Download as PDF, PPTX


![SGA Undo Segment
Shared Pool
Buffer Cache
Undo Header
index state cflags wrap# uel scn dba
--------------------------------------------------------------------------------
0x00 9 0x00 0x04ec 0x0001 0x0000.003d6d72 0x00000000
0x01 9 0x00 0x04ec 0x0002 0x0000.003d6d72 0x00000000
0x02 9 0x00 0x04ec 0x0003 0x0000.003d6d72 0x00000000
Undo Block
* Rec #0x1
BH
Data Block
ITL
Itl Xid Uba Flag Lck Scn/Fsc
Rows
block_row_dump:
tab 0, row 0, @0x1f88
tl: 16 fb: --H-FL-- lb: 0x1 cc: 2
col 0: [10] 31 20 20 20 20 20 20 20 20 20
col 1: [ 1] 41
ASCII HEXA code 41
=> Value ‘A’
V$transaction
XID_INFO UBA_INFO TXN_INFO
-------------------------- --------------- --------------------
addr : status : IDLE
xidusn : ubafil : start_date : 2015-12-10 10:52:46
xidslot : ubablk : ses_addr : 000000006B21CC20
xidsqn : ubasqn :
0. Initial state when a value of "A" is entered (The first stage before update)](https://image.slidesharecdn.com/pdfodi2undorecordchaining-160518090511/75/ODI-chapter2-what-is-undo-record-chaining-4-2048.jpg)
![SGA Undo Segment
Shared Pool
Buffer Cache
1. UPDATE T1 SET C2='B'
v$transaction
XID_INFO UBA_INFO TXN_INFO
-------------------------- --------------- --------------------------------
addr : 0000000069B24E78 ubafil : 6 status : ACTIVE
xidusn : 10 ubablk : 210 start_date : 2016-01-13 18:57:04
xidslot : 0 ubasqn : 532 ses_addr : 000000006B21CC20
xidsqn : 1424 ubarec : 1
Undo Header
index state cflags wrap# uel scn dba
----------------------------------------------------------------
0x00 10 0x80 0x0590 0x0000 0x0000.004c2039 0x018000d2
0x01 9 0x00 0x058f 0x0002 0x0000.004bca7f 0x00000000
Undo Block
BH (0x643fb068) file#: 6 rdba: 0x018000d2 (6/210) class: 36 ba: 0x643ce000
xid: 0x000a.000.00000590 seq: 0x214 cnt: 0x1 irb: 0x1 icl: 0x0 flg: 0x0000
Rec Offset Rec Offset Rec Offset Rec Offset Rec Offset
---------------------------------------------------------------------------
0x01 0x1f44
*-----------------------------
* Rec #0x1 slt: 0x00 objn: 70870(0x000114d6) objd: 70870 tblspc: 5(0x00000005)
* Layer: 11 (Row) opc: 1 rci 0x00
op: Z
itli: 2 ispac: 0 maxfr: 4858
vect = 11
col 1: [ 1] 41
BH (0x643fb1a0) file#: 5 rdba: 0x0140dcab (5/56491) class: 1 ba: 0x643d0000
st: XCURRENT md: NULL fpin: 'kdswh11: kdst_fetch' tch: 1
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0006.000.0000056a 0x00000000.0000.00 C--- 0 scn 0x0000.004c2027
0x02 0x000a.000.00000590 0x018000d2.0214.01 ---- 1 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
tl: 16 fb: --H-FL-- lb: 0x2 cc: 2
col 0: [10] 31 20 20 20 20 20 20 20 20 20
col 1: [ 1] 42
BH (0x643fb2d8) file#: 5 rdba: 0x0140dcab (5/56491) class: 1 ba: 0x643d2000
st: CR md: NULL fpin: 'kdswh11: kdst_fetch' tch: 1
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0006.000.0000056a 0x00000000.0000.00 C--- 0 scn 0x0000.004c2027
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
tl: 16 fb: --H-FL-- lb: 0x0 cc: 2
col 0: [10] 31 20 20 20 20 20 20 20 20 20
col 1: [ 1] 41
Before Image
ASCII HEXA code 41
=> Value ‘A’
Before Image
ASCII HEXA code 41
=> Value ‘A’
After Image
ASCII HEXA code 43
=> Value ‘C’
Uba+seq+record#UPDATE T1
SET c2 = ‘B’](https://image.slidesharecdn.com/pdfodi2undorecordchaining-160518090511/75/ODI-chapter2-what-is-undo-record-chaining-5-2048.jpg)
![SGA Undo Segment
Shared Pool
Buffer Cache
2. UPDATE T1 SET C2=‘C'
v$transaction
XID_INFO UBA_INFO TXN_INFO
-------------------------- --------------- --------------------------------
addr : 0000000069B24E78 ubafil : 6 status : ACTIVE
xidusn : 10 ubablk : 210 start_date : 2016-01-13 18:57:04
xidslot : 0 ubasqn : 532 ses_addr : 000000006B21CC20
xidsqn : 1424 ubarec : 2
Undo Header
index state cflags wrap# uel scn dba
----------------------------------------------------------------
0x00 10 0x80 0x0590 0x0000 0x0000.004c2039 0x018000d2
0x01 9 0x00 0x058f 0x0002 0x0000.004bca7f 0x00000000
Undo Block
BH (0x643fb068) file#: 6 rdba: 0x018000d2 (6/210) class: 36 ba: 0x643ce000
xid: 0x000a.000.00000590 seq: 0x214 cnt: 0x2 irb: 0x2 icl: 0x0 flg: 0x0000
Rec Offset Rec Offset Rec Offset Rec Offset Rec Offset
---------------------------------------------------------------------------
0x01 0x1f44 0x02 0x1ecc
*-----------------------------
* Rec #0x1 slt: 0x00 objn: 70870(0x000114d6) objd: 70870 tblspc: 5(0x00000005)
* Layer: 11 (Row) opc: 1 rci 0x00
op: Z
itli: 2 ispac: 0 maxfr: 4858
vect = 11
col 1: [ 1] 41
*-----------------------------
* Rec #0x2 slt: 0x00 objn: 70870(0x000114d6) objd: 70870 tblspc: 5(0x00000005)
* Layer: 11 (Row) opc: 1 rci 0x01
op: C uba: 0x018000d2.0214.01
itli: 2 ispac: 0 maxfr: 4858
vect = 11
col 1: [ 1] 42
BH (0x643f8e48) file#: 5 rdba: 0x0140dcab (5/56491) class: 1 ba: 0x64396000
st: XCURRENT md: NULL fpin: 'kdswh11: kdst_fetch' tch: 1
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0006.000.0000056a 0x00000000.0000.00 C--- 0 scn 0x0000.004c2027
0x02 0x000a.000.00000590 0x018000d2.0214.02 ---- 1 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
tl: 16 fb: --H-FL-- lb: 0x2 cc: 2
col 0: [10] 31 20 20 20 20 20 20 20 20 20
col 1: [ 1] 43
BH (0x643fb2d8) file#: 5 rdba: 0x0140dcab (5/56491) class: 1 ba: 0x643d2000
st: CR md: NULL fpin: 'kdswh11: kdst_fetch' tch: 1
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0006.000.0000056a 0x00000000.0000.00 C--- 0 scn 0x0000.004c2027
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
tl: 16 fb: --H-FL-- lb: 0x0 cc: 2
col 0: [10] 31 20 20 20 20 20 20 20 20 20
col 1: [ 1] 41
BH (0x643fb1a0) file#: 5 rdba: 0x0140dcab (5/56491) class: 1 ba: 0x643d0000
st: CR md: NULL fpin: 'kdswh11: kdst_fetch' tch: 1
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0006.000.0000056a 0x00000000.0000.00 C--- 0 scn 0x0000.004c2027
0x02 0x000a.000.00000590 0x018000d2.0214.01 ---- 1 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
tl: 16 fb: --H-FL-- lb: 0x2 cc: 2
col 0: [10] 31 20 20 20 20 20 20 20 20 20
col 1: [ 1] 42
After Image
ASCII HEXA code 43
=> Value ‘C’
Before Image
ASCII HEXA code 42
=> Value ‘B’
Before Image
ASCII HEXA code 42
=> Value ‘B’
Before Image
ASCII HEXA code 41
=> Value ‘A’
UPDATE T1
SET c2 = ‘C’](https://image.slidesharecdn.com/pdfodi2undorecordchaining-160518090511/75/ODI-chapter2-what-is-undo-record-chaining-6-2048.jpg)
![SGA Undo Segment
Shared Pool
Buffer Cache
3. UPDATE T1 SET C2=‘D'
v$transaction
XID_INFO UBA_INFO TXN_INFO
-------------------------- --------------- --------------------------------
addr : 0000000069B24E78 ubafil : 6 status : ACTIVE
xidusn : 10 ubablk : 210 start_date : 2016-01-13 18:57:04
xidslot : 0 ubasqn : 532 ses_addr : 000000006B21CC20
xidsqn : 1424 ubarec : 3
Undo Header
index state cflags wrap# uel scn dba
----------------------------------------------------------------
0x00 10 0x80 0x0590 0x0000 0x0000.004c2039 0x018000d2
0x01 9 0x00 0x058f 0x0002 0x0000.004bca7f 0x00000000
Undo Block
BH (0x643fb068) file#: 6 rdba: 0x018000d2 (6/210) class: 36 ba: 0x643ce000
xid: 0x000a.000.00000590 seq: 0x214 cnt: 0x3 irb: 0x3 icl: 0x0 flg: 0x0000
Rec Offset Rec Offset Rec Offset Rec Offset Rec Offset
---------------------------------------------------------------------------
0x01 0x1f44 0x02 0x1ecc 0x03 0x1e54
*-----------------------------
* Rec #0x1 slt: 0x00 objn: 70870(0x000114d6) objd: 70870 tblspc: 5(0x00000005)
* Layer: 11 (Row) opc: 1 rci 0x00
op: Z
itli: 2 ispac: 0 maxfr: 4858
vect = 11
col 1: [ 1] 41
*-----------------------------
* Rec #0x2 slt: 0x00 objn: 70870(0x000114d6) objd: 70870 tblspc: 5(0x00000005)
* Layer: 11 (Row) opc: 1 rci 0x01
op: C uba: 0x018000d2.0214.01
itli: 2 ispac: 0 maxfr: 4858
vect = 11
col 1: [ 1] 42
*-----------------------------
* Rec #0x3 slt: 0x00 objn: 70870(0x000114d6) objd: 70870 tblspc: 5(0x00000005)
* Layer: 11 (Row) opc: 1 rci 0x02
op: C uba: 0x018000d2.0214.02
itli: 2 ispac: 0 maxfr: 4858
vect = 11
col 1: [ 1] 43
BH (0x643f8968) file#: 5 rdba: 0x0140dcab (5/56491) class: 1 ba: 0x6438e000
st: XCURRENT md: NULL fpin: 'kdswh11: kdst_fetch' tch: 1
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0006.000.0000056a 0x00000000.0000.00 C--- 0 scn 0x0000.004c2027
0x02 0x000a.000.00000590 0x018000d2.0214.03 ---- 1 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
tl: 16 fb: --H-FL-- lb: 0x2 cc: 2
col 0: [10] 31 20 20 20 20 20 20 20 20 20
col 1: [ 1] 44
BH (0x643fb2d8) file#: 5 rdba: 0x0140dcab (5/56491) class: 1 ba: 0x643d2000
st: CR md: NULL fpin: 'kdswh11: kdst_fetch' tch: 1
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0006.000.0000056a 0x00000000.0000.00 C--- 0 scn 0x0000.004c2027
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
tl: 16 fb: --H-FL-- lb: 0x0 cc: 2
col 0: [10] 31 20 20 20 20 20 20 20 20 20
col 1: [ 1] 41
BH (0x643fb1a0) file#: 5 rdba: 0x0140dcab (5/56491) class: 1 ba: 0x643d0000
st: CR md: NULL fpin: 'kdswh11: kdst_fetch' tch: 1
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0006.000.0000056a 0x00000000.0000.00 C--- 0 scn 0x0000.004c2027
0x02 0x000a.000.00000590 0x018000d2.0214.01 ---- 1 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
tl: 16 fb: --H-FL-- lb: 0x2 cc: 2
col 0: [10] 31 20 20 20 20 20 20 20 20 20
col 1: [ 1] 42
BH (0x643f8e48) file#: 5 rdba: 0x0140dcab (5/56491) class: 1 ba: 0x64396000
st: CR md: NULL fpin: 'kdswh11: kdst_fetch' tch: 1
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0006.000.0000056a 0x00000000.0000.00 C--- 0 scn 0x0000.004c2027
0x02 0x000a.000.00000590 0x018000d2.0214.02 ---- 1 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
tl: 16 fb: --H-FL-- lb: 0x2 cc: 2
col 0: [10] 31 20 20 20 20 20 20 20 20 20
col 1: [ 1] 43
Before Image
ASCII HEXA code 43
=> Value ‘C’
After Image
ASCII HEXA code 44
=> Value ‘D’
Before Image
ASCII HEXA code 43
=> Value ‘C’
Before Image
ASCII HEXA code 42
=> Value ‘B’
Before Image
ASCII HEXA code 41
=> Value ‘A’
UPDATE T1
SET c2 = ‘D’](https://image.slidesharecdn.com/pdfodi2undorecordchaining-160518090511/75/ODI-chapter2-what-is-undo-record-chaining-7-2048.jpg)
![SGA Undo Segment
Shared Pool
Buffer Cache
4. Summary
v$transaction
XID_INFO UBA_INFO TXN_INFO
-------------------------- --------------- --------------------------------
addr : 0000000069B24E78 ubafil : 6 status : ACTIVE
xidusn : 10 ubablk : 210 start_date : 2016-01-13 18:57:04
xidslot : 0 ubasqn : 532 ses_addr : 000000006B21CC20
xidsqn : 1424 ubarec : 3
Undo Header
index state cflags wrap# uel scn dba
----------------------------------------------------------------
0x00 10 0x80 0x0590 0x0000 0x0000.004c2039 0x018000d2
0x01 9 0x00 0x058f 0x0002 0x0000.004bca7f 0x00000000
Undo Block
BH (0x643fb068) file#: 6 rdba: 0x018000d2 (6/210) class: 36 ba: 0x643ce000
xid: 0x000a.000.00000590 seq: 0x214 cnt: 0x3 irb: 0x3 icl: 0x0 flg: 0x0000
Rec Offset Rec Offset Rec Offset Rec Offset Rec Offset
---------------------------------------------------------------------------
0x01 0x1f44 0x02 0x1ecc 0x03 0x1e54
*-----------------------------
* Rec #0x1 slt: 0x00 objn: 70870(0x000114d6) objd: 70870 tblspc: 5(0x00000005)
* Layer: 11 (Row) opc: 1 rci 0x00
op: Z
itli: 2 ispac: 0 maxfr: 4858
vect = 11
col 1: [ 1] 41
*-----------------------------
* Rec #0x2 slt: 0x00 objn: 70870(0x000114d6) objd: 70870 tblspc: 5(0x00000005)
* Layer: 11 (Row) opc: 1 rci 0x01
op: C uba: 0x018000d2.0214.01
itli: 2 ispac: 0 maxfr: 4858
vect = 11
col 1: [ 1] 42
*-----------------------------
* Rec #0x3 slt: 0x00 objn: 70870(0x000114d6) objd: 70870 tblspc: 5(0x00000005)
* Layer: 11 (Row) opc: 1 rci 0x02
op: C uba: 0x018000d2.0214.02
itli: 2 ispac: 0 maxfr: 4858
vect = 11
col 1: [ 1] 43
BH (0x643f8968) file#: 5 rdba: 0x0140dcab (5/56491) class: 1 ba: 0x6438e000
st: XCURRENT md: NULL fpin: 'kdswh11: kdst_fetch' tch: 1
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0006.000.0000056a 0x00000000.0000.00 C--- 0 scn 0x0000.004c2027
0x02 0x000a.000.00000590 0x018000d2.0214.03 ---- 1 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
tl: 16 fb: --H-FL-- lb: 0x2 cc: 2
col 0: [10] 31 20 20 20 20 20 20 20 20 20
col 1: [ 1] 44
BH (0x643fb2d8) file#: 5 rdba: 0x0140dcab (5/56491) class: 1 ba: 0x643d2000
st: CR md: NULL fpin: 'kdswh11: kdst_fetch' tch: 1
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0006.000.0000056a 0x00000000.0000.00 C--- 0 scn 0x0000.004c2027
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
tl: 16 fb: --H-FL-- lb: 0x0 cc: 2
col 0: [10] 31 20 20 20 20 20 20 20 20 20
col 1: [ 1] 41
BH (0x643fb1a0) file#: 5 rdba: 0x0140dcab (5/56491) class: 1 ba: 0x643d0000
st: CR md: NULL fpin: 'kdswh11: kdst_fetch' tch: 1
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0006.000.0000056a 0x00000000.0000.00 C--- 0 scn 0x0000.004c2027
0x02 0x000a.000.00000590 0x018000d2.0214.01 ---- 1 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
tl: 16 fb: --H-FL-- lb: 0x2 cc: 2
col 0: [10] 31 20 20 20 20 20 20 20 20 20
col 1: [ 1] 42
BH (0x643f8e48) file#: 5 rdba: 0x0140dcab (5/56491) class: 1 ba: 0x64396000
st: CR md: NULL fpin: 'kdswh11: kdst_fetch' tch: 1
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x0006.000.0000056a 0x00000000.0000.00 C--- 0 scn 0x0000.004c2027
0x02 0x000a.000.00000590 0x018000d2.0214.02 ---- 1 fsc 0x0000.00000000
0x03 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
tl: 16 fb: --H-FL-- lb: 0x2 cc: 2
col 0: [10] 31 20 20 20 20 20 20 20 20 20
col 1: [ 1] 43
Before Image
ASCII HEXA code 43
=> Value ‘C’
After Image
ASCII HEXA code 44
=> Value ‘D’
Before Image
ASCII HEXA code 43
=> Value ‘C’
Before Image
ASCII HEXA code 42
=> Value ‘B’
Before Image
ASCII HEXA code 41
=> Value ‘A’
op: C uba: 0x018000d2.0214.02
op: C uba: 0x018000d2.0214.01
op: Z
Rec #0x1
Rec #0x2
Rec #0x3](https://image.slidesharecdn.com/pdfodi2undorecordchaining-160518090511/75/ODI-chapter2-what-is-undo-record-chaining-8-2048.jpg)


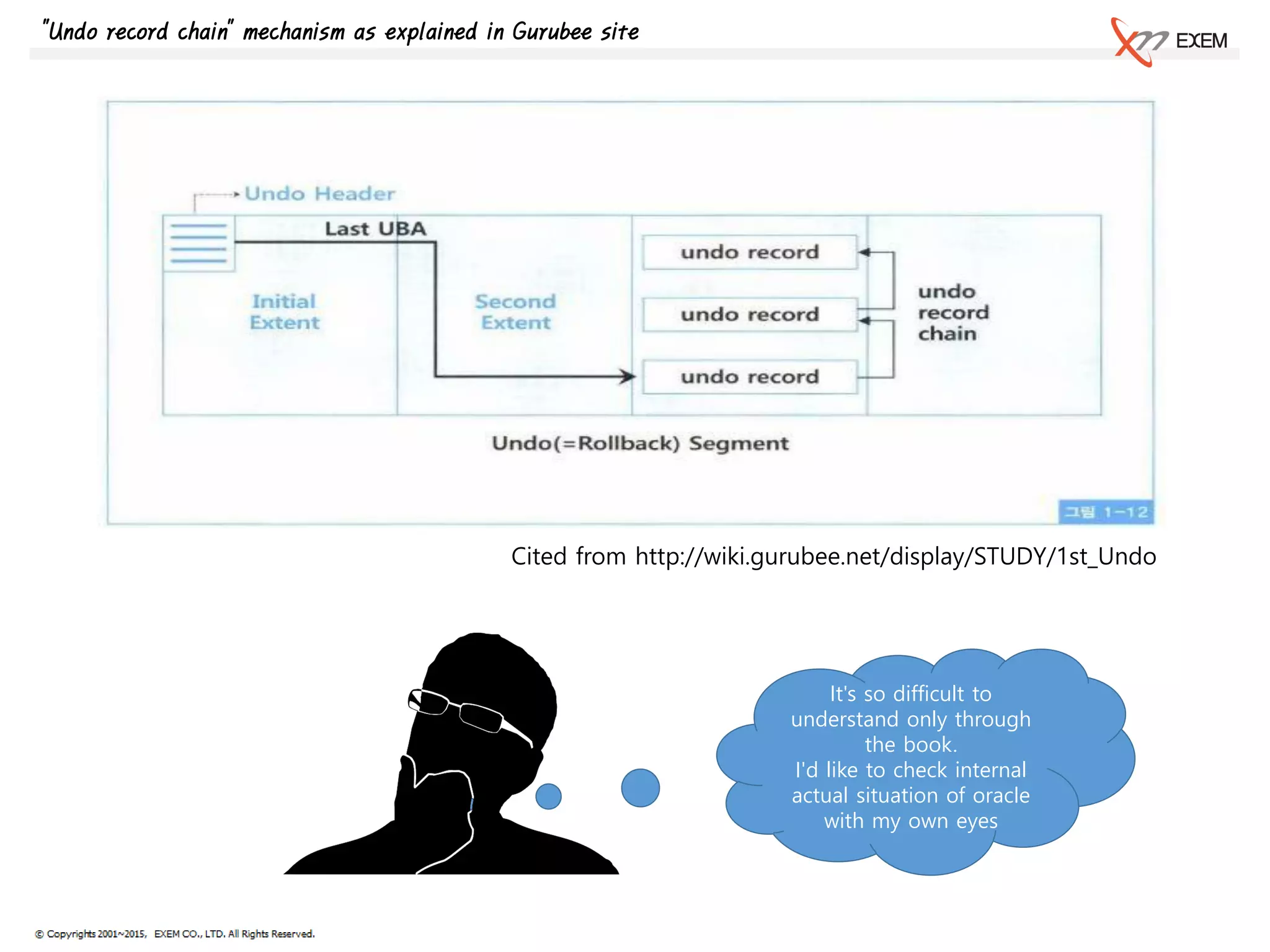
- Undo record chaining allows Oracle to rollback multiple transactions by linking undo records together in a chain. - When an update is made, an undo record is generated and added to the undo block. A new record contains the before image of the update. - Undo records for a transaction are chained together by transaction ID and sequence number. This allows Oracle to efficiently rollback a whole transaction by traversing the undo record chain.


![[ODI] chapter1 When Update statement is executed, How does oracle undo work?](https://cdn.slidesharecdn.com/ss_thumbnails/pdfodi1updatedatablockundo-160518084718-thumbnail.jpg?width=640&height=640&fit=bounds)


![[ODI] chapter3 What is Max CR DBA(Max length)?](https://cdn.slidesharecdn.com/ss_thumbnails/pdfodi3dbblockmaxcrdba6crblock-160518090714-thumbnail.jpg?width=640&height=640&fit=bounds)
![[KOR] ODI no.004 analysis of oracle performance degradation caused by ineffic...](https://cdn.slidesharecdn.com/ss_thumbnails/g-odino-160520013714-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[Practical owi] lock & latch](https://cdn.slidesharecdn.com/ss_thumbnails/practicalowilocklatch-160421010819-thumbnail.jpg?width=640&height=640&fit=bounds)






























![[2009 CodeEngn Conference 03] koheung - 윈도우 커널 악성코드에 대한 분석 및 방법](https://cdn.slidesharecdn.com/ss_thumbnails/20093rdcodeengnkoheungmalwareanalysismethodofwindowskernel-130720165552-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















