![(2011) xxx-yyy xxx
»OntoFrac-S« Ontogenesis of Semantic Web with Fractal Federation
Moving from the realm of WWW to GGG
Rolly Seth
Scientist Fellow (QHS)
Council of Scientific & Industrial Research, India,
rolly.seth@gmail.com, rollys@csir.res.in
Keywords: multi-agent, semantic, factotum, fractal, medical, semantic relativity, ontology, EHR, GGG
Abstract: The annals of history bear witness to plethora of ontologies being created for the realization
of Semantic web. In order to manage this outburst of ontologies, we propose “OntoFrac-S” (Semantic-
Ontology Fractals) as the new way ahead to handle these ever emergent „Ontology Management‟
requirements. The paper presents a conceptual model for the implementation of Semantic Web using
„Fractals‟ and multi-agents as applicable to the next level web systems, that is, GGG (Giant Global
Graph). A generic approach has been proposed as applicable to all domains and further its
implementation in the Medical domain using „Factotum agents‟ is also explained. This paper can be
viewed as a base document for other to work on for building a Semantic world while adhering to the
concept of „Semantic Relativity‟.
1 Introduction
With the day to day proliferation of data coming
from various heterogeneous sources, the need for
adoption of a robust ‗Ontology Management‘ System is
becoming the de-facto standard. In the present times,
like the data itself, ontology also come in assorted sizes,
domains etc. Diverse attempts have been made to
standardize these ontologies in order to accomplish Tim
Berners Lee‘s aim of Semantic Web [1] by making the
data interoperable. Now the researchers are concerned
about linking the heterogenous ontologies more than the
‗data itself‘ cause the ‗concepts‘ which relates data will
only make this data interoperable. In the meanwhile, the
father of ‗WWW‘, Tim Berners Lee has coined yet
another term for the next level of networking which he
has named as GGG (Giant Global Graph) [13]. It
highlights the importance of ‗Linked Data‘ in the coming
years where ontologies will play a crucial role more than
ever.
Keeping apace of the latest developments all around
the world, it is being widely accepted that a single
unified ontology would not be sufficient enough to cater
the every growing needs of the user as has been
expressed in [2], [3], [4], [5] . Over the years the concept
of having local ontologies has emerged in order to
account for the fact that some concepts, interpretations
etc are limited within small communities itself. Thus,
human clusters prefer interacting in their locally accepted
terms than following the lingua franca of the world. This
encumbrance hugely hampers the realization of the
Semantic Web. However, over the years the researchers
have evolved various methodologies to address this
concern which focuses on mapping and integration of
local and global ontologies. Some of them are presented
in [6], [7], [8], [9], [10], [11], [12].
Albeit, they provide the veracious solution for local
and global ontology mapping, hardly any conceptualize
that ‗local‘ and ‗global‘ are merely relative terms and
each ‗local‘ would act as global for a cobweb of many
more sub-local ontologies within it . Thus, this crucial
factor also needs to be addressed while envisioning a
globally linked graph. This paper aims to raise this issue
and propose a solution in this regard.
The rest of the paper is organized as follows: Section
2 starts with the related work. Section 3 gives a brief
overview about relativity of the global data and
addressing it using the fractal approach. Section 3 of the
paper describes our approach in highlighting this issue.
Section 4 explains our proposed approach, followed by
OntoFrac-S Communication Algorithm in Section 5.
Section 6 talks about semantic communication in the
medical world using the relativity concept and aided by
Multi-Agent System of Factotums. Section 7 highlights
the importance of OntoFrac-S while Section 8 gives a
brief overview of implementation methodology. Section
9 presents the future work and Section 10 concludes the
work.
2 Related Work
Ontology Mapping is not a new concept and has
been talked about numerous times. The proposed
approaches for accessing the Global Linked data is mere
integration of local and global ontologies to provide
interoperability of RDF tagged data. Some others have
addressed this issue by offering ‗on the fly Semantic
Web Services‘ solution on a click of a button or even
without human intervention through the use of Intelligent
Agents. So far, so good, but it is high time that we
acknowledge the fact that the world cannot be
conceptualized by assuming that sole integration of a
single global/foundational and many local/domain](https://image.slidesharecdn.com/paper-ontofrac-s-150924153959-lva1-app6892/85/OntoFrac-S-1-320.jpg)
![(2011) xxx-yyy xxx
»OntoFrac-S« Ontogenesis of Semantic Web with Fractal Federation
Moving from the realm of WWW to GGG
Rolly Seth
Scientist Fellow (QHS)
Council of Scientific & Industrial Research, India,
rolly.seth@gmail.com, rollys@csir.res.in
Keywords: multi-agent, semantic, factotum, fractal, medical, semantic relativity, ontology, EHR, GGG
Abstract: The annals of history bear witness to plethora of ontologies being created for the realization
of Semantic web. In order to manage this outburst of ontologies, we propose “OntoFrac-S” (Semantic-
Ontology Fractals) as the new way ahead to handle these ever emergent „Ontology Management‟
requirements. The paper presents a conceptual model for the implementation of Semantic Web using
„Fractals‟ and multi-agents as applicable to the next level web systems, that is, GGG (Giant Global
Graph). A generic approach has been proposed as applicable to all domains and further its
implementation in the Medical domain using „Factotum agents‟ is also explained. This paper can be
viewed as a base document for other to work on for building a Semantic world while adhering to the
concept of „Semantic Relativity‟.
1 Introduction
With the day to day proliferation of data coming
from various heterogeneous sources, the need for
adoption of a robust ‗Ontology Management‘ System is
becoming the de-facto standard. In the present times,
like the data itself, ontology also come in assorted sizes,
domains etc. Diverse attempts have been made to
standardize these ontologies in order to accomplish Tim
Berners Lee‘s aim of Semantic Web [1] by making the
data interoperable. Now the researchers are concerned
about linking the heterogenous ontologies more than the
‗data itself‘ cause the ‗concepts‘ which relates data will
only make this data interoperable. In the meanwhile, the
father of ‗WWW‘, Tim Berners Lee has coined yet
another term for the next level of networking which he
has named as GGG (Giant Global Graph) [13]. It
highlights the importance of ‗Linked Data‘ in the coming
years where ontologies will play a crucial role more than
ever.
Keeping apace of the latest developments all around
the world, it is being widely accepted that a single
unified ontology would not be sufficient enough to cater
the every growing needs of the user as has been
expressed in [2], [3], [4], [5] . Over the years the concept
of having local ontologies has emerged in order to
account for the fact that some concepts, interpretations
etc are limited within small communities itself. Thus,
human clusters prefer interacting in their locally accepted
terms than following the lingua franca of the world. This
encumbrance hugely hampers the realization of the
Semantic Web. However, over the years the researchers
have evolved various methodologies to address this
concern which focuses on mapping and integration of
local and global ontologies. Some of them are presented
in [6], [7], [8], [9], [10], [11], [12].
Albeit, they provide the veracious solution for local
and global ontology mapping, hardly any conceptualize
that ‗local‘ and ‗global‘ are merely relative terms and
each ‗local‘ would act as global for a cobweb of many
more sub-local ontologies within it . Thus, this crucial
factor also needs to be addressed while envisioning a
globally linked graph. This paper aims to raise this issue
and propose a solution in this regard.
The rest of the paper is organized as follows: Section
2 starts with the related work. Section 3 gives a brief
overview about relativity of the global data and
addressing it using the fractal approach. Section 3 of the
paper describes our approach in highlighting this issue.
Section 4 explains our proposed approach, followed by
OntoFrac-S Communication Algorithm in Section 5.
Section 6 talks about semantic communication in the
medical world using the relativity concept and aided by
Multi-Agent System of Factotums. Section 7 highlights
the importance of OntoFrac-S while Section 8 gives a
brief overview of implementation methodology. Section
9 presents the future work and Section 10 concludes the
work.
2 Related Work
Ontology Mapping is not a new concept and has
been talked about numerous times. The proposed
approaches for accessing the Global Linked data is mere
integration of local and global ontologies to provide
interoperability of RDF tagged data. Some others have
addressed this issue by offering ‗on the fly Semantic
Web Services‘ solution on a click of a button or even
without human intervention through the use of Intelligent
Agents. So far, so good, but it is high time that we
acknowledge the fact that the world cannot be
conceptualized by assuming that sole integration of a
single global/foundational and many local/domain](https://image.slidesharecdn.com/paper-ontofrac-s-150924153959-lva1-app6892/75/OntoFrac-S-1-2048.jpg)
![2011 xxx–yyy xxx
ontologies exists at ‘One level‘ only. The macrocosm in
which we live is a complex system having multiple
layers which might not be visible at first view but
becomes more evident as we zoom in to the layers. With
regards to the information, the complexity has already
been justified by proposing that the data is fractal or
‗self- similar‘ in nature. In other words, at first view the
data might be viewed as a specific pattern but as we
zoom in on a specific area, we explore that this pattern
reappears again in a much more contracted area. This
self-similar nature continues at different levels along
with a contraction factor. The papers [15], [16], [17]
have highlighted the presence of this fractal nature in the
information. Apart from the information, Tim Lee in one
of his recent articles emphasizes on seeing the web
system also as a ‗fractal [14]. In order to address these
ever growing complexities of the ‗linked data‘, Tim
proposes on visualizing the web system as ‗FRACTAL
COMMUNITIES‘.
With this view, which has evolved over the years
when we see the ontological approaches in this respect to
unify the global data, they don‘t seem to address this
fractal nature. If data is fractal (as has been addressed by
many), the local and global terminology may seem to be
a relative concept depending upon the amount of scaling
done to view the data. This warrants the fact that merely
conceptualizing the integration of local and global
schemas and ontologies at one level would not help us
achieve our vision of GGG. At this juncture it is crucial
to study the ‘relativity of concepts’ in terms of a layered
approach rather than adopting an unconditional approach
to link the data which might not lead us to the correct
path. Philosophers like W.V. Quine and Noam Chomsky
have already addressed this issue and some early theories
as early as 1968 talk about ‗Semantic Relativism‘ and
‗Ontological Relativity‘ [18], [19]. However, these
philosophies are often juxtaposed with the technology
instead of adopting a federated approach. In the
upcoming sections we shift our paradigm on this well
known but less trodden path for interconnecting the
globe. While at one end, research on language relativity
has been given importance, the others focus on theories
like ‗Fractal Relativity‘, ‗Space Relativity‘ which are
mainly concerned with the time relativity as seen in
Physics and Mathematics domain [20]. With such diverse
views on relativity, ‗Relativity‘ can itself be viewed as a
relative term. However, this paper aims to apply the
philosophical concepts of Ontological/ Semantic
Relativity to the semantic web systems using fractal
concepts. At first glance this might sound you as ‗fractal
relativity‘. However, a deeper analysis of the two will
make you realize that the above mentioned ‗Fractal
Relativity‘ deals with the space time concepts which this
paper doesn‘t deal with. However, we intend to address
the cross- culture, language barriers for building GGG,
using Multi – Agent System by applying fractal
approach. In this regard, the similar works we could
relate to are [21] or [22] and [3], which is with respect to
the manufacturing domain. It presents a task model for
the hierarchical fractals in order to accomplish a given
task. However, it does not account for the linguistic
barriers within any two fractals and solely divides
fractals on the basis of the task at hand. Further, it
doesn‘t relate to Ontologies and the Semantic Web
Information System.
With regards to the Web System, a lot of
technological advancements have been made and it has
been reiterated several times that the next wave of web
(Semantic web) will rely highly on Multi – Agents and
Semantic Web Services as could be seen in [23], [3],
[24], [25]. Without a doubt, the backbone of this new era
would be provided by Ontologies which would define the
relationships, concepts between the meta-tagged data.
The interoperability of this tagged data would further be
provided by the ontology integration/mapping. Although
these form a major part, another crucial concern for
interoperability is relativity of data depending upon the
frame of Reference in which it is required.
3 Fractals and the Semantic
Relativity
Fractal is an age old concept as proposed by Mandelbrot
in his paper [26]. He described various natural structures
like mountains, clouds etc through fractal geometry. As
mentioned earlier, in the recent past this fractalness has
also been found in the web data itself [27], [28]. In order
to fully utilize the potential of these two, the merging of
‗Geographic Fractal‘ with the ‗Information Fractal‘ is of
utmost importance at the moment. Fractals are structures
or patterns which shows self similarity as they are
magnified, depicting the complexity which hides in them.
Other features of fractals are that of self-organization and
self-regulation. This Fractal geometry is best described
by using ‗Power Law‘. Keeping this mathematical
relation in mind, the fractal dimension ‗D‘ of a fractal
has been calculated as D= log s B [31], where ‗s‘ is the
scaling factor that is the depth of zooming done and ‗B‘
is the branching factor that is the number of branches or
sub-fractals patterns a given fractal is divided into. Here,
Fractal Dimension ‗D‘ is a non-integer number. Figure 1
explains this fractal concept. Here we have visualized the
whole globe as a Big Fractal in which various sub-
fractals are present. The number of these sub-fractals at
any level would be the branching factor of that level and
thus would in turn have many sub-fractals.](https://image.slidesharecdn.com/paper-ontofrac-s-150924153959-lva1-app6892/85/OntoFrac-S-2-320.jpg)
![zz (2011) xxx–yy xxx
Figure1: Fractal Communities
Each of the depicted branches/sub-fractals in a given
fractal can be considered as its nodes. Corresponding to
each of the level, a fractal value is assigned to each of the
node in that level. Assuming fractal value of the top level
fractal node to be 1, the fractal value of sublevels is
computed as: F v+1 = s* Fv =C*Bv+1 ^(-1/D) [31], where
C is a constant such that 0<C<=1. Fractal dimension ‘D‘
denotes the amount of information contained in that
fractal. However, the fractal value Fv can aid us in setting
the dynamic abstraction level for viewing the
information. Works like [32],[33],[34] propose that these
fractal values help us in filtering the unneeded content by
setting a fractal threshold and information
above these threshold will be visible to the user to help
him find the correct information. These two concepts
play a vital role in designing a framework for semantic
communication across the globe by taking into account
the ‗Semantic Relativity‘. For us, to explain in simple
terms, the words ‗Semantic Relativity‘ imply that the
meaning of terms and concepts doesn‘t change with the
change in frame of reference. An instance explaining
this non- relativity of the semantics has been mentioned
above where for two different people in different frame
of references, the same term would be inferred
differently. The same has been depicted in Figure 2.
Here, for a person standing in 1st
frame of reference
(which is global view), the term ‗local‘ would mean
something that is adopted in the two countries X and Y.
However, for another person standing in 2nd
frame of
reference (as Country X), the same term local would
mean something that is conceptualized within 2 different
states of the same country ‗X‘. A need for semantic
elucidation by specifying the frame of reference along
with the concept in which it has been conceptualized is
of utmost importance to make the information
interoperable. This proposition has been explained in the
next section.
4 Proposed Approach
One would agree that the geographical divisions
(which also denote the non-relativity in semantics)
cannot be constrained within the Euclidean structures
like circle, triangle etc. Similar, is the case with data
which drives us to explore the world of fractals.
Ontological complexities which have become an
impediment to the fast pace progress of Semantic Web
vision can best be explained and simplified using
fractals. Thus, in order to address these complexities, we
propose an ‘OntoFrac-S’ Web which is an acronym for
‘Semantic- Ontology Fractals’ (Here, ‗S‘ represents the
Semantic Web).
Figure 2: Example of Non-Semantic Relativity
The ‗OntoFrac-S‘ federated Semantic Web system is
conceptualized to be a multi-layered, multi-agent
ontological system. The ‗OntoFrac-S‘ fractal federation
accounts for the fact that the world is divided into
various regions and sub-regions, each of which follow
their own unique ontology. This has been denoted by](https://image.slidesharecdn.com/paper-ontofrac-s-150924153959-lva1-app6892/85/OntoFrac-S-3-320.jpg)
![zz (2011) xxx–yy xxx
several Frac-S (Semantic Fractals) who would represent
a specific geographical region. Each frac-S fractal would
have a Fractal Focal Point (following a common upper
level local ontology within that frac-S) as shown in
Figure 3.
OntoFrac :
Layer 1
OntoFrac :
Layer 4
OntoFrac :
Layer 3
OntoFrac :
Layer 2
Fractal
Focal Points Dynamic Inter-Fractal
Communication
Figure 3: Ontofrac-S
This Fractal Focal Point would be represented by an
agent in the software system and is not any physical
entity. Similar to OntoShells in GUN [35], a frac-S
would have a fractal profile.The frac-S focal agent would
have a OntoFrac-S profile. This profile would contain
the information about its sub-fractals and agents in that
fractal. Each fractal would have the autonomy to manage
the work inside that profile. Any Fractal Focal Point
would act as a Black Box for the outside world, sharing a
common ontology or a local ontology for that fractal.
This would define only an upper level ontology for the
fractals inside it. Not to forget that the term
‗foundational/ upper level ontology‘ is a relative term as
mentioned earlier. The actual referred ontology would
depend on the frame of reference one may find himself
into. The granularity of the ontology would increase as
the fractal layer level increases. The fractal would act as
an abstraction where one would not be needed to search
for each and every resource/agent. Instead fractal focal
point would do that for you. The fractal profile will help
to accomplish this task.
Any outside agent (outside a given fractal) will have
to contact its respective fractal focal point (frac-S focal
agent) before any interaction with the inside fractal
world. Some other responsibilities of this Fractal Focal
Point alias the Frac-S Focal agent would be:
- Broadcasting of Advertised Messages to relevant
Agents/ sub-fractals within that respective fractal.
- Establishing a communication channel between two
fractals by Ontology Mapping and integration. It may be
viewed as the entry point into the fractal.
- Containing information about local agents and sub-
fractals in the Fractal Profile.
- Reject messages which might not be considered as
relevant to that fractal profile.
- Entry/Exit point of all Global queries.
- Resolving local frac-S queries.
- Flexibility to manage information within its focus.
A ‗frac-S‘ is considered to be a region containing a
fixed amount of information ‘I‘. An automatic dynamic
re-configuration would happen within this fractal when
this information content ‗l‘ would exceed a given
Threshold ‗T‘ or become ‗unstable‘ to say so as seen in
Figure 4. This re-configuration will result into automatic
creation of new sub-fractal regions within that fractal.
The effect of this re-configuration will be to make the
fractal ‗stable‘ by keeping the managed information
content level by any frac-S focal point within a given
threshold as shown in Figure 4.
Q). How would fractal re-configuration result into
‗stability‘?
Answer: As mentioned earlier, fractal reconfiguration
would result into the creation of dynamic sub-fractals
which would themselves have the autonomy to manage
the information inside them, thereby relieving its
immediate upper level fractal of some responsibilities.
The outside fractal would have to contact that respective
sub- frac-S for referring to any information inside it.
Thus, issue of manageability of the information would be
solved. This would automatically provide stability as
then the fractal would have to manage less amount of
information (within T).
Some would further argue that how would adoption
of a tree like hierarchical ontological approach would
simply the things rather than complicating it? Concerns
like why to think about ontology relativity when
information is already relative can be raised? But
assigning each Frac-S focal agent with a local ontology
of that frac-S would help simplify the task of ontology
management and further enhance interoperability by
contacting respective Ontology OntoFrac-S Focal
Agents.
Similar to the concepts of sub-sets in Mathematics
and sub-classes in Computer Science, human
communities too inherit some global properties while
adhering to exclusive regional properties. Consider for
example, a person living in country C and state S inherits
some characteristics of its country, some from his state
and some other which would be individual. The same
should be replicated in the information present in the
Semantic Web system backed by an equally compatible
ontology. Fractal approach allows us to address this
feature. Consider a situation where a person says ―You
would have to take it from a nearby bank‖. It depends on
the frame of reference which will define as to which
‗bank‘ the person is referring to? Assuming, Frame of
Reference (FoR) = Context, Context can be thought of
as being divided into two major components namely,
physical and psychological. There are two ways of
determining these contexts- Sensors and Agents. Sensors
are definitely an effective way. But embedding sensors
everywhere would not sound to be a feasible idea.
However, these local agents or the software programs
would replicate the same without incurring physical
sensor‘s much higher cost. In order to perform this task,
OntoFrac-S model would be an aid. To ascertain the
context, local agents (local to any fractal) would be](https://image.slidesharecdn.com/paper-ontofrac-s-150924153959-lva1-app6892/85/OntoFrac-S-4-320.jpg)




![zz (2011) xxx–yy xxx
Step 7: Bid evaluation (See part C of the algorithm)
Step 8: If (Bid_evalReply==‟Successful‟) then
goto step 10
/*Announcement of successful bidder*/
Else
goto Step 9
Step 9: If (Bid_evalReply==‟Unsuccessful‟) then
{ If (frac-S threshold>min_frac-S
threshold) then
/* More upper level fractals available*/
{
Frac-S threshold value= Frac-S
threshold value – decrease_factor
Goto Step 3
/* To Contact more upper level frac-S
fractals*/.
}
Else
Return (Winner=0)
}
Elseif (winner==1 && no_of_winner>1)then
Return((winner=1,number_of_winner>1,
details of equal scorers)
Step 10: Inform(successful_bidder,terms of
agreement)
Step 11: Wait(Successful_bidder->ack)
/*Wait for the acknowledgement from the
successful bidder for accepting terms of the
contract*/
Step 11: If (Bidder_ack==”Yes”) then
{ Clear(Bid_eval_buffer)
If(Agentx(submitted_bid)==1) then
{
Broadcast(query_id, (initiator Agent
URI, associated frac-S agent URI,
winner_details)
/*Announce successful winner to all
agents who have submitted*/
}
Return(Winner=1, No_of_Winners
=1 ,Winner_details)
}
else
Bid_eval(bidder_Ack=”No”)
/* Not accepted the bid*/
C. Bid Evaluation Algorithm:
Step 1: If ((bid_eval==1) && (bidder_ack=‟No‟))
then
{Remove(successful_bid->bid_eval_buffer)
Goto step 8
/* Removing not acknowledged bid from the bid
evaluation buffer and re-evaluating */
}
else
goto step 2
Step 2: Bid_eval=bid_response1
Step 3: /*Check received bid response announcement
identifier. */
If( received (and) =required (and))then,
proceed to Step 4,
else
reject Bid
Goto Step 6
Step 4: Bid_Response_sim_perct=Percenti
/*Assign similarity percentage between the
announced bid and received bid response to each
bid response*/
Step 5: Bid_Response_Scorei = Percenti /
Prpsd_Cmpltn_Timei
/*Assign a score to the bid using the formula: Specialization
Similarity Percentage/Proposed Task completion time*/
Step 6: If(All_Bid_evaluated==1)then
Goto Step 7
Else
{
If (Bid_Response_Scorei>Highest_Score)then
{ Highest_Score= Bid_Response_Scorei
}
eval_bid=Next_Bid_Response
goto step 3
}
/*While all the proposals not evaluated, take the next bid for
evaluation*/
Step 7: bid_eval_buffer=[All evaluated bids ]
Step 8: w_bid=bid_response1
No_of_winners=0
While(w_bid !=last_bid_response)
{
If ((Bid_Response_Scorei==Highest_Score) &&
(Bid_Response_Scorei>80)) then
{ if (No_of_winners==0) then
{ Successful_Bid= Bid_Responsei
Winner=1
No_of_winners+=1;
}
Else
Return(winner=1,number_of_winner>1,
details of equal scorers)
}
}
/*Assign the bid with the maximum score and having score
>80 as the „Successful bid‟ and winner=1.However, if more than 1
bidder has highest score then sending details of all these to the
agent*/
Step 9: If (No_of_Winners==0)then
Return(Bid_eval_response=”Unsuccessful”)
/*If no unanimous bidder (having score >80) wins then
„Unsuccessful‟ message is sent to the initiator agent.*/
5 Semantic Communication in
the Complex Multi-Agent Medical
World using OntoFrac-S
Semantic Web won‘t prove to a boon if it won‘t
aid the humans in performing their various
operations. Applications to which the ‗GGG‘ is put to
use will decide the fate of this next level technology.
One of the major area having high hopes from this
Globally Linked Graph is Medical Science. Long
written concept like tele-medicine would only
blossom full fledge after the successful](https://image.slidesharecdn.com/paper-ontofrac-s-150924153959-lva1-app6892/85/OntoFrac-S-9-320.jpg)
![zz (2011) xxx–yy xxx
implementation of Semantic Web. Thus, we cite a
real world example from the Medical World and
show how such a situation would be efficiently
managed by adopting the ‗OntoFrac-S‘ methodology.
Physicians often need to consult with fellow
physicians to decide on some medical problem.
Further, they would require someone‘s assistance in
referring to similar cases or fetching some medical
data from a distance etc. In order to aid physicians in
performing these tasks, agents have been thought of
as a reliable option as seen in [36], [37], [38]. Using
this as a starting point for our example, we assume
that a ‘Factotum Agent’ is associated with each
physician. Here the word ‗factotum‘ means an ‗All
Purpose Assistant‘. Thus, a factotum agent would
perform all necessary tasks for a physician in the web
world and aid him in his efficient decision making. A
myriad of work done on Multi-Agent Systems [39],
[40], [41] concentrate on formation of a team by
various agents where each agent would be
performing a different task in order to fulfill a preset
aim. A very few of them propose on attaching agents
with individuals. We have adopted this latter
approach as we strongly feel that in the semantic web
each agent needs to have an individual identity like
the resource itself. As proposed in the Semantic Web
approach each resource be it human, thing etc would
have an URI associated with it. However, keeping in
mind the security and management concerns of the
resource, we would need to provide each resource
with a brain. This brain would be provided by
associating with them exclusive agents who would
provide access to authorized users, manage
information, provide flexibility, autonomy,
collaboration in the web system etc. Thus, in doing so
the URI linked to a resource would be efficiently
managed by its respective agent. This, agent in the
Medical World we have called as ‗Factotum‘.
Considering, this Factotum Agent to be present
in the OntoFrac-S World, let us see how will the real
world problems in the medical domain would easily
be tackled. Our situation is as follows:
Situation: ‗A patient approaches a physician to
get diagnosed. He has been having high fever for
some days and thus, he has got his medical tests done
from a nearby hospital named ‗HSPTL‘ on the
recommendation of a doctor named ‗DCTR‘.
However, he hasn‘t collected his reports from the
Pathology Section (PTHLGY) of the hospital. Now,
he approaches the physician for getting diagnosed.‘
Situation Management using OntoFrac-S:
Having provided the detailed algorithm of OntoFrac-
S, let us understand how this patient-physician
situation will be handled in Semantic Web using our
proposed approach. Aftermath the arrival of patient
(Pati), Physician (Phi) would assign his associated
Factotum ‗Fi‘, the task of ‗firstly getting EHR from
PTHLGY section of HSPTL and then getting
suggestions from friend physicians on the possible
illness of the patient using this EHR‘. In order to do
so Phi commands Factotum Fac_i as ―Get report of
Mr. ABC from PTHLGY section of HSPTL hospital
nearby and then consult other physicians on the
illness.‖ After receiving the request from Phi, Agent
Fac_i in Frac-S ‗Fr-Oi‘ divides the process into
Sub-TASK 1: Getting EHR of Mr. ABC, who is
having high fever from nearby HSPTL hospital,
Sub-TASK 2: using his EHR, Consulting friend
Physicians on the illness of Mr. ABC who is having
high fever.
In accomplishing each of the two sub-tasks the
following two major stages are encountered:
i). Identifying the Frame of Reference in which the task
been allotted in order to form a non-relative query
ii). Bidding and finding the solution using this non-relative
query as framed in i).
The 1st
stage is divided into three steps:
i) Searching the assigned task sentence to provide
non-relativity in the query. If this doesn‟t
succeed then follow step ii.
ii) Searching Experience Database of the physician.
If still not succeeded then follow step iii
iii) Finding the Environmental context and query
user/physician for clarifications (if
required).
Following this methodology, in the 1st
Sub-task, the
term ‗nearby‘ looks to be a vague term and would
sound differently to people in different frames of
reference. Thus, simply bidding on the identified sub-
task cannot be performed. In order to do so, the query
has to be made non-relative by clearly identifying as
to which HSPTL Hospital, the physician is referring
to as it might happen that more than one hospital may
have the name as ‗HSPTL‘. Thus, firstly clarity is
sought in finding the exact URI of this hospital
HSPTL using the FoR part of the algorithm (as
mentioned in the previous section). Next, a non-
relative query is formed by replacing the ambiguous
term ‗nearby‘ with the exact location (URI) of the
HSPTL to which the physician is referring to. Then
Contract Net Protocol is followed in an iterative frac-
S order (from local to global) to search for an agent
who would get this sub-task done. Having finished
with sub-task 1, Factotum proceeds to Sub-Task 2.
Here again, the two step process mentioned above is
followed. Here the ambiguity is with respect to the
word ‗friend physicians‘. This equivocalness is
removed by firstly finding as to which Physician, Phi
is referring to. Here syntactical sentence doesn‘t
provide much help and FoR is generally found in step
ii of Stage 1 (that is using experience database).
Physician‘s database will generally aid in finding out](https://image.slidesharecdn.com/paper-ontofrac-s-150924153959-lva1-app6892/85/OntoFrac-S-10-320.jpg)

![zz (2011) xxx–yy xxx
URI would be unique, there would be many who
would have the same resource name and it would be
difficult to identify if this resource refers to Context
A or B. Thus, here we would like to give a simple
proposition that prefixing resource with the frac-S
location in which the resource is present like
http://www.abc.xyz/frac-Slocation/resource would
help easily identify the Frame of Reference in which
that resource name has been used. This task would be
carried out by contacting the linked frac-S to know
ontology it is using. This in turn would tell the
context of resource. Although, a small change, it can
help easy retrieval of the information with higher
accuracy from GGG.
Further, although various schemes for Multi-Agent
have been proposed like but we preferred using
Contract Net Protocol for of our communication.
Some have even pointed out the concern of having
bandwidth requirement using Contract Net Protocol.
This shortcoming is eliminated in our approach as
during Contract Net, the agent doesn‘t need to send
the broadcast message to each and every agent. The
initiator agent (factotum in our case) only needs to
send the message to all Fractal Focal Points of
respective regions, who would further broadcast the
message in their respective fractal regions. This in
turn would reduce the bandwidth limitations.
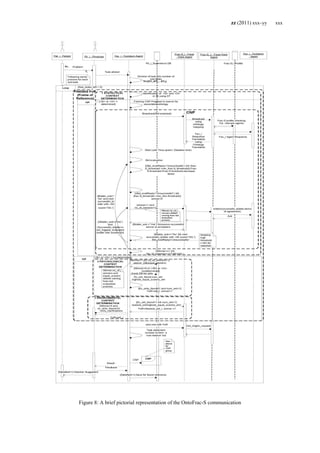
Figure 9 shows the OntoFrac-S framework with
respect to the technological front. As could be seen in
the figure on receiving a task, each agent sends it to
the inference engine. This inference engine contains a
natural language processing module for dividing a
task into sub-tasks using lexical measures.
WORDNET therasus ontologies can be used for this
purpose. After passing to the NLP module, context
determination module will be called. After
determination of the context, a query would be
generated for finding the solution. This query would
be sent as SPARQL [42] query to the frac-S focal
agent would in turn generate a semantic SPARQL
query after Ontology Mapping. Several of lexical
measures provide ways for ontology matching like n
gram similarity, Hamming Distance, cosine similarity
etc.
Also, all inter agent communication would be
held using ACL (Agent Communication Language).
Here OWL, ACL and SPARQL are so chosen
because they are W3C standards.
Further, Concerns on interoperability between
EHRs etc need not be ruffled with for providing a
global schema. Instead of that EHR ontologies would
be mapped on a need to know basis.
GUI
AGENT
(Physici
an
Factotu
m)
Physican
Patient
Frac-S
i Focal
Point
(Agent)
Frac-S i
Ontology
Frac-S
j Focal
Point
(Agent)
SPAR
Q
L
query
Ontology Matching
RDF
Triple
Store
Frac-S j
Ontology
Hospital
EHR
RDF
Triple
Store
Hospital
Domain
OntologyACL Communication
Frac-S j Profile (K
base of 1st level
sub Fracs-S and
agent)
Semantic SPARQL Query
Physic
an K
base
Result
ACL reply
Task
Illness
Inference
Engine
Context
Determination
Query
Generation
NLP
Sub-
Frac-S
j
Hospita
l Focal
Point
(Agent)
Sub-
Frac-S
j Focal
Point
(Agent)
ACLCommunication
Physic
an K
base
Physican
Rule
Engine
C
ure
Figure 9: OntoFrac-S Model
9 Future Work
One of the biggest advantages with this approach
is in implementation wherein a small area would
replicate the behaviour of the actual global space due
to the properties of fractal approach adopted. Thus, as
mentioned earlier even an implementation in a small
university or area would be useful to able to justify
its usefulness for the whole globe.
Thus, the next step could be to implement this
approach on a small scale. Figure 10 shows a sample
GUI screen that a physician would have in front
of him in order to interact with his associated agent
alias ‗Factotum‘
10 Conclusion
Through this paper, we just to want to focus on
the fact that if human races follow irregular patterns
and are fractal in nature then its replication on the
web cannot be seen as merely adopting a global view
approach for providing semantic interoperability. It
must be remembered that ontologies which are](https://image.slidesharecdn.com/paper-ontofrac-s-150924153959-lva1-app6892/85/OntoFrac-S-13-320.jpg)
![zz (2011) xxx–yy xxx
defined by the communities should be given their
autonomy. Simultaneously, the distributed-ness of the
global society must not pose an issue for
interoperability. Aggregation of these two concepts
was provided in this paper using effective Ontology
Management.
OntoFrac-S seems to be a promising approach
for the successful implementation of Semantic web
and provides a paradigm shift towards ‗Semantic
Relativity‘ in the Globally Linked Graph. Our aim
was to highlight this less trodden path of ‗Semantic
Relativity‘ which seems to address the cross
cultural/cross- geographical barriers using fractals.
We strongly feel that this approach seems to provide
the missing link in the Semantic Web. We hope that
more technological research in this field would open
rooms for many more exploration in the years to
come.
Figure 10: Sample GUI Screen in OntoFrac-S System for aiding Physicians using ‗Factotum Service‘
11 References
[1] Tim Berners Lee, The Semantic Web
http://www.scientificamerican.com/article.cfm?i
d=the-semantic-web
[2] A. Brasoveanu, A. Manolescu,
M.N.Spinu, Generic Multimodal ontologies for
Human-Agent Interaction, Int. J. of Computers,
Communication & Control, ISSN 1841-9836,
Vol. V(2010), No. 5, pp. 625-633
[3] I.F.Toma, Contributions to the Study of
Semantic Interoperability in Multi-Agent
Environments- An Ontology Based Approach,
Int. J. of Computers, Communication & Control,
ISSN-1841-9836, Vol. V(2010), No. 5, pp. 946-
952
[4] Ahmad Adel Abu Shareha and others,
Multimodal Integration (Image and Text) Using
Ontology Alignment, American Journal of
Applied Sciences 6 (6): 1217-1224,2009, ISSN
1546-9239
[5] Jérȏme Euzenat, An API for ontology
alignment, The Semantic Web – ISWC-2004,
Springer
[6] Mike Uschold, Creating, integrating and
maintaining local and global ontologies,
Citeseerx](https://image.slidesharecdn.com/paper-ontofrac-s-150924153959-lva1-app6892/85/OntoFrac-S-14-320.jpg)
![zz (2011) xxx–yy xxx
[7] Farshad Hakimpour, Andreas Geppert,
Resolving Semantic Heterogeneity in Schema
Integration: An ontology Based Approach
http://portal.acm.org/citation.cfm?id=505168.50
5196
[8] Namyoun Choi, Il-Yeol Song, and Hyoil
Han, A Survey on Ontology Mapping, SIGMOD
Record, Vol. 35, No. 3, Sep. 2006.
http://portal.acm.org/citation.cfm?id=116809
7
[9] H.Wache and others, Ontology-Based
Integration of Information —A Survey of
Existing Approaches, In: Proceedings of IJCAI-
01 Workshop: Ontologies and Information
Sharing, Seattle, WA,2001,Vol. pp. 108-117
www.let.uu.nl/~paola.monachesi/personal/papers
/wache.pdf ???
[10] Isabel F. Cruz, Huiyong Xiao, Feihong
Hsu,An Ontology-based Framework for XML
Semantic Integration,
[11] Gerd Stumme Alexander Maedche,
Ontology Merging for Federated Ontologies on
the Semantic Web
[12] Diego Calvanese, Ontology of
integration and integration of ontologies
[13] Giant Global Graph
http://en.wikipedia.org/wiki/Giant_Global_Grap
h
[14] Tim Berners-Lee and Lalana Kagal,The
Fractal Nature, of the Semantic Web, AI
Magazine, Vol 29, No. ,
http://www.aaai.org/ojs/index.php/aimagazine/ar
ticle/viewArticle/2161
[15] Christopher C. Yang and other ,
Visualization of large category map for internet
browsing, Decision Support Systems
Volume 35, Issue 1, April 2003, Pages 89-102,
Elsevier
[16] Virgílio Almeida, On the Fractal Nature
of WWW and Its Application to Cache
Modelling, 1996
http://portal.acm.org/citation.cfm?id=859832
[17] Ravi Kumar, The Web and Social
Networks, IEEE, 2002, Volume: 35 Issue: 11,
Pages: 32 - 36
[18] Gilbert Harman, Quine‘s Semantic
Relativity
http://www.princeton.edu/~harman/Papers/Harm
an-Quine.pdf
[19] W.V. Quine, Ontological Relativity, The
Journal of Philosphy, Vol. 65, No. 7. (April 4,
1968), pp 185-212,
http://www.jstor.org/pss/2024305
[20] Laurent Nottale, Scale Relativity, Fractal
Space-Time, and Quantum Mechanics, Chaos,
Solitons & Fractals, Volume 4, Issue 3, March
1994, Pages 361-388 Elsevier,
http://linkinghub.elsevier.com/retrieve/pii/09
60077994900515
[21] Kwangyeol Ryu, Agent-based fractal
architecture and modelling for distributed
manufacturing systems, International Journal of
Production Research, 2003, Taylor & Francis
Ltd., Vol. 41, No. 17, 4233-4255
[22] Kwangyeol Ryu, Modeling and
Specifications of Dynamic Agents in Fractal
Manufacturing System, Volume 52 Issue 2,
October 2003, Computers in Industry, ACM
http://portal.acm.org/citation.cfm?id=948693
[23] Huiying Gao, Qian Zhu, Semantic Web
based Multi-agent Model for the Web Semantic
Service Retrieval, 2009 Computer Network and
Multimedia Technology, 2009. CNMT 2009.
International Symposium on
page:1 – 4, IEEE
[24] C. Cubillos, Towards Open Agent
Systems Through Dynamic Incorporation, Int. J.
of Computers, Communications & Control,
ISSN 1841-9836, Vol. V (2010), No. 5, pp. 675-
683
[25] Ioan Dzitac,Artificial Intelligence +
Distributed Systems = Agents, Int. J. Computers,
Communications & Control, Vol IV(2009), No.
1, pp. 17-26
[26] B.B. Mandelbrot, Fractals and
the Geometry of Nature, W. H. Freeman and Co.,
1982, ISBN 0-7167-1186-9
[27] Gary William Flake and David M.
Pennock,Yahoo! Research Labs, Self-
organization, self-regulation and self-similarity
of fractal web, The Colours of Infinity, Clear
Press, UK (2004)
http://dpennock.com/papers/flake-colours-
2004-fractal-web.pdf,
http://www.springerlink.com/content/ut65570
532670154/
[28] Stephen Dill, Self- Similarity in the
Web, ACM Transactions on Internet
Technology, Vol. 2, No. 3, August 2002, Pages
205–223.
[29] G. Caldarelli , Fractal properties of
Internet, http://arxiv.org/abs/cond-mat/0009178
[30] Damin Xu, Fractal and Mobile Agent-
based Inter-enterprise Quality Tracking and
Control, 2008 IEEE international conference on
industrial technology (IEEE ICIT 2008)
[31] Fractal Dimension, Wikipedia
http://en.wikipedia.org/wiki/Fractal_dimension](https://image.slidesharecdn.com/paper-ontofrac-s-150924153959-lva1-app6892/85/OntoFrac-S-15-320.jpg)
![zz (2011) xxx–yy xxx
[32] Koike, H. ,Fractal Approaches for
Visualizing Huge Hierarchies Proceedings of the
1993 IEEE Symposium on Visual Languages,
pp.55-60, IEEE/CS, 1993
[33] Hideki Koike, Fractal Views: A Fractal
Based Method for Controlling Information
Display, ACM Transaction on Information
Systems, Vol. 13, No. 3, July, pp.305-323,
ACM, 1995,
http://portal.acm.org/citation.cfm?id=203065
[34] Christopher C. Yang, Fractal
summarization for mobile devices to access large
documents on the web, WWW '03 Proceedings
of the 12th international conference on World
Wide Web, 2003
http://portal.acm.org/citation.cfm?id=775183
[35] Vagan Terziyan , Semantic Web
Services for Smart Devices in a ―Global
Understanding Environment‖
http://www.cs.jyu.fi/ai/papers/HCISWWA-
2003.pdf
[36] Barna Iantovics, CMDS Medical
Diagnosis System, Ninth International
Symposium on Symbolic and Numeric
Algorithms for Scientific Computing, 2007,
IEEE, pg 246
[37] Rosa M. Vicari, A multi-agent intelligent
environment for medical Knowledge, Artificial
Intelligence in Medicine 27 (2003) 335–366,
Elsevier
http://www.cs.usask.ca/faculty/sal426/SensorGri
d/docs/MED_MULTIAGENT/A%20multi-
agent%20intelligent%20environment%20for.pdf
[38] V. Alves, Agent Based Decision Support
System in Medicine , WSEAS Transactions on
Biology and Biomedicine,2005
http://repositorium.sdum.uminho.pt/handle/1
822/2721
[39] M. Pipattanasomporn, Multi-Agent
Systems in a Distributed Smart Grid: Design and
Implementation, Power Systems Conference and
Exposition, 2009. PSCE '09. IEEE/PES, March
2009
[40] Xianyi Cheng, Study of Multi-
Agent Information Retrieval Model in Semantic
Web, 2008 International Workshop on Education
Technology and Training & 2008 International
Workshop on Geoscience and Remote Sensing,
IEEE
[41] Huiying Gao , Semantic Web based
Multi-agent Model for the Web Service Retrieval,
The First International Symposium on Computer
Network and Multimedia Technology
2009,CNMT 2009, IEEE
[42] SPARQL,
http://www.w3.org/TR/rdf-sparql-query/](https://image.slidesharecdn.com/paper-ontofrac-s-150924153959-lva1-app6892/85/OntoFrac-S-16-320.jpg)

This document proposes an approach called "OntoFrac-S" to handle the increasing number of ontologies being created for the semantic web. It suggests using fractals and multi-agent systems to implement the semantic web and link data in a way that accounts for the fractal and self-similar nature of data at different levels. Specifically, it argues that merely integrating local and global ontologies is not sufficient, and that ontologies should be viewed as relative concepts depending on the scale, with each local ontology potentially acting as a global ontology for lower-level sub-ontologies. The approach aims to apply concepts of semantic and ontological relativity using fractals to help build a semantically linked global graph while addressing cross-c



































































