Downloaded 36 times

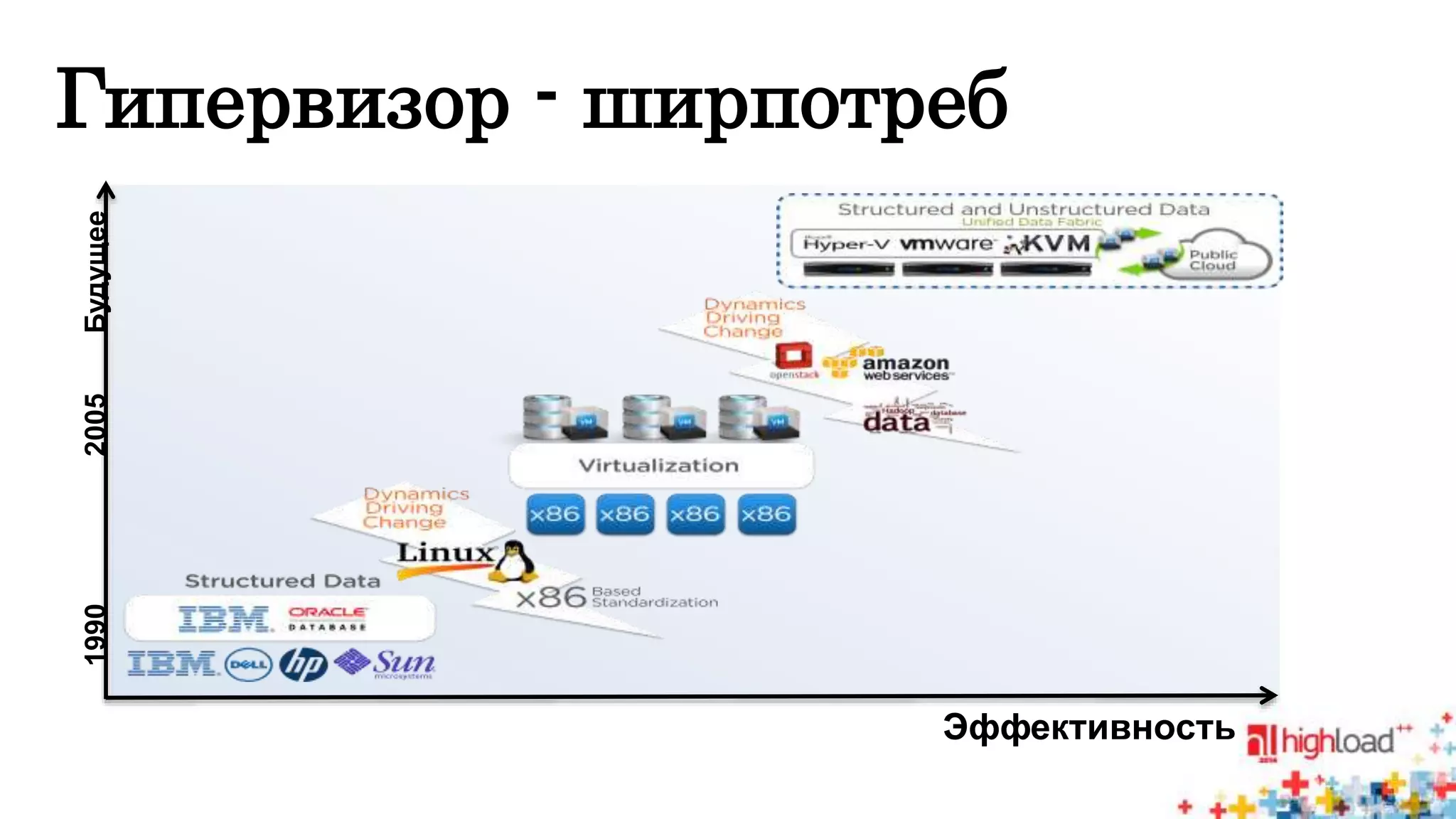












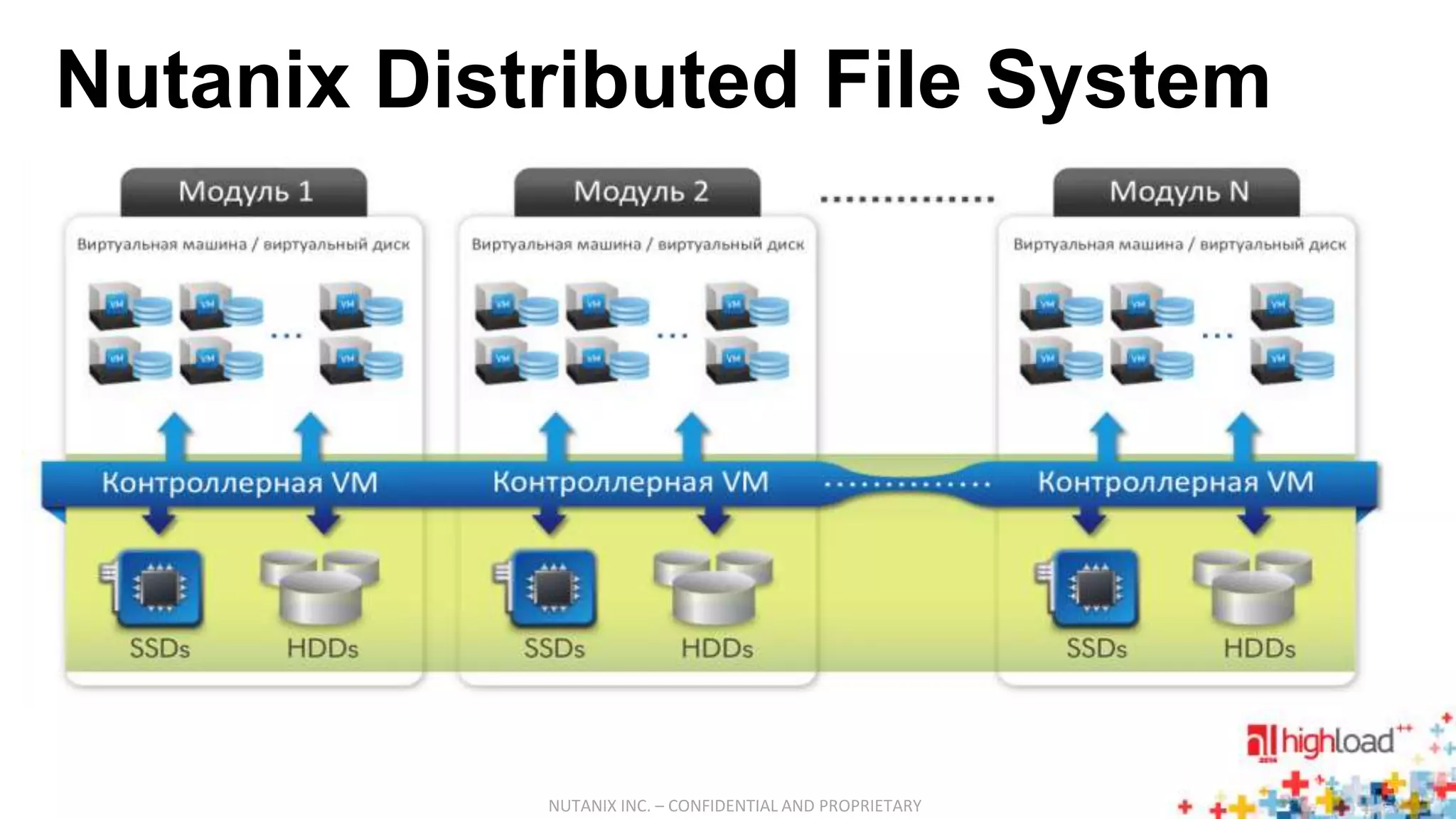
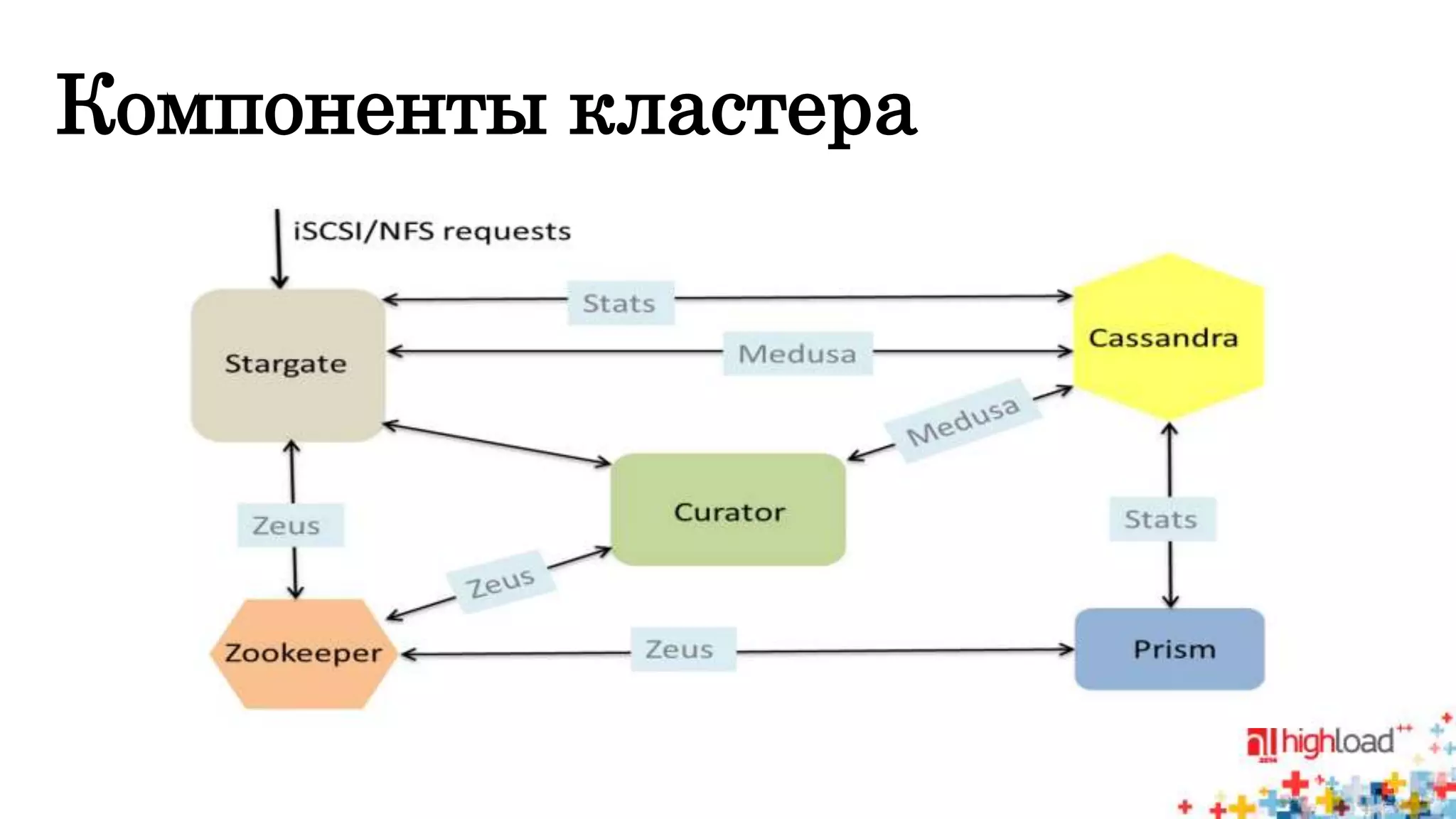



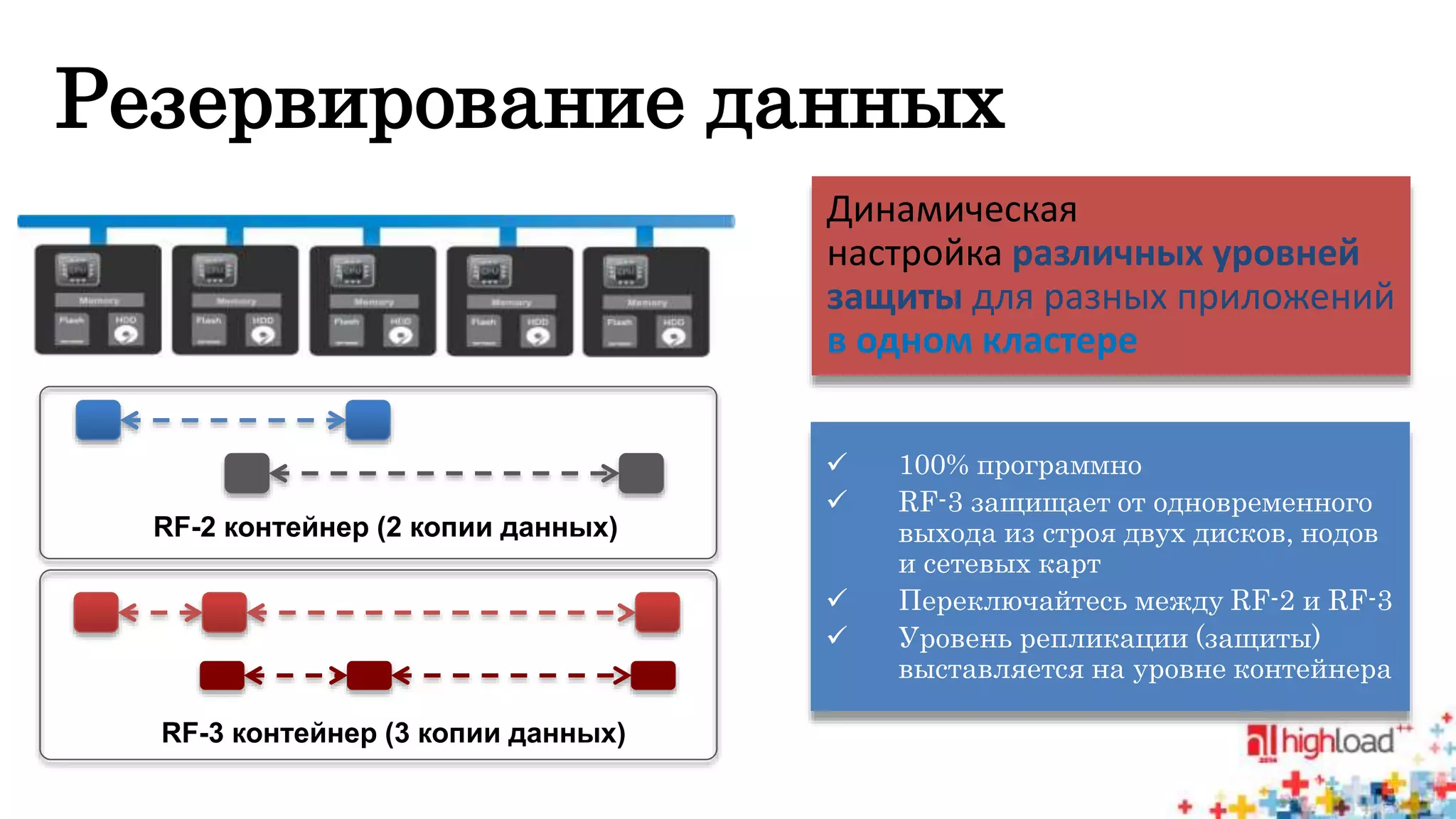
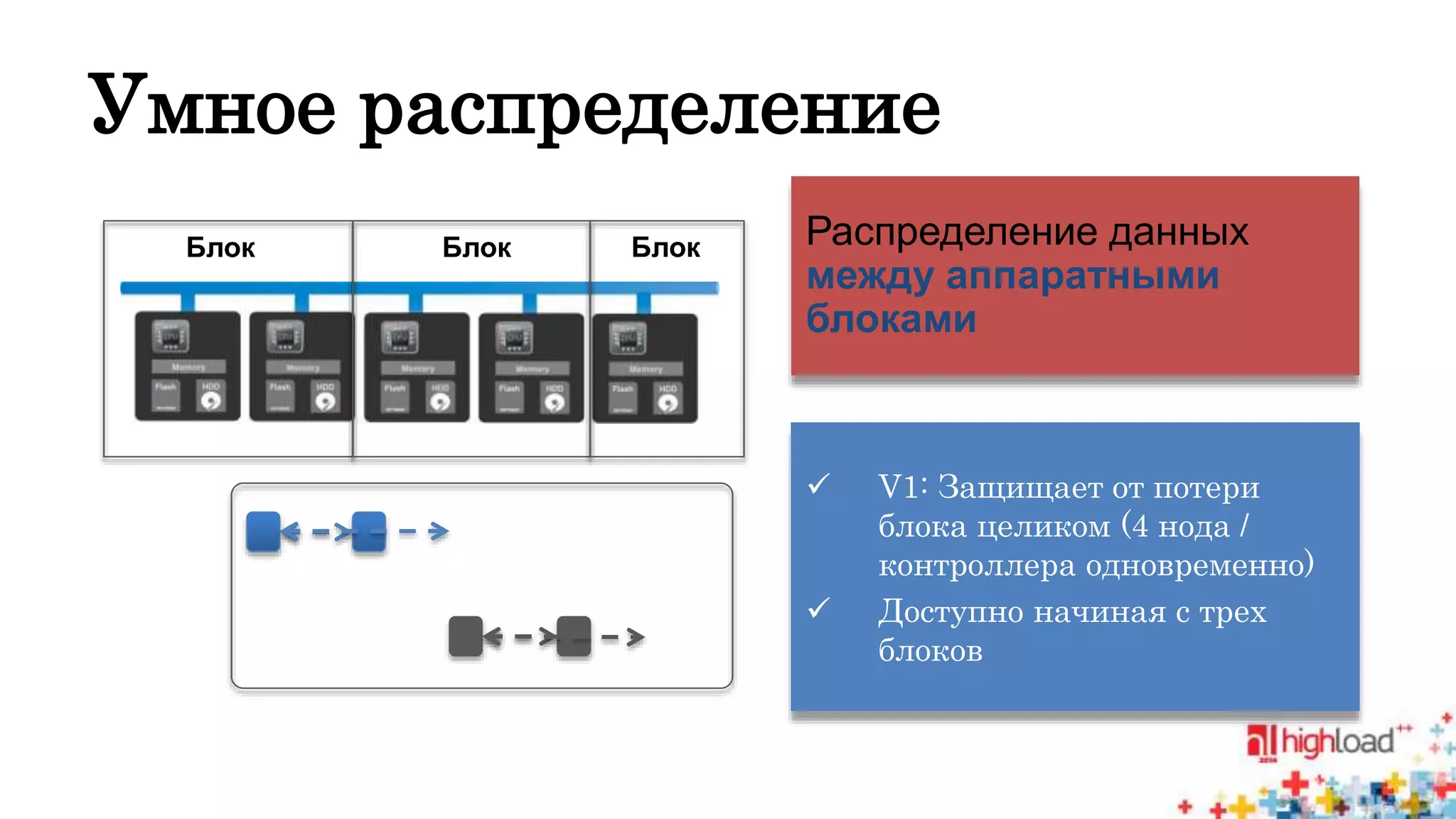


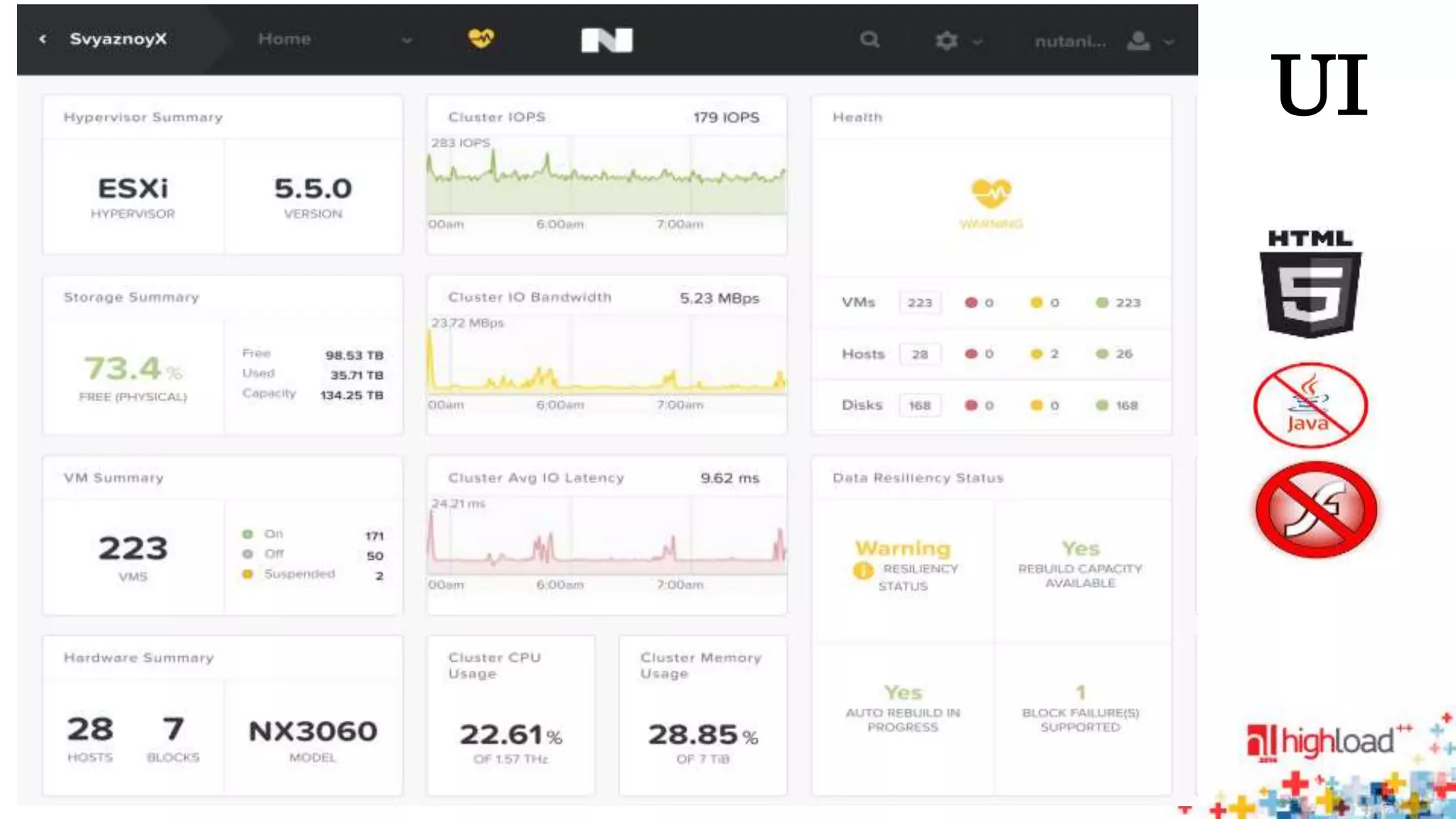

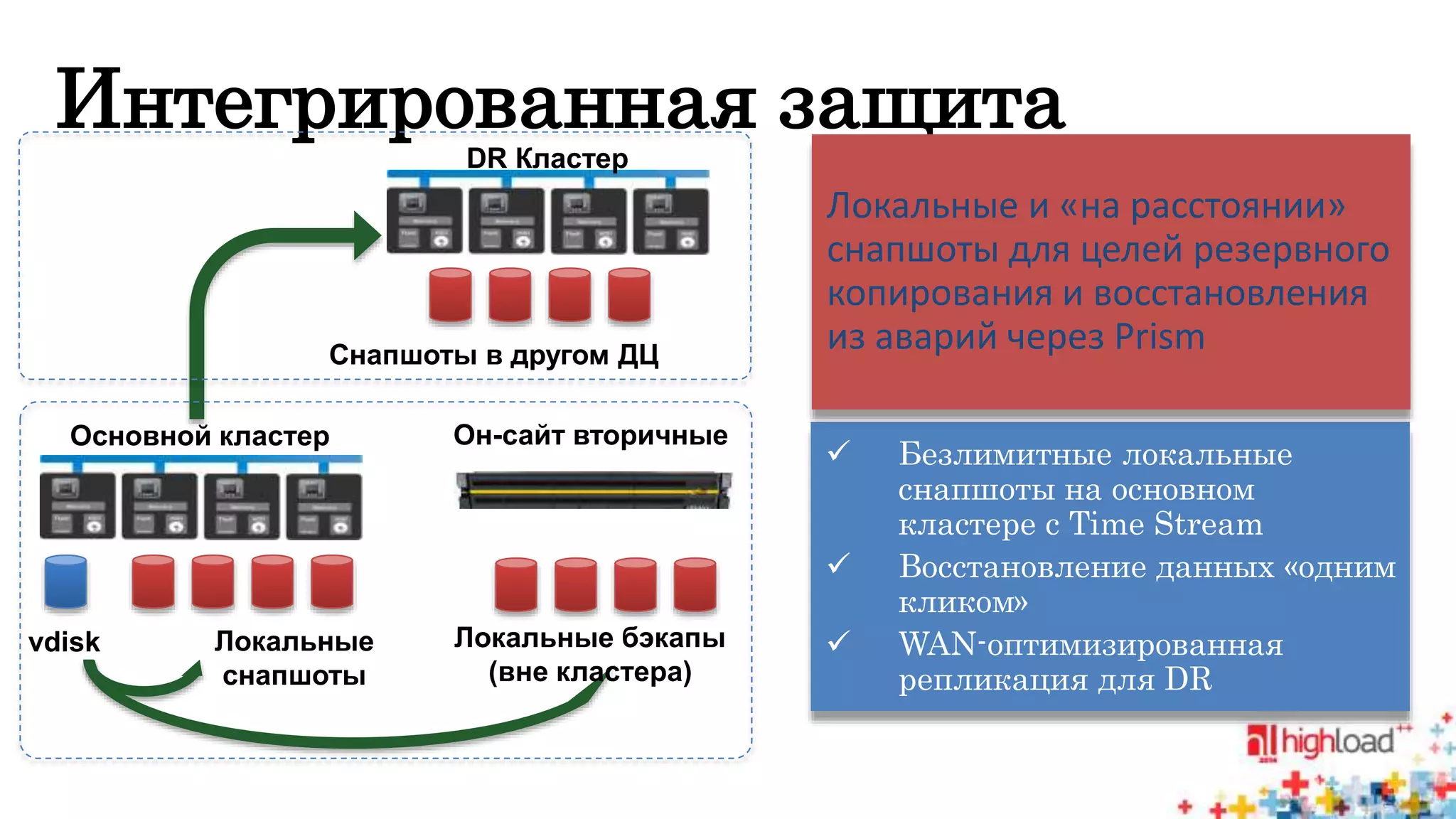



Документ описывает систему Nutanix Acropolis как облачное решение на базе KVM, предназначенное для оптимизации работы дата-центров с фокусом на снижение энергопотребления и автоматизацию. Упоминаются проблемы традиционных систем, такие как сложность, неэффективность и высокая стоимость, а также подчеркивается интегрированная природа Nutanix с поддержкой распределенных файловых систем и защите данных. В результате, система предлагает масштабируемость и гибкость для различных пользователей, от государственных структур до сервис-провайдеров.

































![Обзор архитектуры [файловой] системы Ceph](https://cdn.slidesharecdn.com/ss_thumbnails/ceph-150618110935-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)








































