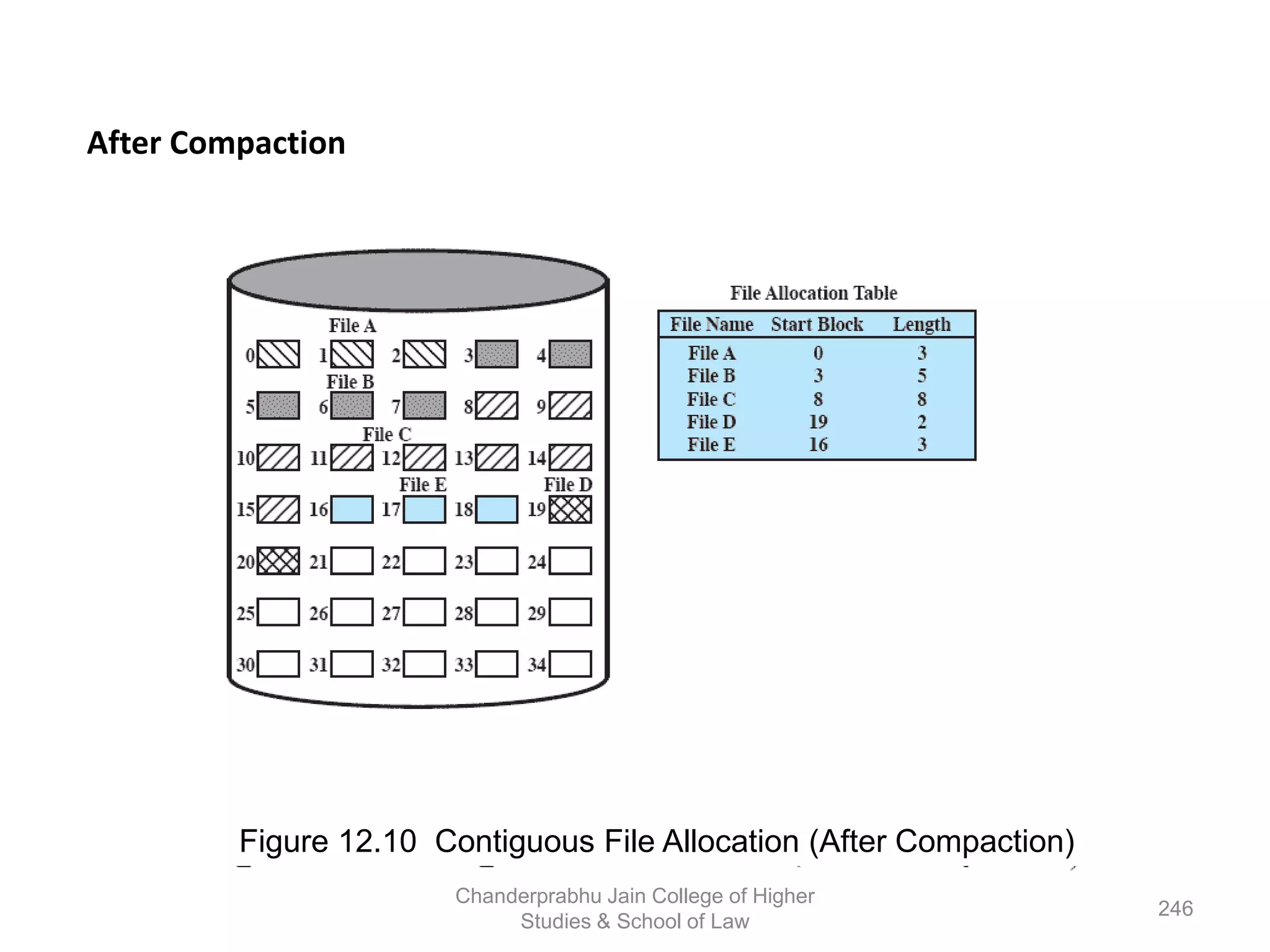
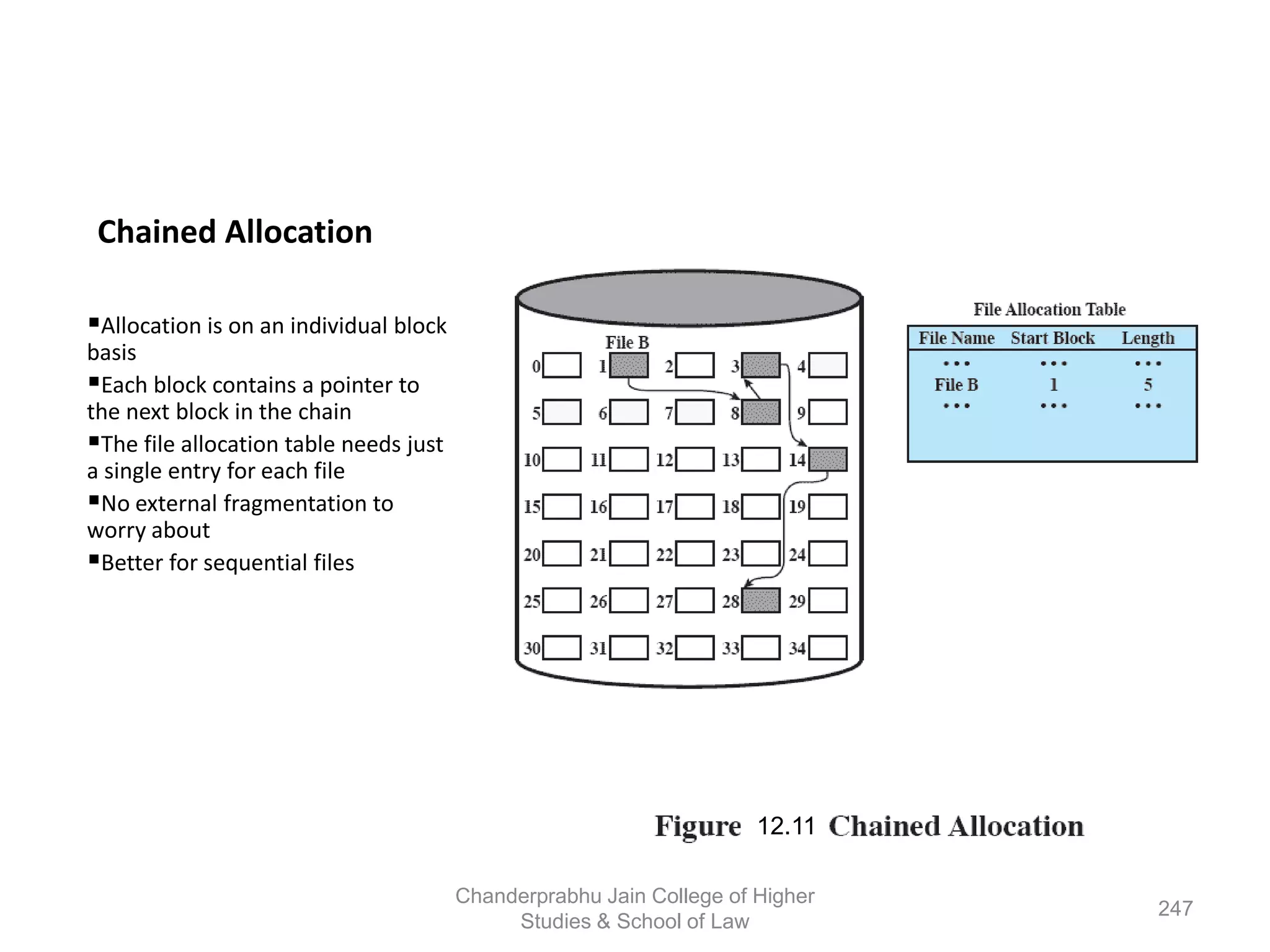






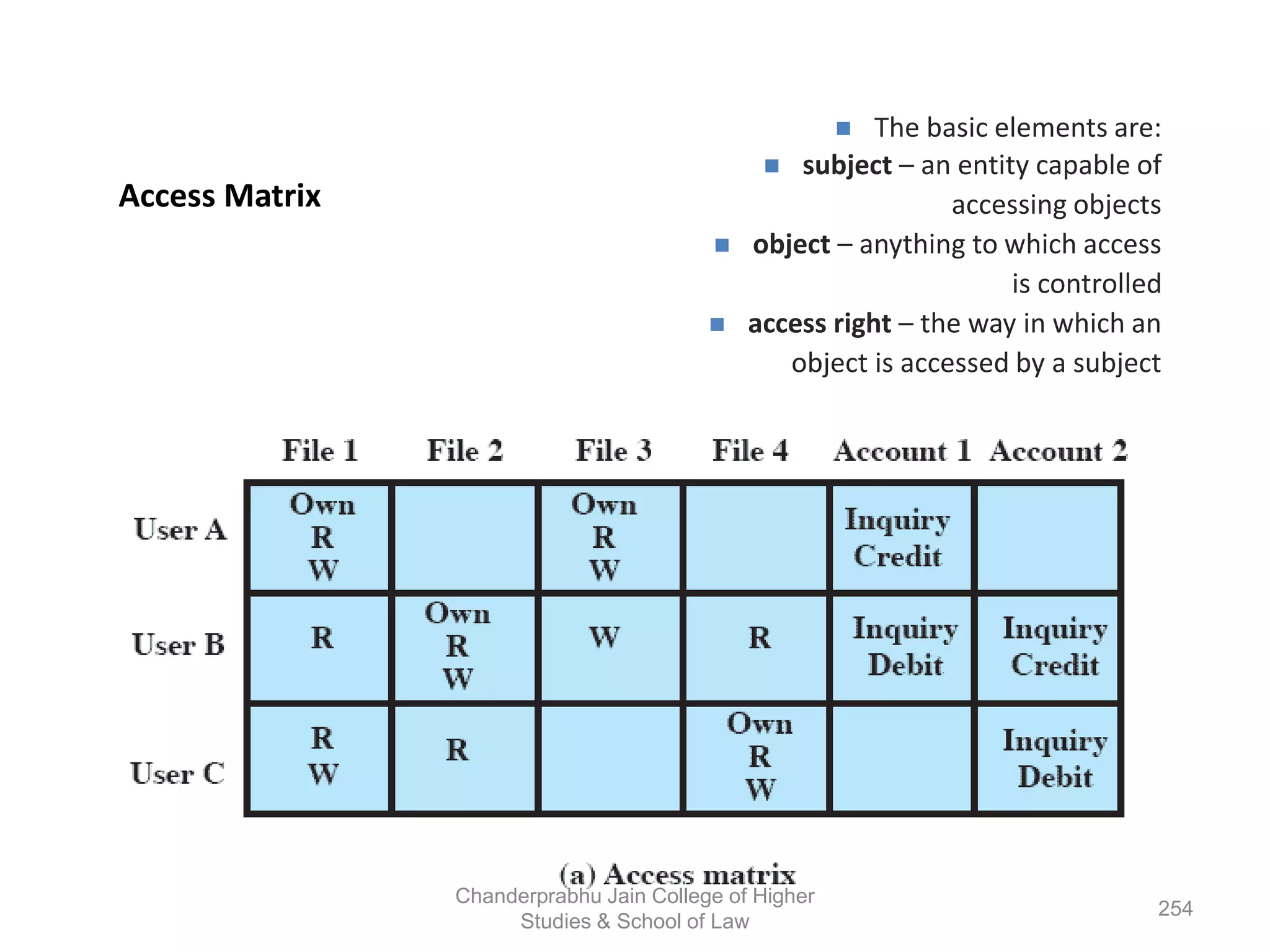

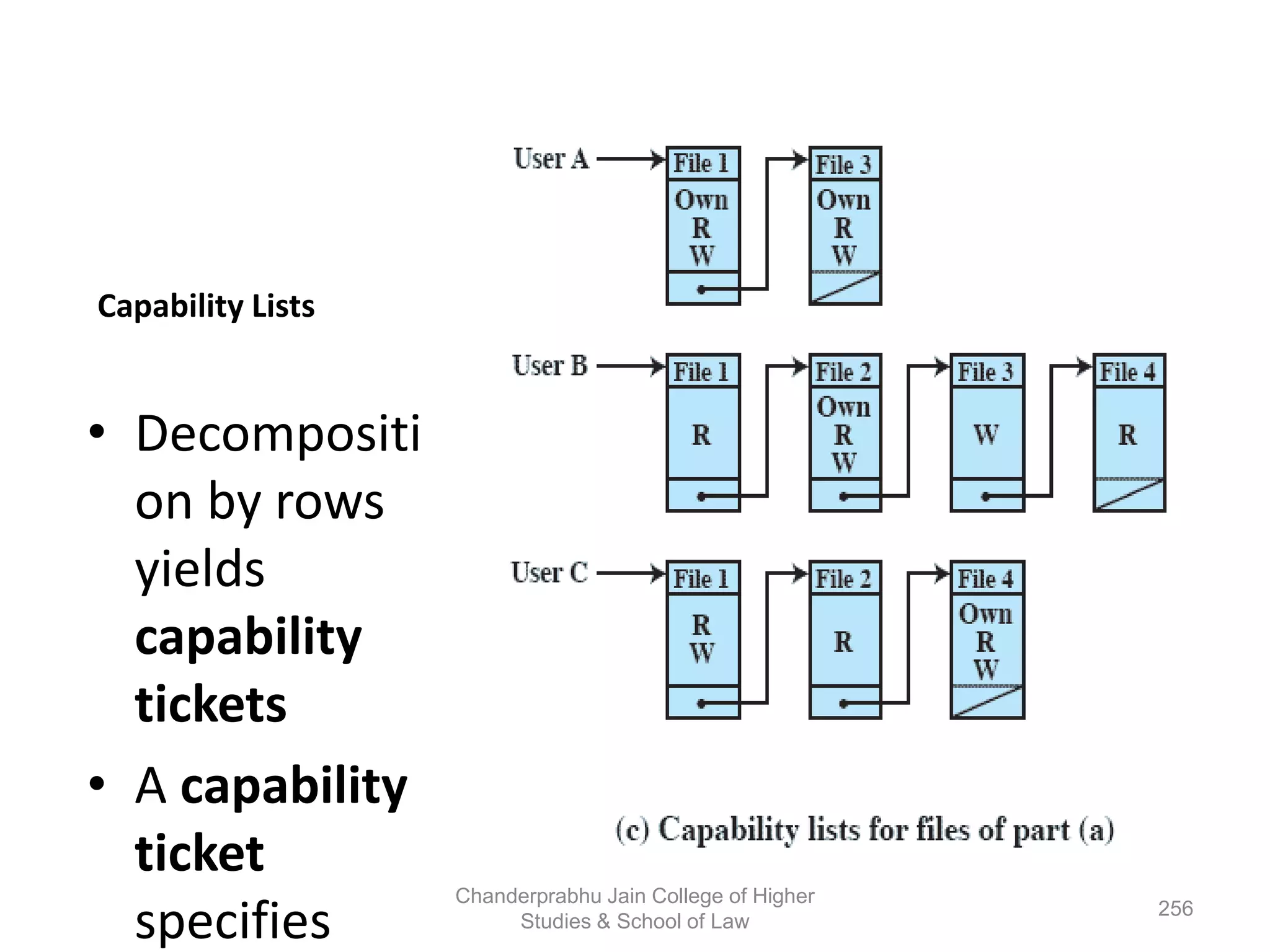


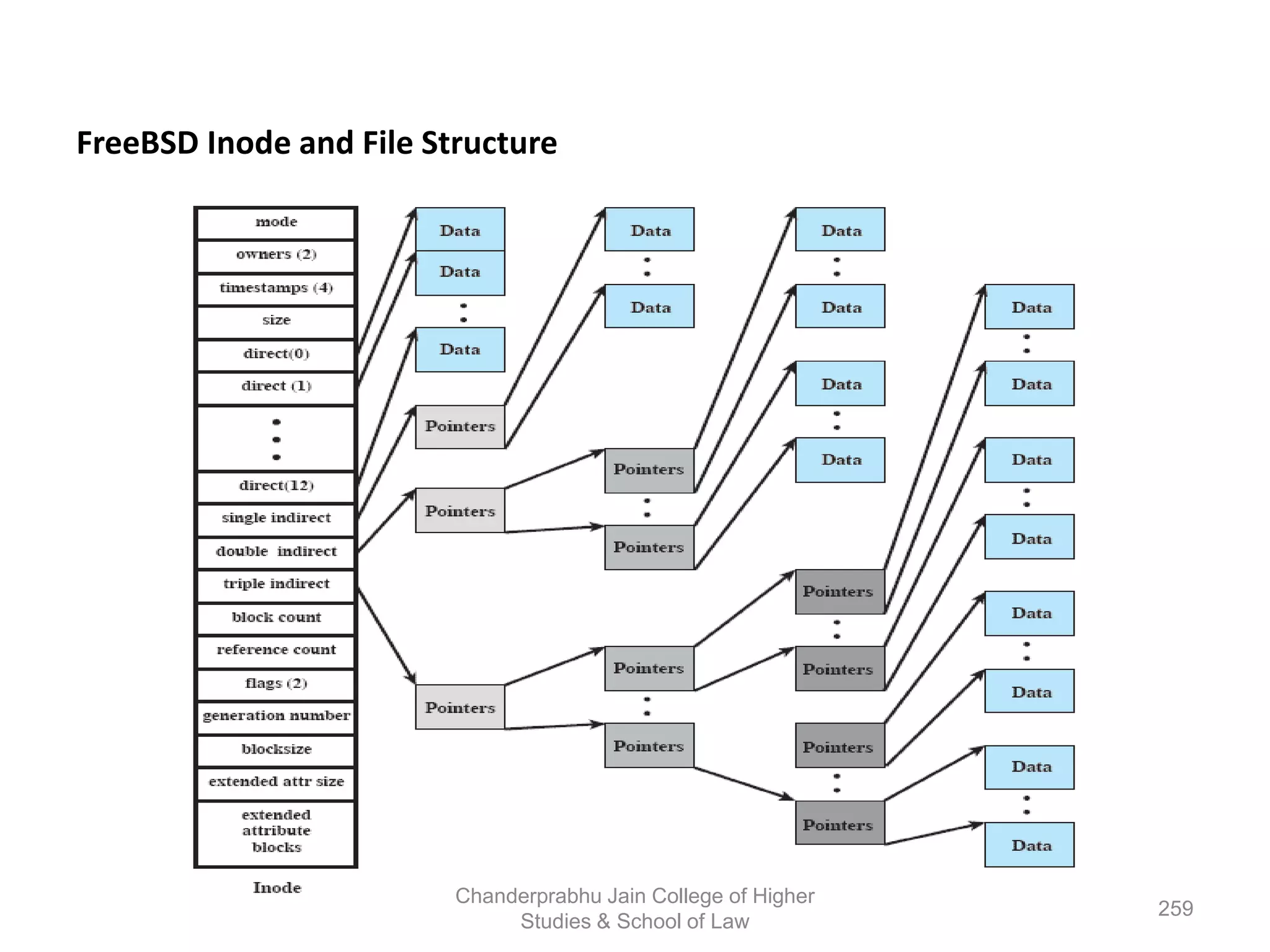
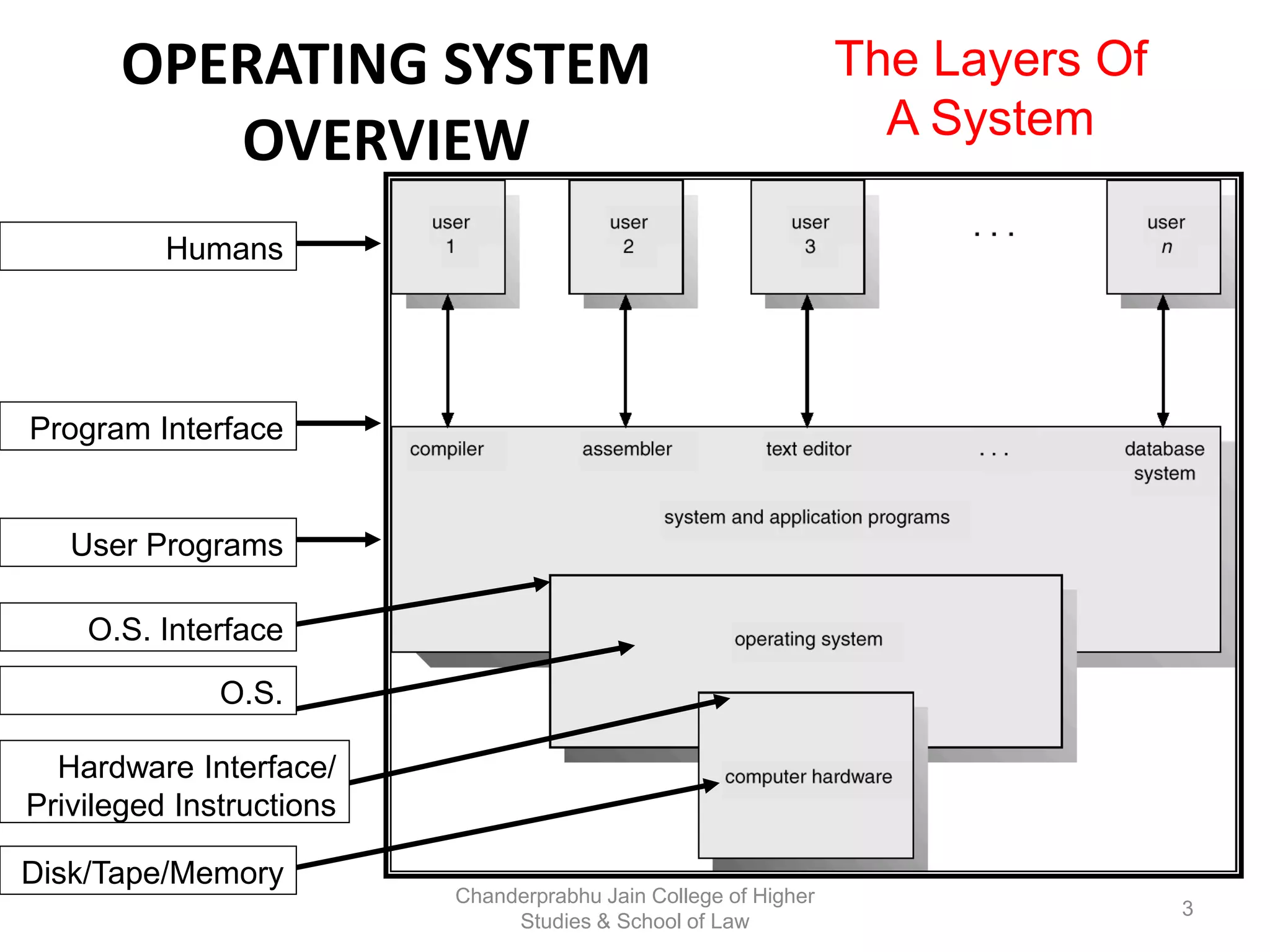
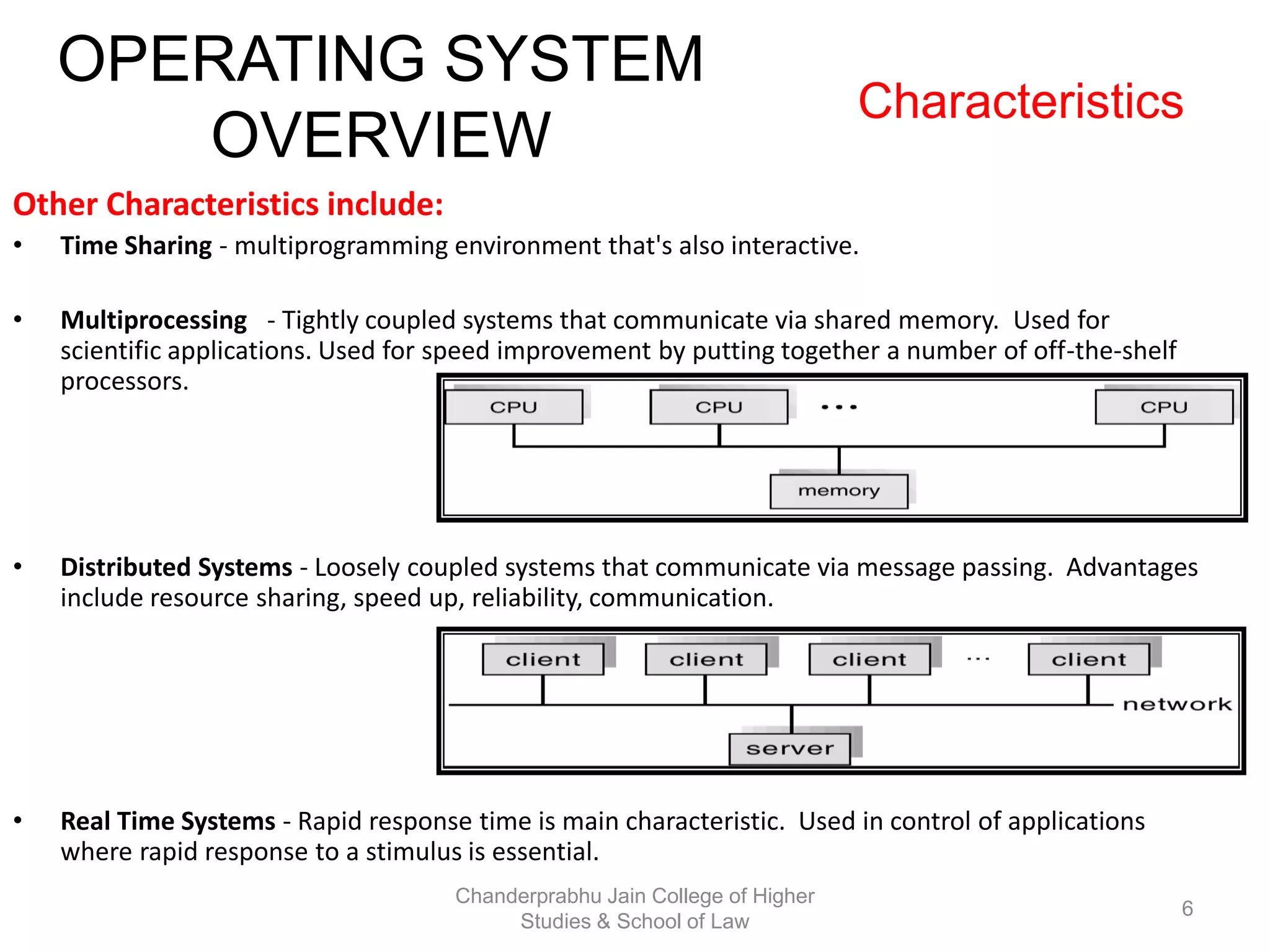
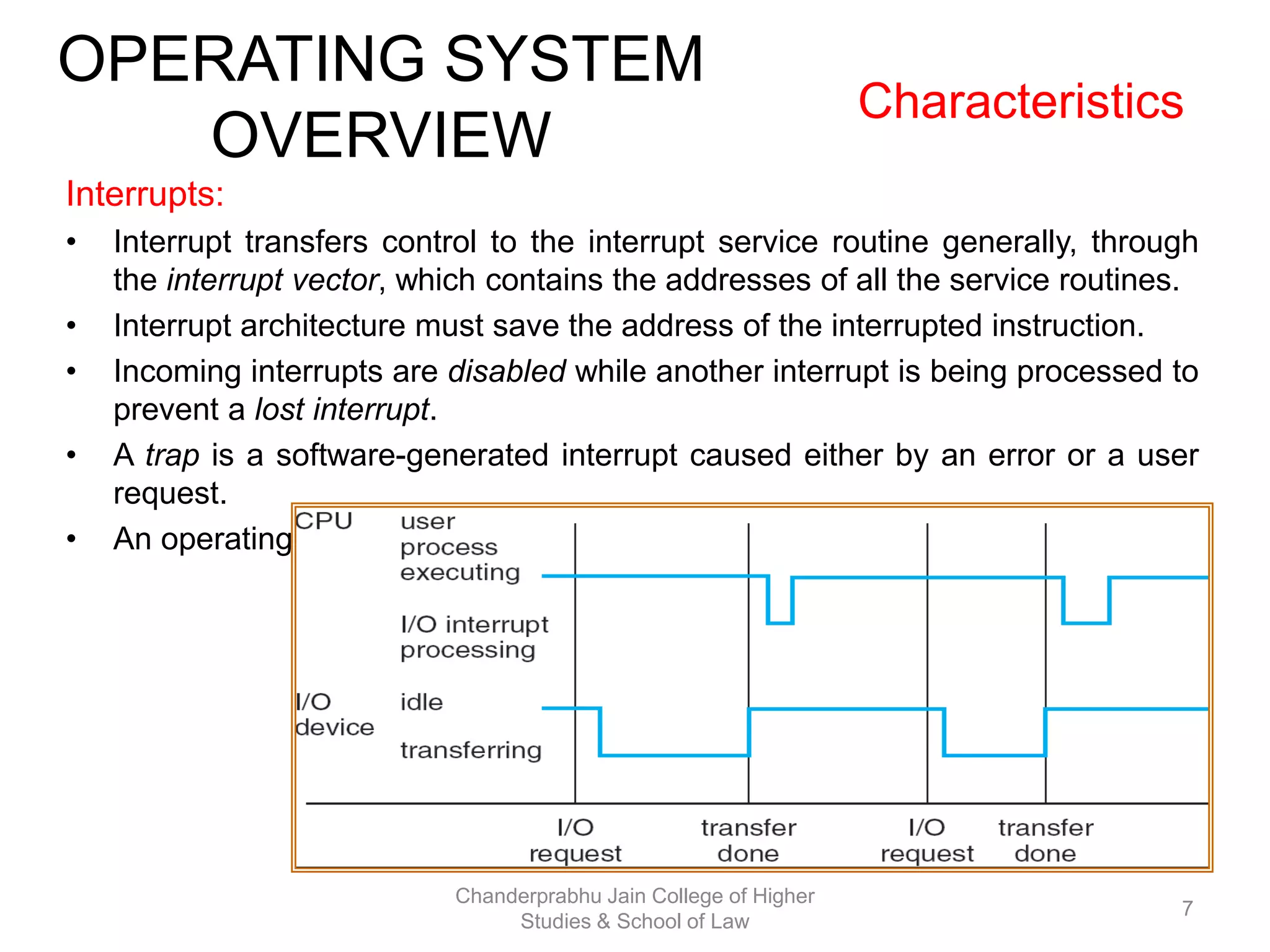
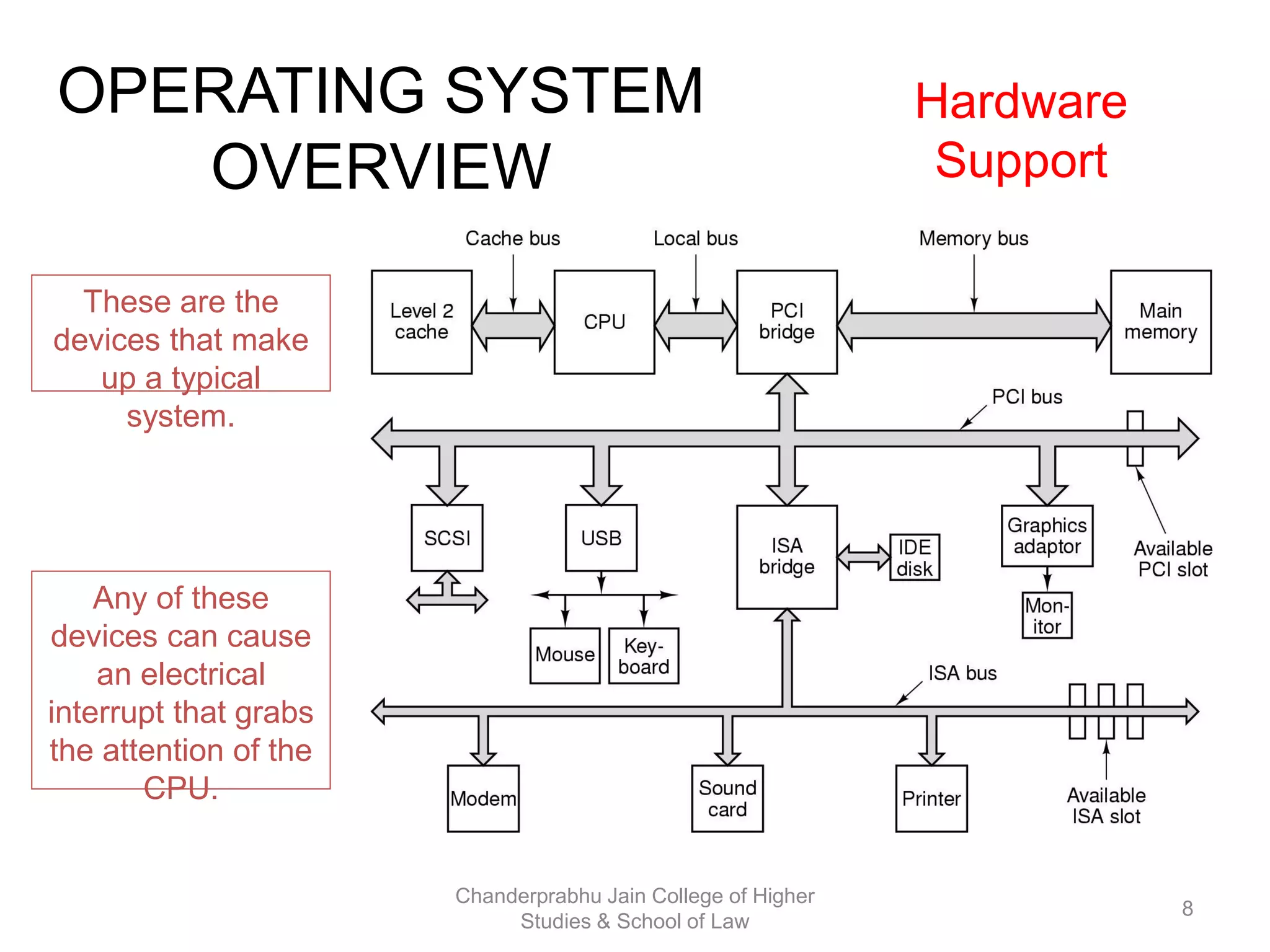
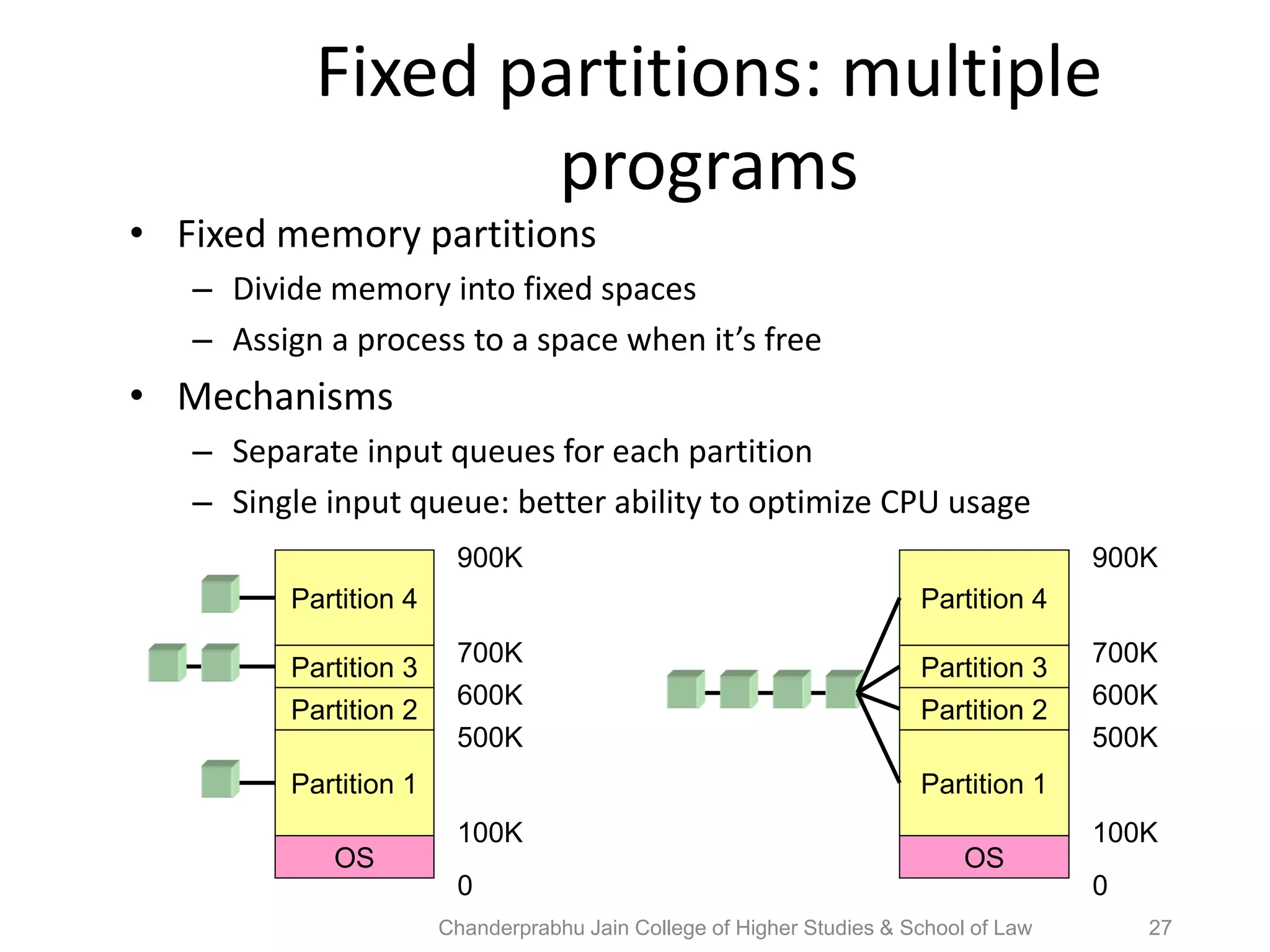
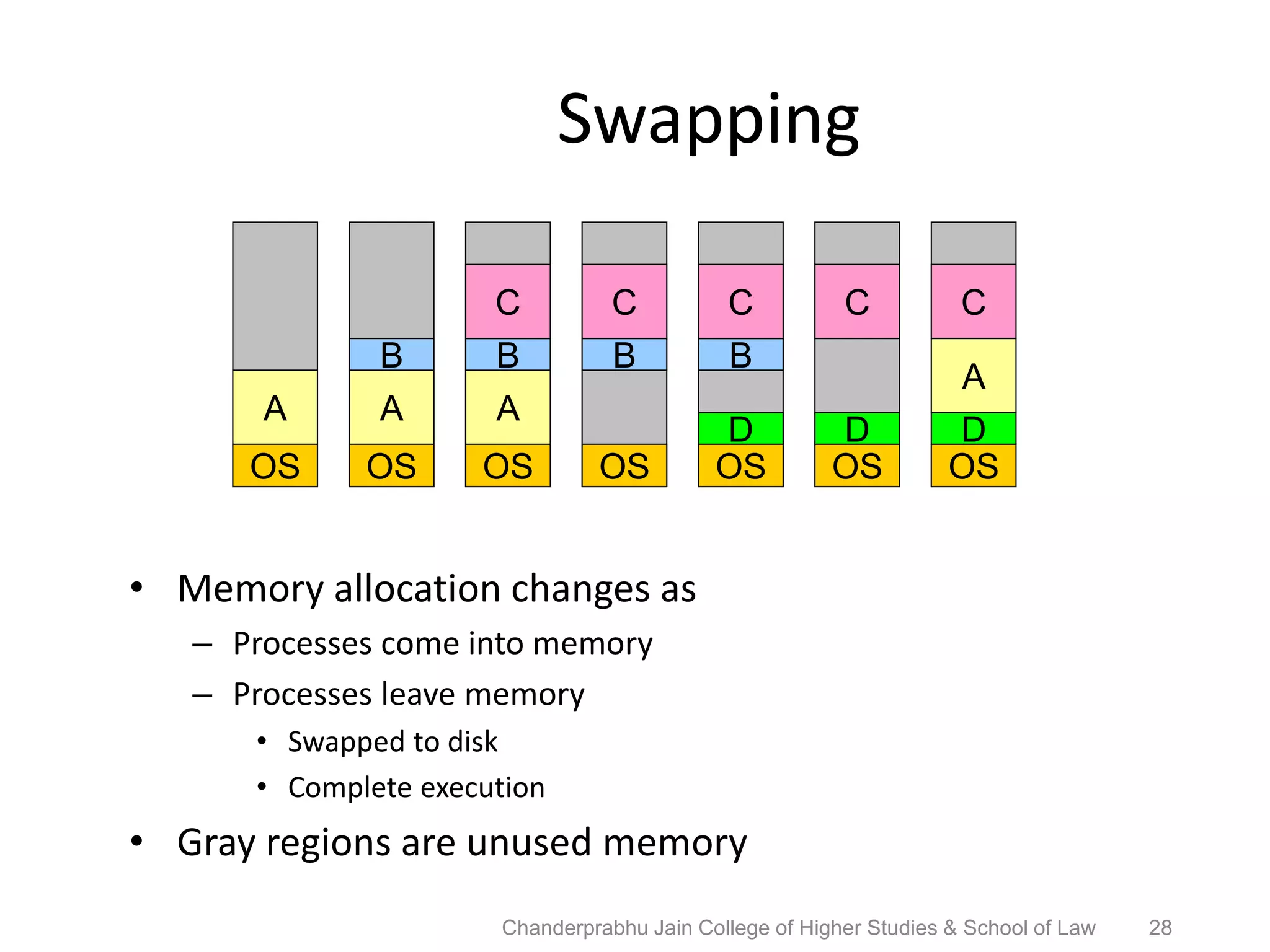
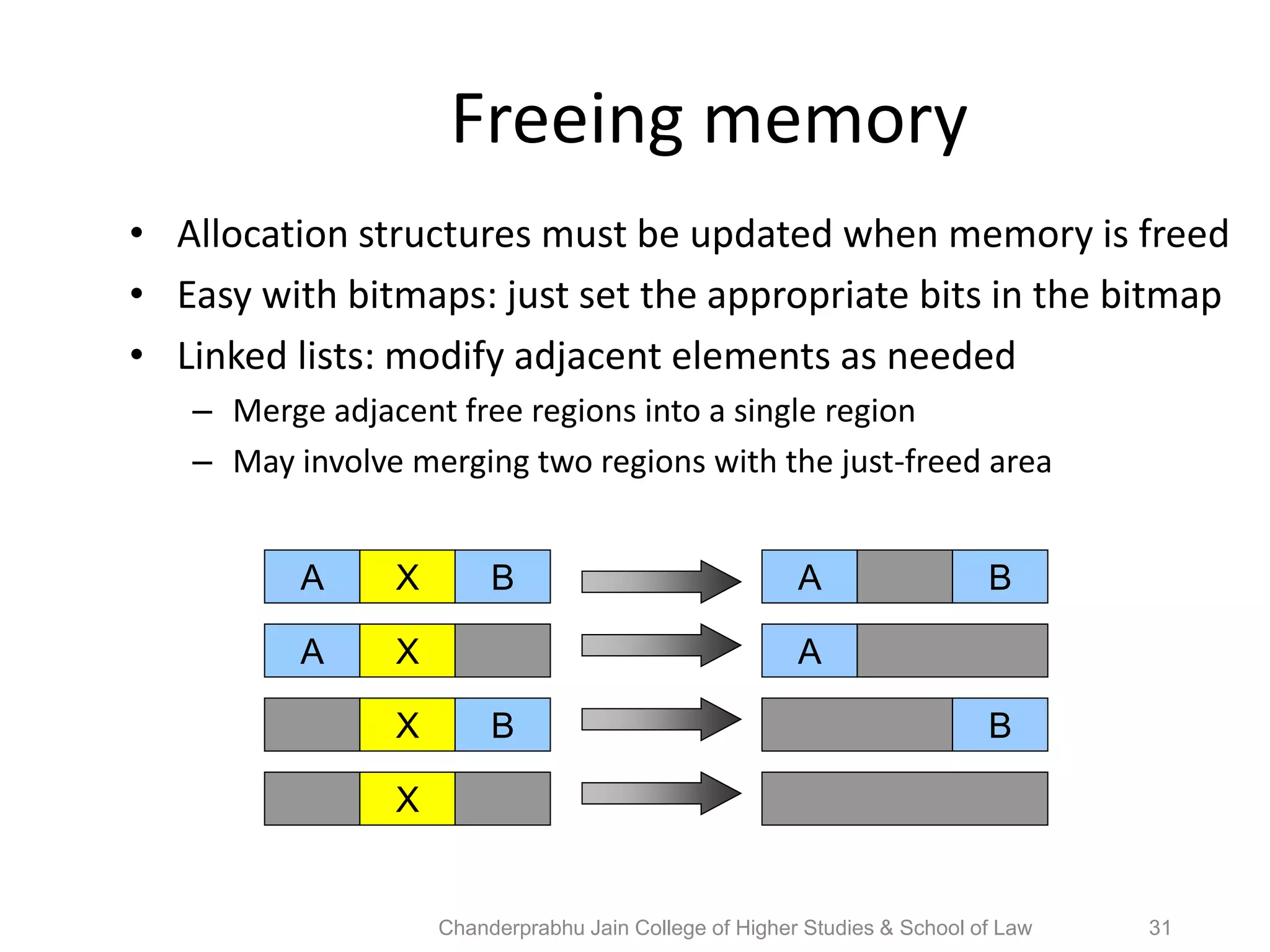
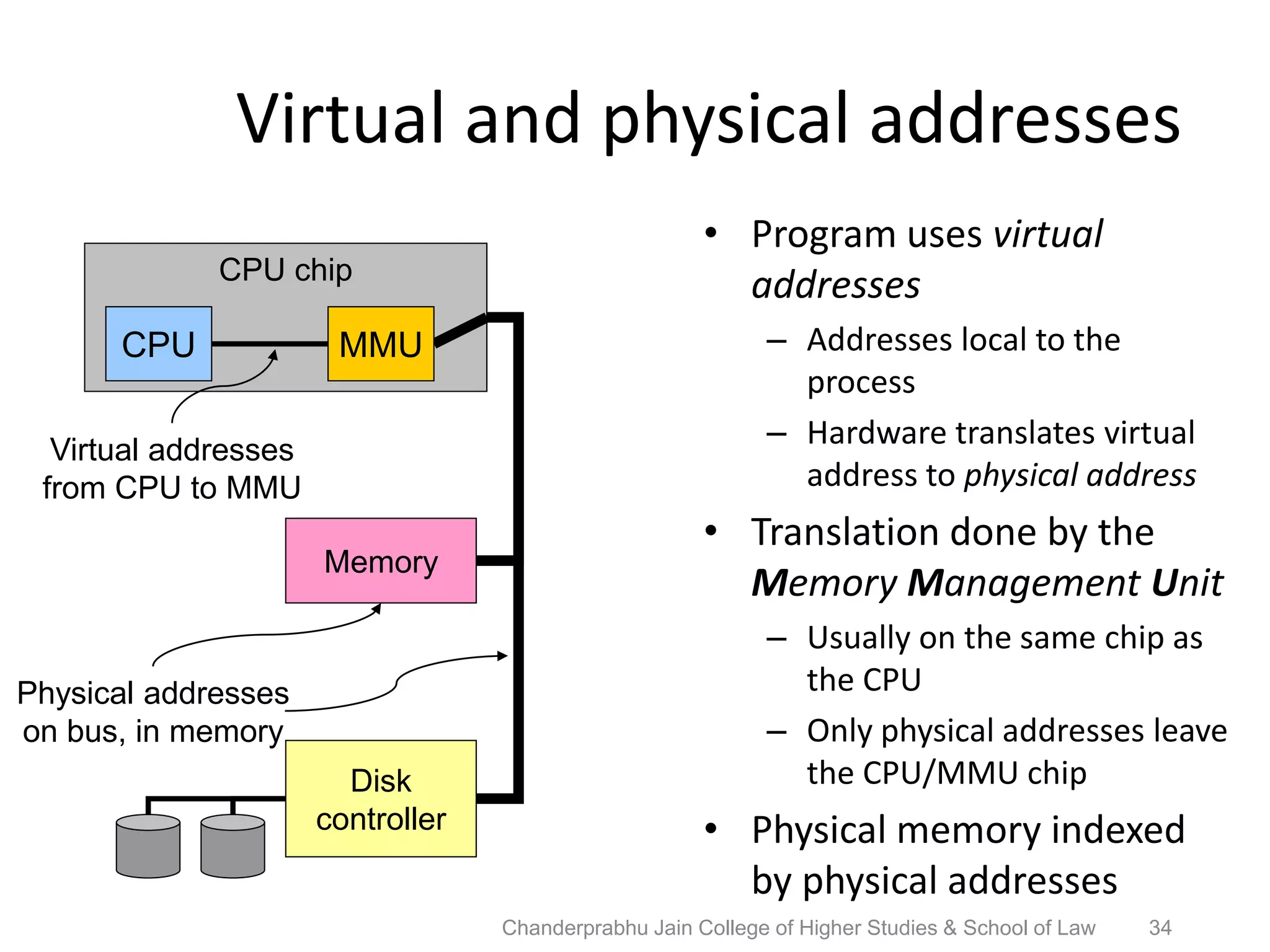
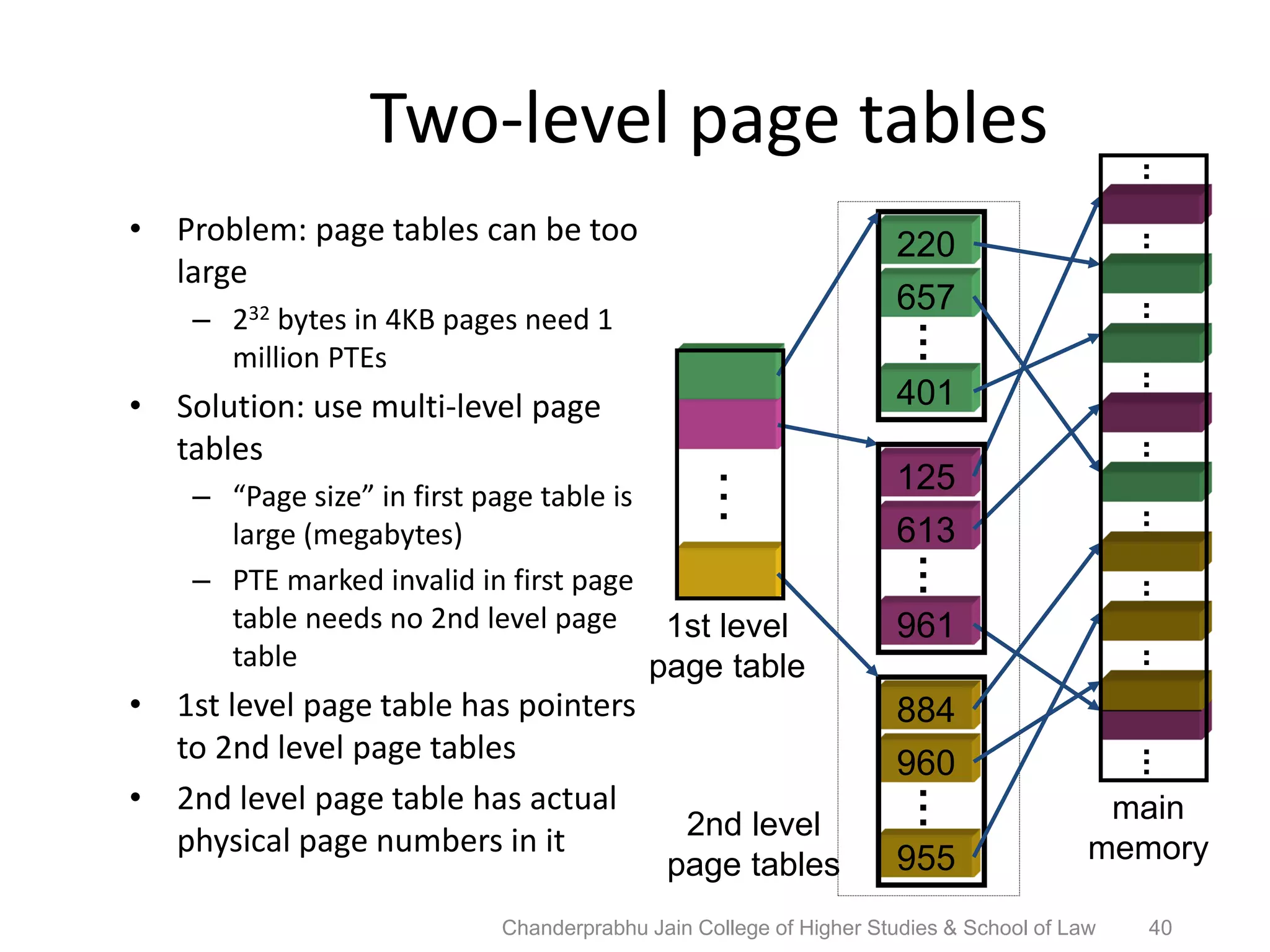
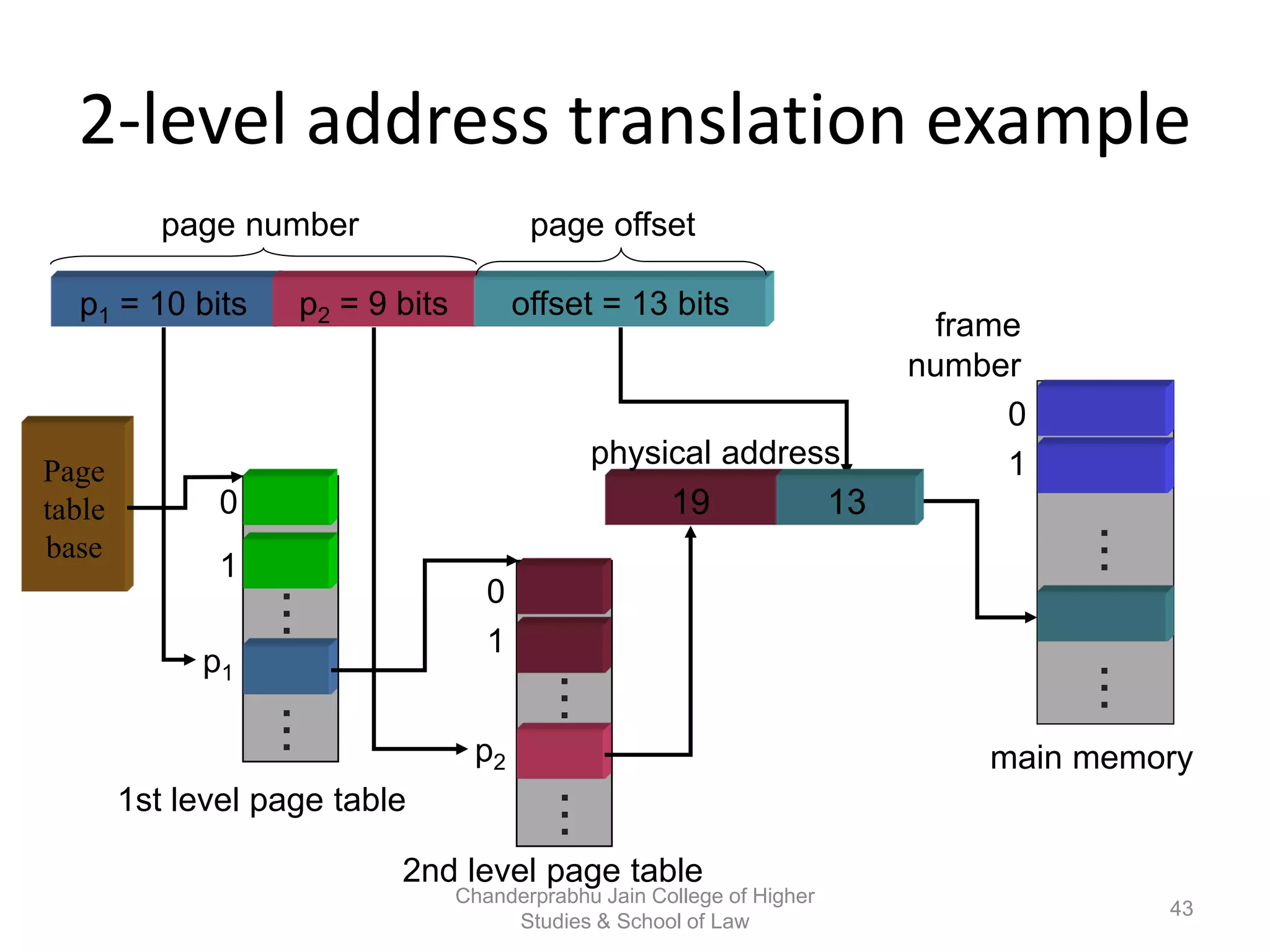
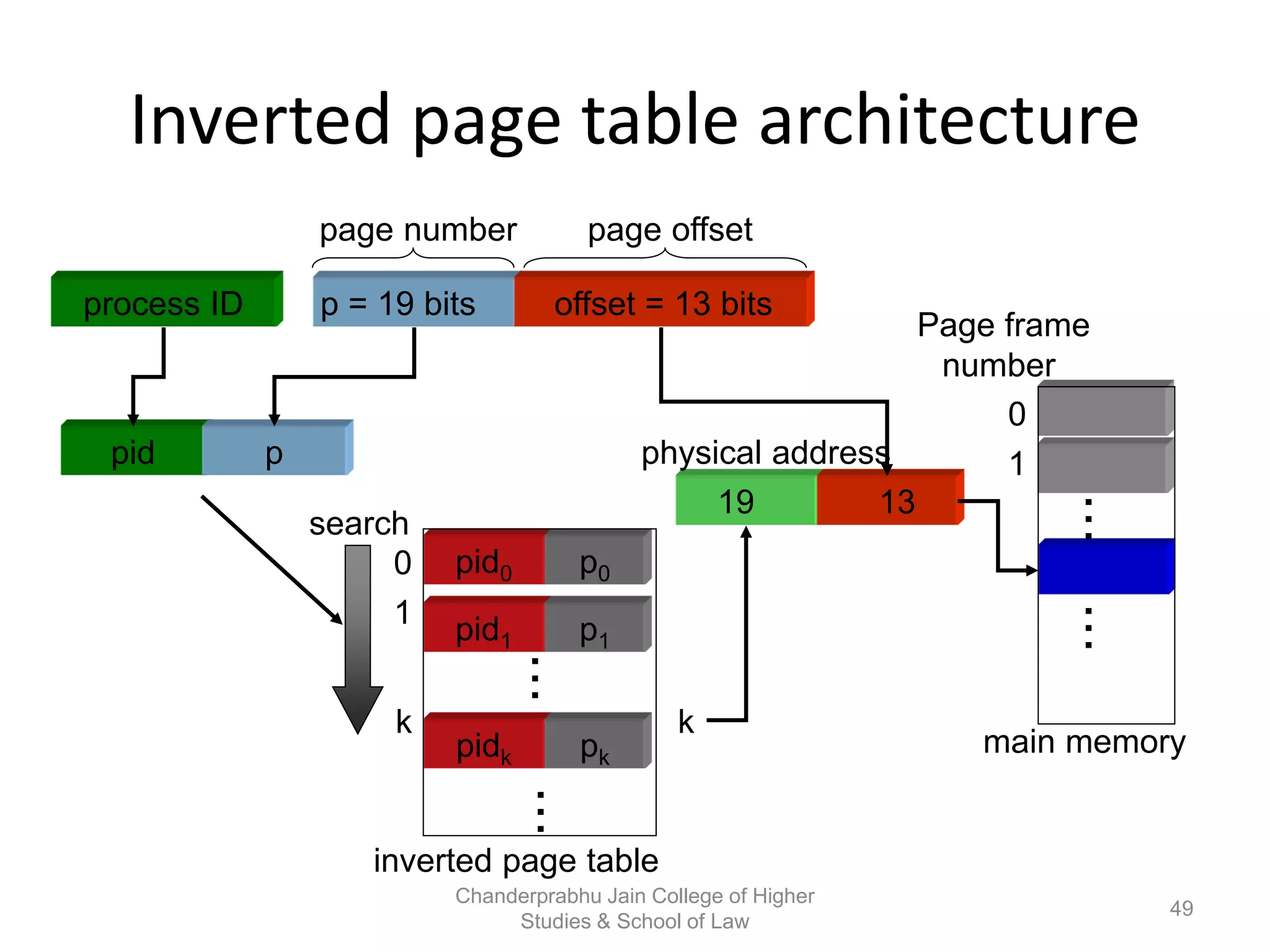
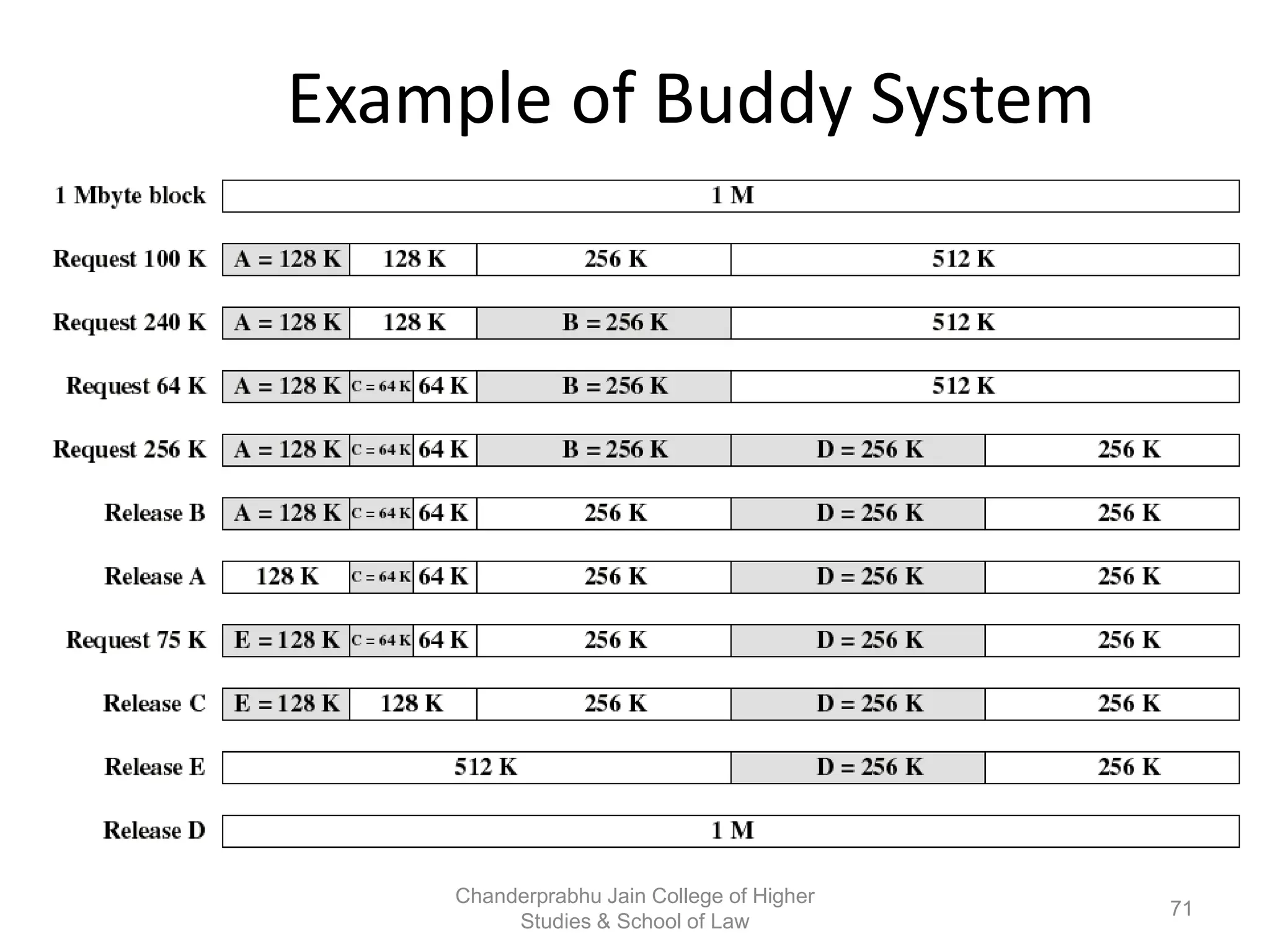
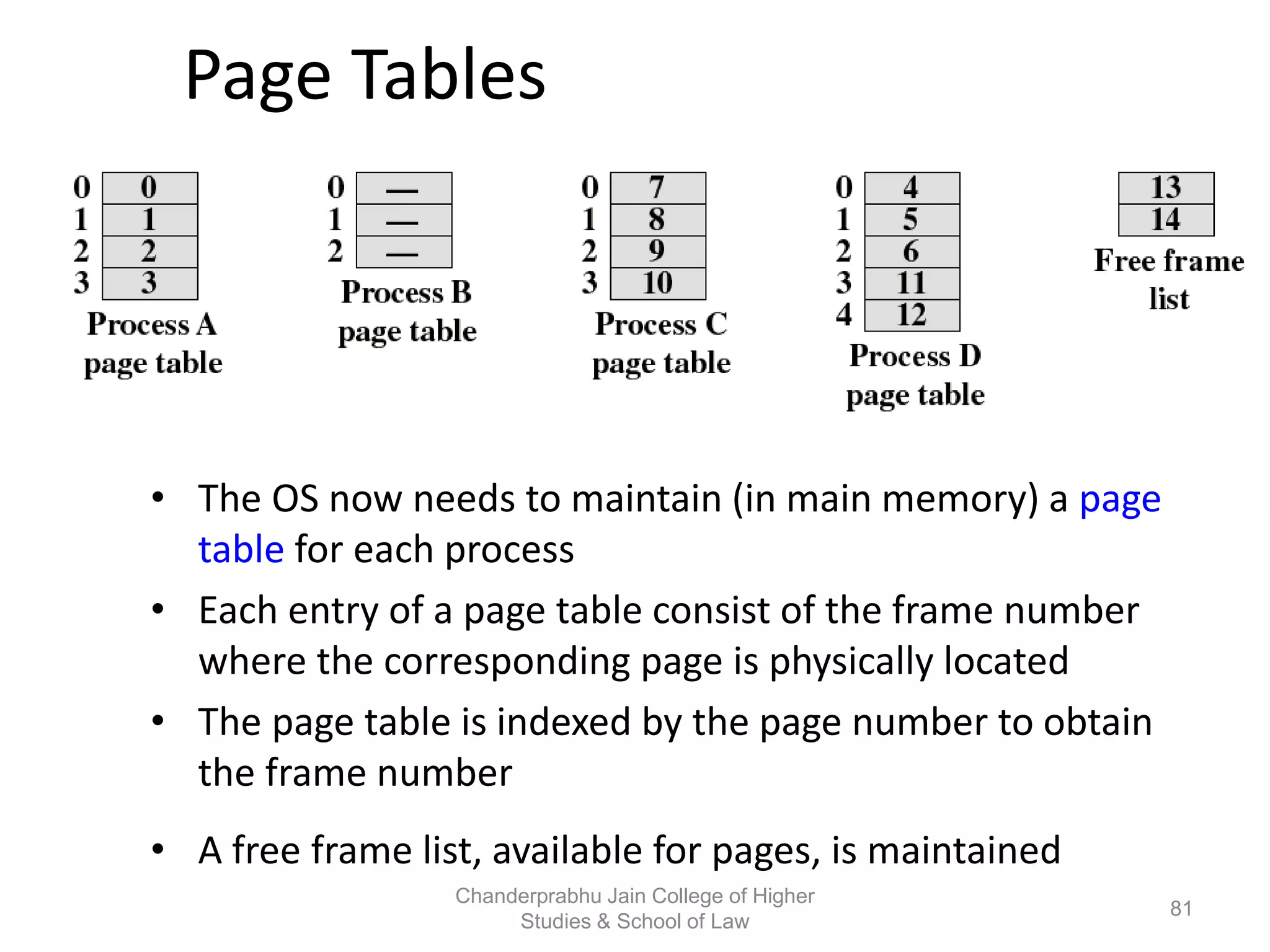
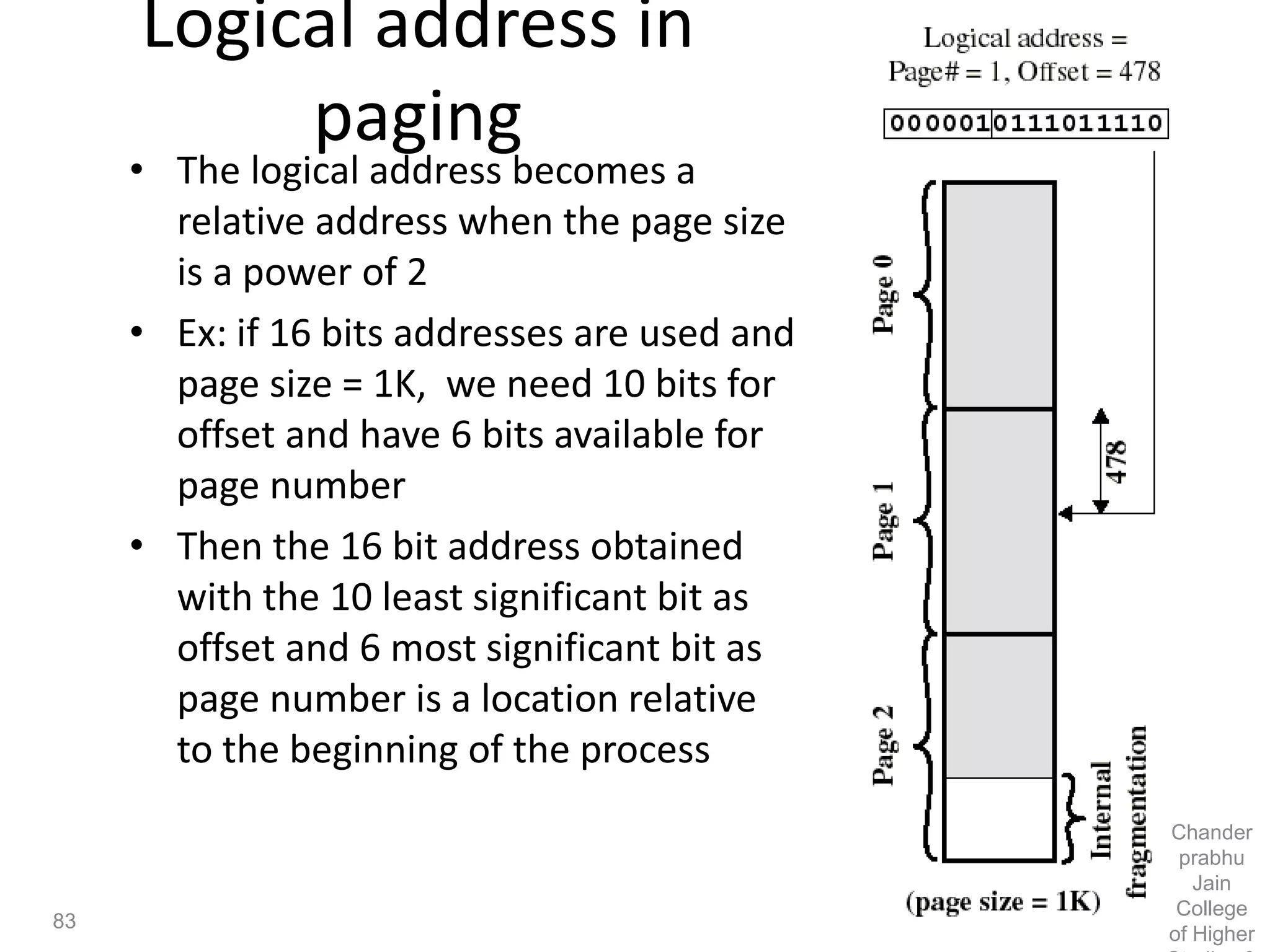
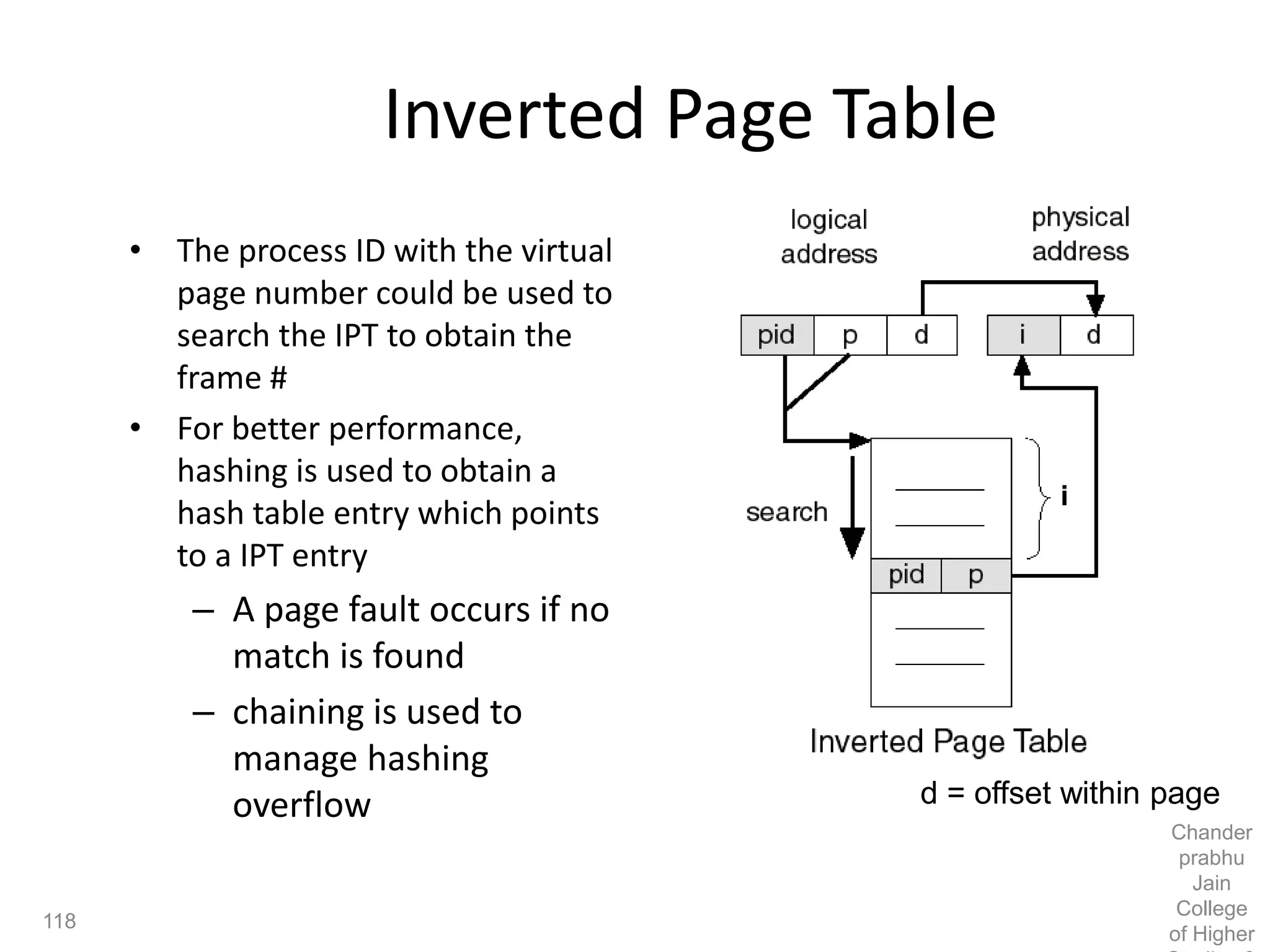
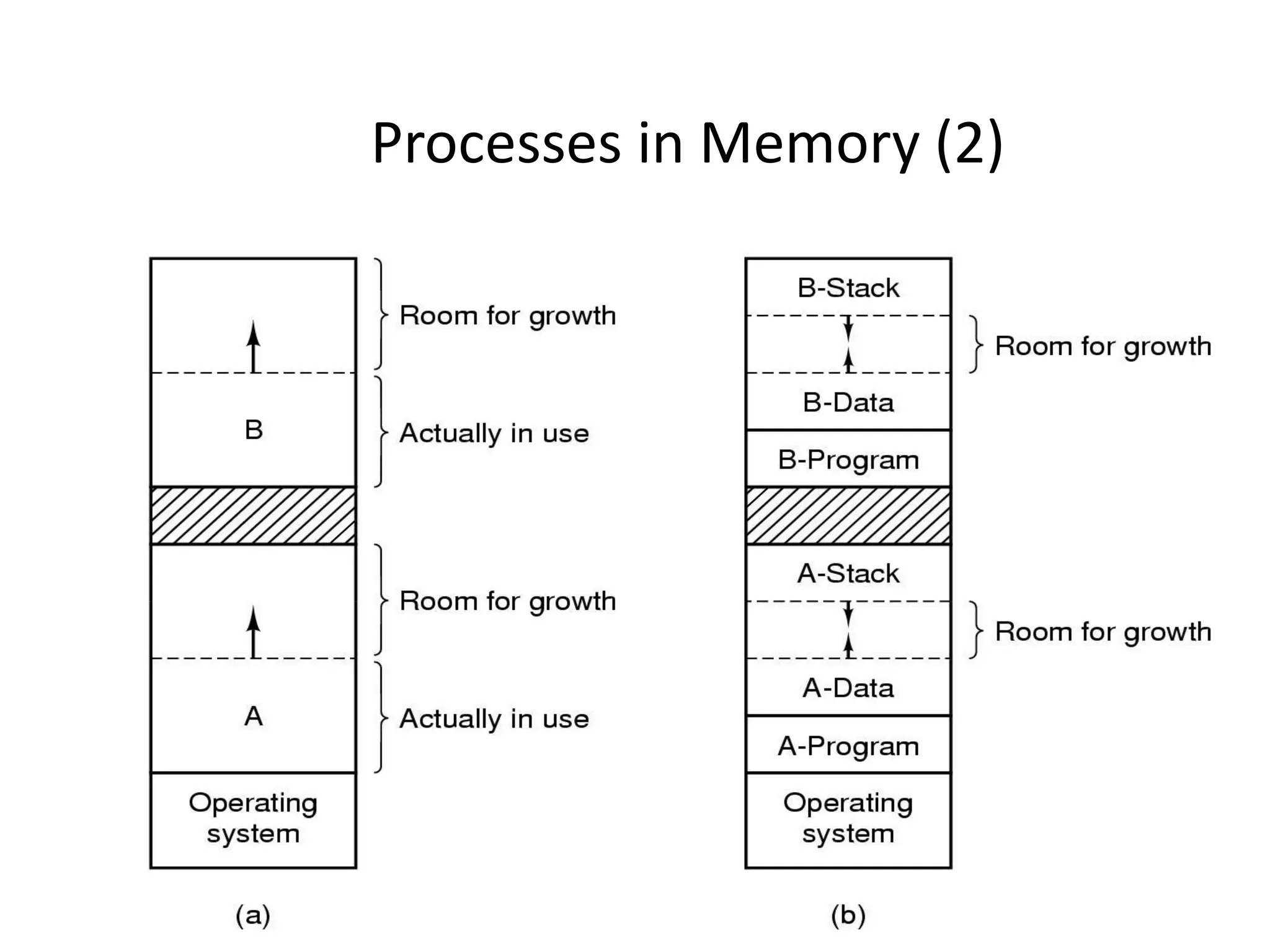
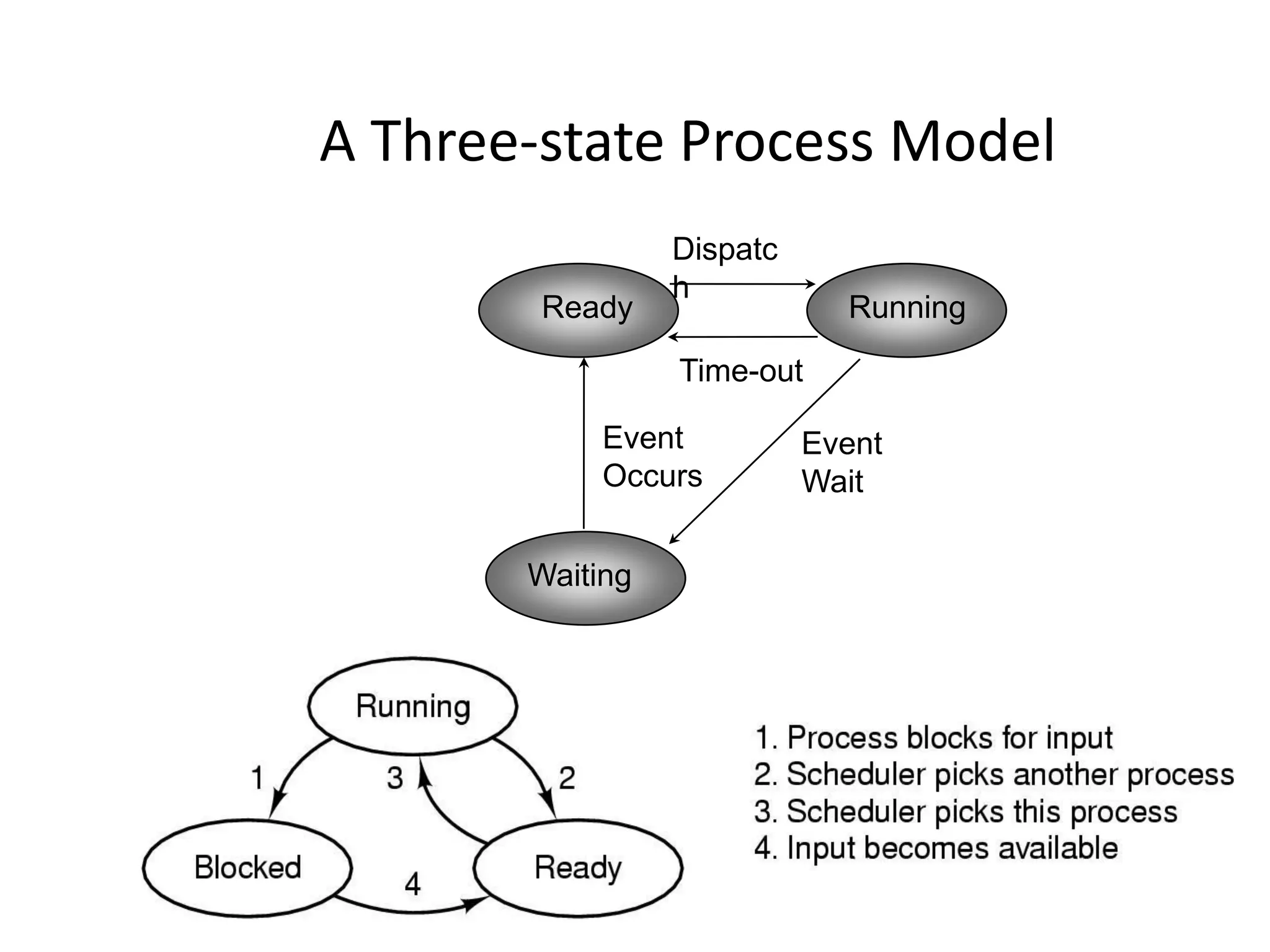
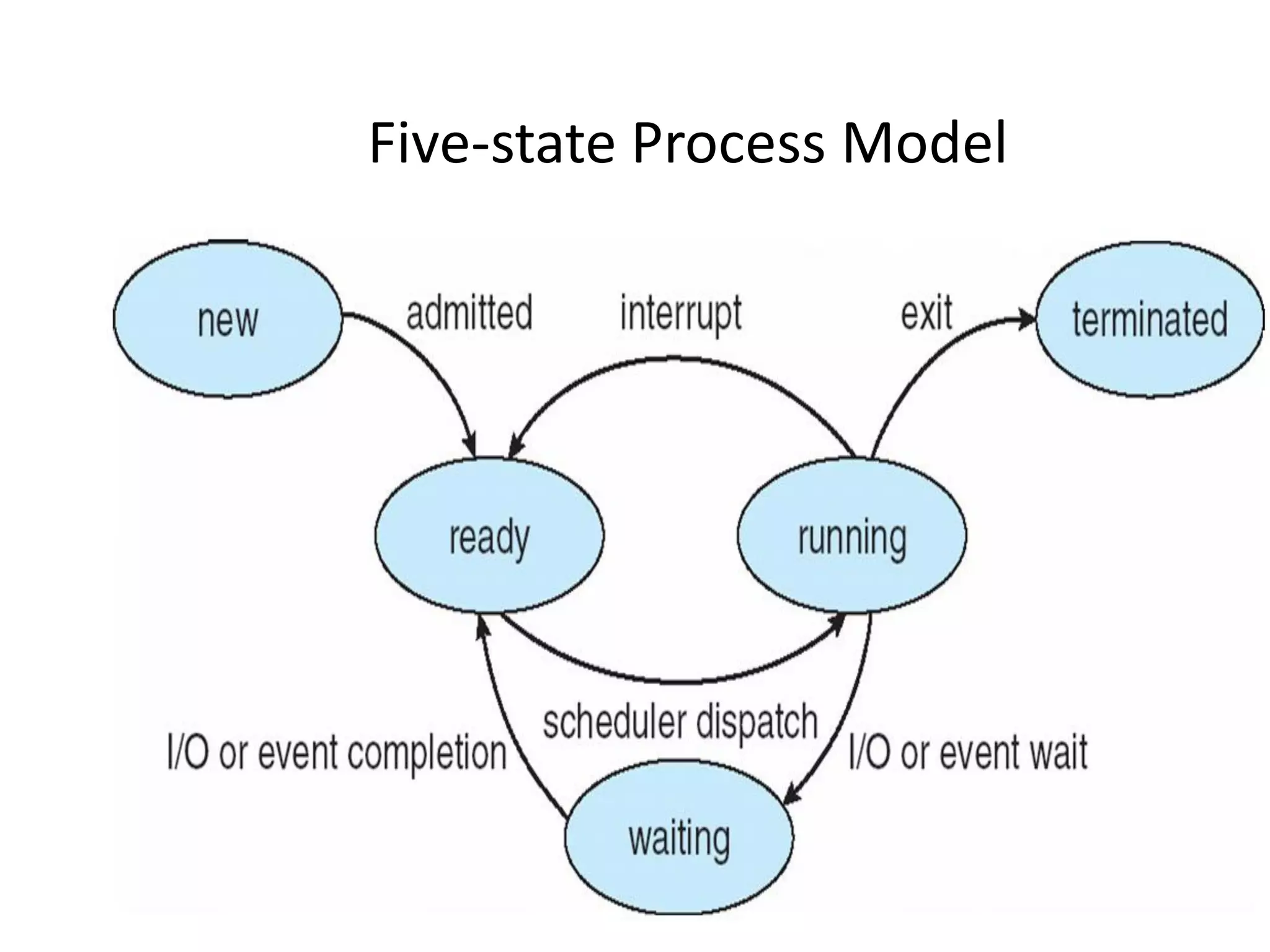
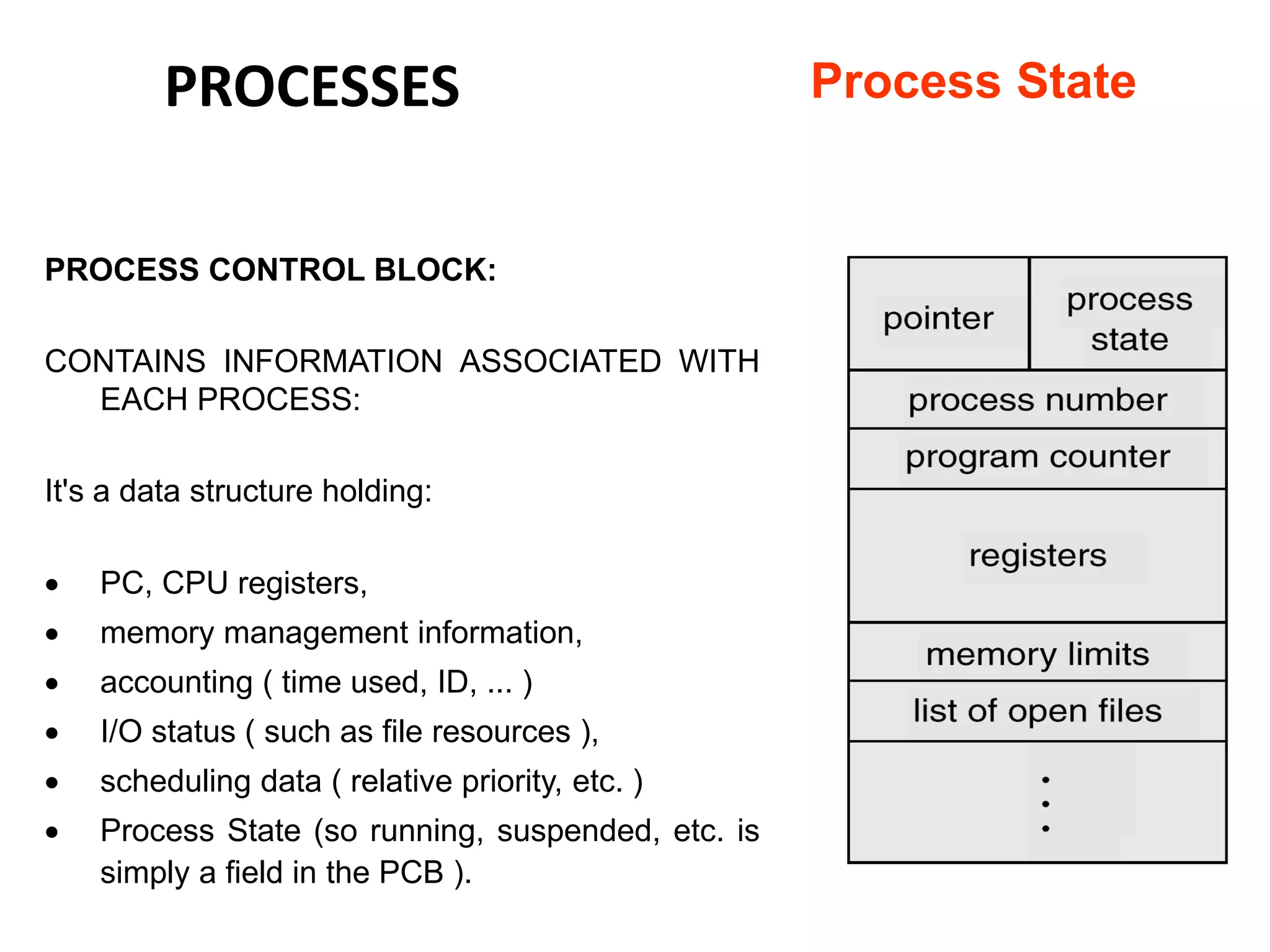
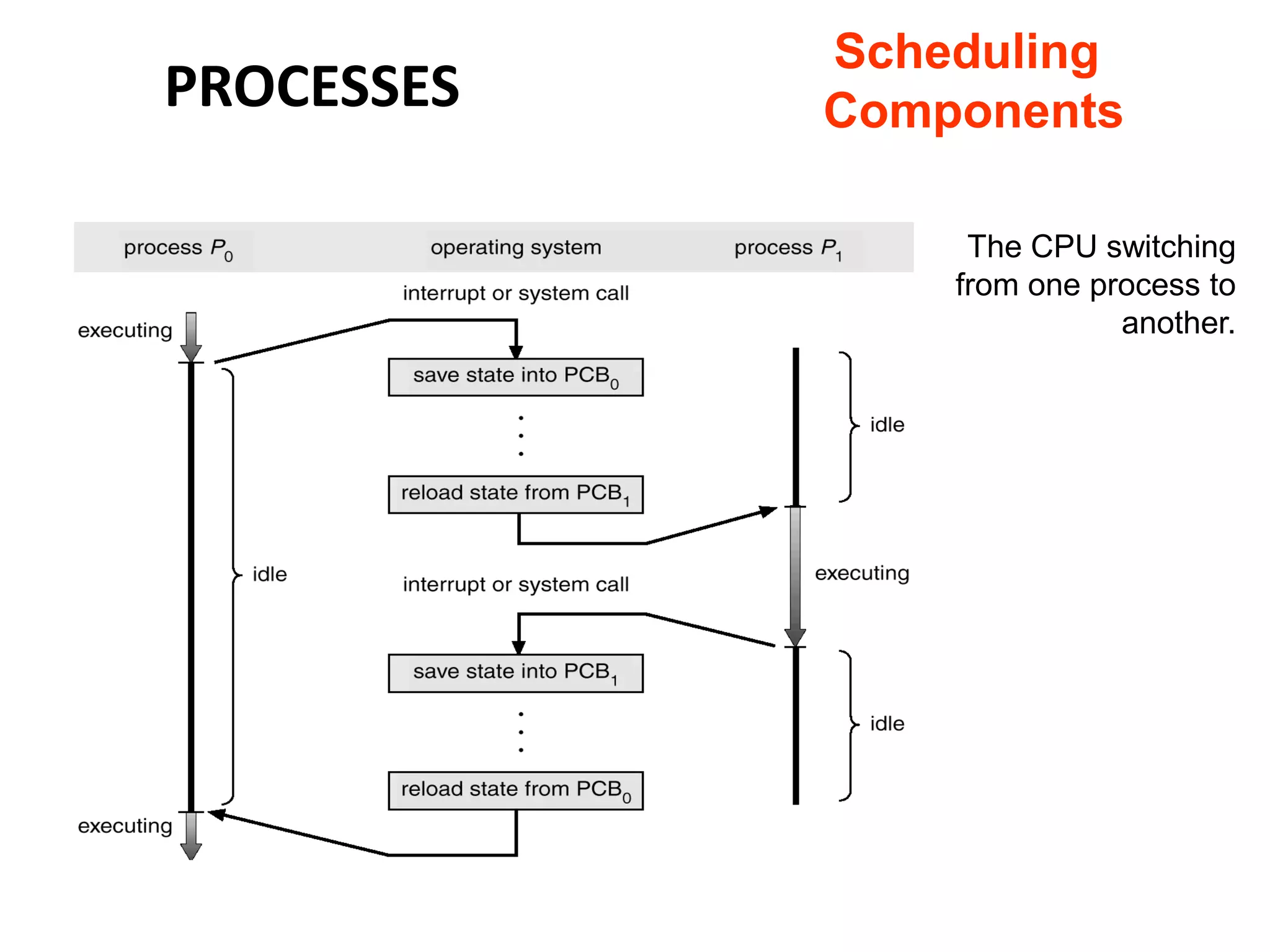
The document provides an overview of operating systems, detailing their role as interfaces between users and hardware, components like CPU scheduling, memory management, and resource allocation. It describes various characteristics like multiprogramming, time-sharing, and real-time systems, as well as the necessity for evolution in response to changing hardware and user needs. Additionally, it covers topics such as job control language, error handling, and the principles of virtual memory and paging in memory management.
























































![Alternative Dispute Resolution (ADR) [LLB -309]](https://cdn.slidesharecdn.com/ss_thumbnails/pptadr-201112101023-thumbnail.jpg?width=640&height=640&fit=bounds)




![Women and Law [LLB 409 (c)]](https://cdn.slidesharecdn.com/ss_thumbnails/pptwomenandlaw-201107184654-thumbnail.jpg?width=640&height=640&fit=bounds)

























