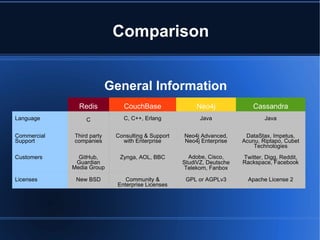
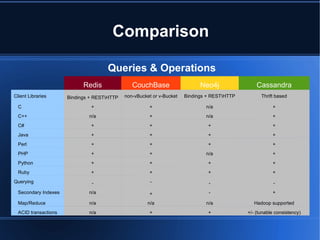
This document compares different NoSQL database options and discusses which type may be best for different use cases. It provides an overview of the current NoSQL landscape and models, including key-value, document, graph and wide column stores. Specific databases like Redis, CouchBase, Neo4j and Cassandra are compared based on features like query support, operations, and commercial options. The document recommends choosing a database based on the specific problem and considering aspects like data size, read/write needs, and tradeoffs between consistency, availability and partitioning. It also advocates starting small but with significance and considering hybrid SQL/NoSQL approaches.

















![Q&A Thank you for attention mail: [email_address] skype: siarhei_bushyk](https://image.slidesharecdn.com/nosqloptionscompared-120209093143-phpapp02/85/NoSQL-Options-Compared-19-320.jpg)











































































