Downloaded 40 times















![Atari Player by Google DeepMind
https://youtu.be/0X-NdPtFKq0?t=21m13s
[Mnih et al. 2015] 3](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-17-320.jpg)


![Tree Search
Optimal value v∗(s) determines the outcome of the game:
[Silver et al. 2016] 5](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-22-320.jpg)
![Tree Search
Optimal value v∗(s) determines the outcome of the game:
from every board position or state s
[Silver et al. 2016] 5](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-23-320.jpg)
![Tree Search
Optimal value v∗(s) determines the outcome of the game:
from every board position or state s
under perfect play by all players.
[Silver et al. 2016] 5](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-24-320.jpg)
![Tree Search
Optimal value v∗(s) determines the outcome of the game:
from every board position or state s
under perfect play by all players.
[Silver et al. 2016] 5](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-25-320.jpg)
![Tree Search
Optimal value v∗(s) determines the outcome of the game:
from every board position or state s
under perfect play by all players.
It is computed by recursively traversing a search tree containing
approximately bd possible sequences of moves, where
[Silver et al. 2016] 5](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-26-320.jpg)
![Tree Search
Optimal value v∗(s) determines the outcome of the game:
from every board position or state s
under perfect play by all players.
It is computed by recursively traversing a search tree containing
approximately bd possible sequences of moves, where
b is the games breadth (number of legal moves per position)
[Silver et al. 2016] 5](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-27-320.jpg)
![Tree Search
Optimal value v∗(s) determines the outcome of the game:
from every board position or state s
under perfect play by all players.
It is computed by recursively traversing a search tree containing
approximately bd possible sequences of moves, where
b is the games breadth (number of legal moves per position)
d is its depth (game length)
[Silver et al. 2016] 5](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-28-320.jpg)
![Game tree of Go
Sizes of trees for various games:
chess: b ≈ 35, d ≈ 80
Go: b ≈ 250, d ≈ 150
[Allis 1994] 6](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-29-320.jpg)
![Game tree of Go
Sizes of trees for various games:
chess: b ≈ 35, d ≈ 80
Go: b ≈ 250, d ≈ 150 ⇒ more positions than atoms in the
universe!
[Allis 1994] 6](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-30-320.jpg)
![Game tree of Go
Sizes of trees for various games:
chess: b ≈ 35, d ≈ 80
Go: b ≈ 250, d ≈ 150 ⇒ more positions than atoms in the
universe!
That makes Go a googol
times more complex than
chess.
https://deepmind.com/alpha-go.html
[Allis 1994] 6](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-31-320.jpg)
![Game tree of Go
Sizes of trees for various games:
chess: b ≈ 35, d ≈ 80
Go: b ≈ 250, d ≈ 150 ⇒ more positions than atoms in the
universe!
That makes Go a googol
times more complex than
chess.
https://deepmind.com/alpha-go.html
How to handle the size of the game tree?
[Allis 1994] 6](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-32-320.jpg)
![Game tree of Go
Sizes of trees for various games:
chess: b ≈ 35, d ≈ 80
Go: b ≈ 250, d ≈ 150 ⇒ more positions than atoms in the
universe!
That makes Go a googol
times more complex than
chess.
https://deepmind.com/alpha-go.html
How to handle the size of the game tree?
for the breadth: a neural network to select moves
[Allis 1994] 6](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-33-320.jpg)
![Game tree of Go
Sizes of trees for various games:
chess: b ≈ 35, d ≈ 80
Go: b ≈ 250, d ≈ 150 ⇒ more positions than atoms in the
universe!
That makes Go a googol
times more complex than
chess.
https://deepmind.com/alpha-go.html
How to handle the size of the game tree?
for the breadth: a neural network to select moves
for the depth: a neural network to evaluate current position
[Allis 1994] 6](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-34-320.jpg)
![Game tree of Go
Sizes of trees for various games:
chess: b ≈ 35, d ≈ 80
Go: b ≈ 250, d ≈ 150 ⇒ more positions than atoms in the
universe!
That makes Go a googol
times more complex than
chess.
https://deepmind.com/alpha-go.html
How to handle the size of the game tree?
for the breadth: a neural network to select moves
for the depth: a neural network to evaluate current position
for the tree traverse: Monte Carlo tree search (MCTS)
[Allis 1994] 6](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-35-320.jpg)

![Neural Network: Modes
[Dieterle 2003] 9](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-43-320.jpg)
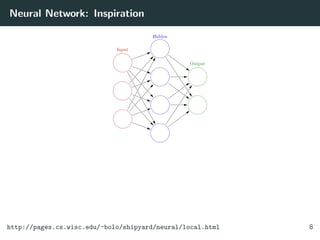
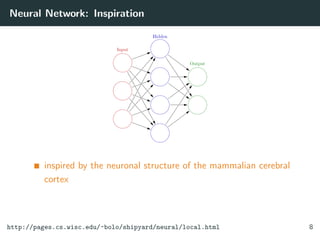
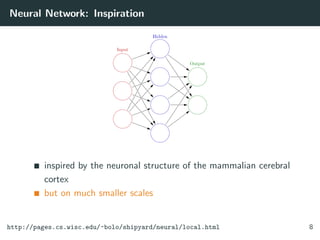
![Neural Network: Modes
Two modes
[Dieterle 2003] 9](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-44-320.jpg)
![Neural Network: Modes
Two modes
feedforward for making predictions
[Dieterle 2003] 9](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-45-320.jpg)
![Neural Network: Modes
Two modes
feedforward for making predictions
backpropagation for learning
[Dieterle 2003] 9](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-46-320.jpg)



![Policy and Value Networks
[Silver et al. 2016] 11](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-50-320.jpg)
![Training the (Deep Convolutional) Neural Networks
[Silver et al. 2016] 12](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-51-320.jpg)
![SL Policy Networks
move probabilities taken directly from the SL policy network pσ (reported as a percentage if above 0.1%).
[Silver et al. 2016] 13](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-52-320.jpg)
![Training the (Deep Convolutional) Neural Networks
[Silver et al. 2016] 14](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-53-320.jpg)
![Rollout Policy
Rollout policy pπ(a|s) is faster but less accurate than SL
policy network.
[Silver et al. 2016] 15](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-54-320.jpg)
![Rollout Policy
Rollout policy pπ(a|s) is faster but less accurate than SL
policy network.
It takes 2µs to select an action, compared to 3 ms in case
of SL policy network.
[Silver et al. 2016] 15](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-55-320.jpg)
![Training the (Deep Convolutional) Neural Networks
[Silver et al. 2016] 16](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-56-320.jpg)
![RL Policy Networks
identical in structure to the SL policy network
[Silver et al. 2016] 17](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-57-320.jpg)
![RL Policy Networks
identical in structure to the SL policy network
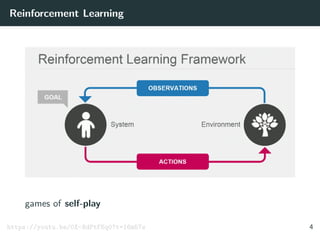
games of self-play
[Silver et al. 2016] 17](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-58-320.jpg)
![RL Policy Networks
identical in structure to the SL policy network
games of self-play
between the current RL policy network and a randomly selected
previous iteration
[Silver et al. 2016] 17](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-59-320.jpg)
![RL Policy Networks
identical in structure to the SL policy network
games of self-play
between the current RL policy network and a randomly selected
previous iteration
goal: to win in the games of self-play
[Silver et al. 2016] 17](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-60-320.jpg)
![RL Policy Networks
identical in structure to the SL policy network
games of self-play
between the current RL policy network and a randomly selected
previous iteration
goal: to win in the games of self-play
[Silver et al. 2016] 17](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-61-320.jpg)
![RL Policy Networks
identical in structure to the SL policy network
games of self-play
between the current RL policy network and a randomly selected
previous iteration
goal: to win in the games of self-play
[Silver et al. 2016] 17](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-62-320.jpg)
![Training the (Deep Convolutional) Neural Networks
[Silver et al. 2016] 18](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-63-320.jpg)
![Value Network
similar architecture to the policy network, but outputs a single
prediction instead of a probability distribution
[Silver et al. 2016] 19](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-64-320.jpg)
![Value Network
similar architecture to the policy network, but outputs a single
prediction instead of a probability distribution
Beware: successive positions are strongly correlated!
[Silver et al. 2016] 19](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-65-320.jpg)
![Value Network
similar architecture to the policy network, but outputs a single
prediction instead of a probability distribution
Beware: successive positions are strongly correlated!
Value network memorized the game outcomes, rather than
generalizing to new positions.
[Silver et al. 2016] 19](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-66-320.jpg)
![Value Network
similar architecture to the policy network, but outputs a single
prediction instead of a probability distribution
Beware: successive positions are strongly correlated!
Value network memorized the game outcomes, rather than
generalizing to new positions.
Solution: generate 30 million (new) positions, each sampled
from a separate game
[Silver et al. 2016] 19](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-67-320.jpg)
![Value Network
similar architecture to the policy network, but outputs a single
prediction instead of a probability distribution
Beware: successive positions are strongly correlated!
Value network memorized the game outcomes, rather than
generalizing to new positions.
Solution: generate 30 million (new) positions, each sampled
from a separate game
almost the accuracy of Monte Carlo rollouts (using pρ), but
15000 times less computation!
[Silver et al. 2016] 19](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-68-320.jpg)
![Value Network
similar architecture to the policy network, but outputs a single
prediction instead of a probability distribution
Beware: successive positions are strongly correlated!
Value network memorized the game outcomes, rather than
generalizing to new positions.
Solution: generate 30 million (new) positions, each sampled
from a separate game
almost the accuracy of Monte Carlo rollouts (using pρ), but
15000 times less computation!
[Silver et al. 2016] 19](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-69-320.jpg)
![Value Network
similar architecture to the policy network, but outputs a single
prediction instead of a probability distribution
Beware: successive positions are strongly correlated!
Value network memorized the game outcomes, rather than
generalizing to new positions.
Solution: generate 30 million (new) positions, each sampled
from a separate game
almost the accuracy of Monte Carlo rollouts (using pρ), but
15000 times less computation!
[Silver et al. 2016] 19](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-70-320.jpg)
![Value Network: Selection of Moves
evaluation of all successors s of the root position s, using vθ(s)
[Silver et al. 2016] 20](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-71-320.jpg)
![Training the (Deep Convolutional) Neural Networks
[Silver et al. 2016] 21](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-72-320.jpg)
![ELO Ratings for Various Combinations of Networks
[Silver et al. 2016] 22](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-73-320.jpg)
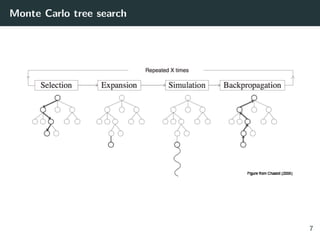
![Monte Carlo Tree Search (MCTS) Algorithm
The tree is traversed by simulation from the root state (i.e.
descending the tree).
[Silver et al. 2016] 23](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-74-320.jpg)
![Monte Carlo Tree Search (MCTS) Algorithm
The tree is traversed by simulation from the root state (i.e.
descending the tree).
The next action is selected with a lookahead search:
[Silver et al. 2016] 23](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-75-320.jpg)
![Monte Carlo Tree Search (MCTS) Algorithm
The tree is traversed by simulation from the root state (i.e.
descending the tree).
The next action is selected with a lookahead search:
1. selection phase
[Silver et al. 2016] 23](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-76-320.jpg)
![Monte Carlo Tree Search (MCTS) Algorithm
The tree is traversed by simulation from the root state (i.e.
descending the tree).
The next action is selected with a lookahead search:
1. selection phase
2. expansion phase
[Silver et al. 2016] 23](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-77-320.jpg)
![Monte Carlo Tree Search (MCTS) Algorithm
The tree is traversed by simulation from the root state (i.e.
descending the tree).
The next action is selected with a lookahead search:
1. selection phase
2. expansion phase
3. evaluation phase
[Silver et al. 2016] 23](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-78-320.jpg)
![Monte Carlo Tree Search (MCTS) Algorithm
The tree is traversed by simulation from the root state (i.e.
descending the tree).
The next action is selected with a lookahead search:
1. selection phase
2. expansion phase
3. evaluation phase
4. backup phase (at end of simulation)
[Silver et al. 2016] 23](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-79-320.jpg)
![Monte Carlo Tree Search (MCTS) Algorithm
The tree is traversed by simulation from the root state (i.e.
descending the tree).
The next action is selected with a lookahead search:
1. selection phase
2. expansion phase
3. evaluation phase
4. backup phase (at end of simulation)
[Silver et al. 2016] 23](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-80-320.jpg)
![Monte Carlo Tree Search (MCTS) Algorithm
The tree is traversed by simulation from the root state (i.e.
descending the tree).
The next action is selected with a lookahead search:
1. selection phase
2. expansion phase
3. evaluation phase
4. backup phase (at end of simulation)
[Silver et al. 2016] 23](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-81-320.jpg)
![MCTS Algorithm: Selection
[Silver et al. 2016] 24](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-82-320.jpg)
![MCTS Algorithm: Expansion
[Silver et al. 2016] 25](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-83-320.jpg)
![MCTS Algorithm: Expansion
A leaf position may be expanded by the SL policy network pσ.
[Silver et al. 2016] 25](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-84-320.jpg)
![MCTS Algorithm: Expansion
A leaf position may be expanded by the SL policy network pσ.
Once it’s expanded, it remains so until the end.
[Silver et al. 2016] 25](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-85-320.jpg)
![MCTS: Evaluation
[Silver et al. 2016] 26](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-86-320.jpg)
![MCTS: Evaluation
Both of the following 2 evalutions:
[Silver et al. 2016] 26](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-87-320.jpg)
![MCTS: Evaluation
Both of the following 2 evalutions:
evaluation from the value network vθ(s)
[Silver et al. 2016] 26](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-88-320.jpg)
![MCTS: Evaluation
Both of the following 2 evalutions:
evaluation from the value network vθ(s)
evaluation by the outcome of the fast rollout pπ
[Silver et al. 2016] 26](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-89-320.jpg)
![MCTS: Evaluation
Both of the following 2 evalutions:
evaluation from the value network vθ(s)
evaluation by the outcome of the fast rollout pπ
[Silver et al. 2016] 26](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-90-320.jpg)
![MCTS: Evaluation
Both of the following 2 evalutions:
evaluation from the value network vθ(s)
evaluation by the outcome of the fast rollout pπ
[Silver et al. 2016] 26](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-91-320.jpg)
![MCTS: Backup
At the end of a simulation, each traversed edge updates its values.
[Silver et al. 2016] 27](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-92-320.jpg)
![Once the search is complete, the algorithm
chooses the most visited move from the root
position.
[Silver et al. 2016] 27](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-93-320.jpg)
![Tree Evaluation: using Value Network
tree-edge values averaged over value network evaluations only
[Silver et al. 2016] 28](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-94-320.jpg)
![Tree Evaluation: using Rollouts
tree-edge values averaged over rollout evaluations only
[Silver et al. 2016] 29](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-95-320.jpg)
![Percentage of Simulations
percentage frequency:
which actions were selected during simulations
[Silver et al. 2016] 30](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-96-320.jpg)
![Principal Variation
i.e. the Path with the Maximum Visit Count
[Silver et al. 2016] 31](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-97-320.jpg)
![Principal Variation
i.e. the Path with the Maximum Visit Count
AlphaGo selected the move indicated by the red circle.
[Silver et al. 2016] 31](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-98-320.jpg)
![Principal Variation
i.e. the Path with the Maximum Visit Count
AlphaGo selected the move indicated by the red circle.
Fan Hui responded with the move indicated by the white square.
[Silver et al. 2016] 31](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-99-320.jpg)
![Principal Variation
i.e. the Path with the Maximum Visit Count
AlphaGo selected the move indicated by the red circle.
Fan Hui responded with the move indicated by the white square.
In his post-game commentary, he preferred the move predicted by AlphaGo (label 1).
[Silver et al. 2016] 31](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-100-320.jpg)
![Tournament with Other Go Programs
[Silver et al. 2016] 32](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-101-320.jpg)









![AlphaGo versus Fan Hui
AlphaGo won 5 - 0 in a formal match on October 2015.
[AlphaGo] is very strong and stable, it seems
like a wall. ... I know AlphaGo is a computer,
but if no one told me, maybe I would think
the player was a little strange, but a very
strong player, a real person.
Fan Hui 34](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-111-320.jpg)







![I heard Google DeepMind’s AI is surprisingly
strong and getting stronger, but I am
confident that I can win, at least this time.
Lee Sedol
...even beating AlphaGo by 4-1 may allow
the Google DeepMind team to claim its de
facto victory and the defeat of him
[Lee Sedol], or even humankind.
interview in JTBC
Newsroom
35](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-119-320.jpg)
![I heard Google DeepMind’s AI is surprisingly
strong and getting stronger, but I am
confident that I can win, at least this time.
Lee Sedol
...even beating AlphaGo by 4-1 may allow
the Google DeepMind team to claim its de
facto victory and the defeat of him
[Lee Sedol], or even humankind.
interview in JTBC
Newsroom
35](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-120-320.jpg)




























![Game Tree in Poker
P R E - F L O P
F L O P
Raise
RaiseFold
Call
Call
Fold
Call
Fold
Call
CallFold
Bet
Check
Check
Raise
Check
T U R N
-50
-100
100
100
-200
Fold
1
22
1
1
2 2
1
[Moravˇc´ık et al. 2017] 40](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-149-320.jpg)
![Game Tree in Poker
P R E - F L O P
F L O P
Raise
RaiseFold
Call
Call
Fold
Call
Fold
Call
CallFold
Bet
Check
Check
Raise
Check
T U R N
-50
-100
100
100
-200
Fold
1
22
1
1
2 2
1
the so-called public tree (tree of public events)
[Moravˇc´ık et al. 2017] 40](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-150-320.jpg)

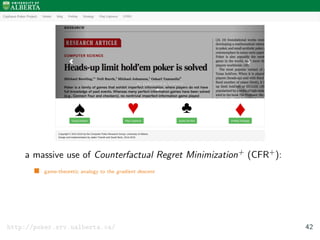
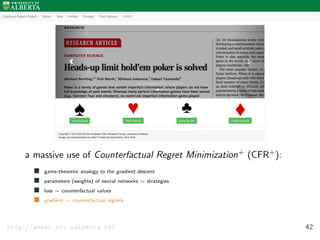
![Cepheus
Heads-up Limit Holdem Poker
[Bowling et al. 2015] 41](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-152-320.jpg)
![Cepheus
Heads-up Limit Holdem Poker
http://poker.srv.ualberta.ca/
[Bowling et al. 2015] 41](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-153-320.jpg)








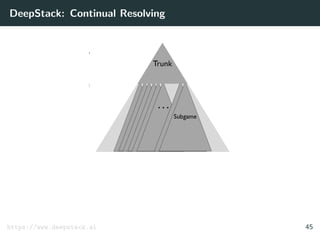
![DeepStack: Components
C
Sampled poker
situations
BA
Agent's possible actions
Lookahead tree
Current public state
Agent’s range
Opponent counterfactual values
Neural net [see B]
Action history
Public tree
Subtree
ValuesRanges
[Moravˇc´ık et al. 2017] 44](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-166-320.jpg)
![DeepStack: Components
C
Sampled poker
situations
BA
Agent's possible actions
Lookahead tree
Current public state
Agent’s range
Opponent counterfactual values
Neural net [see B]
Action history
Public tree
Subtree
ValuesRanges
continual resolving
[Moravˇc´ık et al. 2017] 44](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-167-320.jpg)
![DeepStack: Components
C
Sampled poker
situations
BA
Agent's possible actions
Lookahead tree
Current public state
Agent’s range
Opponent counterfactual values
Neural net [see B]
Action history
Public tree
Subtree
ValuesRanges
continual resolving
“intuitive” local search
[Moravˇc´ık et al. 2017] 44](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-168-320.jpg)
![DeepStack: Components
C
Sampled poker
situations
BA
Agent's possible actions
Lookahead tree
Current public state
Agent’s range
Opponent counterfactual values
Neural net [see B]
Action history
Public tree
Subtree
ValuesRanges
continual resolving
“intuitive” local search
sparse lookahead trees
[Moravˇc´ık et al. 2017] 44](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-169-320.jpg)






![DeepStack: Deep Counterfactual Value Network
Input
Bucket
ranges
7 Hidden Layers
• fully connected
• linear, PReLU
Output
Bucket
values
F E E D F O R W A R D
N E U R A L N E T
Z E R O - S U M
N E U R A L N E T
Output
Counterfactual
values
C A R D
C O U N T E R F A C T U A L
V A L U E S
Zero-sum
Error
B U C K E T I N G
( I N V E R S E )
B U C K E T I N G
C A R D
R A N G E S
500500500500500500500
1000
1
P2
P1
P1
P2
1326
P1
P2
Pot
Public
1326
22100
1
1000
P2
P1
1000
P2
P1
[Moravˇc´ık et al. 2017] 47](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-181-320.jpg)





![DeepStack: Against Professional Players
Participant
Handsplayed
1250
1000
500
250
750
50
0
-500
-250
DeepStackwinrate(mbb/g)
1000
2000
3000
0
5 10 15 20 25 30
[Moravˇc´ık et al. 2017] 49](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-187-320.jpg)
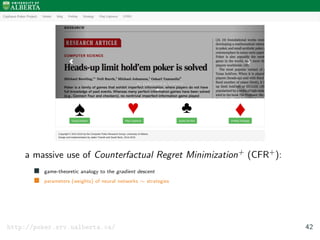
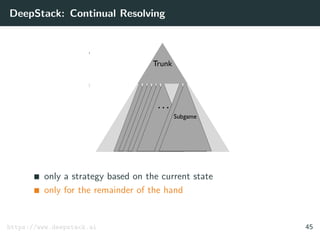
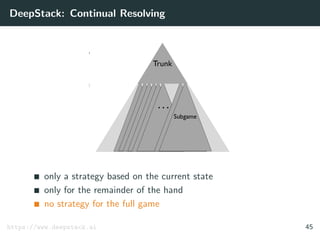
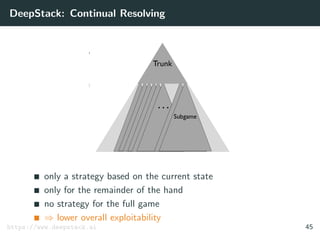
![DeepStack: Theoretical Guarantees
Theorem
Let the error of counterfactual values returned by the value
function be ≤ .
[Moravˇc´ık et al. 2017] 50](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-188-320.jpg)
![DeepStack: Theoretical Guarantees
Theorem
Let the error of counterfactual values returned by the value
function be ≤ .
Let T be the number of resolving iterations for each decision.
[Moravˇc´ık et al. 2017] 50](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-189-320.jpg)
![DeepStack: Theoretical Guarantees
Theorem
Let the error of counterfactual values returned by the value
function be ≤ .
Let T be the number of resolving iterations for each decision.
[Moravˇc´ık et al. 2017] 50](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-190-320.jpg)
![DeepStack: Theoretical Guarantees
Theorem
Let the error of counterfactual values returned by the value
function be ≤ .
Let T be the number of resolving iterations for each decision.
Then the exploitability of the strategies is
≤ k1 +
k2
√
T
where k1 and k2 are game-specific constants.
[Moravˇc´ık et al. 2017] 50](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-191-320.jpg)










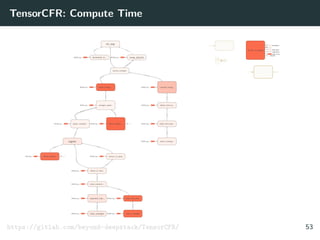
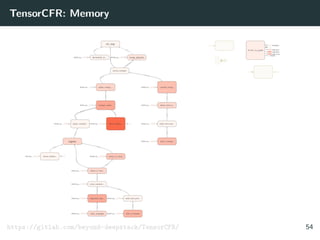

















![SL Policy Networks (1/2)
13-layer deep convolutional neural network
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-222-320.jpg)
![SL Policy Networks (1/2)
13-layer deep convolutional neural network
goal: to predict expert human moves
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-223-320.jpg)
![SL Policy Networks (1/2)
13-layer deep convolutional neural network
goal: to predict expert human moves
task of classification
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-224-320.jpg)
![SL Policy Networks (1/2)
13-layer deep convolutional neural network
goal: to predict expert human moves
task of classification
trained from 30 millions positions from the KGS Go Server
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-225-320.jpg)
![SL Policy Networks (1/2)
13-layer deep convolutional neural network
goal: to predict expert human moves
task of classification
trained from 30 millions positions from the KGS Go Server
stochastic gradient ascent:
∆σ ∝
∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-226-320.jpg)
![SL Policy Networks (1/2)
13-layer deep convolutional neural network
goal: to predict expert human moves
task of classification
trained from 30 millions positions from the KGS Go Server
stochastic gradient ascent:
∆σ ∝
∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-227-320.jpg)
![SL Policy Networks (1/2)
13-layer deep convolutional neural network
goal: to predict expert human moves
task of classification
trained from 30 millions positions from the KGS Go Server
stochastic gradient ascent:
∆σ ∝
∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
Results:
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-228-320.jpg)
![SL Policy Networks (1/2)
13-layer deep convolutional neural network
goal: to predict expert human moves
task of classification
trained from 30 millions positions from the KGS Go Server
stochastic gradient ascent:
∆σ ∝
∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
Results:
44.4% accuracy (the state-of-the-art from other groups)
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-229-320.jpg)
![SL Policy Networks (1/2)
13-layer deep convolutional neural network
goal: to predict expert human moves
task of classification
trained from 30 millions positions from the KGS Go Server
stochastic gradient ascent:
∆σ ∝
∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
Results:
44.4% accuracy (the state-of-the-art from other groups)
55.7% accuracy (raw board position + move history as input)
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-230-320.jpg)
![SL Policy Networks (1/2)
13-layer deep convolutional neural network
goal: to predict expert human moves
task of classification
trained from 30 millions positions from the KGS Go Server
stochastic gradient ascent:
∆σ ∝
∂ log pσ(a|s)
∂σ
(to maximize the likelihood of the human move a selected in state s)
Results:
44.4% accuracy (the state-of-the-art from other groups)
55.7% accuracy (raw board position + move history as input)
57.0% accuracy (all input features)
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-231-320.jpg)
![SL Policy Networks (2/2)
Small improvements in accuracy led to large improvements
in playing strength (see the next slide)
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-232-320.jpg)
![RL Policy Networks (details)
Results (by sampling each move at ∼ pρ(·|st)):
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-233-320.jpg)
![RL Policy Networks (details)
Results (by sampling each move at ∼ pρ(·|st)):
80% of win rate against the SL policy network
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-234-320.jpg)
![RL Policy Networks (details)
Results (by sampling each move at ∼ pρ(·|st)):
80% of win rate against the SL policy network
85% of win rate against the strongest open-source Go program,
Pachi (Baudiˇs and Gailly 2011)
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-235-320.jpg)
![RL Policy Networks (details)
Results (by sampling each move at ∼ pρ(·|st)):
80% of win rate against the SL policy network
85% of win rate against the strongest open-source Go program,
Pachi (Baudiˇs and Gailly 2011)
The previous state-of-the-art, based only on SL of CNN:
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-236-320.jpg)
![RL Policy Networks (details)
Results (by sampling each move at ∼ pρ(·|st)):
80% of win rate against the SL policy network
85% of win rate against the strongest open-source Go program,
Pachi (Baudiˇs and Gailly 2011)
The previous state-of-the-art, based only on SL of CNN:
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-237-320.jpg)
![RL Policy Networks (details)
Results (by sampling each move at ∼ pρ(·|st)):
80% of win rate against the SL policy network
85% of win rate against the strongest open-source Go program,
Pachi (Baudiˇs and Gailly 2011)
The previous state-of-the-art, based only on SL of CNN:
11% of “win” rate against Pachi
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-238-320.jpg)
![Evaluation accuracy in various stages of a game
Move number is the number of moves that had been played in the given position.
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-239-320.jpg)
![Evaluation accuracy in various stages of a game
Move number is the number of moves that had been played in the given position.
Each position evaluated by:
forward pass of the value network vθ
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-240-320.jpg)
![Evaluation accuracy in various stages of a game
Move number is the number of moves that had been played in the given position.
Each position evaluated by:
forward pass of the value network vθ
100 rollouts, played out using the corresponding policy
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-241-320.jpg)
![Scalability
asynchronous multi-threaded search
simulations on CPUs
computation of neural networks on GPUs
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-242-320.jpg)
![Scalability
asynchronous multi-threaded search
simulations on CPUs
computation of neural networks on GPUs
AlphaGo:
40 search threads
40 CPUs
8 GPUs
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-243-320.jpg)
![Scalability
asynchronous multi-threaded search
simulations on CPUs
computation of neural networks on GPUs
AlphaGo:
40 search threads
40 CPUs
8 GPUs
Distributed version of AlphaGo (on multiple machines):
40 search threads
1202 CPUs
176 GPUs
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-244-320.jpg)
![ELO Ratings for Various Combinations of Threads
[Silver et al. 2016]](https://image.slidesharecdn.com/aisupremacy-180617164025/85/AI-Supremacy-in-Games-Deep-Blue-Watson-Cepheus-AlphaGo-DeepStack-and-TensorCFR-245-320.jpg)



The document discusses the advancements in artificial intelligence within various games, highlighting key milestones such as Deep Blue's historic victory over Garry Kasparov in chess, AlphaGo's success in the game of Go, and the innovations in poker strategies with Cepheus and DeepStack. It details the technologies and algorithms driving these AI systems, including deep reinforcement learning, Monte Carlo tree search, and neural networks, while addressing the complexities of each game. The evolution of AI in gaming showcases the transition from brute-force search methods to sophisticated learning algorithms that have dramatically improved performance in complex strategic environments.










![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=640&height=640&fit=bounds)
































































