









![Staging Server
▪ Gateway In & Out of an HDFS Cell
▪ Reads/Writes to /hdfs/staging/{in,out}/... (runs as hdfs)
▪ HTTP Based (POST/GET)
▪ Upload to http://hadoop-staging/put[/hdfs/staging/in/...]
Stores directly in HDFS, no intermediary storage
Multiple files support
Random target directory created if none specified
Parameters user, group, perm, suffix
curl -F "file=@local;filename=remote" http://../put?user=foo&group=bar&perm=644&suffix=.test
▪ Download from http://hadoop-staging/get/hdfs/staging/out/...
Ability to unpack SequenceFile records (unpack={base64,hex}) as key:value lines](https://image.slidesharecdn.com/leveraginghadoopforlegacysystems-final-111109120024-phpapp02/85/Leveraging-Hadoop-for-Legacy-Systems-15-320.jpg)











![Pig to Groovy
bag -> java.util.List
tuple -> Object[]
map -> java.util.Map
int -> int
long -> long
float -> float
double -> double
chararray -> java.lang.String
bytearray -> byte[]
Groovy to Pig
groovy.lang.Tuple -> tuple
Object[] -> tuple
java.util.List -> bag
java.util.Map -> map
byte/short/int -> int
long/BigInteger -> long
float -> float
double/BigDecimal -> double
java.lang.String -> chararray
byte[] -> bytearray](https://image.slidesharecdn.com/leveraginghadoopforlegacysystems-final-111109120024-phpapp02/85/Leveraging-Hadoop-for-Legacy-Systems-28-320.jpg)




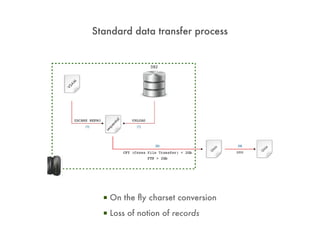
![com.arkea.commons.pig.COBOLBinaryHelper
REGISTER copybook.jar;
A = LOAD '$data' USING cacp.SequenceFileLoadFunc('cacp.COBOLBinaryHelper','[PREFIX:]COPYBOOK');
000010*GAR* OS Y7XRRDC DESCRIPTION RRDC NOUVAU FORMAT 30000020
000020* LG=00328, ESD MAJ LE 04/12/98, ELS MAJ LE 26/01/01 PAR C98310 30000030
000030* GENERE LE 26/01/01 A 17H01, PFX : Y7XRRD- MEMBRE : Y7XRRDC 30000040
000040 01 Y7XRRD-Y7XRRDC. 30000050
000050* DESCRIPTION RRDC NOUVAU FORMAT 1 04/12/98 30000060
000060 03 Y7XRRD-ARTDS-CLE-SECD. 30000070 A: {
000070* CLE SECONDAIRE ARCHIVAGE TENU DE SOLDE 1 11/02/98 30000080 key: bytearray,
000080 05 Y7XRRD-NO-CCM PIC X(4). 30000090
000090* NUMERO CAISSE 1 28/12/94 30000100
value: bytearray,
000100 05 Y7XRRD-NO-PSE PIC X(8). 30000110 parsed: (
000110* NUMERO PERSONNE 5 10/07/97 30000120 Y7XRRD_Y7XRRDC: bytearray,
000120 05 Y7XRRD-CATEGORIE PIC X(2). 30000130
000130* CATéGORIE DU COMPTE 13 09/01/01 30000140 Y7XRRD_ARTDS_CLE_SECD: bytearray,
000140 05 Y7XRRD-RANG PIC X(2). 30000150 Y7XRRD_NO_CCM: chararray,
010010* RANG 15 22/01/01 30000160
010020 05 Y7XRRD-NO-ORDRE PIC X(2). 30000170 Y7XRRD_NO_PSE: chararray,
010030* Numéro d'ordre 17 28/12/94 30000180 Y7XRRD_CATEGORIE: chararray,
010040 05 Y7XRRD-DA-TT-C2 PIC X(8). 30000190
010050* DATE TRAITEMENT SX:-C2 19 - - 30000200 Y7XRRD_RANG: chararray,
010060 05 Y7XRRD-NO-ORDRE-ENR-C2 PIC 9(6). 30000210 Y7XRRD_NO_ORDRE: chararray,
010070* Numéro d'ordre enregistrement SX:-C2 27 - - 30000220
010080 03 Y7XRRD-MT-OPE-TDS PIC S9(13)V9(2) COMP-3. 30000230
Y7XRRD_DA_TT_C2: chararray,
010090* MONTANT OPERATION TENUE-DE-SOLDE 33 03/02/98 30000240 Y7XRRD_NO_ORDRE_ENR_C2: long,
010100 03 Y7XRRD-CD-DVS-ORI-OPE PIC X(4). 30000250
010110* CODE DEVISE ORIGINE OPERATION 41 - - 30000260
Y7XRRD_MT_OPE_TDS: double,
010120 03 Y7XRRD-CD-DVS-GTN-TDS PIC X(4). 30000270 Y7XRRD_CD_DVS_ORI_OPE: chararray,
010130* CODE DEVISE GESTION TENUE-DE-SOLDE 45 - - 30000280 Y7XRRD_CD_DVS_GTN_TDS: chararray,
010140 03 Y7XRRD-MT-CNVS-OPE PIC S9(13)V9(2) COMP-3. 30000290
020010* MONTANT CONVERTI OPERATION 49 - - 30000300 Y7XRRD_MT_CNVS_OPE: double,
020020 03 Y7XRRD-IDC-ATN-ORI-MT PIC X(1). 30000310 Y7XRRD_IDC_ATN_ORI_MT: chararray,
020030* INDICATEUR AUTHENTICITE ORIGINE MONTAN 57 05/12/97 30000320
020040 03 Y7XRRD-SLD-AV-IMPT PIC S9(13)V9(2) COMP-3. 30000330 Y7XRRD_SLD_AV_IMPT: double,
020050* SOLDE AVANT IMPUTATION 58 03/02/98 30000340 Y7XRRD_DA_OPE_TDS: chararray,
020060 03 Y7XRRD-DA-OPE-TDS PIC X(8). 30000350
020070* DATE OPERATION TENUE-DE-SOLDE 66 - - 30000360 Y7XRRD_DA_VLR: chararray,
020080 03 Y7XRRD-DA-VLR PIC X(8). 30000370 Y7XRRD_DA_ARR: chararray,
020090* DATE VALEUR 74 28/12/94 30000380
020100 03 Y7XRRD-DA-ARR PIC X(8). 30000390
Y7XRRD_NO_STR_OPE: chararray,
020110* DATE ARRETE 82 - - 30000400 Y7XRRD_NO_REF_TNL_MED: chararray,
020120 03 Y7XRRD-NO-STR-OPE PIC X(6). 30000410 Y7XRRD_NO_LOT: chararray,
020130* NUMERO STRUCTURE OPERATIONNELLE 90 - - 30000420
020140 03 Y7XRRD-NO-REF-TNL-MED PIC X(4). 30000430 Y7XRRD_TDS_LIBELLES: bytearray,
030010* NUMERO REFERENCE TERMINAL MEDIA 96 03/02/98 30000440 Y7XRRD_LIB_CLI_OPE_1: chararray,
030020 03 Y7XRRD-NO-LOT PIC X(3). 30000450
030030* NUMéRO DE LOT 100 13/10/97 30000460 Y7XRRD_LIB_ITE_OPE: chararray,
030040 03 Y7XRRD-TDS-LIBELLES. 30000470 Y7XRRD_LIB_CT_CLI: chararray,
030050* FAMILLE MONTANTS OPERATION T.DE.SOLDE 103 05/02/98 30000480
030060 05 Y7XRRD-LIB-CLI-OPE-1 PIC X(50). 30000490 Y7XRRD_CD_UTI_LIB_CPL: chararray,
030070* LIBELLE CLIENT OPERATION SX:-1 103 03/02/98 30000500 Y7XRRD_IDC_COM_OPE: chararray,
030080 05 Y7XRRD-LIB-ITE-OPE PIC X(32). 30000510
030090* LIBELLE INTERNE OPERATION 153 - - 30000520
Y7XRRD_CD_TY_OPE_NIV_1: chararray,
030100 05 Y7XRRD-LIB-CT-CLI PIC X(32). 30000530 Y7XRRD_CD_TY_OPE_NIV_2: chararray,
030110* LIBELLE COURT CLIENT 185 - - 30000540 FILLER: chararray,
030120 03 Y7XRRD-CD-UTI-LIB-CPL PIC X(1). 30000550
030130* Code utilisation libellés compl. 217 28/12/94 30000560 Y7XRRD_TDS_LIB_SUPPL: bytearray,
030140 03 Y7XRRD-IDC-COM-OPE PIC X(1). 30000570 Y7XRRD_LIB_CLI_OPE_02: chararray,
040010* INDICATEUR COMMISSION OPERATION 218 03/02/98 30000580
040020 03 Y7XRRD-CD-TY-OPE-NIV-1 PIC X(1). 30000590 Y7XRRD_LIB_CLI_OPE_03: chararray
040030* CODE TYPE OPERATION NIVEAU UN 219 - - 30000600 )
040040 03 Y7XRRD-CD-TY-OPE-NIV-2 PIC X(2). 30000610
040050* CODE TYPE OPERATION NIVEAU DEUX 220 - - 30000620 }
040060 03 FILLER PIC X(7). 30000630
040070* 222 30000640
040080 03 Y7XRRD-TDS-LIB-SUPPL. 30000650
040090* FAMILLE LIBELLES COMPLEMENTAIRES T.D.S 229 17/02/98 30000660
040100 05 Y7XRRD-LIB-CLI-OPE-02 PIC X(50). 30000670
040110* LIBELLE CLIENT OPERATION SX:-02 229 03/02/98 30000680
040120 05 Y7XRRD-LIB-CLI-OPE-03 PIC X(50). 30000690
040130* LIBELLE CLIENT OPERATION SX:-03 279 - - 30000700](https://image.slidesharecdn.com/leveraginghadoopforlegacysystems-final-111109120024-phpapp02/85/Leveraging-Hadoop-for-Legacy-Systems-33-320.jpg)
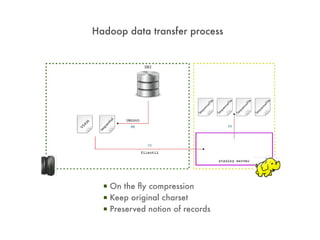
![com.arkea.commons.pig.DB2UnloadBinaryHelper
REGISTER ddl-load.jar;
A = LOAD '$data' USING cacp.SequenceFileLoadFunc('cacp.DB2UnloadBinaryHelper','[PREFIX:]TABLE');
CREATE TABLE SHDBA.TBDCOLS
(COL_CHAR CHAR(4) FOR SBCS DATA WITH DEFAULT NULL,
COL_DECIMAL DECIMAL(15, 2) WITH DEFAULT NULL,
COL_NUMERIC DECIMAL(15, 0) WITH DEFAULT NULL,
.ddl COL_SMALLINT SMALLINT WITH DEFAULT NULL,
COL_INTEGER INTEGER WITH DEFAULT NULL, A: {
COL_VARCHAR VARCHAR(50) FOR SBCS DATA WITH DEFAULT NULL, key: bytearray,
COL_DATE DATE WITH DEFAULT NULL, value: bytearray,
COL_TIME TIME WITH DEFAULT NULL, parsed: (
COL_TIMESTAMP TIMESTAMP WITH DEFAULT NULL) ; COL_CHAR: chararray,
COL_DECIMAL: double,
COL_NUMERIC: long,
COL_SMALLINT: long,
TEMPLATE DFEM8ERT
COL_INTEGER: long,
DSN('XXXXX.PPSDR.B99BD02.SBDCOLS.REC')
COL_VARCHAR: chararray,
DISP(OLD,KEEP,KEEP)
COL_DATE: chararray,
LOAD DATA INDDN DFEM8ERT LOG NO RESUME YES
COL_TIME: chararray,
EBCDIC CCSID(01147,00000,00000)
COL_TIMESTAMP:
INTO TABLE "SHDBA"."TBDCOLS"
chararray
WHEN(00001:00002) = X'003F'
)
.load ( "COL_CHAR" POSITION( 00004:00007) CHAR(00004) NULLIF(00003)=X'FF',
}
"COL_DECIMAL" POSITION( 00009:00016) DECIMAL NULLIF(00008)=X'FF',
"COL_NUMERIC" POSITION( 00018:00025) DECIMAL NULLIF(00017)=X'FF',
"COL_SMALLINT" POSITION( 00027:00028) SMALLINT NULLIF(00026)=X'FF',
"COL_INTEGER" POSITION( 00030:00033) INTEGER NULLIF(00029)=X'FF',
"COL_VARCHAR" POSITION( 00035:00086) VARCHAR NULLIF(00034)=X'FF',
"COL_DATE" POSITION( 00088:00097) DATE EXTERNAL NULLIF(00087)=X'FF',
"COL_TIME" POSITION( 00099:00106) TIME EXTERNAL NULLIF(00098)=X'FF',
"COL_TIMESTAMP" POSITION( 00108:00133) TIMESTAMP EXTERNAL NULLIF(00107)=X'FF'
)
Can also handle DB2 UDB unloads (done using hpu)](https://image.slidesharecdn.com/leveraginghadoopforlegacysystems-final-111109120024-phpapp02/85/Leveraging-Hadoop-for-Legacy-Systems-34-320.jpg)


1. The COBOLBinaryHelper loads COBOL data from SequenceFiles and parses the bytes into a structured record based on the provided COPYBOOK. 2. The record contains the raw COBOL field values as bytearrays as well as parsed versions as strings and arrays. 3. Pig UDFs can then operate directly on the parsed fields to analyze and transform the COBOL data.





























































































