The document presents the Neural Processes family and discusses various types, including Conditional Neural Processes (CNPs) and Attentive Neural Processes (ANPs), emphasizing their ability to model uncertainty and improve predictive performance in tasks like function regression and image completion. Key concepts include the architecture of CNPs and their ability to integrate outputs and prior information for better learning efficiency compared to traditional Gaussian Processes. The document also details experimental results demonstrating the effectiveness of these models in few-shot learning scenarios and generative tasks.

![Table of contents
1. Conditional Neural Processes [Garnelo+ (ICML2018)]
2. Neural Processes [Garnelo+ (ICML2018WS)]
3. Attentive Neural Processes [Kim+ (ICLR2019)]
4. Meta-Learning surrogate models for sequential decision
making [Galashov+ (ICLR2019WS)]
5. On the Connection between Neural Processes and Gaussian
Processes with Deep Kernels [Rudner+ (NeurIPS2018WS)]
6. Conclusion
K. Matsui (RIKEN AIP) Neural Processes Family 1 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-2-2048.jpg)
![Table of Contents
1. Conditional Neural Processes [Garnelo+ (ICML2018)]
2. Neural Processes [Garnelo+ (ICML2018WS)]
3. Attentive Neural Processes [Kim+ (ICLR2019)]
4. Meta-Learning surrogate models for sequential decision
making [Galashov+ (ICLR2019WS)]
5. On the Connection between Neural Processes and Gaussian
Processes with Deep Kernels [Rudner+ (NeurIPS2018WS)]
6. Conclusion
K. Matsui (RIKEN AIP) Neural Processes Family Conditional Neural Processes 2 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-3-2048.jpg)






![Conditional Neural Processes iii Training
Optimization Problem
minimization of the negative conditional log probability
θ∗
= arg min
θ
L(θ)
L(θ) = −Ef∼P
[
EN
[
log Qθ
(
{yi}n−1
i=0 | ON , {xi}n−1
i=0
)]]
• f ∼ P : prior process
• N ∼ Unif(0, n − 1)
• ON = {(xi, yi)}N
i=0 ⊂ O
practical implementation : gradient descent
1. sampling f and N
2. MC estimates of the gradient of L(θ)
3. gradient descent by estimated gradient
K. Matsui (RIKEN AIP) Neural Processes Family Conditional Neural Processes Model 10 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-11-2048.jpg)

![Image Completion i Setting
Dataset
1. MNIST (f : [0, 1]2 → [0, 1])
Complete the entire image from a small number of
observation
2. CelebA (f : [0, 1]2 → [0, 1]3)
Complete the entire image from a small number of
observation
network architectures
• the same model architecture as for 1D function regression
except for
• input layer : 2D pixel coordinates normalized to [0, 1]2
• output layer : color intensity of the corresponding pixel
K. Matsui (RIKEN AIP) Neural Processes Family Conditional Neural Processes Experimental Results 13 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-14-2048.jpg)





![Table of Contents
1. Conditional Neural Processes [Garnelo+ (ICML2018)]
2. Neural Processes [Garnelo+ (ICML2018WS)]
3. Attentive Neural Processes [Kim+ (ICLR2019)]
4. Meta-Learning surrogate models for sequential decision
making [Galashov+ (ICLR2019WS)]
5. On the Connection between Neural Processes and Gaussian
Processes with Deep Kernels [Rudner+ (NeurIPS2018WS)]
6. Conclusion
K. Matsui (RIKEN AIP) Neural Processes Family Neural Processes 20 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-21-2048.jpg)


![Evidence Lower-Bound (ELBO)
隠れ変数 z の変分事後分布を q(z | x1:n, y1:n) とおくと ELBO は
log p (y1:n|x1:n)
≥ Eq(z|x1:n,y1:n)
[ n∑
i=1
log p (yi | z, xi) + log
p(z)
q (z | x1:n, y1:n)
]
特に予測時には観測データとテストデータを分割して
log p (ym+1:n | x1:m, xm+1:n, y1:m)
≥ Eq(z|xm+1:n,ym+1:n)
[ n∑
i=m+1
log p (yi | z, xi) + log
p (z | x1:m, y1:m)
q (z | xm+1:n, ym+1:n)
]
≈ Eq(z|xm+1:n,ym+1:n)
[ n∑
i=m+1
log p (yi | z, xi) + log
q (z | x1:m, y1:m)
q (z | xm+1:n, ym+1:n)
]
p を q で近似している理由は, 観測データによる条件付き分布としての計算
に O(m3
) のコストがかかるのを回避するため
K. Matsui (RIKEN AIP) Neural Processes Family Neural Processes Model 23 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-24-2048.jpg)



![Table of Contents
1. Conditional Neural Processes [Garnelo+ (ICML2018)]
2. Neural Processes [Garnelo+ (ICML2018WS)]
3. Attentive Neural Processes [Kim+ (ICLR2019)]
4. Meta-Learning surrogate models for sequential decision
making [Galashov+ (ICLR2019WS)]
5. On the Connection between Neural Processes and Gaussian
Processes with Deep Kernels [Rudner+ (NeurIPS2018WS)]
6. Conclusion
K. Matsui (RIKEN AIP) Neural Processes Family Attentive Neural Processes 27 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-28-2048.jpg)
![Recall : Neural Processes
x1 y1
x2 y2
x3 y3
MLPθ
MLPθ
MLPθ
MLPΨ
MLPΨ
MLPΨ
r1
r2
r3
s1
s2
s3
rCm
m sC
x
rC
~
MLP y
ENCODER DECODER
Deterministic
Path
Latent
Path
NEURAL PROCESS
m Mean
z
z
*
*
• 潜在表現 r と潜在変数 z を両方モデルに組み込む ver.
• ELBO を目的関数として学習
log p (yT | xT , xC , yC )
≥Eq(z|sT ) [log p (yT | xT , rC , z)] − DKL (q (z | sT ) ∥q (z | sC ))
K. Matsui (RIKEN AIP) Neural Processes Family Attentive Neural Processes Introduction 28 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-29-2048.jpg)






![Attentive Neural Processes : Remarks
• self-attention, cross-attention を導入しても, 観測点に対す
る permutation invariant な性質は保たれる
• uniform attention (全ての観測点の同じ重みを割り振る) を
採用するとオリジナルの NP に帰着
• オリジナルの NP と同様の ELBO 最大化で学習
log p (yT | xT , xC, yC)
≥Eq(z|sT ) [log p (yT | xT , r∗, z)] − DKL (q (z | sT ) ∥q (z | sC))
• r∗ = r∗(xC, yC, xT ) : cross-attention の出力 (潜在表現)
• attention 計算 (各観測点に対する重み計算) が増えたため,
予測時の計算複雑さは O(n + m) から O(n(n + m)) に増加
K. Matsui (RIKEN AIP) Neural Processes Family Attentive Neural Processes ANPs 36 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-37-2048.jpg)
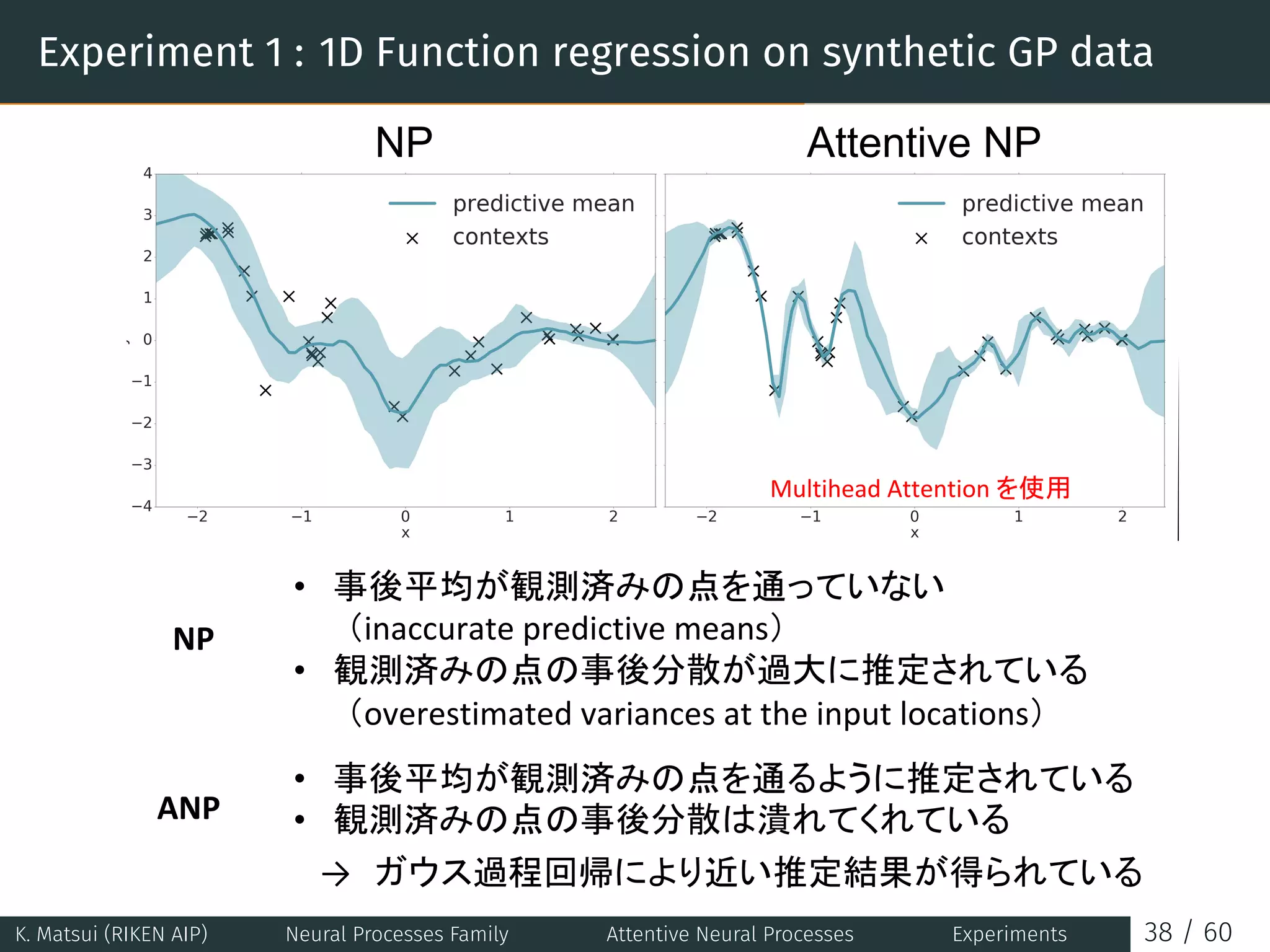
![Experiment 1 : 1D Function regression on synthetic GP data
context point
target negative log likelihood
training iteration
wall clock time
Published as a conference paper at ICLR 2019
Figure 3: Qualitative and quantitative results of different attention mechanisms for 1D GP func
regression with random kernel hyperparameters. Left: moving average of context reconstruc
error (top) and target negative log likelihood (NLL) given contexts (bottom) plotted against train
iterations (left) and wall clock time (right). d denotes the bottleneck size i.e. hidden layer size o
MLPs and the dimensionality of r and z. Right: predictive mean and variance of different atten
mechanisms given the same context. Best viewed in colour.
1D Function regression on synthetic GP data We first explore the (A)NPs trained on data th
generated from a Gaussian Process with a squared-exponential kernel and small likelihood noi
We emphasise that (A)NPs need not be trained on GP data or data generated from a known stocha
process, and this is just an illustrative example. We explore two settings: one where the hype
rameters of the kernel are fixed throughout training, and another where they vary randomly at e
d =
hidden layer size of MLPs
dimensionality of r
dimensionality of z
• 2 GP
• context point n target point m iteration
•
• ANPs self-attention , cross-attention
1
|C|
i C
Eq(z|sC ) [log p (yi|xi, r (xC, yC, xi) , z)]
1
|T|
i T
Eq(z|sC ) [log p (yi|xi, r (xC, yC, xi) , z)]
K. Matsui (RIKEN AIP) Neural Processes Family Attentive Neural Processes Experiments 37 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-38-2048.jpg)

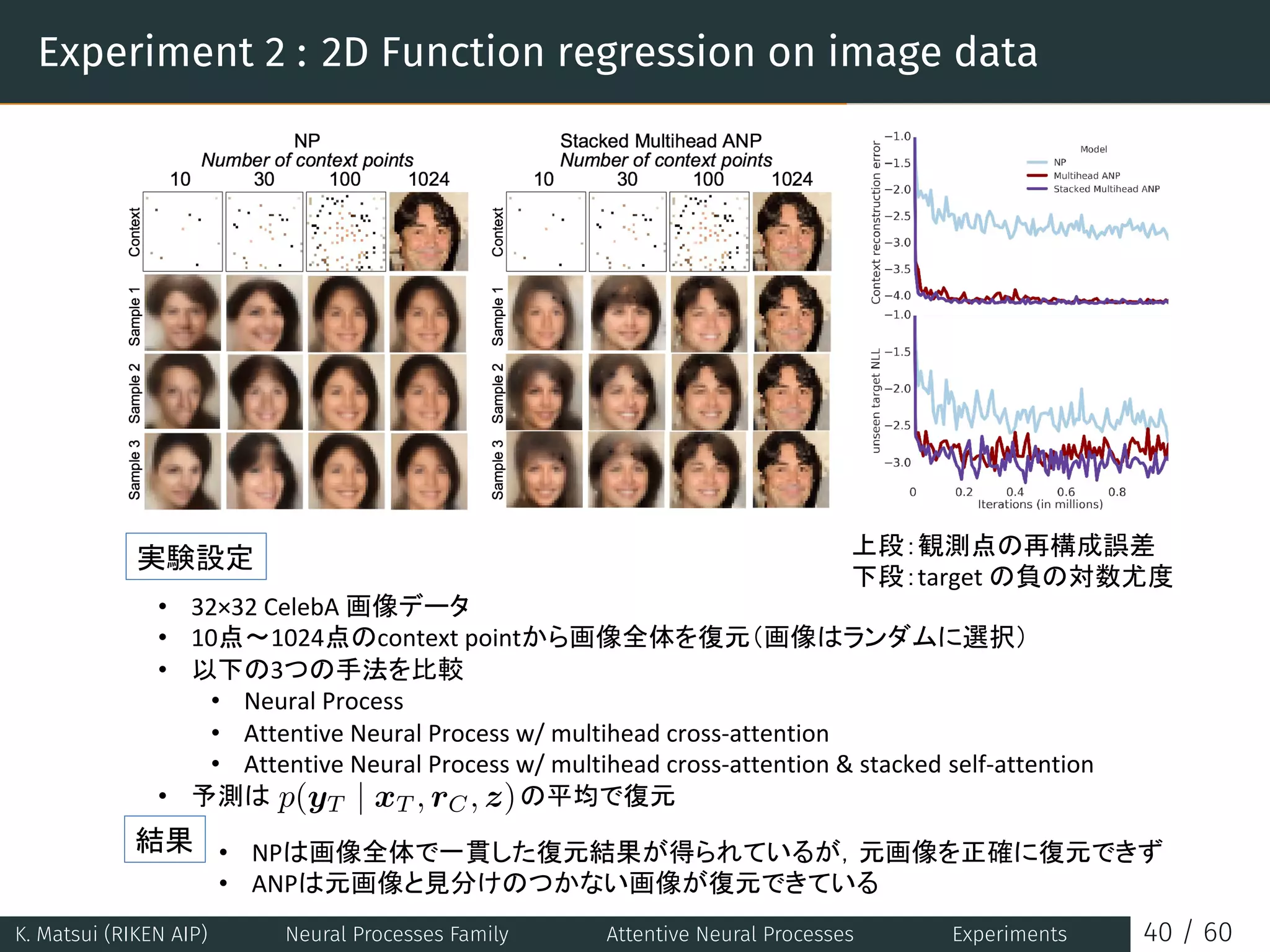

![Table of Contents
1. Conditional Neural Processes [Garnelo+ (ICML2018)]
2. Neural Processes [Garnelo+ (ICML2018WS)]
3. Attentive Neural Processes [Kim+ (ICLR2019)]
4. Meta-Learning surrogate models for sequential decision
making [Galashov+ (ICLR2019WS)]
5. On the Connection between Neural Processes and Gaussian
Processes with Deep Kernels [Rudner+ (NeurIPS2018WS)]
6. Conclusion
K. Matsui (RIKEN AIP) Neural Processes Family BO via Neural Processes 42 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-43-2048.jpg)
![Meta-Learning
個々のタスクに対して共通に良い初期値を与える上位の学習器
(meta-learner) を考える
Model-Agnostic Meta-Learning (MAML) [Finn+ (ICML2017)]
• meta-learner によって θ が task 1-3 の学習に対して良い初
期値となるように設定される
• meta-learner の設定した θ を warm start とすることでよ
り少ないコストで task 毎の最適なパラメータを発見
できる
K. Matsui (RIKEN AIP) Neural Processes Family BO via Neural Processes 43 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-44-2048.jpg)


![Experiments : Bayesian Optimization via NPs
Adversarial task search for RL agents [Ruderman+ (2018)]
• Search Problem of adversarially designed 3D Maze
• trivially solvable by human players
• But RL agents will catastrophically fail
• Notation
• fA : given agent mapping from task params to its
performance r
• parameters of the task
• M : maze layout
• ps, pg : start and goal positions
Problem setup
1. Position search (p∗
s, p∗
g) = arg min
ps,pg
fA(M, ps, pg)
2. Full maze search (M∗, p∗
s, p∗
g) = arg min
M,ps,pg
fA(M, ps, pg)
K. Matsui (RIKEN AIP) Neural Processes Family BO via Neural Processes 46 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-47-2048.jpg)
![Experiments : Bayesian Optimization via NPs
(a) Position search results (b) Full maze search results
Figure 2: Bayesian Optimisation results. Left: Position search Right: Full maze search. We report
the minimum up to iteration t (scaled in [0,1]) as a function of the number of iterations. Bold
lines show the mean performance over 4 unseen agents on a set of held-out mazes. We also show
20% of the standard deviation. Baselines: GP: Gaussian Process (with a linear and Matern 3/2
product kernel [Bonilla et al., 2008]), BBB: Bayes by Backprop [Blundell et al., 2015], AlphaDiv:
AlphaDivergence [Hernández-Lobato et al., 2016], DKL: Deep Kernel Learning [Wilson et al., 2016].
K. Matsui (RIKEN AIP) Neural Processes Family BO via Neural Processes 47 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-48-2048.jpg)
![Table of Contents
1. Conditional Neural Processes [Garnelo+ (ICML2018)]
2. Neural Processes [Garnelo+ (ICML2018WS)]
3. Attentive Neural Processes [Kim+ (ICLR2019)]
4. Meta-Learning surrogate models for sequential decision
making [Galashov+ (ICLR2019WS)]
5. On the Connection between Neural Processes and Gaussian
Processes with Deep Kernels [Rudner+ (NeurIPS2018WS)]
6. Conclusion
K. Matsui (RIKEN AIP) Neural Processes Family Connection between NP and GP 48 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-49-2048.jpg)


![Gaussian Processes with Deep Kernels ii
Definition 1 (deep kernel [Tsuda+ (2002)])
k (xi, xj) :=
1
d
d∑
j,j′=1
σ
(
w⊤
j xi + bj
)
Σjj′ σ
(
w⊤
j′ xj + bj
)
• σ
(
w⊤
j xi + bj
)
は 1 層の NN, w, b はモデルパラメータで
σ(·) は活性化関数
• Σ = (Σjj′ )d
j,j′=1 は半正定値行列
行列表記
ϕi := ϕ(xi, W , b) =
√
1
d
σ(W ⊤
xi + b) ∈ Rd
,
Φ = [ϕ1, ..., ϕn] とおくと, k(X, X) = ΦΣΦ⊤.
以下, GP の平均関数は次のような形で書かれるとする
m(X) = Φµ, µ ∈ Rd
K. Matsui (RIKEN AIP) Neural Processes Family Connection between NP and GP GP with Deep Kernels 51 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-52-2048.jpg)

![Gaussian Processes with Deep Kernels iv
エビデンス p (y|X) を計算するには共分散行列 ΦΣΦ⊤ + τ−1In
の逆行列計算が必要 (O(n3) の計算コスト)
→ エビデンス下界 (ELBO) の計算で置き換えてコスト削減
log p(Y | X) ≥ Eq(z|X)[log p(Y | z, X)] − KL(q(z | X)∥p(z))
K. Matsui (RIKEN AIP) Neural Processes Family Connection between NP and GP GP with Deep Kernels 53 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-54-2048.jpg)
![予測時の ELBO の一致 i
Deep kernel GPs のエビデンス下界を, 観測データとテストデー
タを明示的に分離して書く (C = 1 : m, T = m + 1 : n はそれぞ
れ観測データ, テストデータを表す)
log p (YT | XT , XC, YC)
≥Eq(z|XT ,YT ) [log p (YT | z, XT )] − KL (q (z | XT , YT ) ∥p (z | XC, YC))
ここで, p (z | XC, YC) は観測データ XC, YC に基づいて設定さ
れる “data-driven” な prior
p (z | XC, YC) = N(µ(XC, YC), Σ(XC, YC))
NPs でやったのと同様にこれを変分事後分布で近似する
p (z | XC, YC) ≈ q (z | XC, YC)
K. Matsui (RIKEN AIP) Neural Processes Family Connection between NP and GP NP as GP 54 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-55-2048.jpg)
![予測時の ELBO の一致 ii
以上の下で, Deep kernel GP の ELBO は
Eq(z|XT ,YT ) [log p (YT | z, XT )] − KL (q (z | XT , YT ) ∥q (z | XC, YC))
一方, NPs の ELBO は
log p (ym+1:n | x1:m, xm+1:n, y1:m)
≥ Eq(z|xm+1:n,ym+1:n)
[ n∑
i=m+1
log p (yi | z, xi) + log
p (z | x1:m, y1:m)
q (z | xm+1:n, ym+1:n)
]
≈ Eq(z|xm+1:n,ym+1:n)
[ n∑
i=m+1
log p (yi | z, xi) + log
q (z | x1:m, y1:m)
q (z | xm+1:n, ym+1:n)
]
となり, 両者の生成モデルが同じならばELBO も一致すること
がわかる
K. Matsui (RIKEN AIP) Neural Processes Family Connection between NP and GP NP as GP 55 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-56-2048.jpg)

![Table of Contents
1. Conditional Neural Processes [Garnelo+ (ICML2018)]
2. Neural Processes [Garnelo+ (ICML2018WS)]
3. Attentive Neural Processes [Kim+ (ICLR2019)]
4. Meta-Learning surrogate models for sequential decision
making [Galashov+ (ICLR2019WS)]
5. On the Connection between Neural Processes and Gaussian
Processes with Deep Kernels [Rudner+ (NeurIPS2018WS)]
6. Conclusion
K. Matsui (RIKEN AIP) Neural Processes Family Conclusion 57 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-58-2048.jpg)

![Further Neural Processes
• Functional neural processes [Louizos+ (arXiv2019)]
• Recurrent neural processes [Willi+ (arXiv2019)]
• Sequential neural processes [Singh+ (arXiv2019)]
• Conditional neural additive processes [Requeima+
(arXiv2019)]
K. Matsui (RIKEN AIP) Neural Processes Family Conclusion 59 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-60-2048.jpg)
![References
[1] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep
networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages
1126–1135. JMLR. org, 2017.
[2] Alexandre Galashov, Jonathan Schwarz, Hyunjik Kim, Marta Garnelo, David Saxton, Pushmeet Kohli, SM Eslami,
and Yee Whye Teh. Meta-learning surrogate models for sequential decision making. arXiv preprint
arXiv:1903.11907, 2019.
[3] Marta Garnelo, Dan Rosenbaum, Christopher Maddison, Tiago Ramalho, David Saxton, Murray Shanahan,
Yee Whye Teh, Danilo Rezende, and SM Ali Eslami. Conditional neural processes. In International Conference on
Machine Learning, pages 1690–1699, 2018.
[4] Marta Garnelo, Jonathan Schwarz, Dan Rosenbaum, Fabio Viola, Danilo J Rezende, SM Eslami, and Yee Whye
Teh. Neural processes. arXiv preprint arXiv:1807.01622, 2018.
[5] Hyunjik Kim, Andriy Mnih, Jonathan Schwarz, Marta Garnelo, Ali Eslami, Dan Rosenbaum, Oriol Vinyals, and
Yee Whye Teh. Attentive neural processes. arXiv preprint arXiv:1901.05761, 2019.
[6] Tim GJ Rudner, Vincent Fortuin, Yee Whye Teh, and Yarin Gal. On the connection between neural processes and
gaussian processes with deep kernels. In Workshop on Bayesian Deep Learning, NeurIPS, 2018.
K. Matsui (RIKEN AIP) Neural Processes Family Conclusion 60 / 60](https://image.slidesharecdn.com/neuralprocessesfamily-2-190820061831/75/Neural-Processes-Family-61-2048.jpg)
![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Conditional Neural Processes](https://cdn.slidesharecdn.com/ss_thumbnails/conditionalneuralprocesses-180727001730-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−](https://cdn.slidesharecdn.com/ss_thumbnails/20190415dlhacks-190422075753-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)








































