Downloaded 13 times




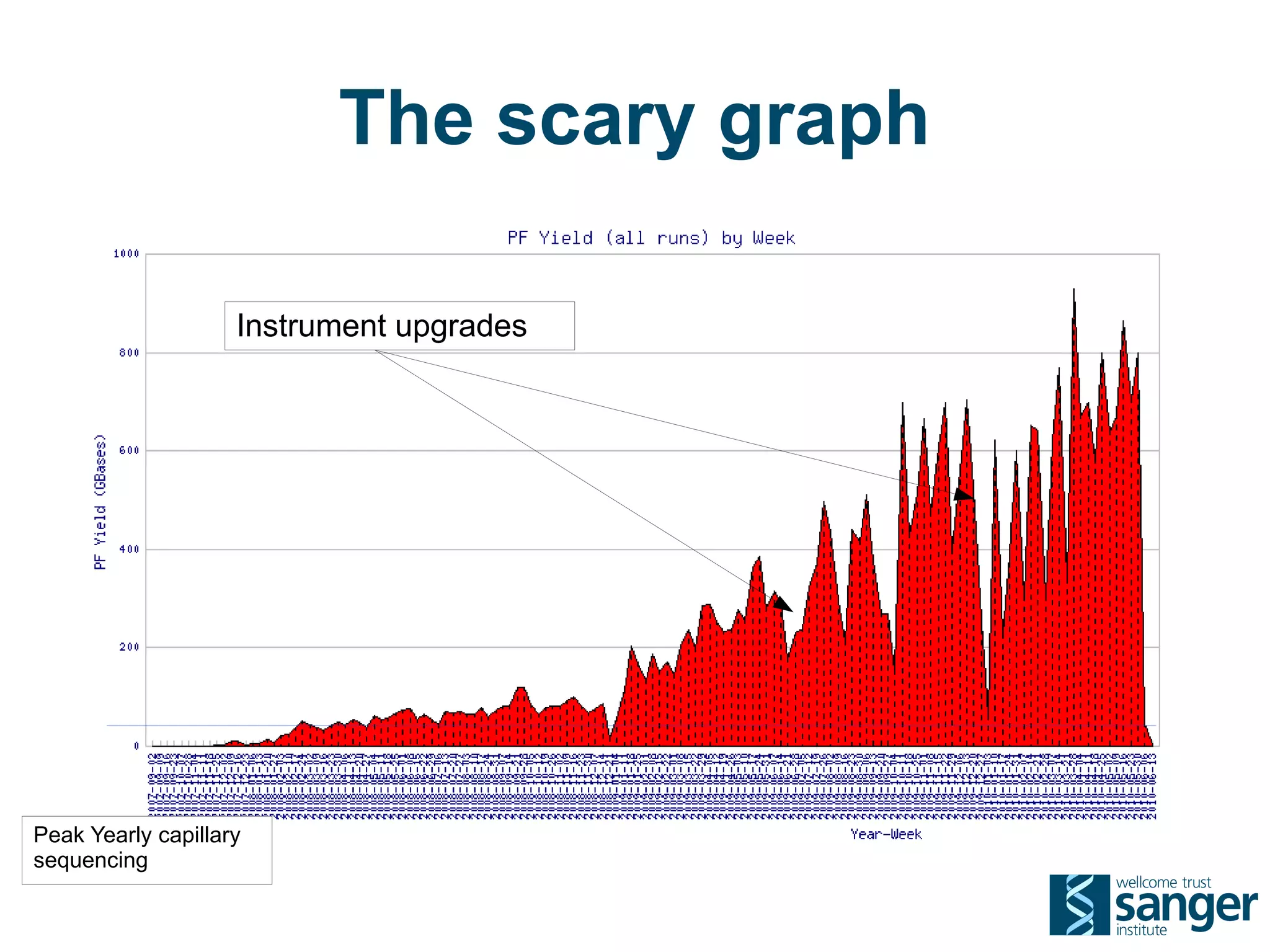
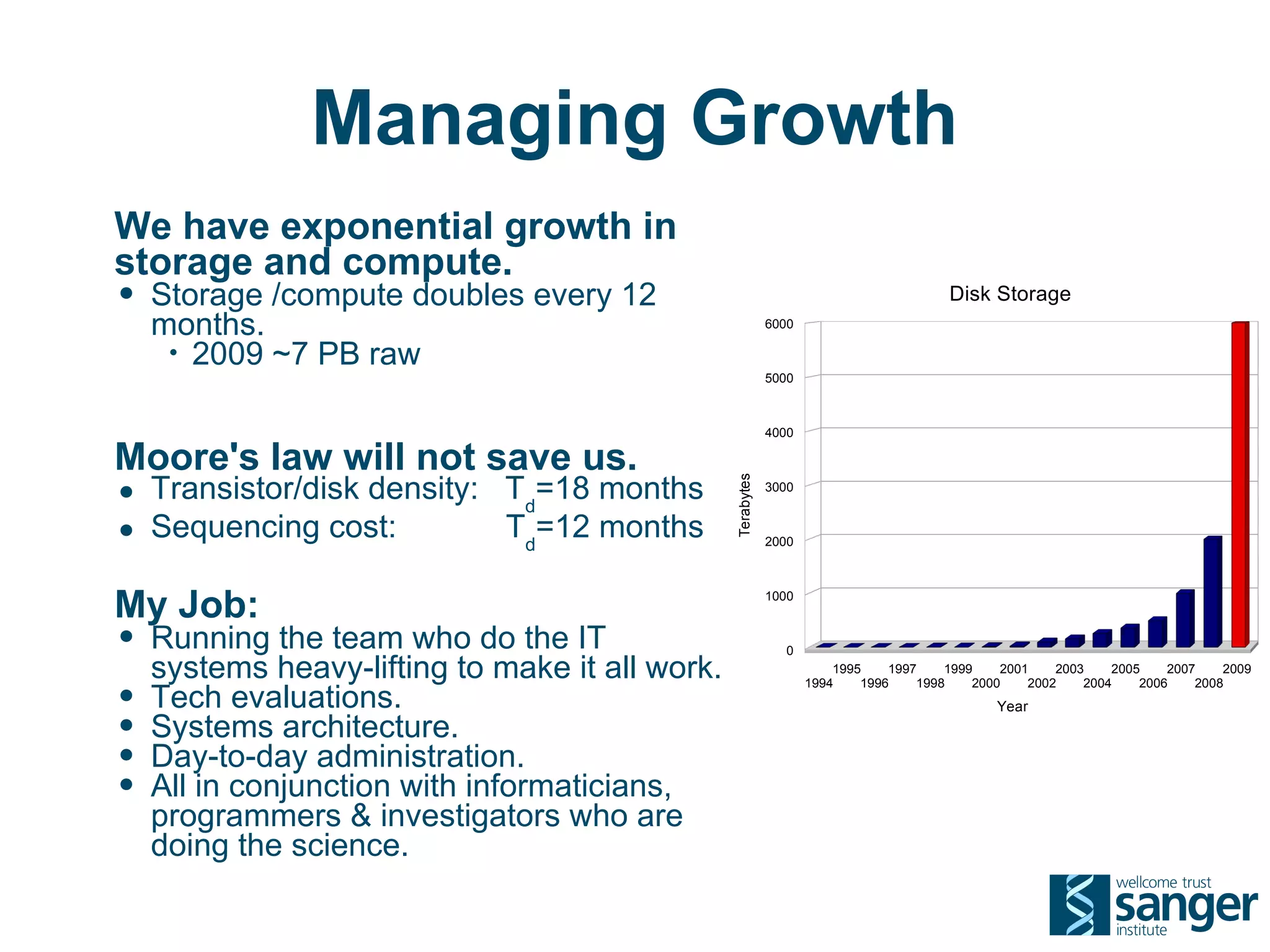


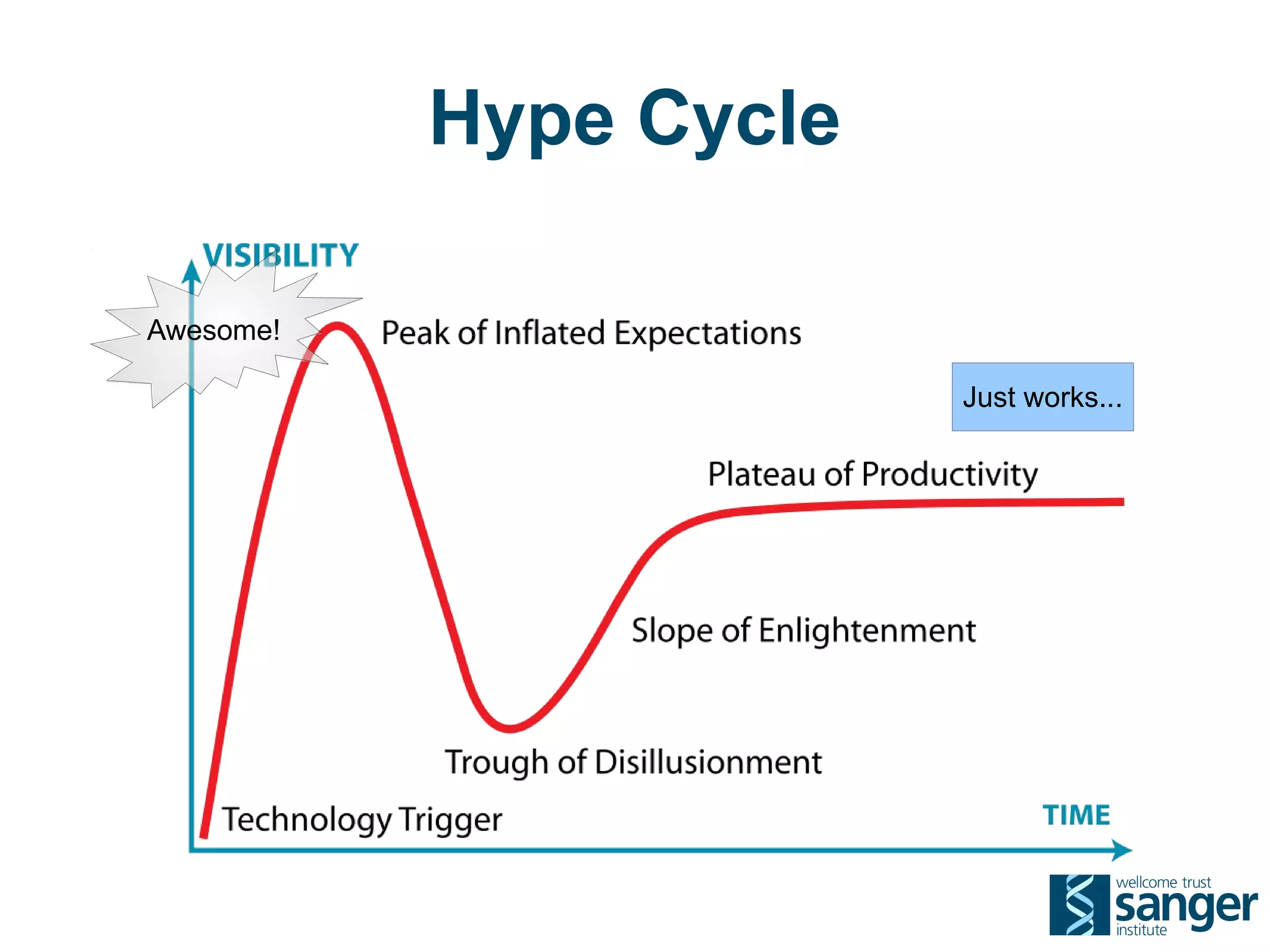







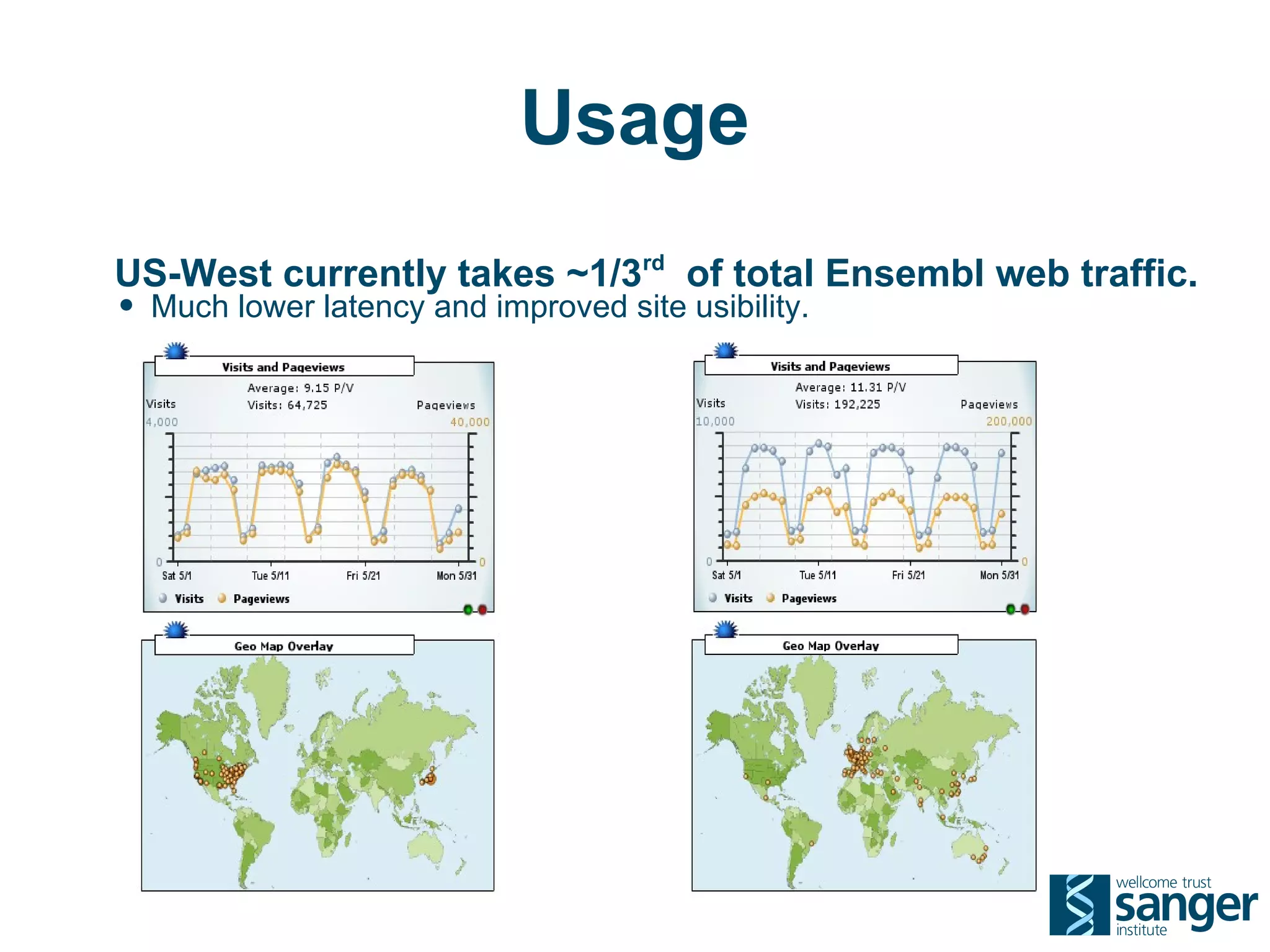












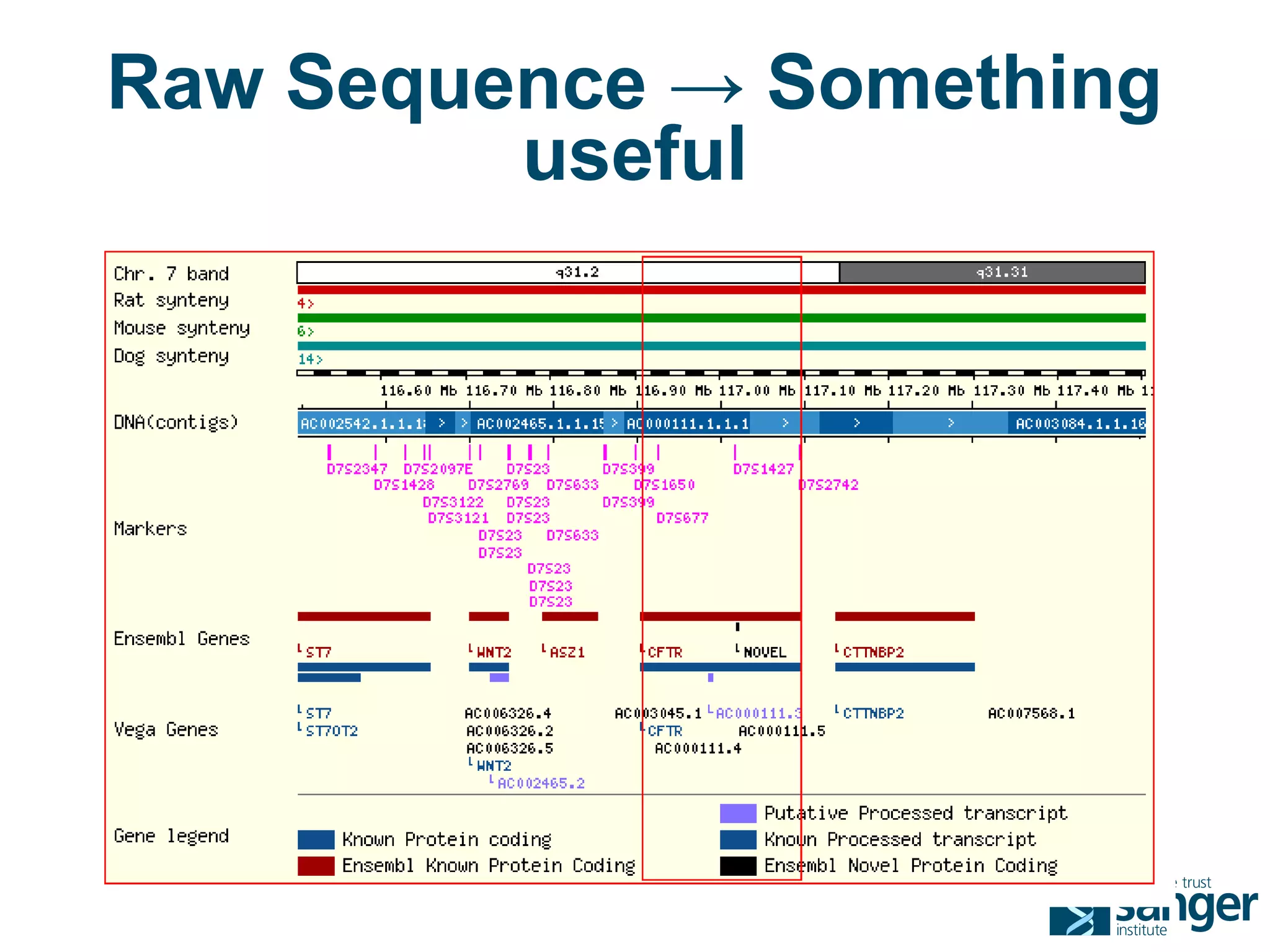

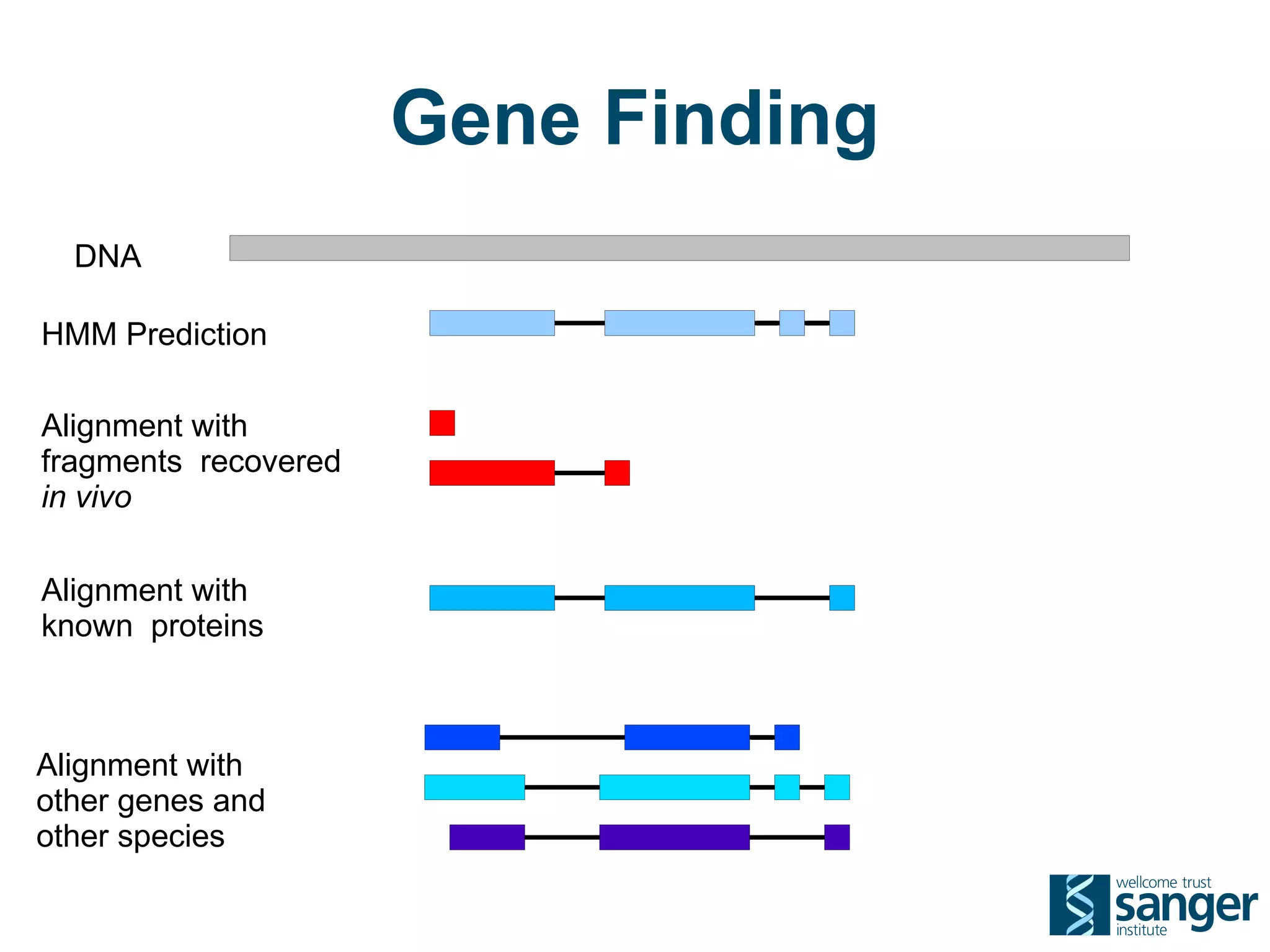
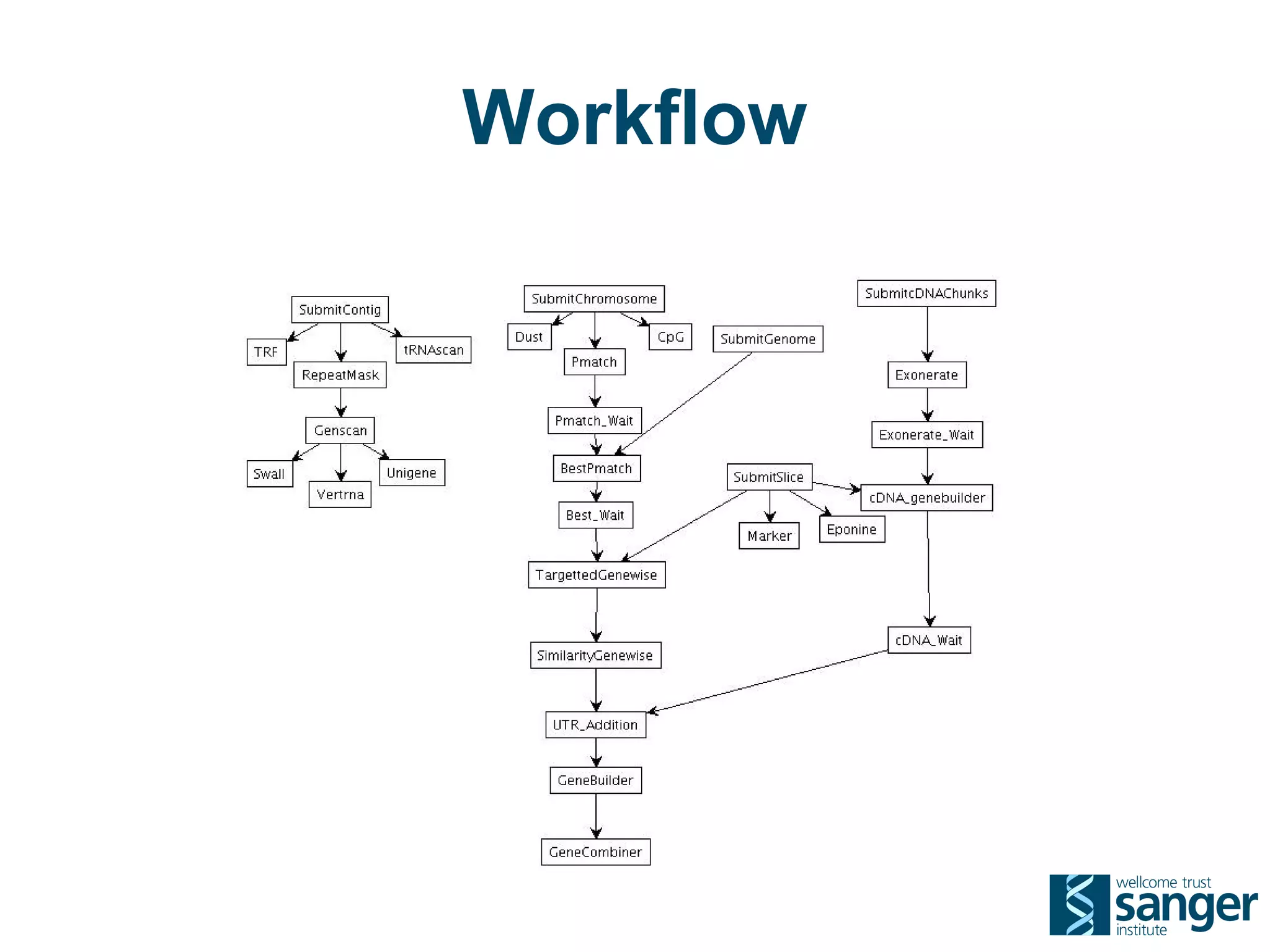







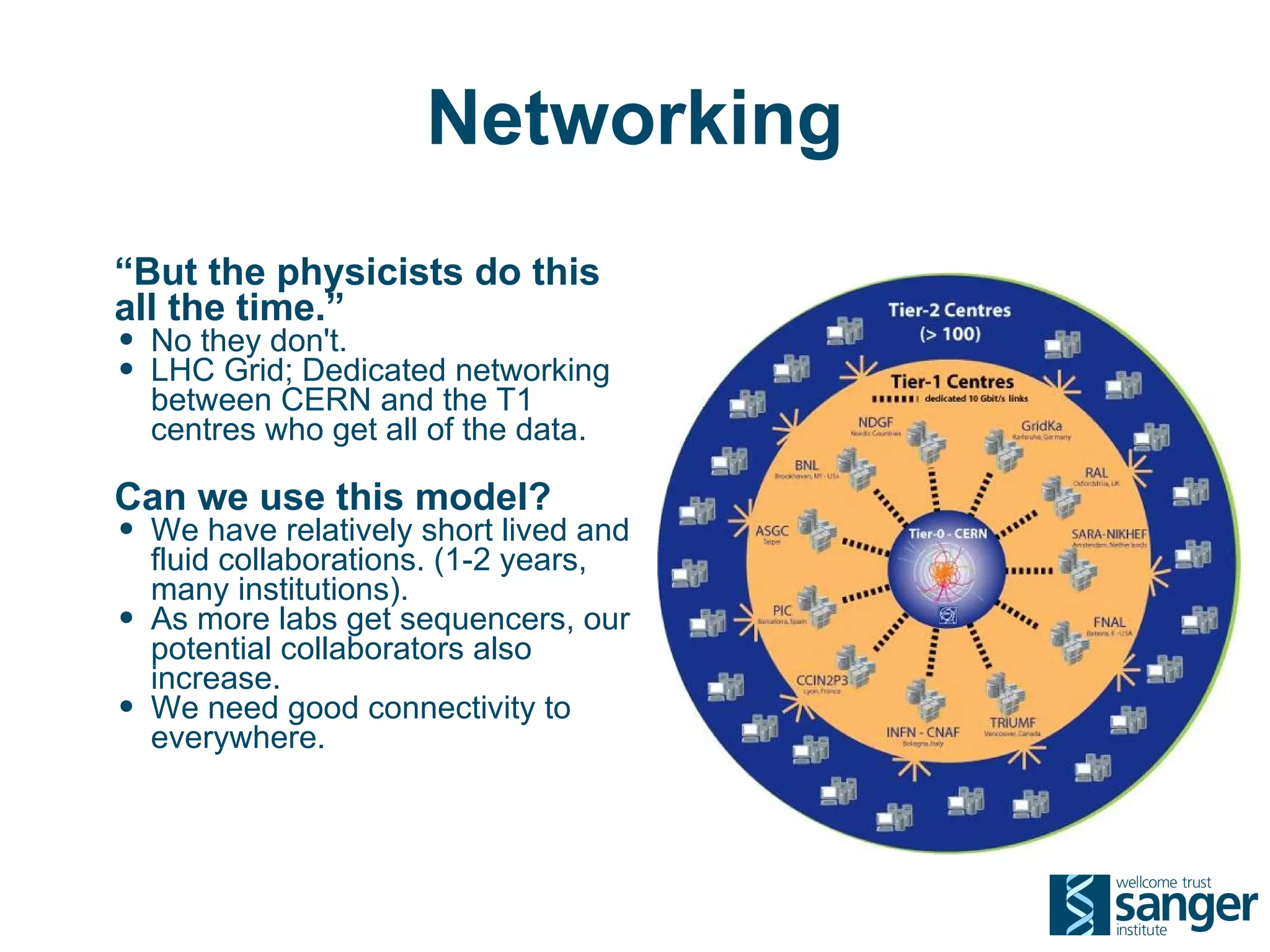

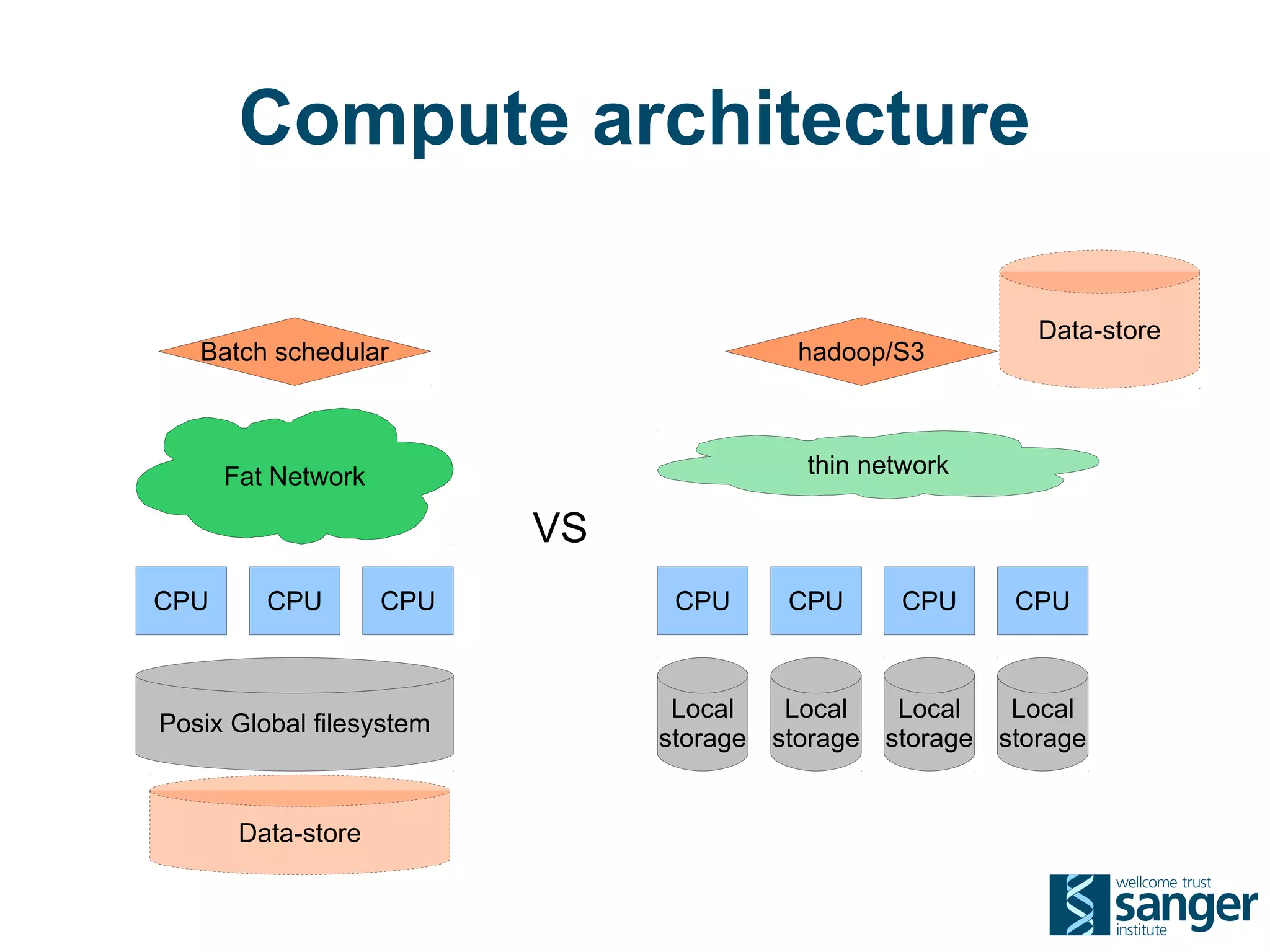

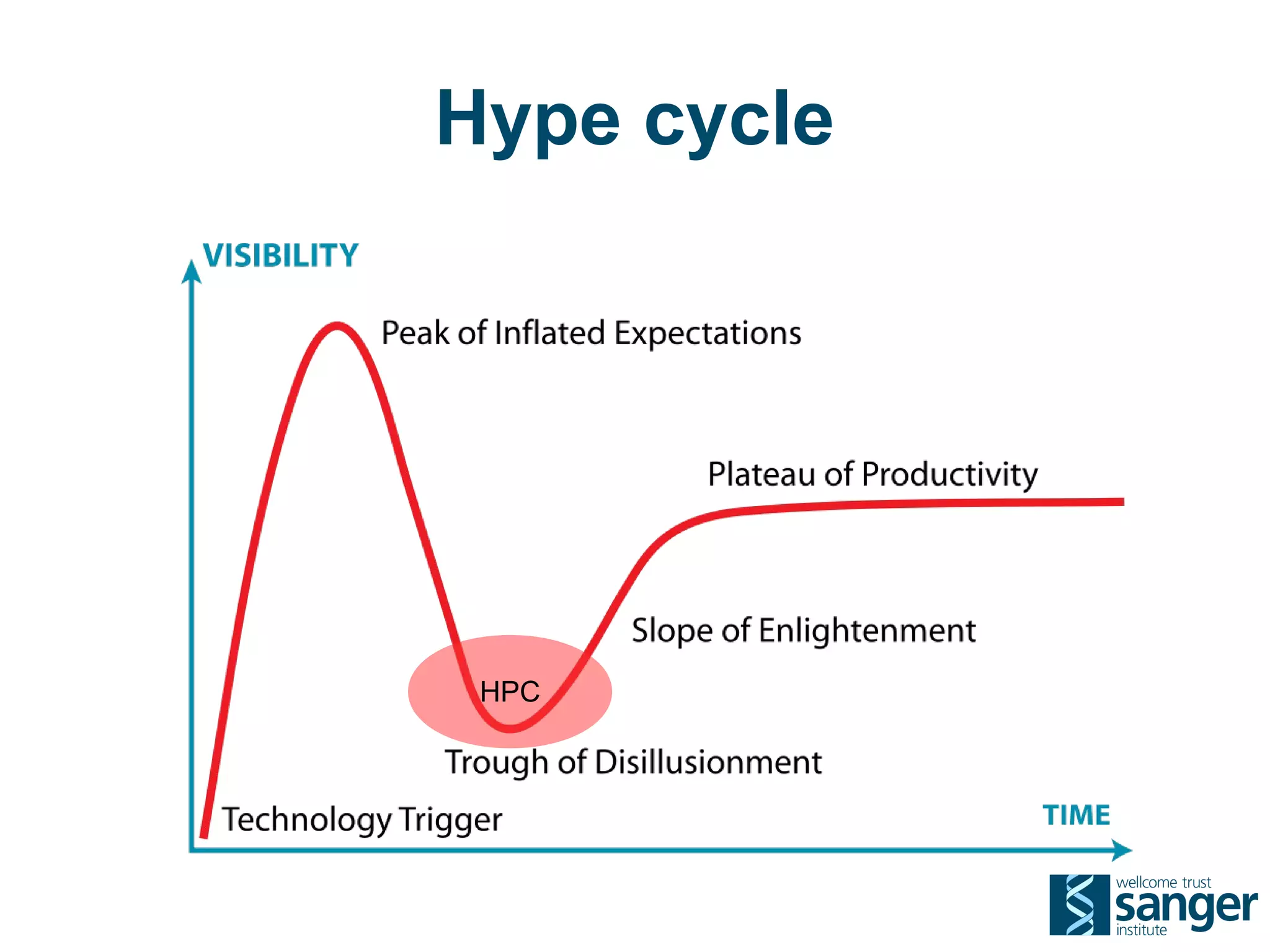


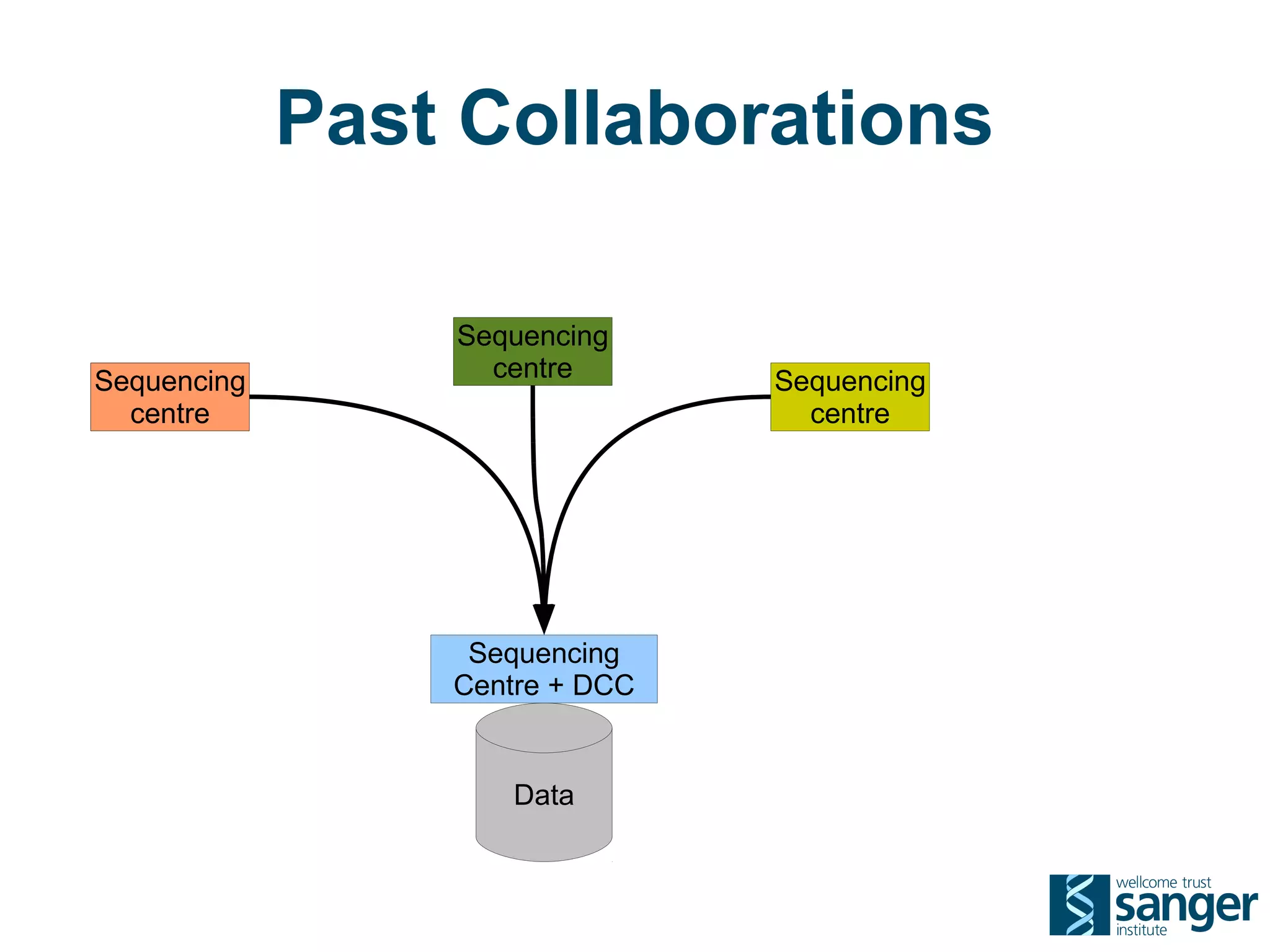
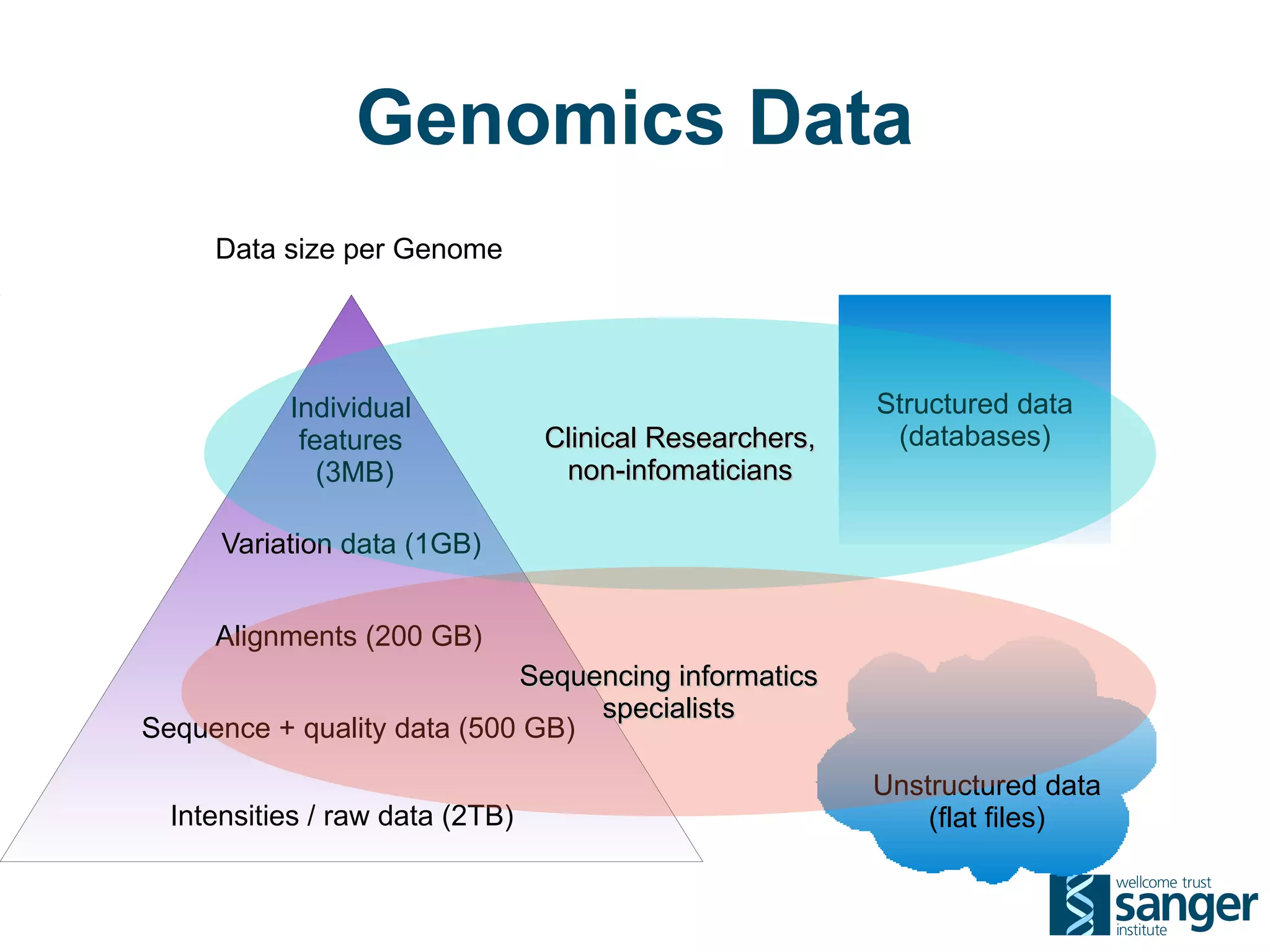


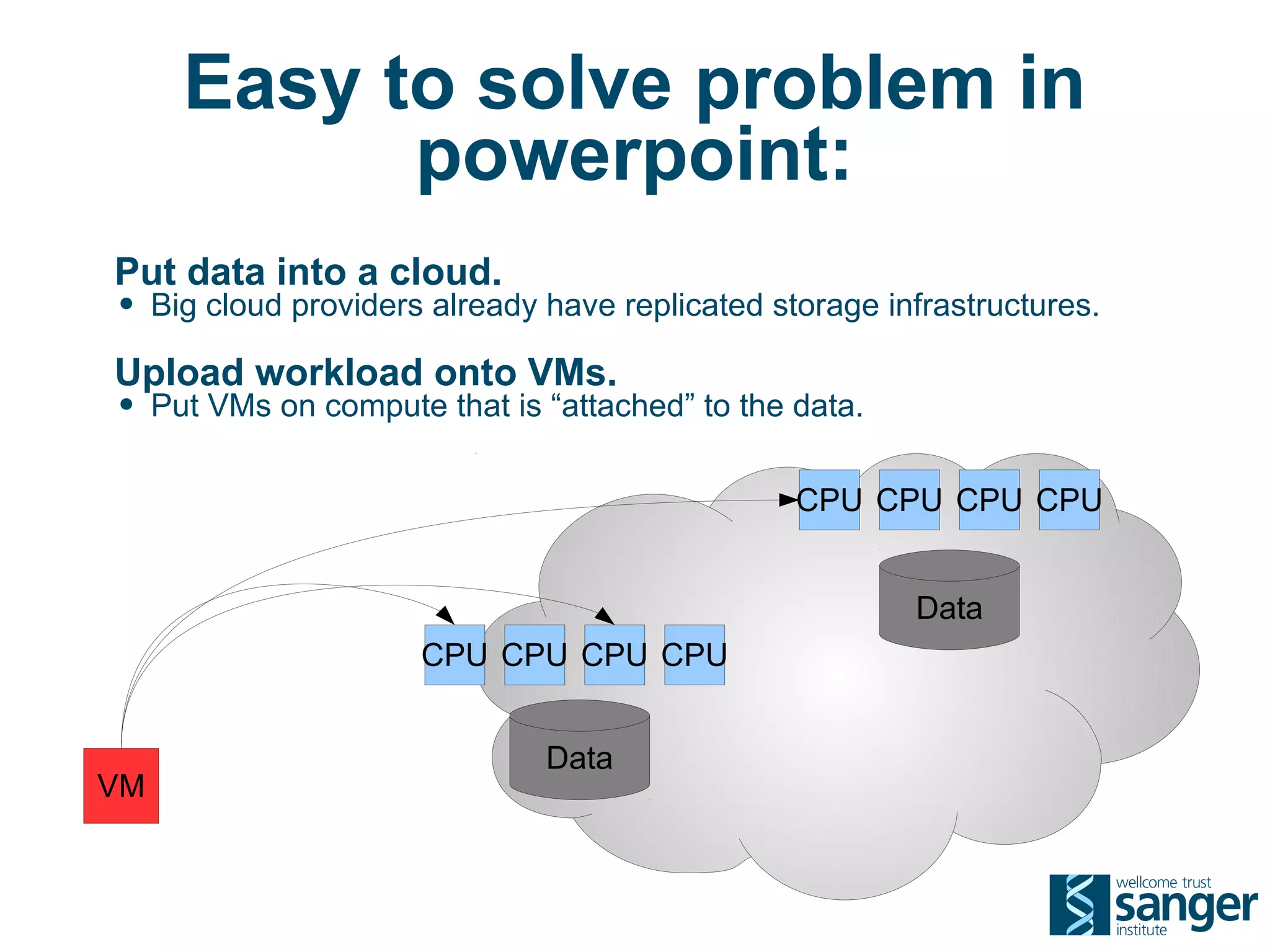






The Sanger Institute generates large amounts of genomic data and requires significant compute resources to analyze it. It has experimented with running its analysis pipelines in the cloud to expand capacity and markets. However, moving large datasets into the cloud and ensuring fast access to the data within cloud compute resources has proved challenging. While individual components like web services have worked well, the high performance computing workloads that rely on large-scale data access and processing have not scaled effectively due to data transfer bottlenecks and lack of high-performance filesystems in the cloud.







































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















