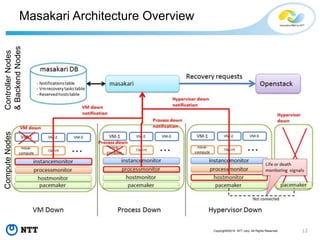
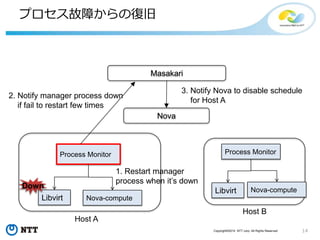
#13 This is quick architecture overview of Masakari.
Masakari is roughly divided to 2 parts.
One is Masakari controller presented in light blue box at top of the slide. Another is state monitoring processes displayed in the boxes at bottom of the slide.
The controller process is in charge of calling OpenStack API depending on the type of notification from monitoring processes.
The monitoring processes are monitoring whether each type of error Masakari want to detect occurs or not.
In following slides, I’ll present you how each monitoring process is monitoring different errors.
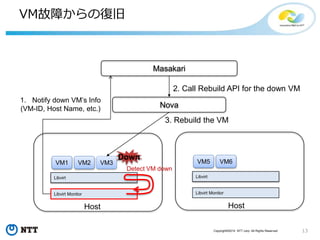
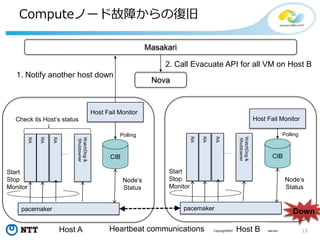
#17 I show you a quick instruction of Masakari.
Before setting up Masakari, there are 2 prerequisites,
Masakari assumes Compute Node uses KVM as its virtualizing technology and shares storages for ephemeral disks, NFS or ceph.
2.


![2Copyright©2015 NTT corp. All Rights Reserved.
仮想マシンHA機能とは,
仮想マシンの高可用性を実現
仮想マシン(VM)故障時に、オペレータを介さずに自動復旧する機
能を提供する.
仮想マシンHA機能の必要性
• PET VMの存在
[1]
• すべてのアプリケーションはクラウドネイティブではない
• 仮想マシンの高可用性を実現させるためのOSS
[1] http://www.slideshare.net/randybias/pets-vs-cattle-the-elastic-cloud-story
http://www.theregister.co.uk/2013/03/18/servers_pets_or_cattle_cern/](https://image.slidesharecdn.com/openstack-instanceha20160618r5-160629050006/85/openstack-HA-2-320.jpg)
![3Copyright©2015 NTT corp. All Rights Reserved.
仮想マシンHAの要件
仮想マシンHAのuser storyについてコミュニティで議論しています.[2]
[2] http://specs.openstack.org/openstack/openstack-user-stories/user-stories/proposed/ha_vm.html
運用:
• Capacity Reservation
仮想マシンを復旧させるために、必要
な空き容量を常に確保
• Host Maintenance
計画メンテナンスなどを行う際に
仮想マシンHA機能を無効化
• Event History
過去のイベント履歴など
故障検知:
• Computeノード故障
• プロセス故障
qemu-kvmプロセス故障(VM crashes)
nova-computeプロセスの異常
• VM故障
I/O errorなど
• その他の故障
Network component fails
AZ, DC, Region failure
• 仮想マシンが故障から自動的に復旧する
• VM毎に仮想マシンHA機能を設定可能](https://image.slidesharecdn.com/openstack-instanceha20160618r5-160629050006/85/openstack-HA-3-320.jpg)
![4Copyright©2015 NTT corp. All Rights Reserved.
Openstack HA Team
Andrew Beekhof
@REDHAT
Ken Gaillot
@REDHAT
Michele Baldessari
@REDHAT
Adam Spiers
@SUSE
Dawid Deja
@Intel
主なメンバー
NTT Group
SIC: Sampath Priyankara, Masahito Muroi, Toshikazu Ichikawa
NTT Data: Takashi Kajinami
NTT Data Inc: Tushar Patil
Team情報
ML: openstack-dev@lists.openstack.org subject: [openstack-dev] [HA]
IRC: http://eavesdrop.openstack.org/#High_Availability_Meeting
ミーティング時間:
毎週の月曜日 17:00 JST
相談・雑談: #openstack-ha](https://image.slidesharecdn.com/openstack-instanceha20160618r5-160629050006/85/openstack-HA-4-320.jpg)



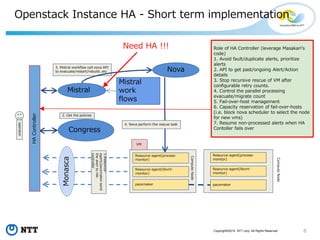
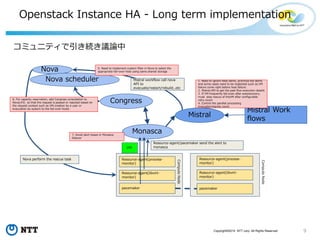
![10Copyright©2015 NTT corp. All Rights Reserved.
コミュニティで引き続き議論
(1) Product Working Groupでの取り組み
High Availability for VMs
https://wiki.openstack.org/wiki/ProductTeam/User_Stories/HA_VMs
User story
http://specs.openstack.org/openstack/openstack-user-stories/user-
stories/proposed/ha_vm.html
Gerrit:
https://review.openstack.org/#/c/318431/
(2) Openstack HA Teamでの議論
ML: openstack-dev@lists.openstack.org subject: [openstack-dev] [HA]
IRC: http://eavesdrop.openstack.org/#High_Availability_Meeting
過去のログ: http://eavesdrop.openstack.org/meetings/ha/
ミーティング時間:
毎週の月曜日 17:00 JST
相談・雑談: #openstack-ha](https://image.slidesharecdn.com/openstack-instanceha20160618r5-160629050006/85/openstack-HA-10-320.jpg)






















































![[Interact 2018] 別視点からのハイパーコンバージドインフラ ~ ソフトウェアによる華麗な “ものづくり“ の世界](https://cdn.slidesharecdn.com/ss_thumbnails/interact2018ogawad-180703223547-thumbnail.jpg?width=640&height=640&fit=bounds)















